
使用python从欧空局哥白尼数据中心(TheCopernicusDataSpaceEcosystem)网站上批量下载遥感数据(sentinel-1\sentinel-2\sentinel-3)
哥白尼官方指南中有详细描述如何依据遥感影像名称、数据列表、获取影像的日期、属性等创建一个url连接(简单地说就是,将筛选的条件按照哥白尼官方的规则写入url)注意:网站可能有访问量限制,如果需要大量下载影像,可以下载一段时间后,暂停2分钟(time.sleep(700) )后继续下载。(纬度 经度,纬度 经度,纬度 经度,纬度 经度,纬度 经度)在此步骤中,需要依据所需下载的遥感数据信息,构建一个
·
参考资料:
哥白尼网站:
APIs | Copernicus Data Space Ecosystem
官方数据下载指南:
https://documentation.dataspace.copernicus.eu/APIs/Token.html
需要准备的:
- 哥白尼网站的账号(用户名、密码)
使用python 下载影像代码:
步骤1:Access Token
需要哥白尼网站的账号、密码
def get_access_token(username: str, password: str) -> str:
data = {
"client_id": "cdse-public",
"username": UserName,
"password": Password,
"grant_type": "password",
}
try:
r = requests.post("https://identity.dataspace.copernicus.eu/auth/realms/CDSE/protocol/openid-connect/token",
data=data,
)
r.raise_for_status()
except Exception as e:
raise Exception(
f"Access token creation failed. Reponse from the server was: {r.json()}"
)
return r.json()["access_token"]
# 哥白尼网站账户
UserName = "********@gmail.com" #哥白尼网站用户名(邮箱)
Password = "*********" # 密码
access_token = get_access_token(UserName, Password)步骤2:构建数据搜索url(‼️重点)
在此步骤中,需要依据所需下载的遥感数据信息,构建一个url
1、官方指南
哥白尼官方指南中有详细描述如何依据遥感影像名称、数据列表、获取影像的日期、属性等创建一个url连接(简单地说就是,将筛选的条件按照哥白尼官方的规则写入url)
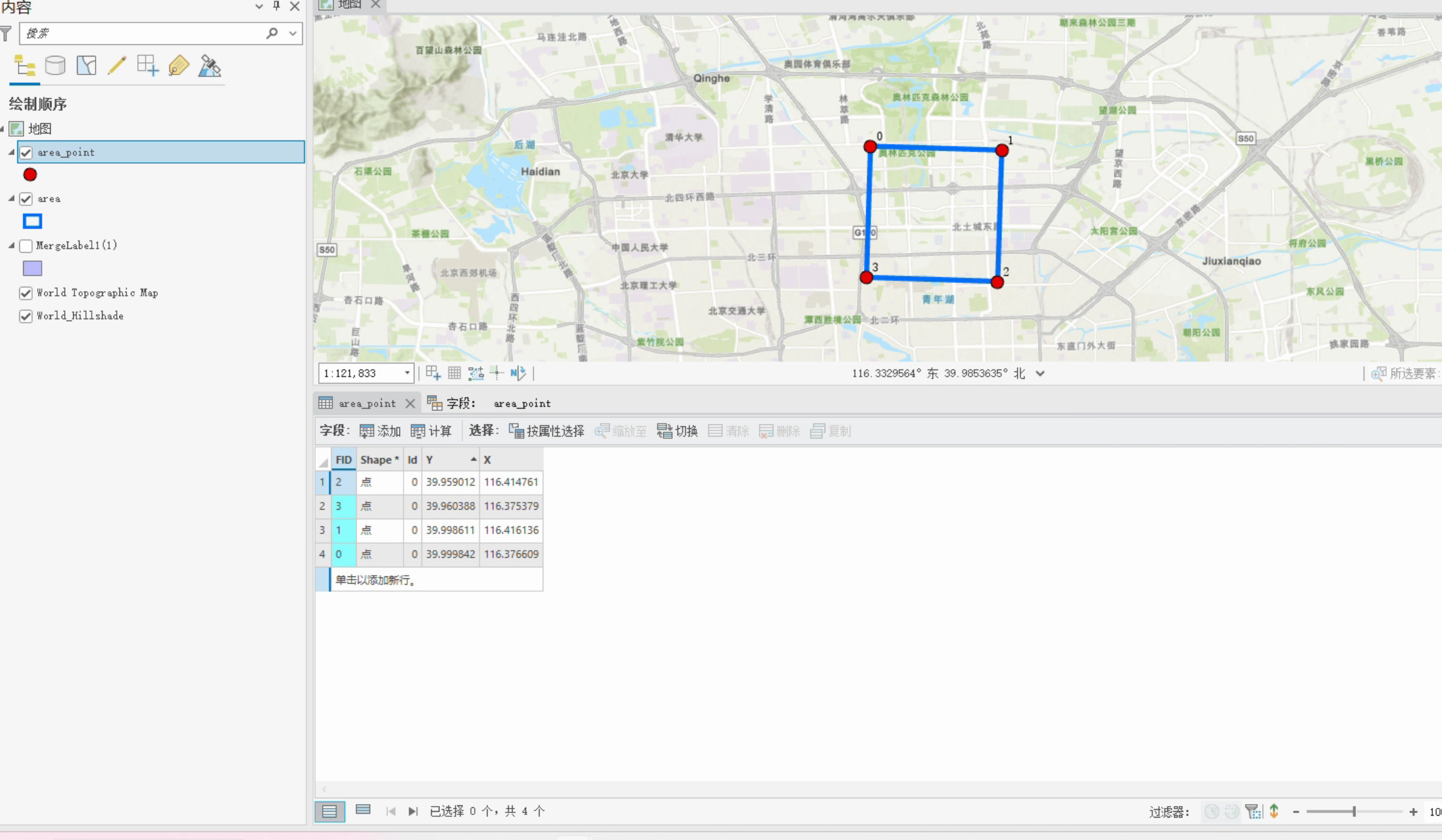
2、示例:以一个最常见的情况为例:(要求特定区域、特定时间、特定的影像数据集)
下载一个矢量(area.shp)区域内、2019年1月1日-12月31日内所有的sentinel-2 L2A数据
url1 = "https://catalogue.dataspace.copernicus.eu/odata/v1/Products?$filter=Collection/Name eq 'SENTINEL-2' and OData.CSC.Intersects(area=geography'SRID=4326;POLYGON((116.376609450000004 39.999842170000001,116.416136129999998 39.998611490000002,116.414760659999999 39.959012410000000,116.375378769999998 39.960387879999999,116.376609450000004 39.999842170000001))') and ContentDate/Start gt 2019-01-01T00:00:00.000Z and ContentDate/Start lt 2019-12-31T00:00:00.000Z and Attributes/OData.CSC.StringAttribute/any(att:att/Name eq 'productType' and att/OData.CSC.StringAttribute/Value eq 'S2MSI2A')&$top=1000"
1、红字——遥感卫星名称
2、篮字——矢量区域的坐标
- 在CGS_WGS_1984坐标系下的坐标
- 多边形定点的坐标,顺时针顺序,一圈(第一个和最后一个点一样)
- (顶点0,顶点1, 顶点2,顶点3, 顶点0)
- (经度 纬度,经度 纬度,经度 纬度,经度 纬度,经度 纬度)
 3、黄字——影像拍摄时间
3、黄字——影像拍摄时间
- 世界标准时间
4、紫字——影像产品名称的开头
- 如sentinel-2 的L2A产品数据均以S2MSI2A开头
5、绿字——影像数量
默认只搜索满足要求的前20个影像产品
