
Apache DolphinScheduler保姆级实操指南:云原生任务调度实战
DolphinScheduler正成为大数据调度领域的事实标准,其云原生架构和操作友好的界面,让开发者从繁琐的流程管控中解放出来。建议初学者从本文示例出发,逐步探索其跨集群任务分发、K8s集成等高级能力。相关阅读DolphinScheduler 3.0源码解析海豚调度 vs Apache Oozie性能压测。
·
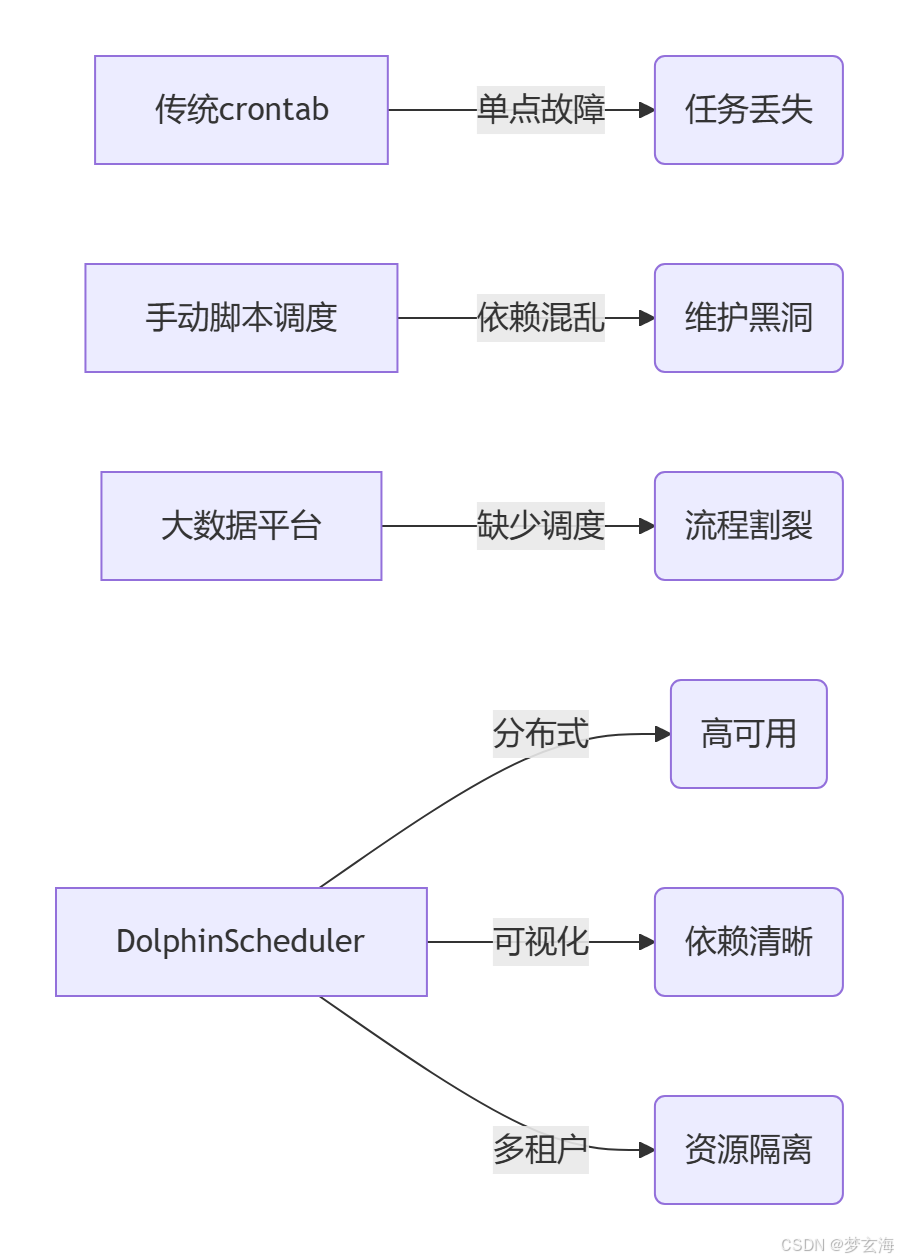
为什么需要DolphinScheduler?
