
精通DDD领域设计模式的代码实现
聚合是领域模型中的一个界限上下文,它包含了一组领域对象,这些对象通过内在的关联形成一个聚合根(Root Entity)以及一系列的从属对象。聚合的边界定义了哪些对象是可以在外部访问的,而哪些对象是受限的。在设计聚合时,需要明确其边界。聚合的边界由聚合根来定义,这个根实体是聚合中唯一可以直接被外部访问的实体。聚合根负责维护聚合内的业务规则,并对外提供了一个统一的接口。

简介:DDD(领域驱动设计)强调以业务领域为核心进行系统设计,以提高软件质量和代码可维护性。本案例详细介绍了在Java环境下实现DDD的关键概念,如领域模型、聚合、值对象、实体、服务和仓储。通过使用POJO构建领域模型,聚合根的创建,以及值对象的不可变性实现,开发者可以深入理解并实践DDD,提升业务逻辑处理能力,并掌握对象持久化的设计。该案例还包括了一个示例项目文件dddsample-1.1.0,供学习者分析和实践。 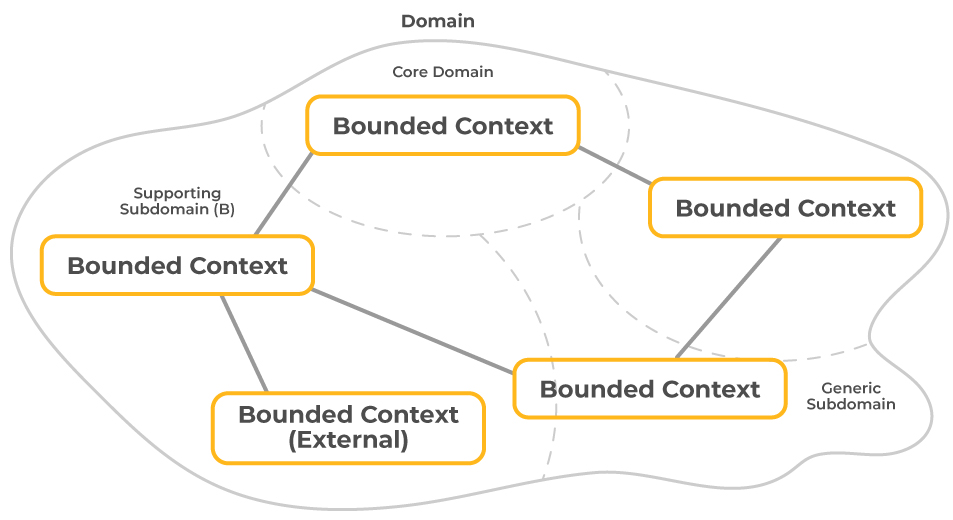
1. 领域驱动设计(DDD)概念
领域驱动设计(Domain-Driven Design, DDD)是一种关注软件核心业务逻辑开发的设计范式,它强调以领域知识为驱动,以领域模型为核心,通过紧密合作的开发团队和领域专家共同构建软件模型。DDD 不仅仅是一种技术手段,更是一种解决复杂业务问题的思考方式。
1.1 DDD 的核心理念
DDD 核心理念强调在软件开发的全生命周期中,将业务领域知识转化为计算机程序模型。它将软件系统划分为多个领域,并识别出核心领域、支撑领域和通用领域。通过这种划分,开发团队可以更有针对性地解决实际问题,提高系统的可维护性和扩展性。
1.2 DDD 与传统开发方法的差异
与传统的软件开发方法相比,DDD 更加注重模型的准确性和领域知识的深度挖掘。在传统的开发流程中,业务需求通常在开发后期才被转化为技术需求。而DDD倡导在需求分析阶段就介入领域专家,从而使模型构建更加贴近实际业务流程,减少因理解偏差带来的设计和实现上的错误。
接下来的章节将深入探讨DDD的要素、领域模型构建以及业务逻辑的分离与表达等方面,帮助读者建立起DDD设计模式的全面认识。
2. 领域模型构建与业务逻辑表达
构建一个清晰且逻辑严密的领域模型是实施领域驱动设计(DDD)的关键步骤。领域模型不仅反映了业务领域的核心概念和业务规则,也是软件开发过程中与业务人员沟通的重要桥梁。在此章节中,我们将深入探讨领域模型的基本要素,以及如何有效地将业务逻辑分离并表达。
2.1 领域模型的要素
2.1.1 领域与子领域
领域(Domain)是指一个组织或业务的活动范围,它涵盖了所有与该业务相关的概念、实体、过程和规则。领域模型是对这个业务范围内的概念和规则的抽象表示。在复杂系统中,领域往往太大而无法作为一个统一的整体进行处理,这时就需要将领域进一步划分为更小的子领域。
子领域(Subdomain)是领域中可以独立开发、有明确定义边界的区域。在DDD中,通常将子领域划分为核心领域(Core Domain)、支撑领域(Supporting Subdomain)和通用领域(Generic Subdomain)。
- 核心领域 包含了企业最独特、最有竞争力的业务规则。这是区分企业与其他企业的关键所在,通常是DDD实施的重点。
- 支撑领域 支撑着核心领域的运行,虽然对业务有帮助,但不具备区分企业的能力。
- 通用领域 包含的业务规则是通用的,通常可以通过购买商业解决方案或简单的软件模块来实现。
2.1.2 限界上下文的划分