top=1000:产品列表结果的前1000个数据
url1 = "https://catalogue.dataspace.copernicus.eu/odata/v1/Products?$filter=Collection/Name eq 'SENTINEL-2' and OData.CSC.Intersects(area=geography'SRID=4326;POLYGON((116.376609450000004 39.999842170000001,116.416136129999998 39.998611490000002,116.414760659999999 39.959012410000000,116.375378769999998 39.960387879999999,116.376609450000004 39.999842170000001))') and ContentDate/Start gt 2025-01-01T00:00:00.000Z and ContentDate/Start lt 2025-07-09T00:00:00.000Z and Attributes/OData.CSC.StringAttribute/any(att:att/Name eq 'productType' and att/OData.CSC.StringAttribute/Value eq 'S2MSI2A')&$top=1000"步骤3:按顺序下载影像
注意:网站可能有访问量限制,如果需要大量下载影像,可以下载一段时间后,暂停2分钟(time.sleep(700) )后继续下载
json = requests.get(url1).json()
df = pd.DataFrame.from_dict(json['value']) #获取待下载的影像列表
# 循环 ID 进行 下载
SitefolderPath = 'D://SENTINEL2' # 存放待下载影像的文件夹路经
for ImageID in range(df.shape[0]):
ID = df['Id'][ImageID]
Name = df['Name'][ImageID]
# 判断该影像是否已经下载成功
fileName_download = SitefolderPath + '/' + Name + '.zip'
if os.path.exists(fileName_download) == False:
"""
下载数据
"""
fileName_download = SitefolderPath + '/' + Name + '.zip'
try:
access_token = get_access_token(UserName, Password)
url_downloadLink = f"https://zipper.dataspace.copernicus.eu/odata/v1/Products(" + ID + ")/$value"
headers = {"Authorization": f"Bearer {access_token}"}
session = requests.Session()
session.headers.update(headers)
response = session.get(url_downloadLink, headers=headers, stream=True)
with open(fileName_download, "wb") as file:
for chunk in response.iter_content(chunk_size=8192):
if chunk:
file.write(chunk)
print(f" {ImageID}/{df.shape[0]}, {Name}")
except Exception as e:
print(f" {ImageID}/{df.shape[0]}, {Name}, download Error and wait")
print("--waitting for 7 min - ---", time.strftime(" %Y -%m- %d %H:%M:%S", time.localtime()))
#time.sleep(700) # 有访问限制,如果需要大量下载影像,可以下载一段时间后,暂停2分钟
else:
print(f"{ImageID}/{df.shape[0]}, {Name}, is already exist")完整代码:
import requests
import pandas as pd
import os
import time
UserName = "********@gmail.com"
Password = "********"
def get_access_token(username: str, password: str) -> str:
data = {
"client_id": "cdse-public",
"username": UserName,
"password": Password,
"grant_type": "password",
}
try:
