
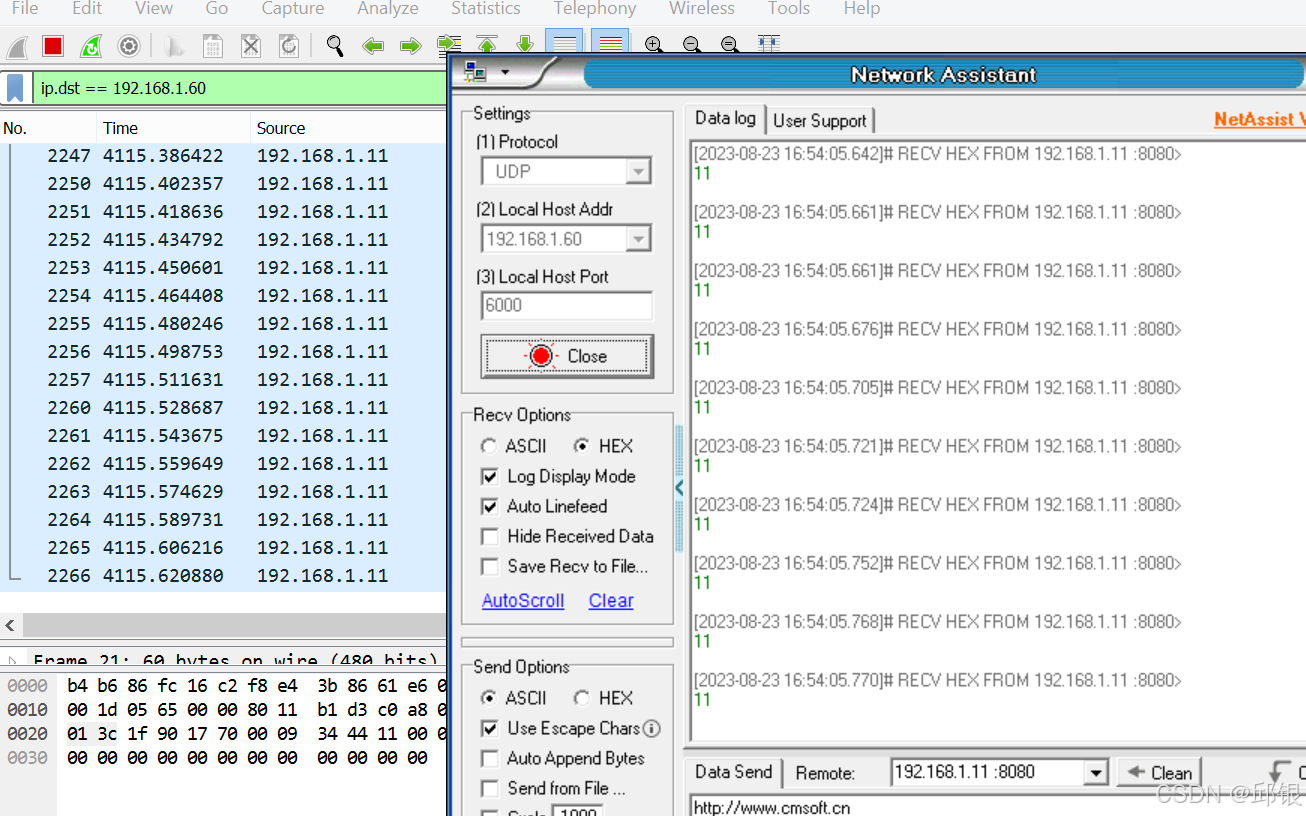
88Q5152 TSN功能测试
按照5152的queue设计原理,若采用strict priority调度,优先级较高的报文可以无限抢占低优先级的queue的发送,最严重的情况是有可能导致低优先级的报文无法发送,Weighted round robin在一定程度上解决了低优先级queue饿死的问题。5152为每个Port的每一个queue都提供了一个速率(rate)的设置寄存器,可以通过设置该寄存器来限制端口的egress的速率
1. Qav
5152为每个Port的每一个queue都提供了一个速率(rate)的设置寄存器,可以通过设置该寄存器来限制端口的egress的速率。
5152没有为Qav属性设计类似sendSlope和idleSlope这些属性,转而直接为每一个Queue设计了QueuePri_Rate寄存器,
按照5152的queue设计原理,若采用strict priority调度,优先级较高的报文可以无限抢占低优先级的queue的发送,最严重的情况是有可能导致低优先级的报文无法发送,Weighted round robin在一定程度上解决了低优先级queue饿死的问题。
1.1. 以下针对默认的queue0验证下switch的Qav功能。
在switch一端通过iperf按照100M的速率发送报文,如下图所示:
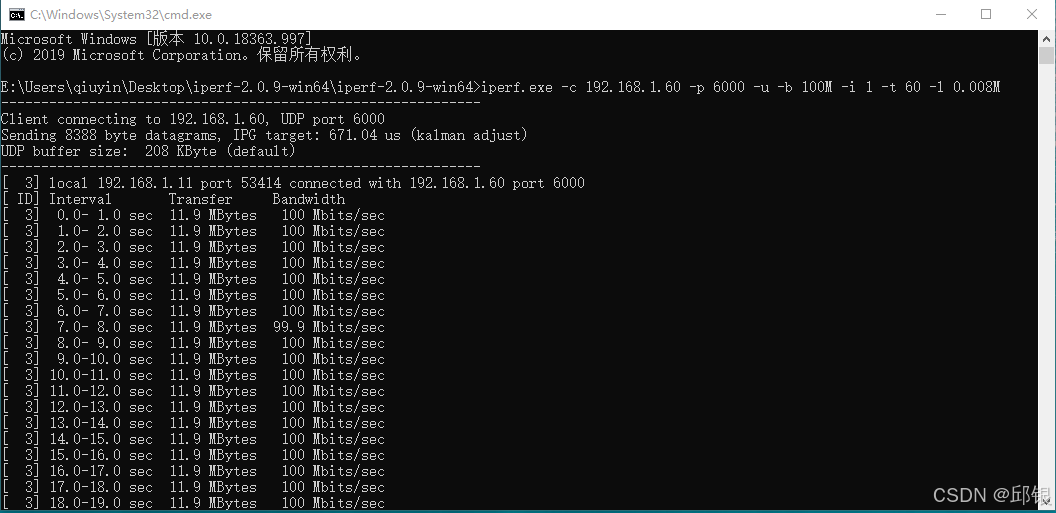
- 若不开启Qav功能,Port口输出的速率如下图所示:
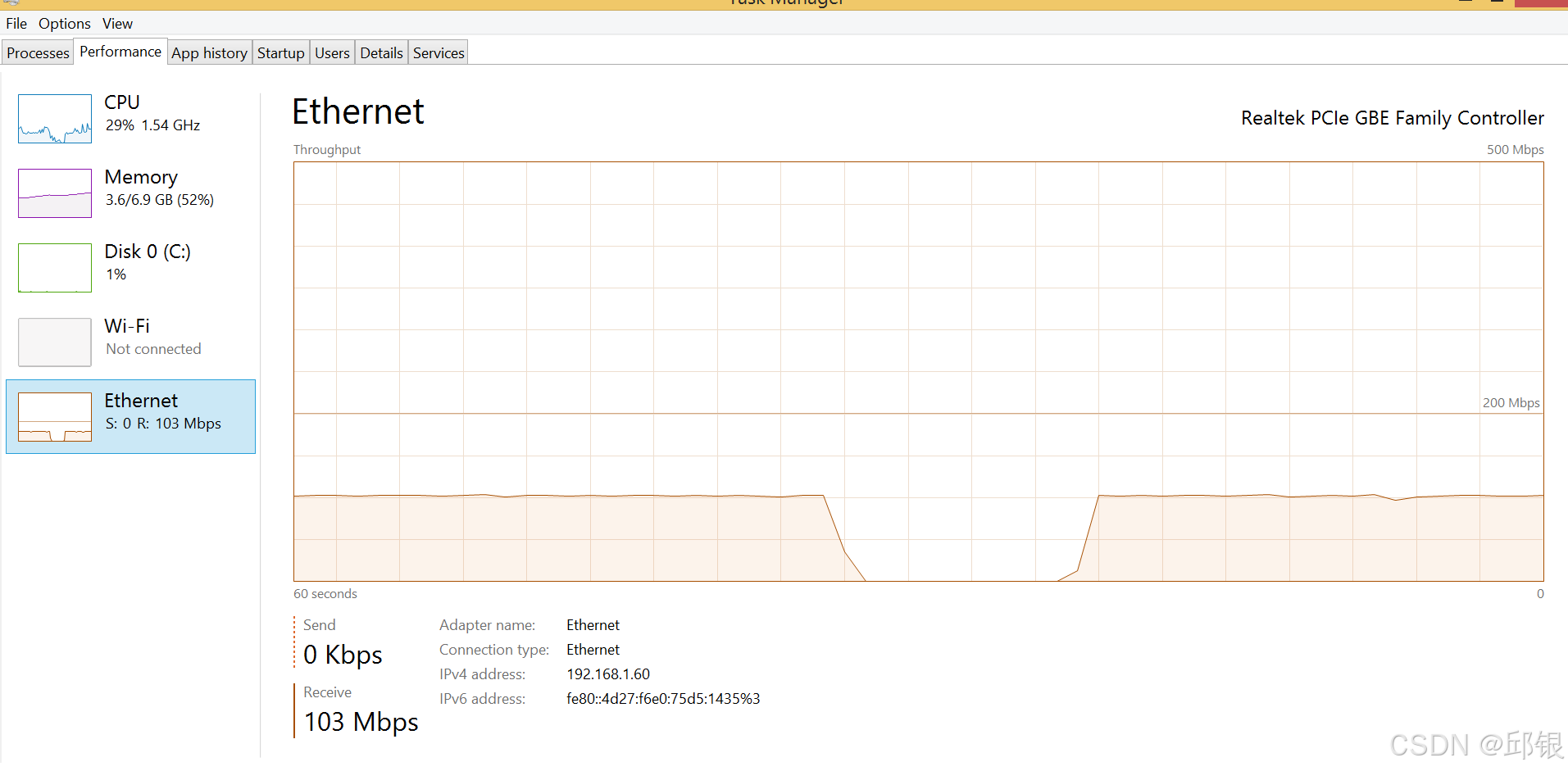
- 若打开Qav,同时设置该Port的queue0的速率限制值为64M,再观察Port口的输出速率:
1.2. 8个queue同时转发数据时:
2.Qbv
如果switch的egress端口不设置门控列表,在switch收到数据后,就会直接转发到目标端口,转发的速率应该是尽力而为;如果针对的是一些实时性要求较高的报文,这里的尽力而为就会与时延要求相冲突或者说到达时间不可控。
如果在5152的egress端加上门控列表,设置Port(x)口egress的开关周期:当Port(x) Egress端为Close时,从其他Port(y)口收进来的frame会缓存到Port(x)Egress queue中,但是不会从Port(x)的MAC端发出去;若Port(x)的Egress queue设置为open,那么egress queue中的frame就会在这段open的时间内将报文全部发出去,直到queue为close。从表象上看,发出去的同一优先级的报文将变得周期性。
switch端实现机制:
5152的每一个Port都分配了8个egress queue,同时每一个egress queue与PCP相绑定,例如优先级为0的frame分配到queue0,优先级为1 的frame分配到queue1。
