
【AI概念】端到端学习(End-to-End Learning)vs. 分阶段学习(Pipeline Learning)|定义、核心原理、数学表达、优缺点系统对比与工程选择建议|实际案例、工程实现细节
大家好,我是爱酱。本篇将会深入梳理端到端学习(End-to-End Learning)与分阶段学习(Pipeline Learning)这两个常被混淆的机器学习范式,结合数学公式、工程案例与优缺点,帮助你彻底厘清两者的本质区别与联系。注:本文章含大量数学算式、详细例子说明及大量代码演示,大量干货,建议先收藏再慢慢观看理解。新频道发展不易,你们的每个赞、收藏跟转发都是我继续分享的动力!
大家好,我是爱酱。本篇将会深入梳理端到端学习(End-to-End Learning)与分阶段学习(Pipeline Learning)这两个常被混淆的机器学习范式,结合数学公式、工程案例与优缺点,帮助你彻底厘清两者的本质区别与联系。
注:本文章含大量数学算式、详细例子说明及大量代码演示,大量干货,建议先收藏再慢慢观看理解。新频道发展不易,你们的每个赞、收藏跟转发都是我继续分享的动力!
一、核心定义与基本思想
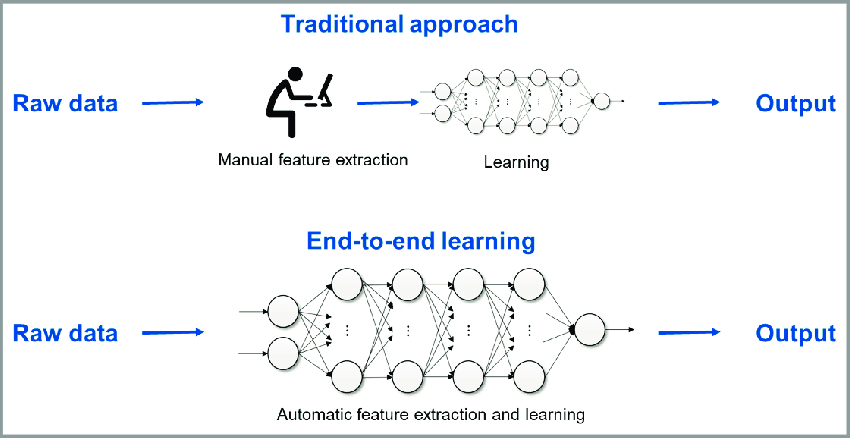
1. 端到端学习(End-to-End Learning)
-
定义:端到端学习是指用一个统一的模型,将原始输入直接映射到最终输出,中间不再人为拆分为多个独立的处理阶段或子模块。
-
英文专有名词:End-to-End Learning, E2E
-
典型流程:输入原始数据(如原始图像、音频、文本),模型自动完成特征提取、表示学习、决策输出等所有步骤。
-
数学表达:
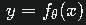
其中
是原始输入,
是最终输出,
是参数为
的端到端模型。
2. 分阶段学习(Pipeline Learning)
-
定义:分阶段学习将复杂任务拆解为多个独立的子模块或阶段,每个阶段专注于特定子任务,通常由不同的模型或算法分别完成,最后串联输出。
-
英文专有名词:Pipeline Learning, Modular Learning, Machine Learning Pipeline
-
典型流程:如“特征提取—特征选择—模型训练—后处理”,每一步都可独立优化和调试。
-
数学表达:

其中
表示第
个阶段的处理函数。
二、工程流程与典型架构
1. 端到端学习流程
-
数据输入:原始数据(如原始像素、原始音频波形)
-
模型结构:单一深度神经网络(如CNN、Transformer等)
-
训练目标:直接优化最终任务的损失函数(如分类准确率、翻译BLEU分数等)
代表案例
-
图像识别:原始图像 → CNN → 直接输出类别
-
语音识别:原始音频 → RNN/Transformer → 直接输出文本
-
机器翻译:原始句子 → Transformer → 直接输出目标语言
2. 分阶段学习流程
-
数据输入:原始数据
-
阶段1:特征提取(如SIFT、MFCC、TF-IDF等)
-
阶段2:特征选择/降维(如PCA、LDA等)
-
阶段3:模型训练(如SVM、逻辑回归、决策树等)
-
阶段4:后处理/集成(如投票、加权平均等)
代表案例
-
传统语音识别:音频 → MFCC特征提取 → 声学模型 → 语言模型 → 文本输出
-
传统图像分类:图像 → SIFT/HOG特征 → SVM分类器
三、优缺点系统对比
| 维度 | 端到端学习(End-to-End) | 分阶段学习(Pipeline) |
|---|---|---|
| 流程设计 | 简洁统一,所有步骤一体化 | 分模块、分阶段,结构清晰 |
| 人工干预 | 极少,特征提取等由模型自动完成 | 需大量人工特征工程与调参 |
| 可解释性 | 较差,模型为“黑盒” | 较好,各阶段可单独分析与调优 |
| 灵活性 | 低,难以插拔或替换中间环节 | 高,可针对每一阶段独立优化 |
| 性能极限 | 数据充足时可逼近理论最优 | 受限于手工设计与阶段性误差累积 |
| 数据需求 | 极高,需要大量标注数据 | 可在小数据下依靠人工知识弥补 |
| 工程复杂度 | 低,整体开发与维护简化 | 高,需维护多个模块与接口 |
| 错误追踪 | 难以定位具体环节问题 | 易于定位与修复各阶段bug |