r = requests.post("https://identity.dataspace.copernicus.eu/auth/realms/CDSE/protocol/openid-connect/token",
data=data,
)
r.raise_for_status()
except Exception as e:
raise Exception(
f"Access token creation failed. Reponse from the server was: {r.json()}"
)
return r.json()["access_token"]
access_token = get_access_token(UserName, Password)
url1 = "https://catalogue.dataspace.copernicus.eu/odata/v1/Products?$filter=Collection/Name eq 'SENTINEL-2' and OData.CSC.Intersects(area=geography'SRID=4326;POLYGON((85.59368903234216 28.45399959387374,85.69426481777356 28.44154215786701,85.67779208779949 28.33785843326445,85.57731227280733 28.35030389114404,85.59368903234216 28.45399959387374))') and ContentDate/Start gt 2025-01-01T00:00:00.000Z and ContentDate/Start lt 2025-07-09T00:00:00.000Z and Attributes/OData.CSC.StringAttribute/any(att:att/Name eq 'productType' and att/OData.CSC.StringAttribute/Value eq 'S2MSI2A')&$top=1000"
json = requests.get(url1).json()
df = pd.DataFrame.from_dict(json['value'])
# 循环 ID 进行 下载
SitefolderPath = 'D://SENTINEL2' # 存放待下载影像的文件夹路经
for ImageID in range(df.shape[0]):
ID = df['Id'][ImageID]
Name = df['Name'][ImageID]
# 判断该影像是否已经下载成功
fileName_download = SitefolderPath + '/' + Name + '.zip'
if os.path.exists(fileName_download) == False:
"""
下载数据
"""
fileName_download = SitefolderPath + '/' + Name + '.zip'
try:
access_token = get_access_token(UserName, Password)
url_downloadLink = f"https://zipper.dataspace.copernicus.eu/odata/v1/Products(" + ID + ")/$value"
headers = {"Authorization": f"Bearer {access_token}"}
session = requests.Session()
session.headers.update(headers)
response = session.get(url_downloadLink, headers=headers, stream=True)
with open(fileName_download, "wb") as file:
for chunk in response.iter_content(chunk_size=8192):
if chunk:
file.write(chunk)
print(f" {ImageID}/{df.shape[0]}, {Name}")
except Exception as e:
print(f" {ImageID}/{df.shape[0]}, {Name}, download Error and wait")
print("--waitting for 7 min - ---", time.strftime(" %Y -%m- %d %H:%M:%S", time.localtime()))
#time.sleep(700) # 有访问限制,如果需要大量下载影像,可以下载一段时间后,暂停2分钟
else:
print(f"{ImageID}/{df.shape[0]}, {Name}, is already exist")

技术共进,成长同行——讯飞AI开发者社区
更多推荐


 24
24 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)