限界上下文(Bounded Context)是DDD中用于区分不同领域模型边界的术语。它是领域模型的物理边界,界定了模型的适用范围。在限界上下文中,术语和业务对象的含义是明确的,并且只在该上下文中有效。限界上下文的一个关键功能是隔离模型概念和语言,从而减少大型系统的复杂性。
限界上下文的划分基于以下几个原则:
- 上下文地图 创建一个上下文地图,描述各个限界上下文之间的关系,包括合作关系、共享内核、客户-供应商关系、开放主机服务等。
- 团队组织 根据限界上下文组织团队,确保每个团队负责一个清晰定义的领域。
- 模块化 通过限界上下文将系统分解为模块化的部分,每个部分可以独立开发和部署。
2.2 业务逻辑的分离与表达
2.2.1 业务逻辑的抽象
业务逻辑是实现业务功能的核心规则和流程。在DDD中,业务逻辑被抽象为领域模型中的各种元素,包括实体、值对象、服务等。抽象业务逻辑可以提高代码的可读性和可维护性,同时避免逻辑在系统中被无序地散播。
要抽象业务逻辑,首先要识别领域中的核心概念,并定义这些概念之间的关系和交互规则。然后,将这些规则封装在相应的领域对象中。例如,一个订单处理系统可能会有一个 Order 实体,它封装了订单的属性和行为,如添加商品、计算总价等。
2.2.2 命令、查询职责分离(CQRS)
命令、查询职责分离(Command Query Responsibility Segregation, CQRS)是一种设计模式,它将数据的查询(读取)与命令(修改)操作分离。CQRS有助于清晰地区分系统的不同方面,简化复杂系统的操作,并提高性能。
在CQRS中,命令负责修改数据状态,它通过发送一个命令来执行业务操作。查询则负责数据的读取,返回系统当前状态的信息。CQRS通常与事件溯源(Event Sourcing)结合使用,通过存储状态变更事件来重建系统的当前状态。
2.2.3 用例驱动的设计
用例驱动的设计(Use Case Driven Design, UCDD)是一种开发方法,强调从用户的视角来定义系统功能。用例代表了用户(或外部系统)与系统之间的一次交互。通过用例,可以将复杂的业务流程分解为可管理的小块,每个小块描述了系统如何响应一个特定的请求。
每个用例都描述了一个业务场景,包括参与者(谁)和业务活动(做什么)。用例驱动的设计有助于确保系统的设计以用户的需求为中心,从而提高系统的可用性和用户满意度。
在本章节中,我们介绍了领域模型构建和业务逻辑表达的基础知识,为进一步深入领域驱动设计奠定了坚实的基础。接下来的章节,我们将继续探讨聚合设计以及值对象的实现等关键概念。
3. 聚合设计及聚合根的实现
聚合是领域驱动设计(DDD)中一个关键的概念,它是一种将相关对象组合在一起形成一个整体单元的方式。聚合设计关注于如何将复杂的领域模型划分为更小的、更易管理的部分。正确的聚合设计可以减少系统的复杂性并提高其可维护性。在本章中,我们将深入探讨聚合设计原则以及如何实现聚合根。
3.1 聚合设计原则
聚合设计原则是构建清晰、一致且可维护领域模型的基础。理解并正确应用这些原则是成功实现DDD策略的关键。
3.1.1 聚合的定义和边界
聚合是领域模型中的一个界限上下文,它包含了一组领域对象,这些对象通过内在的关联形成一个聚合根(Root Entity)以及一系列的从属对象。聚合的边界定义了哪些对象是可以在外部访问的,而哪些对象是受限的。
在设计聚合时,需要明确其边界。聚合的边界由聚合根来定义,这个根实体是聚合中唯一可以直接被外部访问的实体。聚合根负责维护聚合内的业务规则,并对外提供了一个统一的接口。
3.1.2 聚合内部结构和规则
聚合内部的结构和规则应确保以下几点:
- 内部一致性:聚合内部的所有操作必须保证聚合状态的一致性。任何对聚合内的操作都必须通过聚合根来执行。
- 事务边界:聚合是事务处理的基本单元,所有对聚合的操作应该在同一个事务中完成,以确保数据的一致性。
