
使用python实现自动下载网站数据的详细操作流程(附详解源码)
使用python来对网站上的数据集进行抓取、下载、分类保存,让你解放双手轻松整理数据!步骤详细,一看就会,老年人我也给你讲明白!
概要
最近在做项目复现,需要下载相关数据集,对于大量的时间序列数据集,网站中往往是以时间分类来存放的,对于动辄需要学习几年甚至十几年的深度学习模型来说,数据下载必然要交给代码来自动执行,下面通过一个具体的示例来展示一下使用python自动下载网站中的数据集并分门别类的存储好。
数据集网站链接:挪威气象局浮标数据集
地址:https://thredds.met.no/thredds/catalog/obs/buoy-svv-e39/catalog.html
本文数据的相关处理方式我也专门写了博客说明,需要的同学请移步:使用python的NetCDF4库来处理时序数据详细流程
这里下载好的海浪数据集也上传到我的资源,需要的同学直接取用即可。
挪威峡湾海洋波浪场浮标检测数据
目标数据介绍
这里我们要下载的数据集是挪威气象局通过布置海洋浮标的方式来获得的海浪要素数据集,我们需要的时间跨度为2017-2020年之间四年的数据,浮标一共布置在五个地点,我们要做的是设置程序,自动抓取目标数据集的URL,下载下来,并分类存储在本地文件夹下。
程序所需相关库
所需相关库如下:
import time
import requests
import os
from bs4 import BeautifulSoup
import re
import sys
这里介绍一下这两个库
-
BeautifulSoup 是一个用于解析 HTML 和 XML 文档的 Python 库,广泛应用于网页抓取、数据提取和处理任务。
-
requests 是一个简单易用的 HTTP 库,用于发送各种 HTTP 请求(GET、POST、PUT、DELETE 等)。广泛用于网页抓取、数据传输等领域。
安装也很简单,直接使用pip命令即可。
pip install beautifulsoup4
重点代码细节解释
这里我通过一个小示例的debug过程来说明一下BeautifulSoup对网页HTML信息的识别抓取过程,帮助大家更好的理解,
示例代码如下:
import requests
from bs4 import BeautifulSoup
base_url = "https://thredds.met.no/thredds/catalog/obs/buoy-svv-e39/catalog.html"
response = requests.get(base_url)
soup = BeautifulSoup(response.text, "html.parser")
year_urls = []
#上面三行就是抓取到我们给的URL对应网页的HTML页面
# 查找页面中包含年份的目录链接
for link in soup.find_all("a"):
href = link.get("href")
if href and "/catalog.html" in href:
print("发现目标URL")
很多同学可能疑惑,下面那个for循环到底是在干嘛呢?为什么运行就能抓取到我们要的URL呢?
这就需要我们使用debug操作,结合网页实际的HTML页面来看看代码到底做了什么
首先debug一下,看看link变量的变化
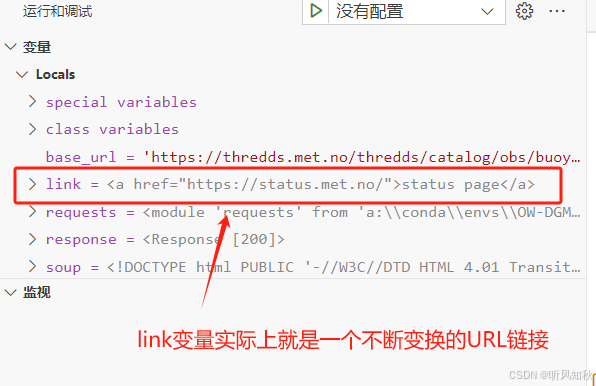
可以看到,link是一个不断在变化的URL地址,且前面都带了一个“a”的标记,我们去网站的HTML页面看看这个标记代表着什么。
使用chorme浏览器打开我在文章一开始给出的超链接地址,在网页上按下F12,我们就可以看到详细的HTML信息页面
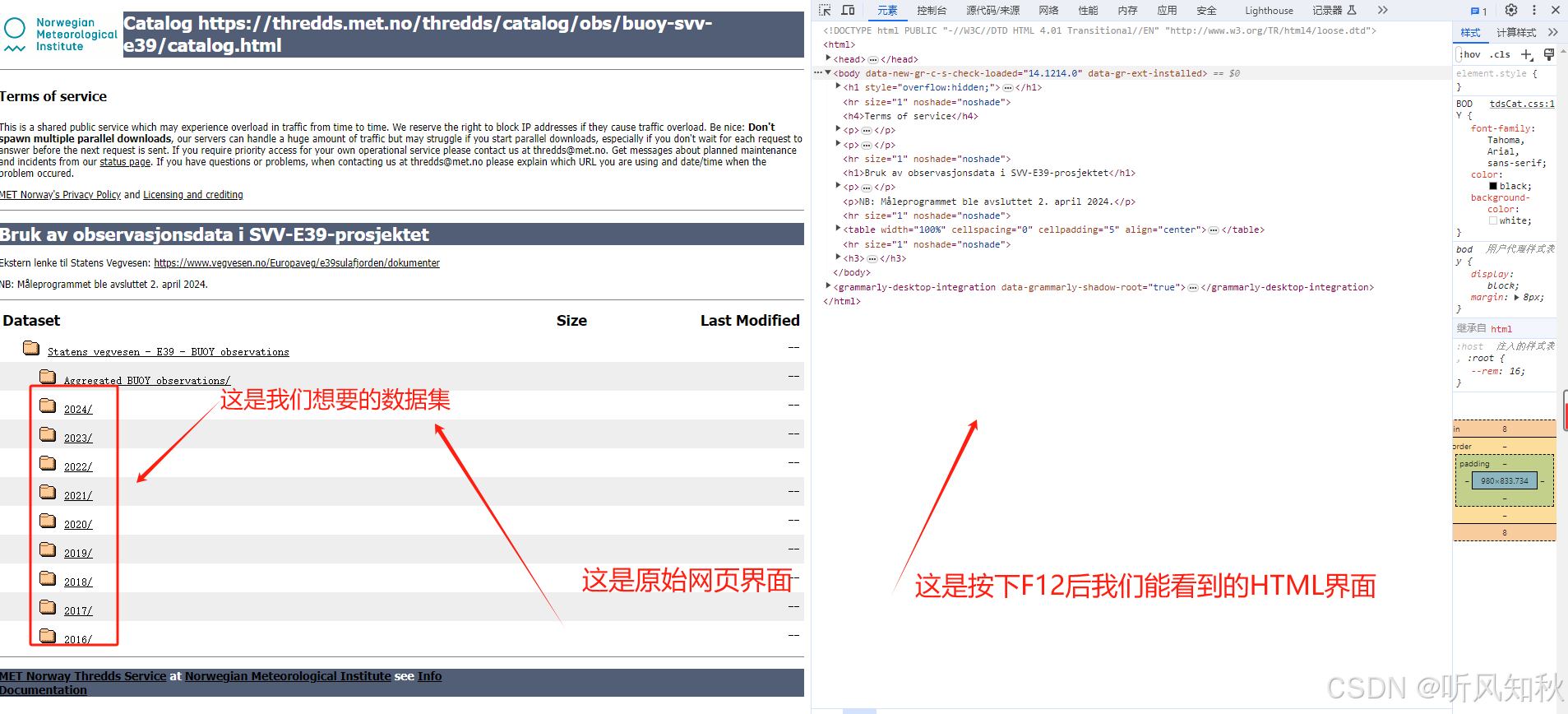
图中红框就是我们想要的数据集,我们要获得网页中这些数据集的URL。在HTML页面中检查一下,我们就会发现代码的原理。
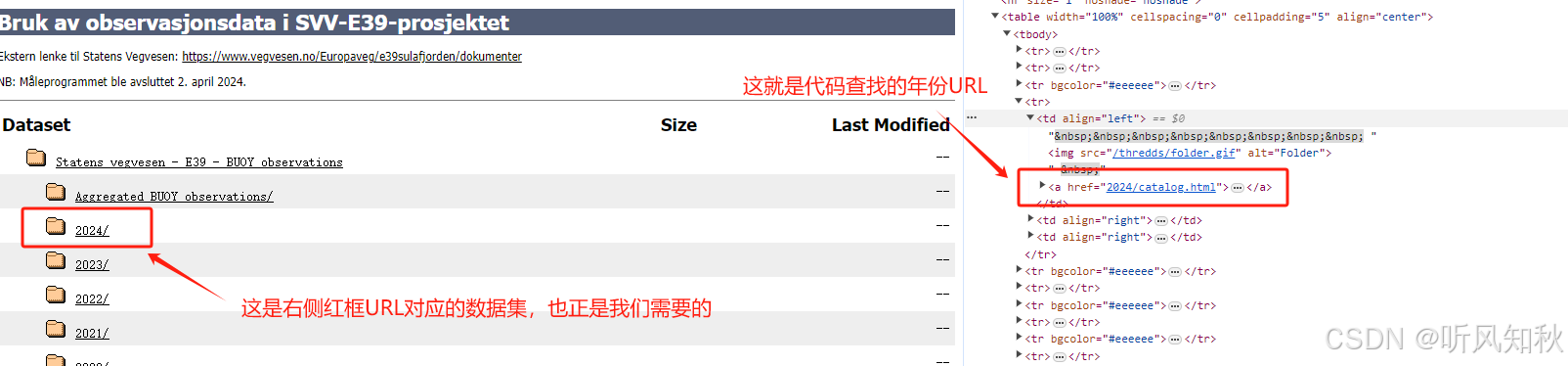