在5152内部为某一个Port的某一个Queue设定一个周期(cycle Period),假设为100ms,同时设置Port的queue0的open时间为200us,剩下的时间为close状态。之后使能Qbv功能:
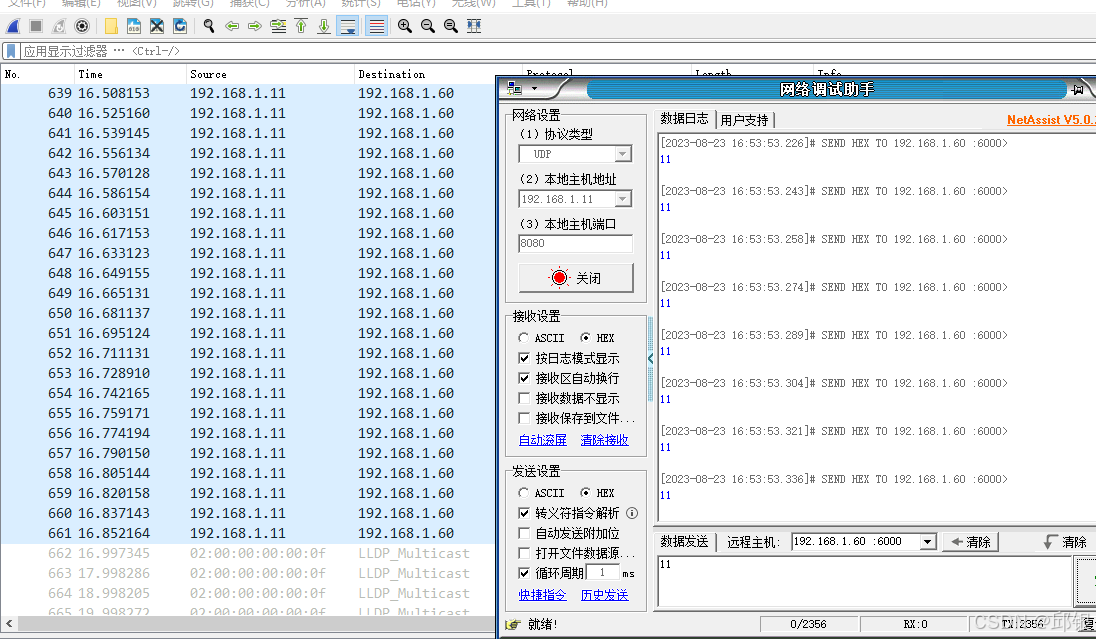
上图是PC在switch的Port1口以1ms为周期的发送,考虑到网卡的转发效率,实际的发送周期大概是15ms。
下图是没有打开Qbv功能时,switch的转发到Port8时候的报文,可以看出报文的转发间隔与ingress的大体接近:
如下图所示:若使能Qbv功能,报文严格按照100ms的周期进行转发,且只在周期内的open状态下才有数据发出,一旦queue处于close,那么报文将pending在egress queue里。
2.1. YANG模型解析:
利用开源的tinyXML2进行xml文件的解析,将RTAW生成的YANG模型中的门控列表信息转化成88Q5152的cfg.c文件,参与编译。
目前尝试主要解析的是门控列表等信息:
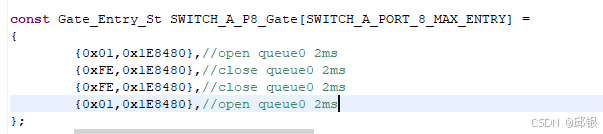
2.1.1. 按照switch手册,每个queue state的持续状态不能超2.048ms,且每个Port的Queue state个数不超过16个;
将配置文件设置成如下参数:
实际在Port8接收到的frame如下图所示:
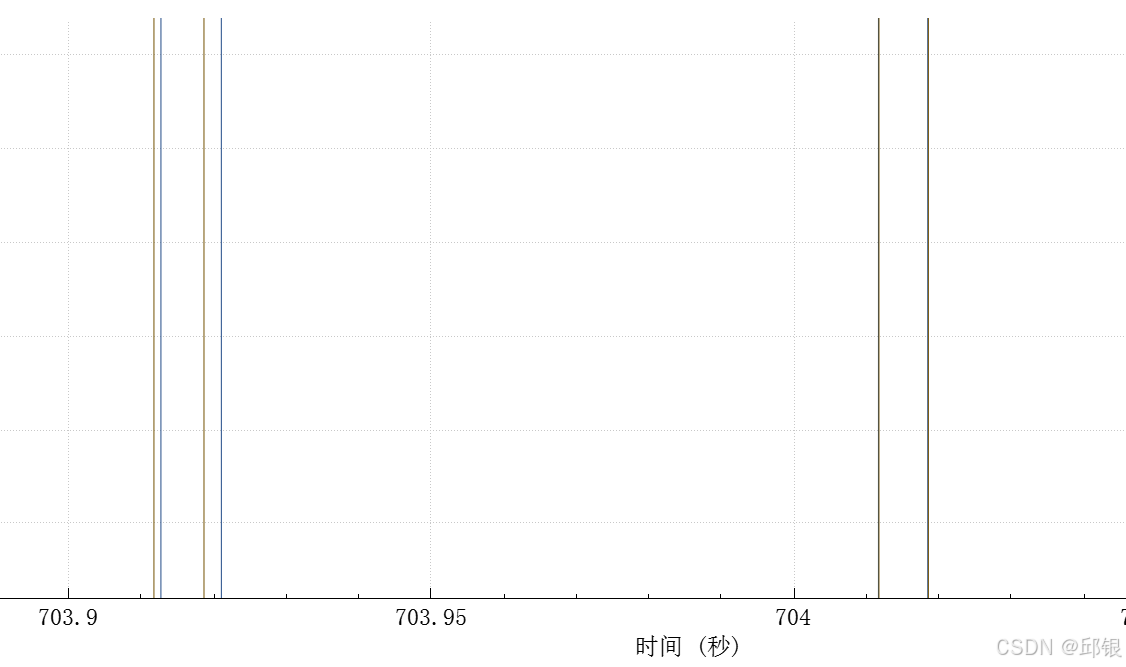
可以明显看出frame的间隔在100ms,且在703.9s处有4组报文(每一条竖轴代表一个Queue state下的frame,目前发送了2个vlanId的报文,),目前无法精确测量出Queue state的持续时间。
2.3 保护带:
为了防止一个queue里的数据在queue close之前还未发送完成,继而影响一个queue中数据的发送(如果下一个queue中的数据优先级较高,那么就会造成成低优先级的数据延迟了高优先级数据的发送),为了防止该现象的发生,Qbv提出了保护带机制。即当落入GB(保护带)区间,该Queue不允许再发送新的frame,已经在MAC上发送的数据允许发完。——可以预见,GB的长度可以在64~1522之间进行选择,当然会造成一定的带宽浪费。
3. gPTP:
https://zhuanlan.zhihu.com/p/448643557
https://zhuanlan.zhihu.com/p/297977065
4. Qci:Per-Stream Filtering and Policing
https://zhuanlan.zhihu.com/p/428863852
4.1 流过滤功能验证:
4.1.1 TCAM