- 严格封装:聚合内部的实现细节对外部世界是不可见的,这种封装确保了聚合的内部状态不会被外部直接操作,从而破坏聚合的一致性。
3.2 聚合根的实现策略
聚合根是聚合的核心,它既是聚合内部成员的协调者,又是外部交互的接口。正确实现聚合根是确保聚合设计成功的关键。
3.2.1 聚合根的选择和职责
选择正确的聚合根对于聚合设计来说至关重要。聚合根应遵循以下原则:
- 它应该代表一个领域概念的实体,例如订单、用户或产品。
- 它应该是对领域问题有明确业务意义的对象。
- 它应承担对聚合内其他对象的业务规则责任。
聚合根的职责包括:
- 维护聚合内对象的不变量。
- 提供聚合外访问聚合内对象的唯一接口。
- 管理对聚合内对象的创建和删除。
3.2.2 聚合内实体与值对象的关系
聚合内的实体和值对象有明确的职责分工。实体通常拥有唯一标识符,并且即使它们的属性值相同,它们也可以被认为是不同的对象。相对的,值对象则通过其属性值来定义,它们没有唯一标识符。
聚合根与内部实体、值对象之间的关系应遵循以下规则:
- 实体间的关系可以是相互引用,但应避免循环依赖。
- 值对象通常是聚合根属性的一部分,并且它们的生命周期与聚合根绑定。
- 实体可以包含值对象,但值对象不能包含实体。
通过明确聚合根的选择和职责,以及聚合内实体与值对象的关系,可以确保聚合设计的清晰性和一致性,进而提升整个系统的可维护性和扩展性。
接下来的章节将介绍如何在具体的编程实践中实现聚合根,包括一些最佳实践和常见错误的讨论。我们将深入探讨聚合根的代码实现,并展示如何通过代码逻辑来维护聚合内的业务规则和不变量。
4. 值对象的不可变性实现
值对象是领域驱动设计(DDD)中的重要概念,其不可变性是保持领域模型一致性和稳定性的关键。在本章节中,我们将详细探讨值对象的概念、作用以及如何实现不可变性。
4.1 值对象的概念与作用
4.1.1 值对象与实体的对比
在DDD中,值对象和实体是两种不同的对象。实体通常具有唯一标识符(ID),可以通过ID来区分两个实例是否相同。而值对象则没有唯一的标识符,它们通过属性值来判断相等性。值对象更多地关注其属性值的组合,一旦创建后,其内部状态不能改变。
与实体相比,值对象的价值在于它能够简洁地表达领域概念,尤其是在需要比较对象间差异时,值对象可以忽略唯一性标识符,直接比较属性值。
4.1.2 值对象在模型中的应用
值对象在领域模型中有着广泛的应用,例如表示货币、颜色、日期范围等。这些概念往往不需要独立的身份,而是在业务逻辑中作为整体进行操作和比较。例如,一个订单的送货地址可以用值对象表示,该对象包含了街道、城市、邮编等信息,当这些信息发生变化时,地址值对象应当被整个替换,而不是部分修改。
4.2 不可变性设计原则
4.2.1 不可变对象的优势
不可变对象具有以下优势: 1. 线程安全:不可变对象天生线程安全,可以无需同步机制在多线程环境中安全使用。 2. 一致性:对象一旦创建,状态不再改变,从而保持业务逻辑的一致性和可预测性。 3. 易于理解与维护:由于对象的不可变性,我们可以更容易理解代码的流程,并且减少因状态变化导致的错误。
4.2.2 实现不可变性的技术手段
为了实现值对象的不可变性,我们可以采取以下技术手段:
1. 封装属性
public final class Money {
private final BigDecimal amount;
private final Currency currency;
public Money(BigDecimal amount, Currency currency) {
this.amount = amount;
this.currency = currency;
}