大家看到这里就明白了为什么soup.find_all(“a”)中查找条件要写“a”了,因为他代表着网页中所有的跳转链接部分,代码抽取所有跳转链接,再筛选到我们需要的年份数据集链接,这就是这段代码背后的原理,也是这章下载内容最关键的点。
下载流程
首先把相关库导入进去
import time
import requests
import os
from bs4 import BeautifulSoup
import re
import sys
对于以时间序列为标志的数据集,最重要的就是处理好时间序列,才能做到有条理、不遗漏的下载所需数据集,所以我们先做一个时间处理:
# 获取年份目录的页面
def get_year_urls(start_years, end_years):
response = requests.get(base_url)
soup = BeautifulSoup(response.text, "html.parser")
year_urls = []
# 查找页面中包含年份的目录链接
for link in soup.find_all("a"):
href = link.get("href")
if href and "/catalog.html" in href:
year_str = href.split("/")[0]
if year_str.isdigit() and start_years <= int(year_str) <= end_years:
#这里大家要注意做一个替换,换成你要下载数据集的地址
#当然想更省事的同学也可以直接用split库把这里的地址切分开做一个拼接。
year_urls.append(f"https://thredds.met.no/thredds/catalog/obs/buoy-svv-e39/{year_str}/catalog.html")
return year_urls
上面函数的目的是获取一个你要抓取的数据集的精确到年份的URL列表
下面我们继续把时间精确到月份上:
# 获取每月数据页面的 URL 列表
def get_month_urls(year_url):
response = requests.get(year_url)
soup = BeautifulSoup(response.text, "html.parser")
month_urls = []
# 查找页面中的月份目录链接
for link in soup.find_all("a"):
href = link.get("href")
if href and "/catalog.html" in href:
month_urls.append(year_url.replace("catalog.html", href))
return month_urls
时间安排好之后(注意,这里我下载的浮标数据分类就到了月份,你需要的数据集如果需要更精确的时间单位,那你可以仿照上面代码来进一步做区分。)我们就得到了真正的数据集存放界面了,我们需要按照月份来读个读取数据,把数据集的URL链接抓取并保存起来,供后面下载函数来直接下载。这部分代码如下:
def get_nc_file_urls(month_url, number_buoy):
"""
Args:
month_url: 各个浮标的wave.nc文件链接
Returns:
file_urls: 文件链接
"""
response = requests.get(month_url)
soup = BeautifulSoup(response.text, "html.parser")
file_urls = []
# 查找所有Sulafjorden_wave.nc文件
for link in soup.find_all("a"):
href = link.get("href")
if href and ("wave.nc" in href) and (number_buoy in href) and ('raw' not in href):
dataset_url = month_url.replace("catalog.html", href)
