
【python学习】beautifulsoup4的安装、定义、特点、功能和代码示例并进行解释
beautifulsoup4提供了一个简单易用的API来导航、搜索和修改解析树
·
引言
BeautifulSoup是一个用于解析HTML和XML文档的Python库。它最初由Leonard Richardson开发,现在是由社区维护。BeautifulSoup将复杂的文档结构转换成一个树形结构,方便用户进行遍历和搜索
文章目录
一、安装beautifulsoup4库
可以通过以下命令安装BeautifulSoup4:
pip install beautifulsoup4
通常还需要安装一个解析器,如lxml或html5lib:
pip install lxml
# 或者
pip install html5lib
若是在pycharm中,操作如下图所示(lxml或html5lib操作类似):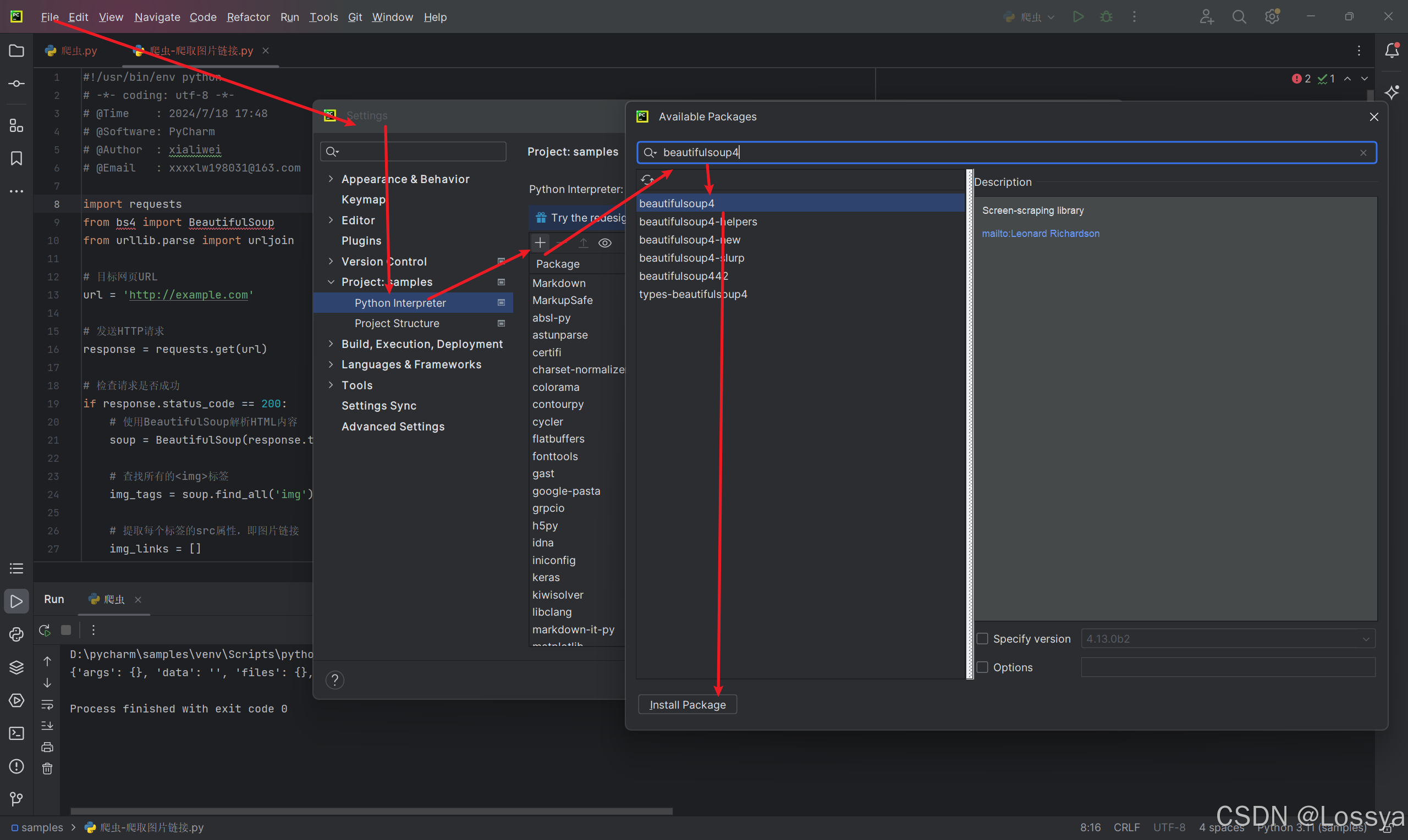
二、beautifulsoup4的定义
BeautifulSoup是构建在lxml和html.parser之上的一个库,它提供了一个简单易用的API来导航、搜索和修改解析树。BeautifulSoup4是该库的第四个主要版本,通常简称为BeautifulSoup
三、beautifulsoup4的特点
3.1 简单易用
BeautifulSoup提供了简洁的API,使得提取数据变得非常简单
3.2 灵活性
支持多种解析器,如lxml和html.parser,可以根据需求选择合适的解析器
3.3 容错性
即使文档格式不正确,BeautifulSoup也能很好地解析
强大的搜索功能
提供了丰富的搜索方法,如通过标签名、属性、CSS类等
四、beautifulsoup4的功能
4.1 解析HTML和XML文档
4.2 提供方法遍历和搜索解析树
4.3 支持修改文档内容
4.4 支持从文档中提取数据
五、beautifulsoup4的代码示例
5.1 代码
以下是一个简单的
BeautifulSoup示例,它解析HTML文档,并打印出文档的结构和内容:
# 导入BeautifulSoup库
from bs4 import BeautifulSoup
# 定义HTML文档字符串
html_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="soup" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
# 创建BeautifulSoup对象,传入HTML文档字符串和解析器(这里使用'lxml')
soup = BeautifulSoup(html_doc, 'lxml')