// Getter methods
public BigDecimal getAmount() {
return amount;
}
public Currency getCurrency() {
return currency;
}
}
在上述Java代码中, Money 类的实例一旦创建,其 amount 和 currency 属性就不能被更改。通过使用 final 关键字,我们确保了这些属性在对象生命周期内不变。
2. 使用构造方法初始化对象
如上例所示,使用构造方法来初始化对象的所有属性值,并在对象的生命周期中不允许修改这些属性。
3. 不提供修改状态的方法
确保不公开任何setter方法,这样外部代码无法更改对象的状态。
通过上述手段,我们可以构建出符合不可变性原则的值对象。在DDD实践中,这种不可变对象的设计是保证领域模型纯净性的重要手段。
5. 实体的唯一标识符管理
在领域驱动设计(DDD)中,实体是具有生命周期和唯一身份的领域对象。管理实体的唯一标识符是构建稳定系统的基石。本章将深入探讨唯一标识符的生成策略,以及如何在分布式系统中维护标识符的一致性。
5.1 标识符生成策略
实体的唯一标识符通常有两种类型:自然主键和代理主键。自然主键是指能够反映实体业务含义的属性,例如人名、地点或产品的型号。代理主键是系统生成的、与业务无关的唯一标识符,如数据库自增ID或UUID。
5.1.1 自然主键与代理主键
自然主键是业务领域的直接反映,它们具有一定的业务含义。然而,自然主键在实际应用中可能会面临一些挑战。例如,业务规则的变化可能会影响到主键的唯一性。此外,自然主键可能会随着时间的推移而改变,这会导致实体身份的不稳定性。
代理主键通常由系统自动分配,不反映任何业务含义。它们的优点在于稳定性与一致性,能够确保实体的唯一性,不受业务变化的影响。代理主键包括数据库自增ID、UUID等。
5.1.2 唯一标识符的生成算法
唯一标识符的生成算法有多种,常用的包括数据库自增ID、UUID、Twitter的Snowflake算法和MongoDB的ObjectID。
- 数据库自增ID :是最简单的生成策略,适用于单数据库实例的场景,但在分布式环境下可能无法保证唯一性。
sql -- 以MySQL为例,创建自增ID的表 CREATE TABLE `id_generator` ( `id` int(11) NOT NULL AUTO_INCREMENT, PRIMARY KEY (`id`) ); -
UUID :在分布式系统中常用,因为它几乎可以保证全球范围内的唯一性。但UUID过长,不利于存储和处理。
java import java.util.UUID; // Java 生成 UUID 示例 String uuid = UUID.randomUUID().toString(); -
Twitter Snowflake :是一个分布式ID生成算法,通过组合时间戳、数据节点ID和序列号生成唯一ID,适合分布式系统。
java // 伪代码表示 Snowflake ID 的生成过程 public long generateId() { long timestamp = System.currentTimeMillis(); return (timestamp << 22) | (datacenterId << 12) | sequence; } -
MongoDB ObjectID :MongoDB自动生成的唯一ID,包含了时间戳、机器ID、PID和计数器。
5.2 标识符的一致性维护
在分布式系统中,保证唯一标识符的一致性是一个挑战。由于多个节点可能同时操作,生成ID时必须考虑线程安全和唯一性保证。
5.2.1 分布式系统中的ID生成问题
