
运用谷歌浏览器的开发者工具,模拟搜索引擎蜘蛛抓取网页
运用谷歌浏览器的开发者工具,模拟搜索引擎蜘蛛抓取网页
·
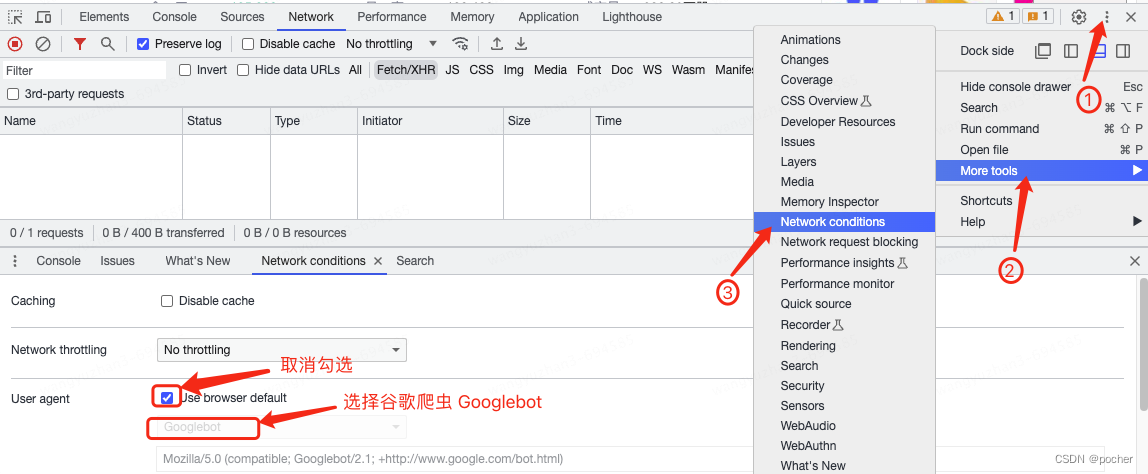
第一步:按压键盘上的F12键打开开发这工具,并点击右上角三个小黑点
第二步:选择More tools
第三步:选择Network conditions
第四步:找到User agent一列,取消复选框的勾选
第五步:选择谷歌爬虫agent即Googlebot
第六步:在当前浏览器地址栏中,输入想要访问的网站地址,直接访问。返回的页面就是爬虫看到的页面。

技术共进,成长同行——讯飞AI开发者社区
更多推荐


 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)