# 打印BeautifulSoup对象的美化后的HTML代码
print(soup.prettify())
# 找到title标签
print(soup.title)
# title标签里的内容
print(soup.title.string)
# 找到p标签
print(soup.p)
# 找到p标签class的名字
print(soup.p['class'])
# 找到第一个a标签
print(soup.a)
# 找到所有的a标签
print(soup.find_all('a'))
# 找到id为link3的标签
print(soup.find(id="link3"))
# 找到所有<a>标签的链接
for link in soup.find_all('a'):
print(link.get('href'))
# 找到文档中所有的文本内容
print(soup.get_text())
5.2 代码解释
from bs4 import BeautifulSoup: 导入BeautifulSoup模块html_doc = """...""": 定义了一个HTML文档字符串soup = BeautifulSoup(html_doc, 'lxml'): 创建一个BeautifulSoup对象,传入HTML文档字符串和解析器(这里使用’lxml’)print(soup.prettify()): 打印BeautifulSoup对象的美化后的HTML代码print(soup.title): 打印title标签print(soup.title.string): 打印title标签里的内容print(soup.p): 打印第一个p标签print(soup.p['class']): 打印p标签class的名字print(soup.a): 打印第一个a标签print(soup.find_all('a')): 打印所有的a标签print(soup.find(id="link3")): 打印id为link3的标签for link in soup.find_all('a'):: 遍历所有的a标签print(link.get('href')): 打印每个a标签的href属性值print(soup.get_text()): 打印文档中所有的文本内容
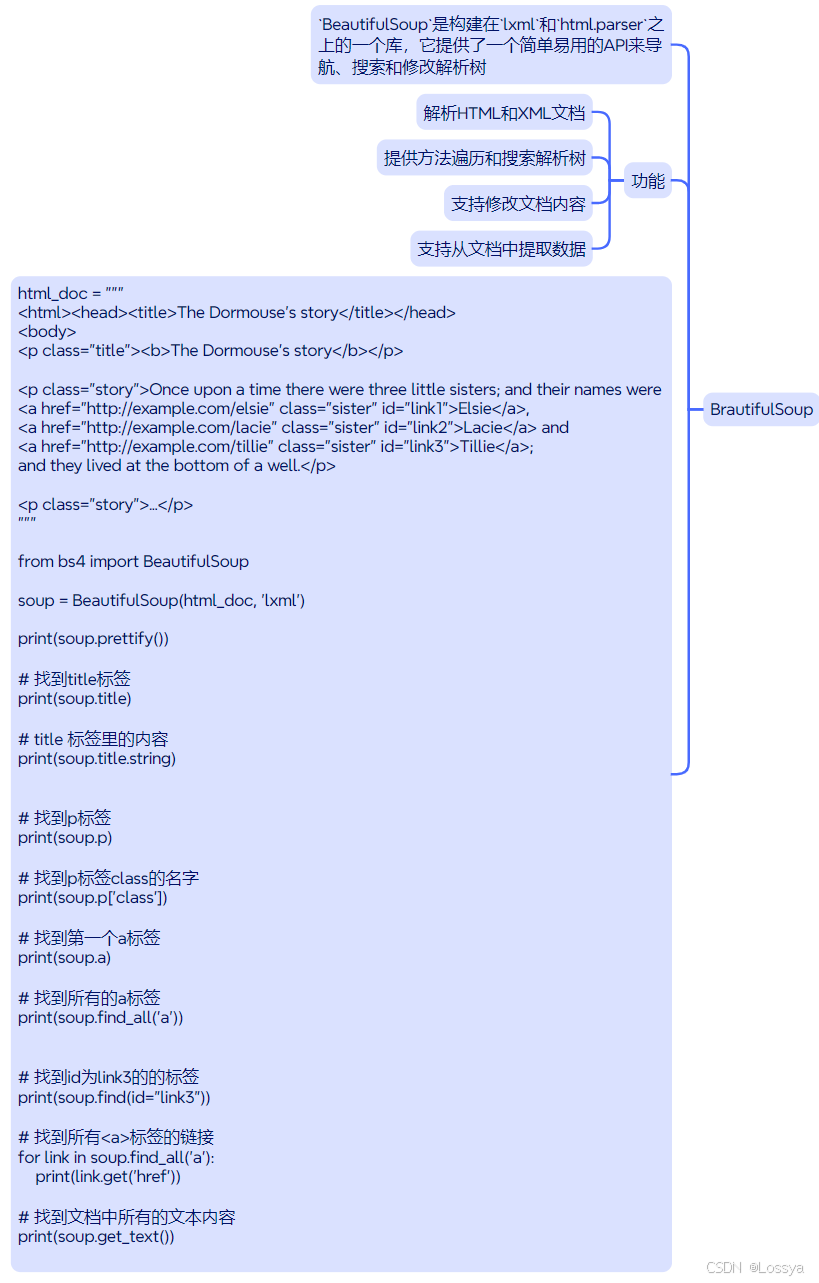
六、总结(思维导图)

技术共进,成长同行——讯飞AI开发者社区
更多推荐
 28
28 0
0- 0



 已为社区贡献39条内容
已为社区贡献39条内容

所有评论(0)