在分布式系统中,由于多个节点可能同时创建实体,直接在应用层生成ID容易引发冲突。为解决这一问题,可以采取以下策略:
- 使用集中式ID生成服务,例如Redis或ZooKeeper,通过原子操作保证ID的唯一性。
- 在数据库层面,可以使用分布式数据库的特定功能来生成唯一ID,如Google的UUID()函数或AWS的DynamoDB表。
5.2.2 解决方案与实践
集中式ID生成服务是一种常见的解决方案。例如,Twitter的分布式ID生成算法Snowflake就是在这种背景下产生的。它通过在ID中编码时间戳、数据中心ID、节点ID和序列号来生成一个64位的长整型数字。这种方式可以生成大量的唯一ID,并且在分布式环境中是线程安全的。
// 示例:实现类似 Snowflake 的ID生成器
public class SnowflakeIdGenerator {
private final long twepoch = 1288834974657L;
private final long workerIdBits = 5L;
private final long datacenterIdBits = 5L;
private final long maxWorkerId = -1L ^ (-1L << workerIdBits);
private final long maxDatacenterId = -1L ^ (-1L << datacenterIdBits);
private final long sequenceBits = 12L;
private final long workerIdShift = sequenceBits;
private final long datacenterIdShift = sequenceBits + workerIdBits;
private final long timestampLeftShift = sequenceBits + workerIdBits + datacenterIdBits;
private final long sequenceMask = -1L ^ (-1L << sequenceBits);
private long workerId;
private long datacenterId;
private long sequence = 0L;
private long lastTimestamp = -1L;
public SnowflakeIdGenerator(long workerId, long datacenterId) {
if (workerId > maxWorkerId || workerId < 0) {
throw new IllegalArgumentException(String.format("Worker ID can't be greater than %d or less than 0", maxWorkerId));
}
if (datacenterId > maxDatacenterId || datacenterId < 0) {
throw new IllegalArgumentException(String.format("Datacenter ID can't be greater than %d or less than 0", maxDatacenterId));
}
this.workerId = workerId;
this.datacenterId = datacenterId;
}
// Generate ID logic omitted for brevity...
