
毕业设计:Vue3+FastApi+Python+Neo4j实现主题知识图谱网页应用——前后端:数据爬虫
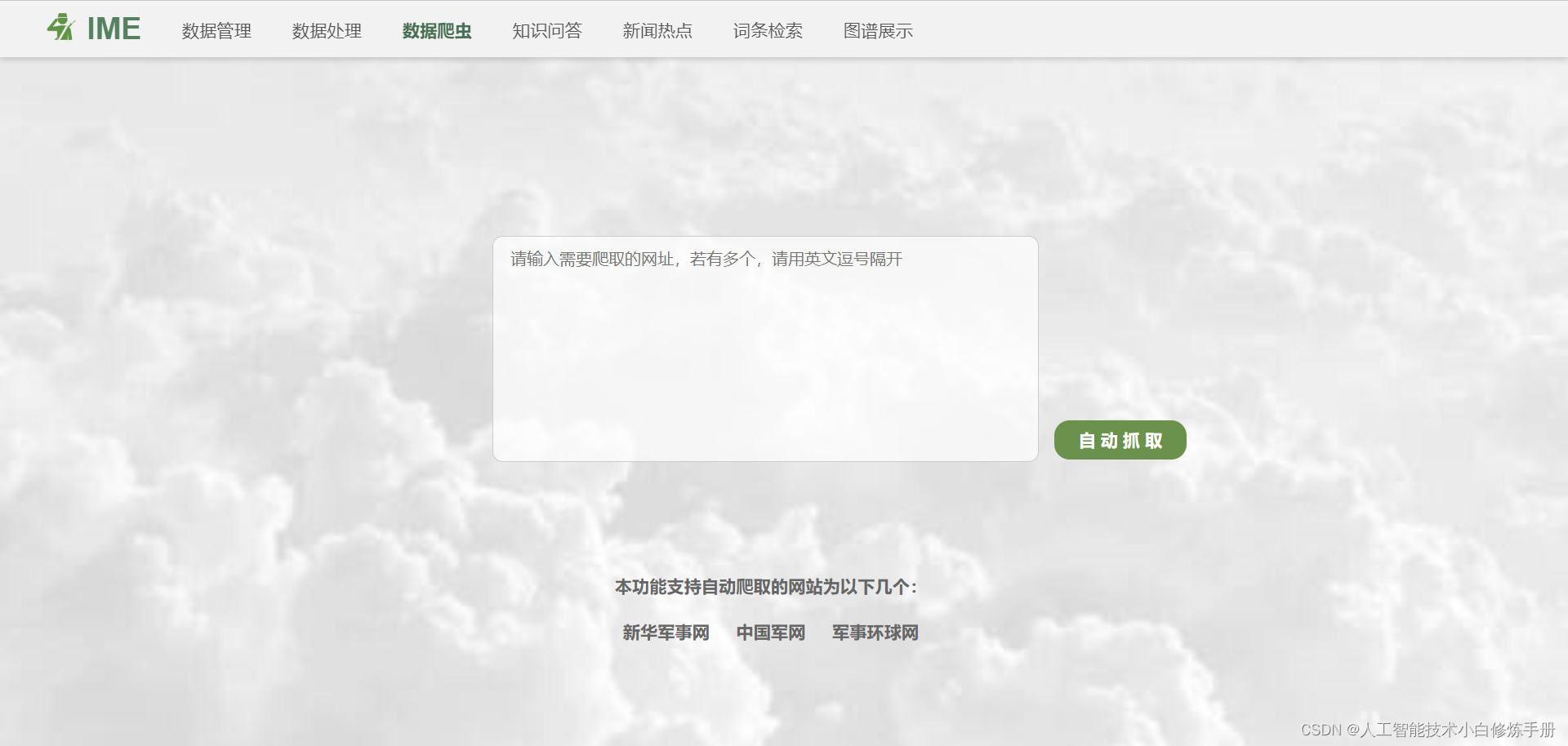
在该模块中,用户输入需要爬取的网址,点击“自动抓取”,后台针对相关网址进行爬虫,并返回进行格式化处理的数据,以便后续上传到数据集中进行处理,如下图所示。
简介
完整项目资源链接:https://download.csdn.net/download/m0_46573428/87796553
项目详细信息请看:https://blog.csdn.net/m0_46573428/article/details/130071302
在该模块中,用户输入需要爬取的网址,点击“自动抓取”,后台针对相关网址进行爬虫,并返回进行格式化处理的数据,以便后续上传到数据集中进行处理,如下图所示。
功能点:①点击下方新闻网站,可以跳转到相应的平台主页,方便用户复制需要下载的新闻链接;②输入框红输入新闻链接,多个则用英文逗号分开;③点击“自动抓取”,系统后台爬虫后会弹出爬虫结果下载链接。
主要代码
前端代码:Crawler.vue
Html
这段代码是Vue.js模板(template)代码。
1. 模板的根元素为<div id="main">,包含了以下内容:
- 一个
<textarea>元素,用于输入需要爬取的网址,其初始值为空字符串,且可以使用v-model绑定到组件的newsList属性上。 - 一个
<button>元素,用于触发自动抓取功能,点击时调用组件的AutoCrawl()函数。 - 一个
<div id="Beizhu">元素,用于包含说明性文字信息和链接列表。
2. <div id="Beizhu">元素包含了一个文本段落和一个无序列表<ul>:
- 文本段落中展示了“本功能支持自动爬取的...”等说明信息。
- 无序列表中列出了三个JS新闻网站的URL,并将它们用
<a>元素进行包裹,链接具有target="_blank"的标志,允许点击后在新的页面中打开链接。 需要注意的是,在实际使用中,占位符''所代表的URL也需要进行替换和确认。
Script
这段代码定义了一个Vue.js组件(默认导出),包含以下内容:
1. 定义了一个名为Crawl的Vue组件,其中包括以下选项:
name: 组件名称为Crawl。props: 空对象,表示该组件不接受外部传递的属性值。data(): 组件的局部数据对象,其中声明了一个字符串类型的newsList属性,它的初始值为空字符串。
2. 定义了一个名为AutoCrawl的方法,在点击按钮后将会触发,其具体行为包括:
- 通过使用
axios.get()函数发送一个HTTP GET请求至一个特定URL的服务器上,并将当前newsList属性所储存的网址地址作为查询参数添加到URL中。 - 如果请求成功,则弹窗提示用户将服务器返回的数据复制到浏览器中进行下载。
- 如果请求失败,则弹出警告框提示“NewsCrawl failed!”。
<template>
<div id="main">
<textarea
placeholder="请输入需要爬取的网址,若有多个,请用英文逗号隔开"
v-model="newsList"
/>
<button @click="AutoCrawl()">自 动 抓 取</button>
<div id="Beizhu">
<p> <b> 本功能支持自动爬取的网站为以下几个:</b></p>
<ul>
<li>
<a href="http://www.news.cn/milpro/" target="_blank"> <b>新华JS网</b> </a>
</li>
<li>
<a href="http://www.81.cn/bq_208581/jdt_208582/index.html" target="_blank"> <b>中国J网</b></a>
</li>
<li>
<a href="https://mil.huanqiu.com/" target="_blank"> <b>JS环球网</b></a>
</li>
</ul>
</div>
</div>
</template>
<script>
export default {
name: "Crawl",
props: {},
data() {