dataset_page = requests.get(dataset_url)
dataset_soup = BeautifulSoup(dataset_page.text, "html.parser")
# 找到实际的下载链接
for a in dataset_soup.find_all("a"):
file_href = a.get("href")
if file_href and "fileServer" in file_href:
file_urls.append(f"https://thredds.met.no{file_href}")
return file_urls
这段代码执行之后返回来的就是每一个月份下所需要数据的URL链接了,这里有一个需要注意的点,因为我不是需要整个页面内的所有数据集,我只需要海浪相关数据,而风速、温度等数据集是我不需要的,上述代码中使用了 if 条件语句来做URL筛选,大家改写代码的时候要注意这里修改成你需要的数据集筛选方式。
#注意这个if语句,替换成你所需要的筛选内容来得到你要的数据集。
if href and ("wave.nc" in href) and (number_buoy in href) and ('raw' not in href):
我们继续添加代码,再写一个文件下载函数来帮我们下载抓取到的数据集。这里为了防止下载的目标数据过大不能一次读取,我们设置下分块下载。
# 下载文件函数
def download_file(url, save_path):
response = requests.get(url, stream=True) #发送GET请求以获取文件内容
with open(save_path, "wb") as file:
for chunk in response.iter_content(chunk_size=8192): #分块读取响应内容,每次读取8192字节的数据块
file.write(chunk)
print(f"Downloaded: {save_path}")
大功告成,我们最后使用一个完整的下载函数来串起上述所有相关函数,最后用mian函数来启动我们整个下载流程。
# 主下载逻辑
def main_buoy(start_years, end_years):
# if not os.path.exists(path):
# os.makedirs(download_dir)
# 获取年份页面列表
year_urls = get_year_urls(start_years, end_years)
#写个列表让代码自动抓取五个浮标的数据,这里是五个浮标的对应标记
range_buoy_download = ['_A_','_B_', '_C_', '_D_', '_F_']
#这个列表是为了在保存数据时能够把五个浮标数据分来保存起来
file_buoy = ['A', 'B', 'C', 'D', 'F']
for i in range(len(range_buoy_download)):
for year_url in year_urls:
# 获取每月页面列表
month_urls = get_month_urls(year_url)
for month_url in month_urls:
# 获取.nc文件的实际下载链接
file_urls = get_nc_file_urls_2(month_url, range_buoy_download[i]) #在这个地方打开的是所有浮标当月的数据
for file_url in file_urls:
file_name = os.path.join(download_dir, file_buoy[i], os.path.basename(file_url))
# 检查文件是否已下载
if not os.path.exists(file_name):
print(file_url)
download_file(file_url, file_name)
time.sleep(5) # 等待2秒再下载下一个文件,避免过多请求
else:
print(f"File already exists: {file_name}")