}
此外,还有基于数据库的ID生成策略,例如MySQL的auto_increment和sequence,或者PostgreSQL的SERIAL和BIGSERIAL类型,但它们往往更适合单个数据库实例,不适合分布式环境。
在实践中,选择合适的ID生成策略需要根据系统的具体需求和架构来定。对于高并发的分布式系统,推荐使用集中式ID生成服务或基于算法的ID生成方案,以确保ID的唯一性和系统的性能。
6. 跨领域对象服务的设计
6.1 服务的界定与职责
6.1.1 服务与领域模型的关系
在领域驱动设计中,服务是围绕业务功能和操作的抽象,它们不拥有状态,但负责协调领域模型中的一个或多个领域对象完成特定的业务任务。良好的服务界定可以提升系统的可维护性,实现业务逻辑的解耦合,同时保持领域逻辑的清晰。
服务在与领域模型的交互中充当着协调者的角色。它们将领域对象串联起来,以执行复杂的业务操作。一个服务应该只拥有一个职责,能够表述为一个业务场景或工作流程。
6.1.2 服务的抽象与封装
将业务逻辑抽象化成服务有助于后续的技术实现和业务流程的调整。服务的封装不仅仅是对业务操作的封装,更是对领域模型的一种保护。它提供了一种从外部操作领域模型的接口,同时隐藏了领域模型的内部实现细节。
当设计服务时,应该:
- 确保服务的职责单一。
- 服务应该定义清晰的接口。
- 服务应该是无状态的。
通过这些原则,可以确保服务易于测试和维护。
6.2 服务层的设计模式
6.2.1 应用服务、领域服务和基础设施服务
在DDD中,服务层主要分为应用服务、领域服务和基础设施服务。
- 应用服务(Application Services) :处理来自用户界面的请求。它们不包含业务逻辑,而是通过领域服务来协调领域对象完成任务。
- 领域服务(Domain Services) :封装了业务逻辑,但没有状态。它们通常用于实现跨越多个实体或值对象的行为。
- 基础设施服务(Infrastructure Services) :提供非领域逻辑相关的技术性支持,如邮件发送、消息队列等。
6.2.2 设计模式在服务层的应用案例
在设计服务层时,应用设计模式可以帮助我们构建出清晰、可扩展的架构。一个常见的模式是使用 Transaction Script 模式在应用服务层进行事务控制。此模式下,一个操作对应一个脚本,负责整个事务过程。
示例代码(假设使用Java和Spring框架):
@Component
public class AccountService {
@Autowired
private AccountRepository accountRepository;
@Transactional
public void transferMoney(Long fromAccountId, Long toAccountId, BigDecimal amount) {
Account fromAccount = accountRepository.findById(fromAccountId)
.orElseThrow(() -> new AccountNotFoundException("Account not found for ID: " + fromAccountId));
Account toAccount = accountRepository.findById(toAccountId)
.orElseThrow(() -> new AccountNotFoundException("Account not found for ID: " + toAccountId));
if (fromAccount.getBalance().compareTo(amount) < 0) {
throw new InsufficientFundsException("Insufficient funds for account ID: " + fromAccountId);
}
fromAccount.debit(amount);
toAccount.credit(amount);
accountRepository.save(fromAccount);
accountRepository.save(toAccount);
}
}
在上述代码中, transferMoney 方法执行了一个跨账户转账的业务流程,它使用了 @Transactional 注解来管理事务,保证了转账操作的原子性。
在设计服务层时,也需要考虑服务的发现、监控、日志记录和安全等方面,这些可以通过集成相应的基础设施服务来实现。
通过上述章节内容,我们了解了跨领域对象服务设计的核心概念以及如何根据实际需求实现服务层的设计。这些知识点将帮助我们在构建复杂系统时保持清晰的业务逻辑与技术实现的分离,确保系统的灵活、可维护和可扩展性。
简介:DDD(领域驱动设计)强调以业务领域为核心进行系统设计,以提高软件质量和代码可维护性。本案例详细介绍了在Java环境下实现DDD的关键概念,如领域模型、聚合、值对象、实体、服务和仓储。通过使用POJO构建领域模型,聚合根的创建,以及值对象的不可变性实现,开发者可以深入理解并实践DDD,提升业务逻辑处理能力,并掌握对象持久化的设计。该案例还包括了一个示例项目文件dddsample-1.1.0,供学习者分析和实践。

技术共进,成长同行——讯飞AI开发者社区
更多推荐


 29
29 0
0- 0



 已为社区贡献34条内容
已为社区贡献34条内容

所有评论(0)