这里的流过滤功能首先借助了TCAM模块,即TCAM模块首先对ingress的报文进行了捕获以及校验,一旦ingress的报文跟TCAM Entry中设置的条件相匹配(比如Dest MAC Addr一样),那么TCAM就会对该frame做进一步的处理(转发到其它设定的Port,而非原先MAC地址映射的PORT;;或者丢弃该报文;或者转给switch内部其他模块处理):针对Qci流过滤,TCAM一旦侦测到ingress frame符合匹配条件,则TCAM会启动Stream Filter instance(Stream FilterEn = 1)
4.1.2. Stream Filter:
Switch的Qci(PSFP)里面也分了几个小的components:STREAM FILTER;STREAM GATE;STREAM GATE TIME GEN;STREAM_METER等,这里先介绍STREAM FILTER:
一旦使能了Stream Filter,当发送的报文超过了MaxSDUSize(最大数据服务单元),Switch就会丢弃该报文:
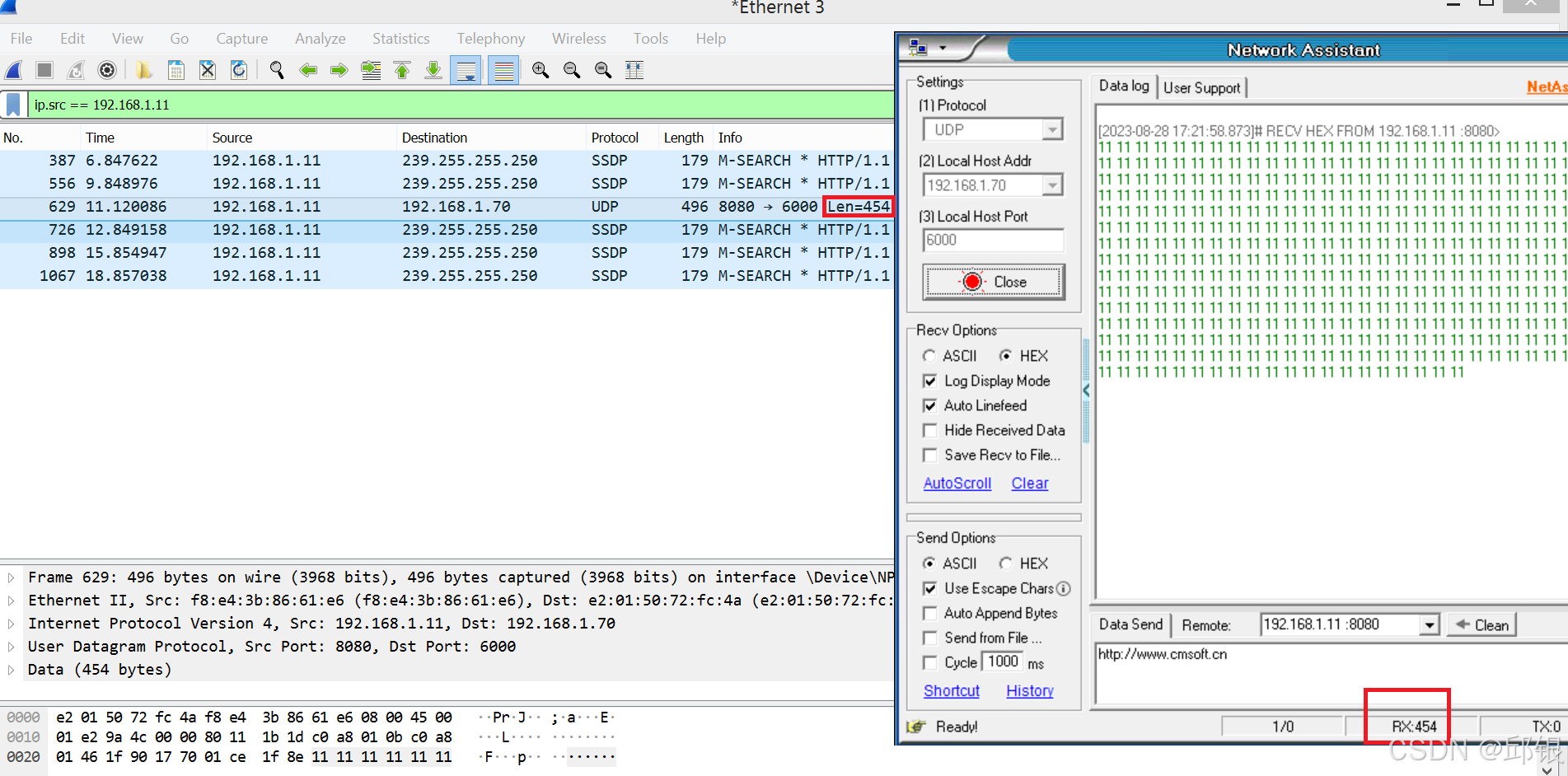
设置MaxSDUSize = 500进行验证,由于MaxSDUSize包括了CRC,所以实际的frame长度为496bytes,一旦udp报文长度超过454(496-14-20-8),则switch丢弃该报文:
i. 若发送的字节长度是454:
发送端:
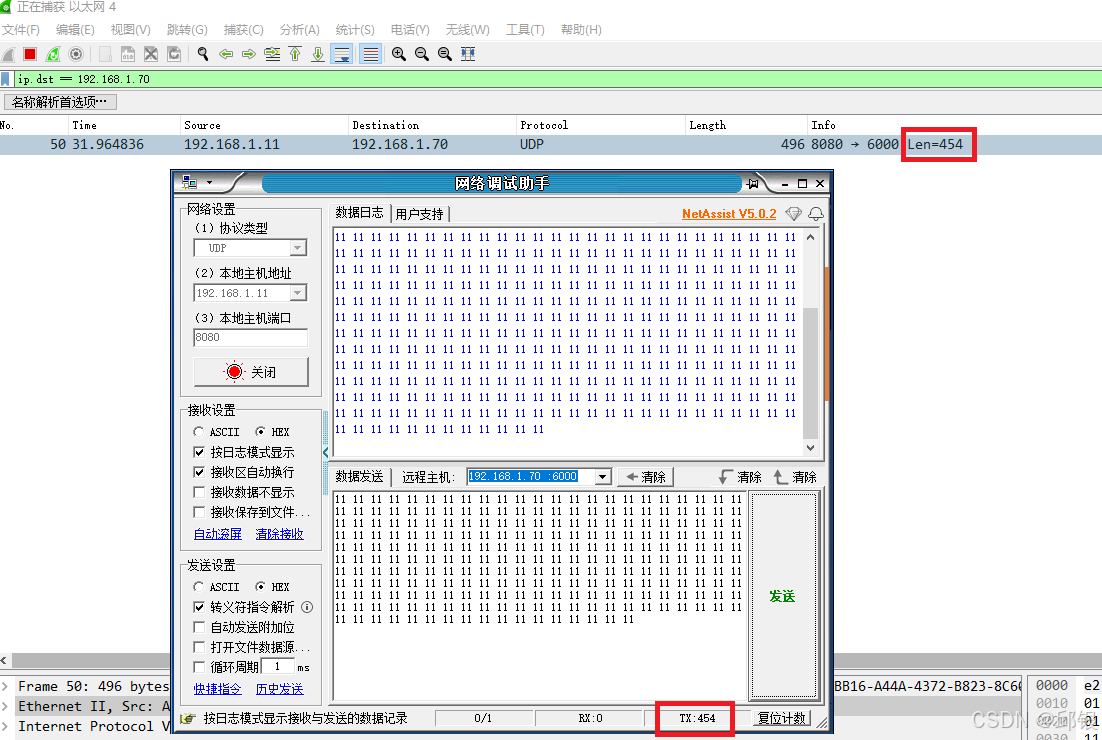