#这里写上我们目标抓取数据网页的总URL地址,以及我们数据的保存路径。
base_url = "https://thredds.met.no/thredds/catalog/obs/buoy-svv-e39/catalog.html"
download_dir = "./Dataset/buoy/" #这里路径是会自动创建的
if __name__ == "__main__":
#设置好要下载的年份
start_years = 2017
end_years = 2019
main_buoy(start_years= start_years, end_years= end_years)
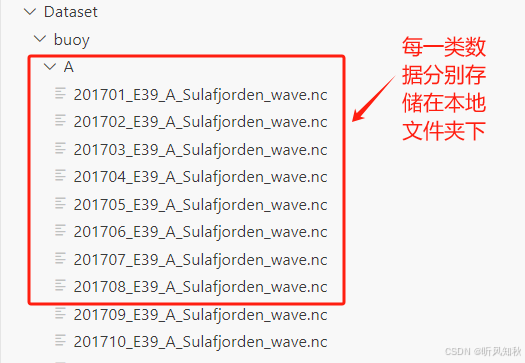
运行起来,就可以获得我们完整的海浪浮标数据。如下:
完整代码
这里把完整可执行代码直接放上来,供大家学习使用。
import time
import requests
import os
from bs4 import BeautifulSoup
import re
import sys
# 下载文件函数
def download_file(url, save_path):
response = requests.get(url, stream=True) #发送GET请求以获取文件内容
with open(save_path, "wb") as file:
for chunk in response.iter_content(chunk_size=8192): #分块读取响应内容,每次读取8192字节的数据块
file.write(chunk)
print(f"Downloaded: {save_path}")
# 获取年份目录的页面
def get_year_urls(start_years, end_years):
response = requests.get(base_url)
soup = BeautifulSoup(response.text, "html.parser")
year_urls = []
# 查找页面中包含年份的目录链接
for link in soup.find_all("a"):
href = link.get("href")
if href and "/catalog.html" in href:
year_str = href.split("/")[0]
if year_str.isdigit() and 2017 <= int(year_str) <= 2019:
year_urls.append(f"https://thredds.met.no/thredds/catalog/obs/buoy-svv-e39/{year_str}/catalog.html")
return year_urls
# 获取每月数据页面的 URL 列表
def get_month_urls(year_url):
response = requests.get(year_url)
soup = BeautifulSoup(response.text, "html.parser")
month_urls = []
# 查找页面中的月份目录链接
for link in soup.find_all("a"):
href = link.get("href")
if href and "/catalog.html" in href:
month_urls.append(year_url.replace("catalog.html", href))
return month_urls
def get_nc_file_urls(month_url, number_buoy):
"""
Args:
month_url: 各个浮标的wave.nc文件链接
Returns:
file_urls: 文件链接
"""
response = requests.get(month_url)
soup = BeautifulSoup(response.text, "html.parser")
file_urls = []