(解决小白认知痛点)
二、3分钟极速部署(小白友好版)
环境准备
bash
# 最低配置(开发环境)
JDK 8+
MySQL 5.7+
Zookeeper 3.8+Docker一键启动(避坑推荐)
docker
docker run -d --name dolphinscheduler \
-e DATABASE_TYPE=mysql \
-e SPRING_DATASOURCE_URL="jdbc:mysql://localhost:3306/ds?useUnicode=true&characterEncoding=UTF-8" \
-e SPRING_DATASOURCE_USERNAME=root \
-p 12345:12345 \
apache/dolphinscheduler:3.2.0三、核心概念可视化解析
| 术语 | 类比现实 | 技术定义 |
|---|---|---|
| 工作流(Workflow) | 工厂生产线 | DAG任务集合 |
| 任务节点(Task) | 生产工序 | Shell/SQL/Spark等执行单元 |
| 实例(Instance) | 当日生产批次 | 工作流的具体运行实例 |
| 警报组(Alert) | 工厂广播系统 | 失败报警渠道配置 |
四、手把手创建第一个工作流(含代码段)
场景:每日用户行为分析
-
步骤1:登录控制台
http://localhost:12345/dolphinscheduler(默认账号admin/dolphinscheduler123) -
步骤2:创建工作流
-
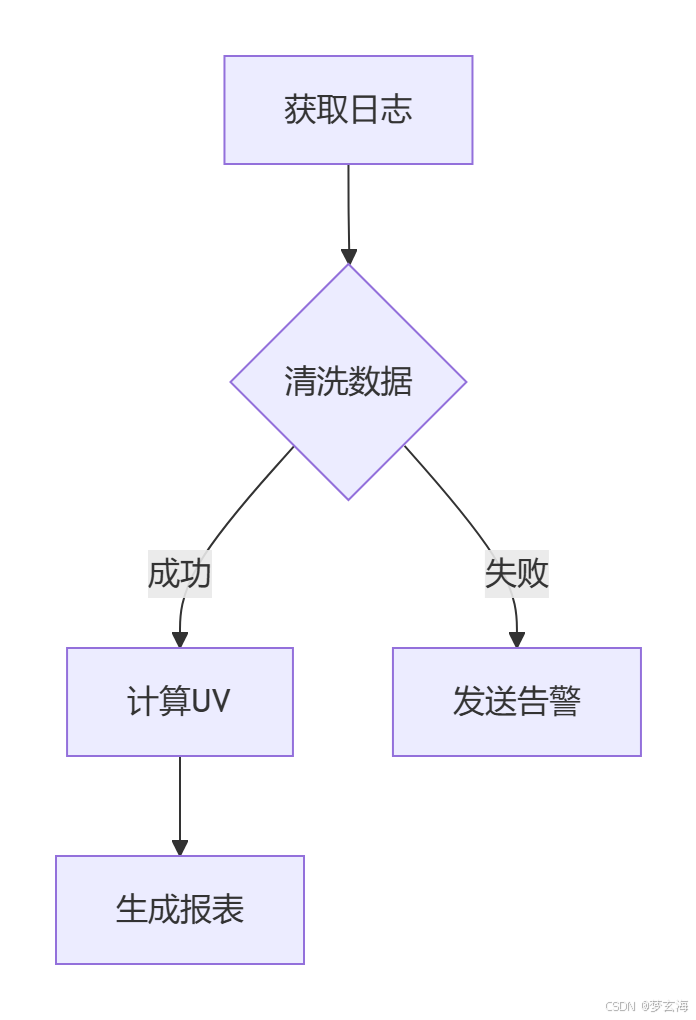 步骤3:配置Shell任务(关键代码)
步骤3:配置Shell任务(关键代码)
shell
#!/bin/bash
# 参数自动注入示例
spark-submit \
--master yarn \
--name behavior_analysis_${sys_date} \ # 系统动态参数
/opt/jobs/user_analysis.py ${begin_date} ${end_date}- 步骤4:设置调度策略
cron
0 2 * * * # 每天凌晨2点执行(支持Quartz表达式)五、高级特性解锁(小白也能用)
- 参数透传(跨任务传值)
python
# 在Python节点中获取上游输出
context.getUpstreamOutParam('uv_count') - 失败自动重试
yaml
# workflow定义片段
task_retry_interval: 300 # 5分钟重试
retry_times: 3 # 最多重试3次- 条件分支(动态路由)
shell
# 根据日期判断是否周末
if [ ${week} -gt 5 ]; then
echo "skip weekend processing"
exit 0
fi六、避坑指南(来自生产实践)
- 资源错配:Spark任务内存溢出 → 在
conf/worker.properties调整:
properties
worker.worker.task.resource.limit=true
worker.worker.task.memory.max=8g # 根据集群配置调整- 时区陷阱:定时任务延迟8小时 → 修改
common.properties:
properties
spring.jackson.time-zone=GMT+8 七、效能对比(说服力数据)
| 指标 | Crontab | Airflow | DolphinScheduler |
|---|---|---|---|
| 可视化程度 | ❌ | ⭐⭐⭐ | ⭐⭐⭐⭐ |
| 高可用部署 | ❌ | ⭐⭐ | ⭐⭐⭐⭐ |
| 大数据集成度 | ⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
| 学习曲线 | ⭐⭐⭐⭐ | ⭐⭐ | ⭐⭐⭐ |
结语
“DolphinScheduler正成为大数据调度领域的事实标准,其云原生架构和操作友好的界面,让开发者从繁琐的流程管控中解放出来。建议初学者从本文示例出发,逐步探索其跨集群任务分发、K8s集成等高级能力。”
相关阅读
- DolphinScheduler 3.0源码解析
- 海豚调度 vs Apache Oozie性能压测

技术共进,成长同行——讯飞AI开发者社区
更多推荐



 8
8 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)