接收端:
-
ii. 若发送的数据长度为455:
发送端:
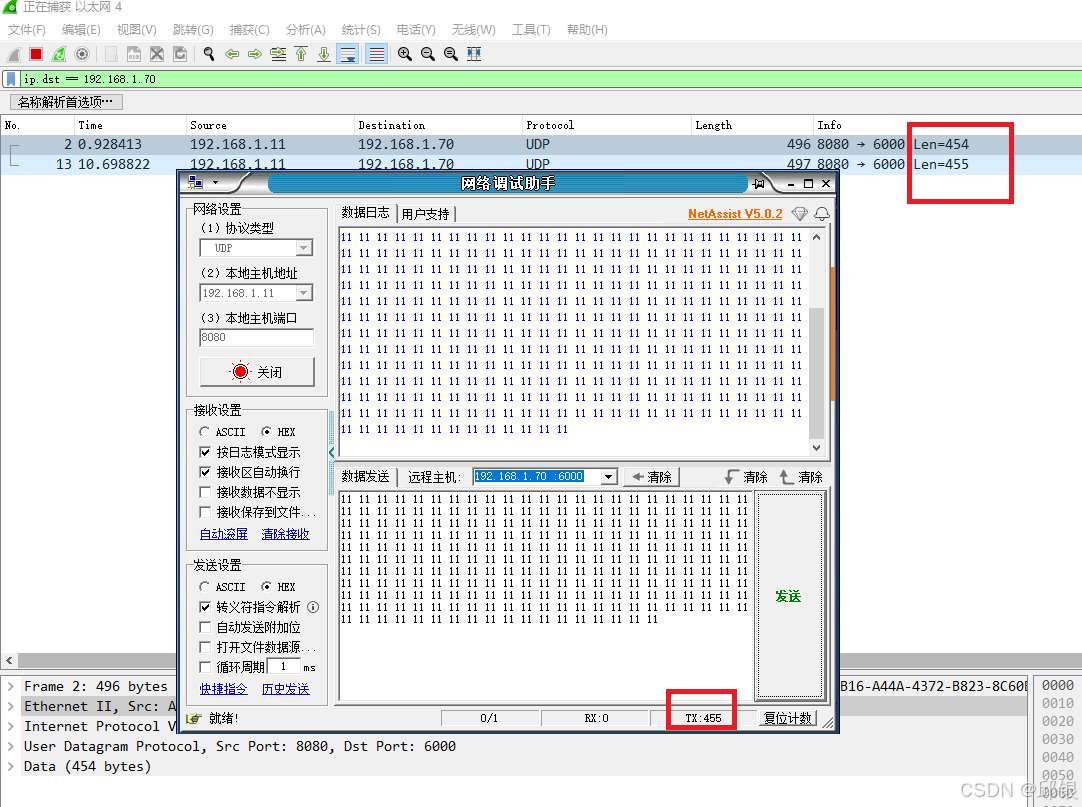
接收端:
如下图所示:接受端没有收到发来的455字节报文。
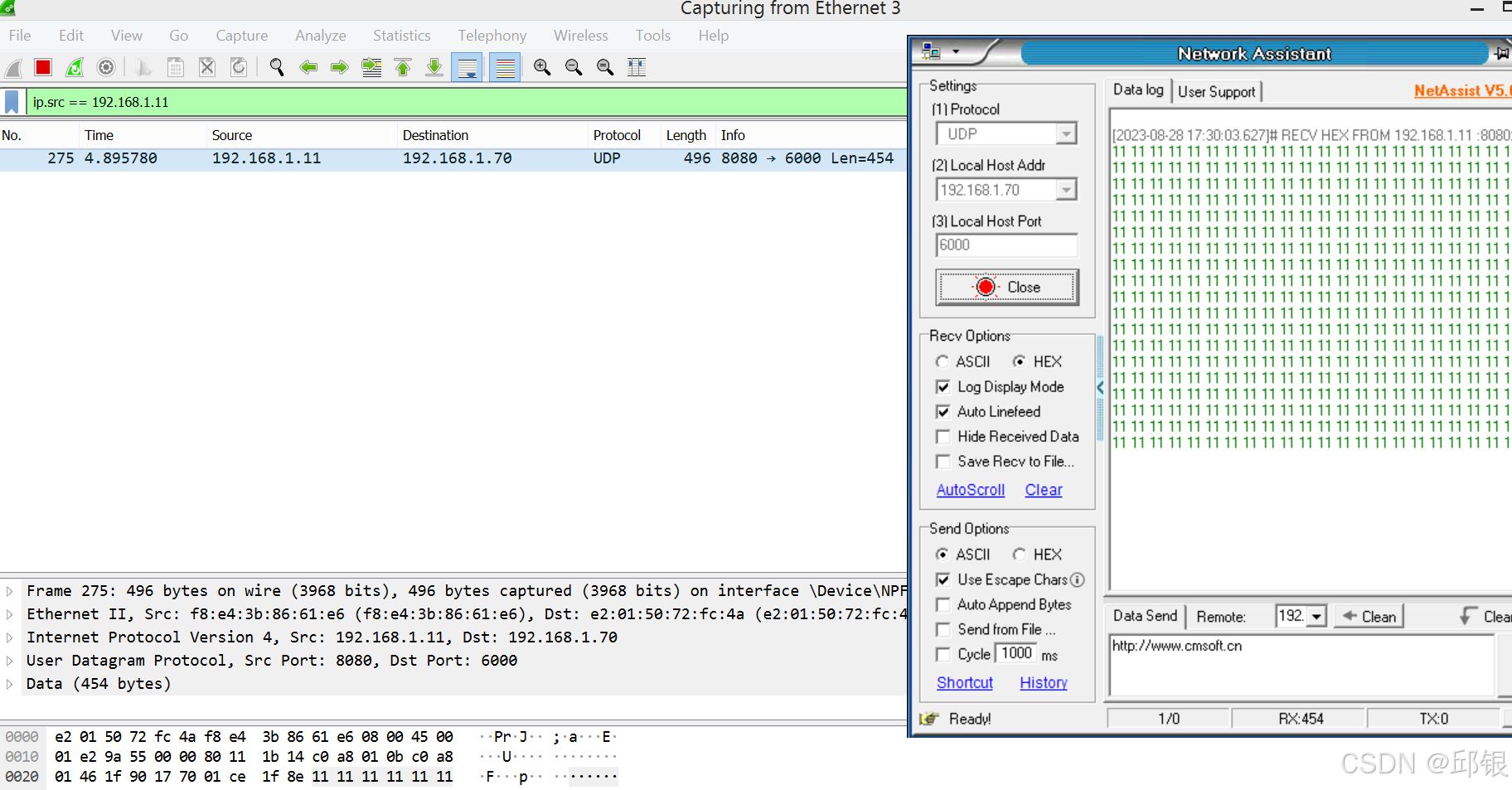
可以看出stream filter按照MaxSDUSize对数据进行了过滤。这里类似于实现了知乎上那篇文章中提到的“阻断”。
4.1.3. switch中丢弃的frame字节数:
在遇到发送的报文因为MaxSDUSize限制而被过滤掉的情况时,switch会在寄存器中存储被滤掉的报文的数目——StreamFilterFilteredFrames。通过测试发现,这里的计数是以frame为单位的。
同时通用的normal Statistics Counter也会将过滤掉的报文数目记录下来,我们可以理解为StreamFilterFilteredFrames是Qci专属的记录filtered counter的模块,而normal Statistics Counter是通用的为每一个Port口而设计的计数器。
如下图所示,当用助手发送了4帧 456 bytes frame后,counter的计数情况如下图所示:
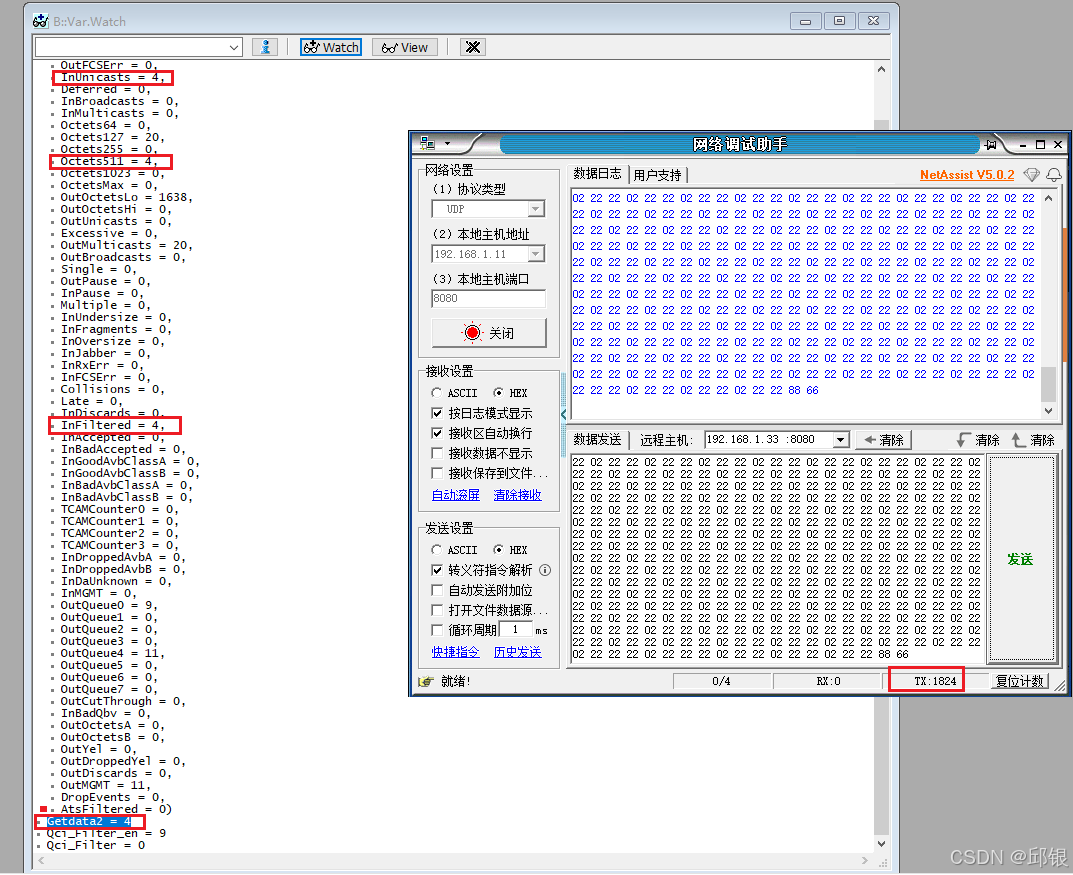