# 查找所有Sulafjorden_wave.nc文件
for link in soup.find_all("a"):
href = link.get("href")
if href and ("wave.nc" in href) and (number_buoy in href) and ('raw' not in href):
dataset_url = month_url.replace("catalog.html", href)
dataset_page = requests.get(dataset_url)
dataset_soup = BeautifulSoup(dataset_page.text, "html.parser")
# 找到实际的下载链接
for a in dataset_soup.find_all("a"):
file_href = a.get("href")
if file_href and "fileServer" in file_href:
file_urls.append(f"https://thredds.met.no{file_href}")
return file_urls
# 主下载逻辑
def main_buoy(start_years, end_years):
# if not os.path.exists(path):
# os.makedirs(download_dir)
# 获取年份页面列表
year_urls = get_year_urls(start_years, end_years)
range_buoy_download = ['_A_','_B_', '_C_', '_D_', '_F_']
file_buoy = ['A', 'B', 'C', 'D', 'F']
for i in range(len(range_buoy_download)):
for year_url in year_urls:
# 获取每月页面列表
month_urls = get_month_urls(year_url)
for month_url in month_urls:
# 获取.nc文件的实际下载链接
file_urls = get_nc_file_urls(month_url, range_buoy_download[i]) #在这个地方打开的是所有浮标当月的数据
for file_url in file_urls:
file_name = os.path.join(download_dir, file_buoy[i], os.path.basename(file_url))
# 检查文件是否已下载
if not os.path.exists(file_name):
print(file_url)
download_file(file_url, file_name)
time.sleep(5) # 等待2秒再下载下一个文件,避免过多请求
else:
print(f"File already exists: {file_name}")
# 初始页面 URL 和下载目录
base_url = "https://thredds.met.no/thredds/catalog/obs/buoy-svv-e39/catalog.html"
download_dir = "./Dataset/buoy/"
if __name__ == "__main__":
start_years = 2017
end_years = 2019
main_buoy(start_years= start_years, end_years= end_years)
结语
本文依然是一个项目复现中的小知识节点,完整的项目复现会很快跟大家见面!
本文仅在个人学习过程中所写就,难免有错误与疏漏,请大家不吝赐教。
本文所下载数据仅作为科研用途,请勿恶意抓取数据!
如果这篇文章对你有所帮助,请点赞收藏!

技术共进,成长同行——讯飞AI开发者社区
更多推荐


 54
54 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)