四、典型应用场景与案例
1. 端到端学习适用场景
-
特征工程困难或不可行:如语音识别、机器翻译、端到端自动驾驶感知-决策
-
大数据+高算力:如大模型训练、预训练-微调范式
-
追求极致性能:如Kaggle竞赛、工业级AI部署
2. 分阶段学习适用场景
-
数据有限/标注难:如医学影像、工业检测等小样本场景
-
需要高可解释性:如金融风控、医疗诊断等高风险领域
-
多团队协作开发:如大型工程项目、跨学科AI系统
五、常见误区与工程实践建议
-
误区1:端到端一定优于分阶段。实际上,端到端对数据和算力要求极高,且可解释性差,许多实际工程仍采用分阶段方案。
-
误区2:分阶段一定落后。分阶段方案在数据有限、需要解释或工程可控性强的场景下依然主流。
-
建议:
-
任务复杂、数据充足时优先尝试端到端,追求极致性能。
-
数据有限、需解释、工程可控性高时优先分阶段,便于调优和维护。
-
混合范式也是趋势,如端到端主干+部分可插拔模块。
-
六、数理公式与工程流程举例
1. 端到端模型损失函数
2. 分阶段Pipeline损失函数(以两阶段为例)
七、未来趋势与发展方向
-
端到端+分阶段混合架构:如端到端主干+可解释模块,兼顾性能与可控性。
-
AutoML与Pipeline自动化:自动搜索最佳分阶段流程,提升开发效率。
-
可解释AI与模块化AI:提升端到端系统的可解释性,推动工程落地。
-
大模型驱动的端到端范式:多模态大模型推动端到端学习在更多领域落地。
八、总结
端到端学习(End-to-End Learning)与分阶段学习(Pipeline Learning)是现代机器学习和人工智能系统设计中的两种核心范式,它们代表了AI系统工程中自动化与模块化、黑盒与可解释、极致性能与工程可控性的不同取舍。
端到端学习通过单一模型将原始输入直接映射到最终输出,最大程度减少了人工干预和手工特征设计。其优势在于流程极简、开发效率高、能够充分利用大数据和强算力挖掘复杂的输入输出关系。端到端方法尤其适用于特征工程难以手工完成、数据量充足、追求极致性能的场景,如语音识别、机器翻译、自动驾驶感知决策一体化等。近年来,深度学习和大模型的崛起极大推动了端到端范式在工业界和学术界的广泛应用。
然而,端到端学习也存在明显的短板。首先,它对数据和算力的需求极高,数据稀缺时难以保证泛化性能。其次,模型结构高度耦合,缺乏中间可控环节,导致可解释性和可调试性较差。在实际工程中,端到端模型一旦出现错误,往往难以定位具体问题所在,维护和优化成本较高。
分阶段学习则将复杂任务拆解为多个独立的子模块,每个阶段专注于特定子任务,如特征提取、特征选择、模型训练、后处理等。每个环节可以采用不同的算法、团队独立开发和调优,具有高度的灵活性和可解释性。分阶段方案适用于数据有限、需要高可解释性、工程可控性要求高的场景,如金融风控、医疗诊断、工业检测等。它便于定位和修复各阶段bug,支持多团队协作和系统级优化。
但分阶段学习也有局限:人工特征工程和模块设计依赖领域知识,可能导致信息损失和误差累积;整体性能上限受限于各阶段最弱环节,难以逼近理论最优。
实际工程中,端到端与分阶段并非绝对对立,而是可以融合互补。越来越多的AI系统采用“端到端主干+部分可插拔模块”的混合架构,既兼顾性能,又提升可解释性和工程可控性。例如,自动驾驶系统中感知部分采用端到端深度网络,而决策与规划阶段则采用模块化设计。
未来趋势方面,AutoML、可解释AI、模块化AI等新技术正在推动端到端与分阶段的进一步融合。大模型和多模态AI的发展,也让端到端学习在更多复杂场景落地成为可能;而对于高风险、强合规要求的行业,分阶段与可解释模块依然不可或缺。
理解端到端学习与分阶段学习的本质区别、优缺点和适用场景,是AI系统设计和工程实践的基础。只有根据具体任务、数据条件和业务目标灵活选择甚至融合两者,才能最大化AI系统的性能、可解释性与工程可控性,推动智能技术在各行各业的深度落地和创新发展。
谢谢你看到这里,你们的每个赞、收藏跟转发都是我继续分享的动力。
如需进一步案例、代码实现或与其他聚类算法对比,欢迎留言交流!我是爱酱,我们下次再见,谢谢收看!

技术共进,成长同行——讯飞AI开发者社区
更多推荐
 32
32 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)