其中Getdata2是从Qci中来获取的,上面的一串是从normal Statistics Counter中来的,normal Statistics Counter获取到的信息会更详细点。
注:这里发现Qci有个设置不合理的地方,估计是芯片bug:就是不管驱动是否使能OverSizeBlockEn,只要设置了MAXSDUSize,那么这部分功能就会起作用。
4.2. Stream Gate:
//
4.3. STREAM_METER:
stream meter也是利用了TCAM来监控,也是针对特定信息的报文进行监控(比如frame的目的MAC地址与TCAM中指定的MAC地址一致),与4.1不一样的地方在于:这里会打开TCAM的FlowMeter功能——那么一旦被TCAM所识别到的流就会被Flow Meter所处理。
这里的Flow Meter也就相当于知乎上那篇文章中的“限流”,switch针对某一个port的某一个类型的frame进行了带宽限制,一旦超过了某个带宽,switch就会在入口处进行限流。——这里存在丢包的可能性。
stream meter利用了令牌桶原理,将流经的报文分为Green(通过)、Yellow(警告)、Red(丢弃)
4.3.1. 测试验证:
通过iperf工具向Port1中发送带宽为100M的frame,在Port8接收,同时设置Port8的网卡地址为TCAM中指定的MAC Addr。设置FlowMeter的带宽为10M。
发送端:
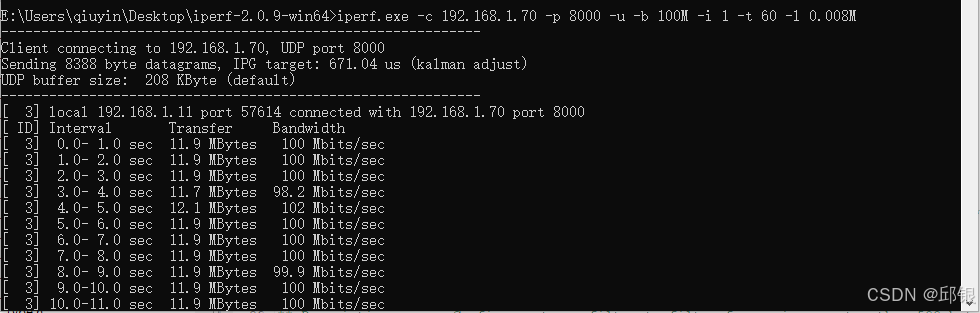
