
JavaWeb-在java中使用IK分词器
可以看到林腾已经识别出来了,博客能识别是因为这个词本来就比较大众,IK分词器原本就可以识别。而"的,啊,a"就没有识别出来,因为我们将它们设置成了停用词
·
目录
添加依赖
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-core</artifactId>
<version>8.5.0</version>
</dependency>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-analyzers-common</artifactId>
<version>8.5.0</version>
</dependency>
<dependency>
<groupId>com.github.magese</groupId>
<artifactId>ik-analyzer</artifactId>
<version>8.5.0</version>
</dependency>注意,版本要保持一致。
配置拓展词和停用词
通过 Maven 引入了 IK 分词器的依赖时,项目中不会自动生成 IKAnalyzer.cfg.xml 文件,也不会自带默认的扩展词典和停用词词典。因此,你需要手动创建 IKAnalyzer.cfg.xml 文件,并将其放置在项目的类路径下(通常是 resources 目录中):
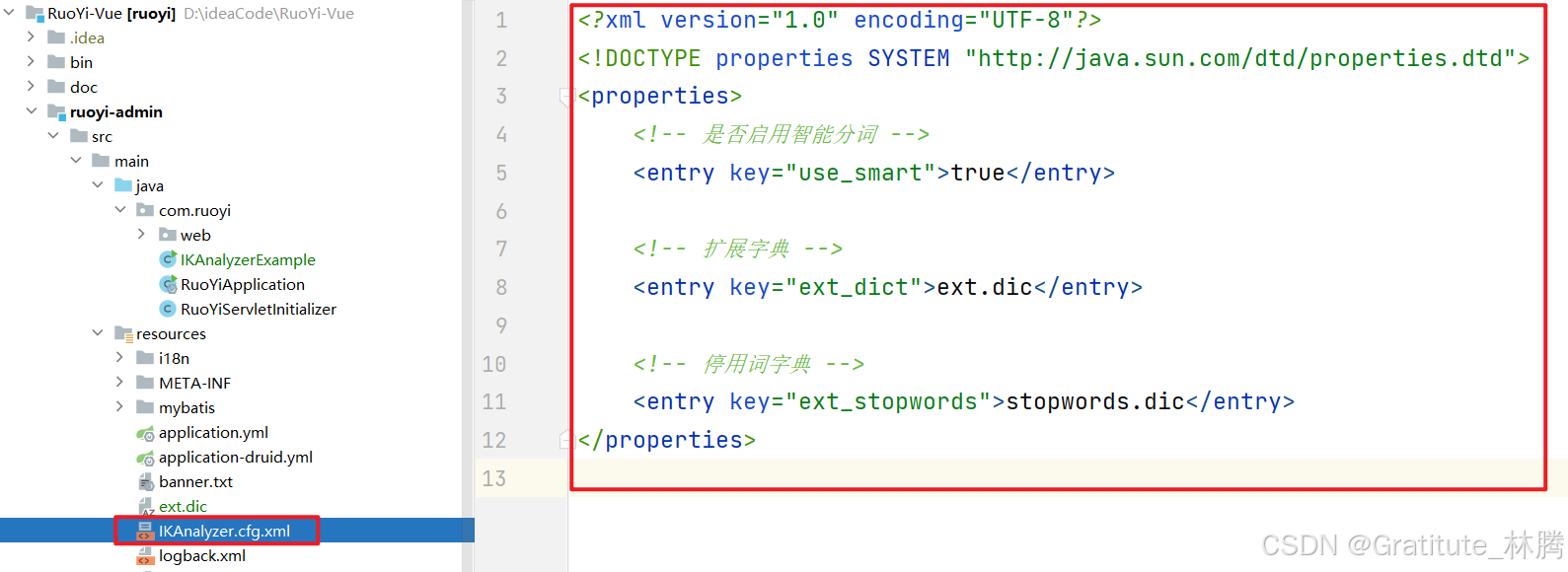
在配置文件中,指定了扩展字典和停用词字典,我们需要在与IKAnalyzer.cfg.xml同一目录下创建对应的文件:
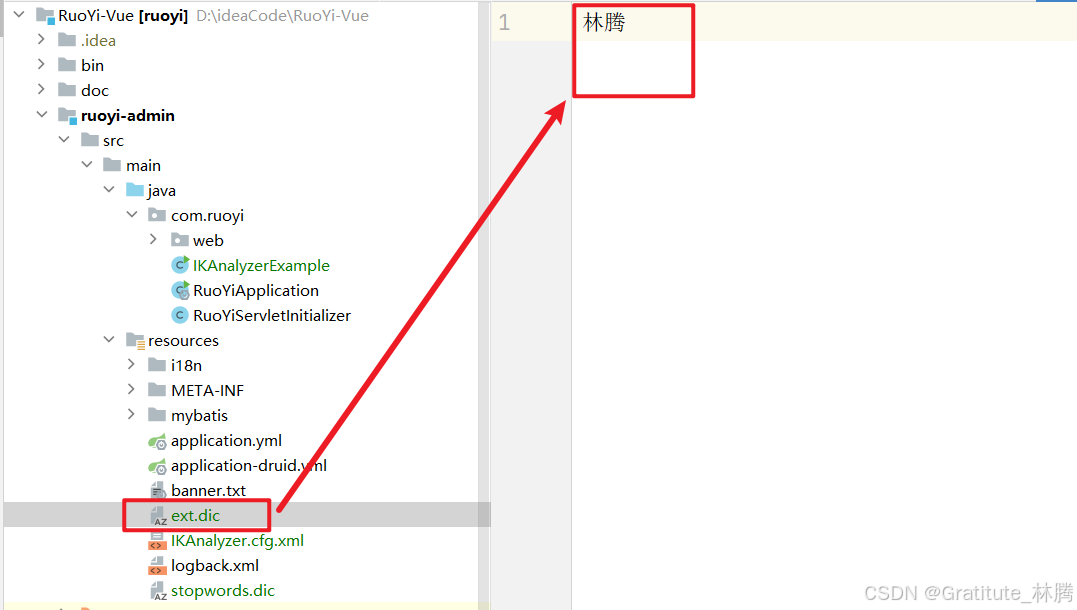
在ext.dic中添加要拓展的词,这样IK分词器就可以识别出来了,比如我这里添加了:林腾
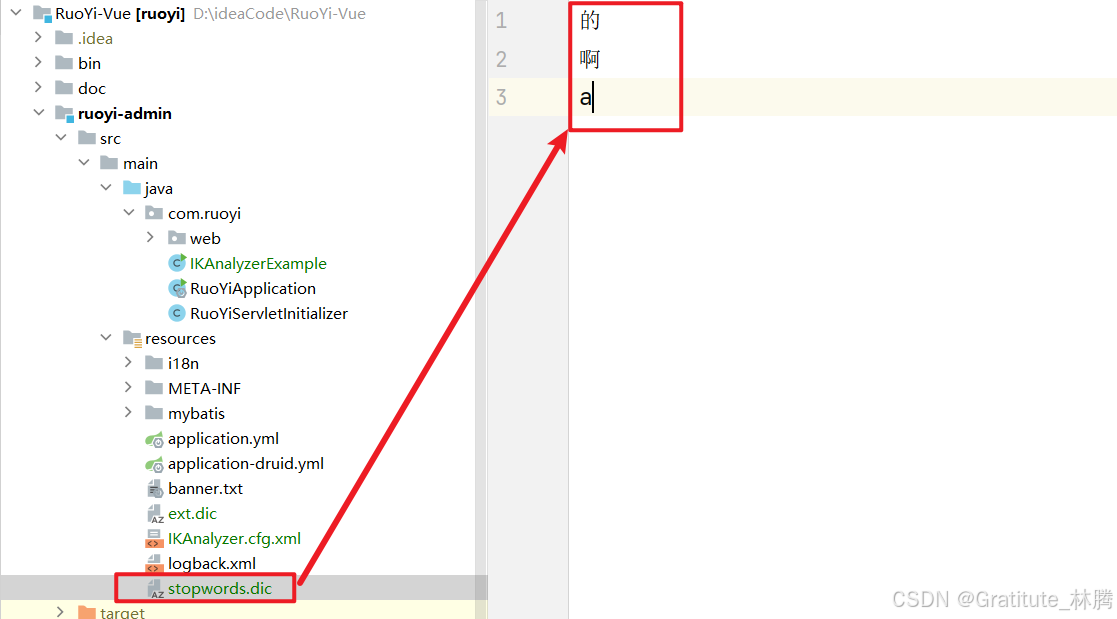
在stopwords.dic中添加要停用的词,这样IK分词器就不会识别这些词了,这里我停用了的,啊,a
运行测试
测试代码
public class IKAnalyzerExample {
public static void main(String[] args) {
try {
// 待分词的文本
String text = "林腾的博客啊a";
// 创建 IKAnalyzer 分词器,参数 true 表示使用智能分词模式
IKAnalyzer analyzer = new IKAnalyzer(true);
// 分词
TokenStream tokenStream = analyzer.tokenStream("content", new StringReader(text));
CharTermAttribute term = tokenStream.addAttribute(CharTermAttribute.class);
tokenStream.reset();
// 输出分词结果
System.out.println("分词结果:");
while (tokenStream.incrementToken()) {
System.out.print(term.toString() + " ");
}
tokenStream.close();
analyzer.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
根据我们刚刚添加的词典内容,IK分词器可以识别:林腾,不能识别:的,啊,a
结果:

可以看到林腾已经识别出来了,博客能识别是因为这个词本来就比较大众,IK分词器原本就可以识别。而"的,啊,a"就没有识别出来,因为我们将它们设置成了停用词

技术共进,成长同行——讯飞AI开发者社区
更多推荐

 8
8 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)