-
接收端:
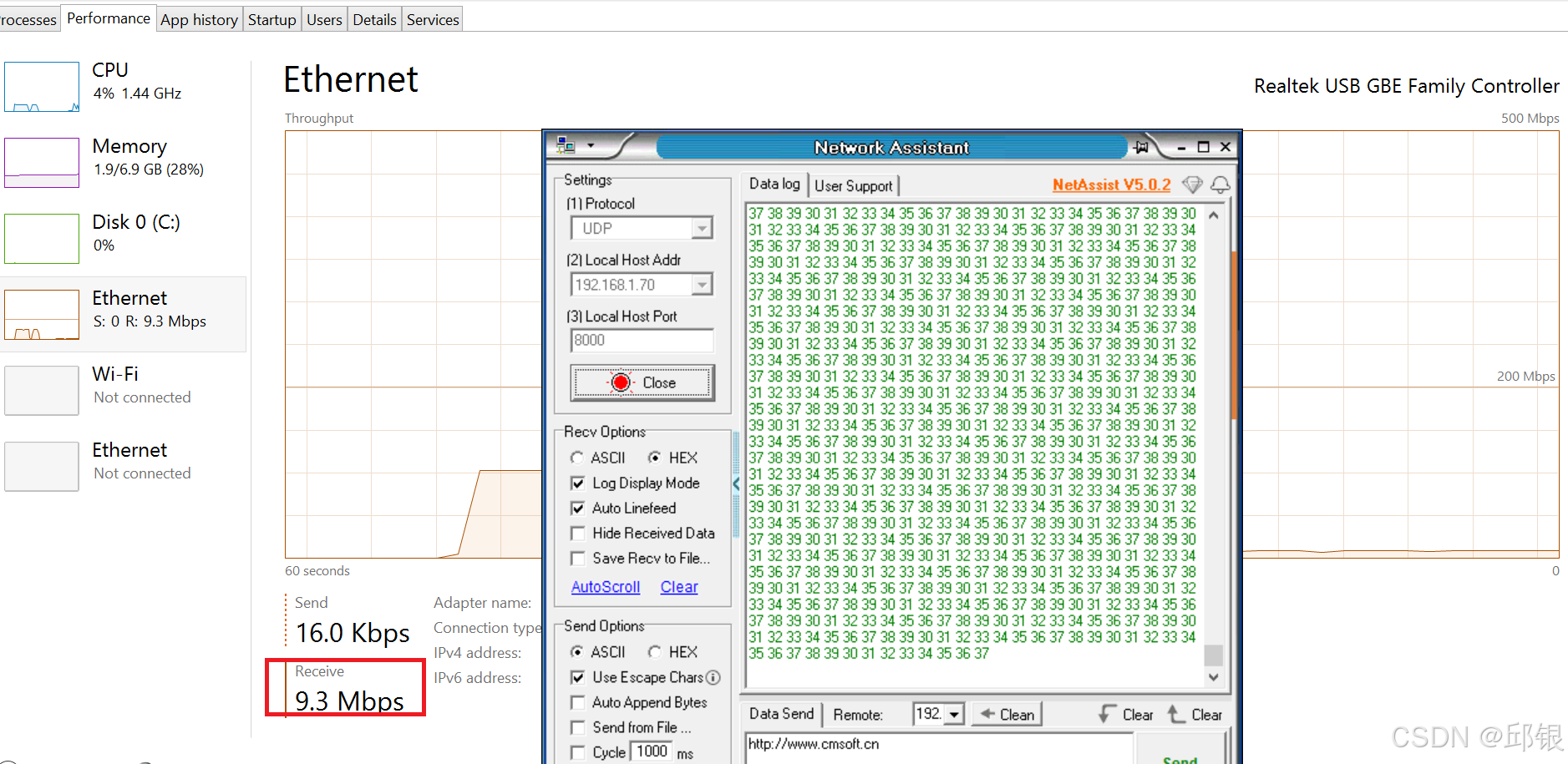
4.3.2. normal Statistics Counter观测数据过滤:
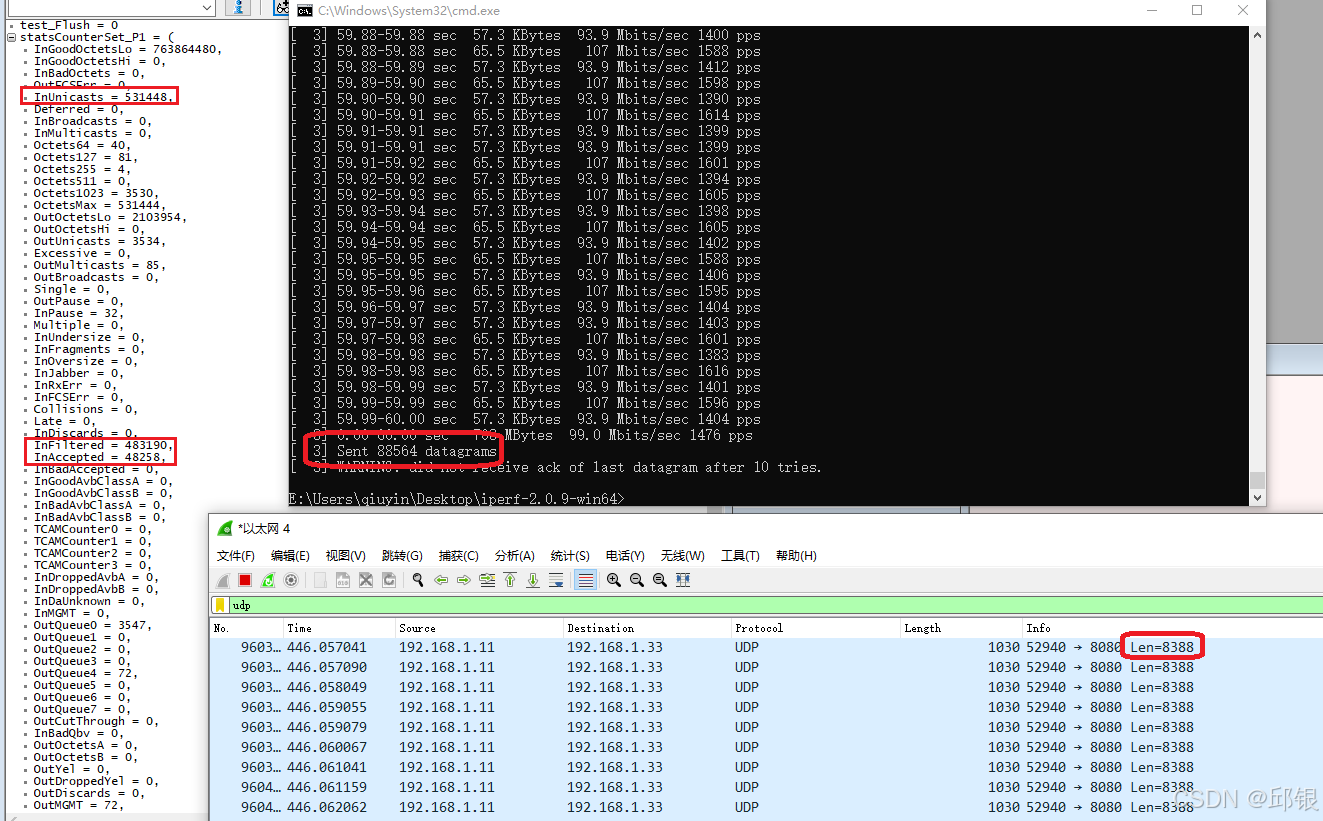
- 由于通过iperf发送的带宽是100M。Qci设定的带宽是10M,所以90%的报文将被过滤掉(Filtered),从normal Statistics Counter中观测到的数据也是符合这个比例关系:inFiltered和InAccepted的比例关系。
- 通过iperf一共发了88564个datagrams,按照8388/1500 = 5.592 ≈6个frame,那么Switch理论上需要抓到88564*6 = 531384,跟normal Statistics Counter计数的InUnicasts几乎一致。
- normal Statistics Counter还可以观察长短帧的数目,具体参考其中的OctetMax和Octet255,这两个加起来正好等于InUnicasts。
5.FRER(Frame Replication and Elimination for Reliability)
-

技术共进,成长同行——讯飞AI开发者社区
更多推荐

 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)