return {
newsList: "",
};
},
methods: {
AutoCrawl: function () {
this.axios
.get("http://localhost:8000/NewsCrawl?newsList=" + this.newsList)
.then((res) => {
alert("请复制以下链接到浏览器中进行下载:" + res.data);
this.newsList = "";}
)
.catch((error) => {
alert("NewsCrawl failed!");
});
},
},
};
</script>
<style scoped>
* {
color: #666;
}
#main {
padding-top:15%;
margin: auto;
width: 60%;
text-align: center;
}
ul {
margin: auto;
margin-top: 10px;
}
li {
list-style: none;
float: left;
padding: 13px;
}
textarea {
float: left;
resize: none;
outline: none;
margin-left: 175px;
border: #ccc solid 1px;
padding: 10px;
width: 55%;
background: rgba(255, 255, 255, 0.7);
border-radius: 10px;
height: 200px;
font-size: 16px;
padding-left: 17px;
}
button {
float: left;
border: none;
background: rgb(107, 146, 77);
color: white;
padding: 8px 10px;
font-weight: bold;
border-radius: 15px;
margin: 181px -23px 0px 15px;
width: 130px;
cursor: pointer;
}
#Beizhu {
margin-top: 110px;
float: left;
margin-left: 290px;
}
</style>后端代码
工具函数
这段代码定义了两个函数download(url, user_agent='wswp', num_retries=2)和get_content(page_url),用于下载网页HTML并获取页面内容。
具体而言,download()函数实现了:
- 使用
urllib.request.Request()方法创建一个Request对象,并使用指定的User-Agent头部信息发送HTTP请求。 - 发送HTTP请求并获取响应数据。
- 如果出现URLError异常,则打印错误信息并尝试重新下载网页(最多重试2次)。如果服务器返回5xx错误,则同样尝试重新下载网页。
- 返回获得的HTML内容。
而get_content()函数则实现了:
- 调用
download()函数下载指定URL的HTML内容,并对其进行解析,使用了BeautifulSoup模块进行HTML解析。 - 如果下载失败,则打印一条错误消息并退出程序;否则,返回解析后的HTML文档对象。
这两个函数通常用于Web爬虫或网站数据抓取等场景中,用爬取指定页面的HTML内容,进而提取需要的信息和数据。
# 下载网页html
def download(url, user_agent='wswp', num_retries=2):
print('downloading: %', url)
# 防止对方禁用Python的代理,导致forbidden错误
headers = {'User-agent': user_agent}
request = urllib.request.Request(url, headers=headers)
try:
html = urllib.request.urlopen(request).read()
except urllib.error.URLError as e:
print('download error:', e.reason)
html = None
if num_retries > 0:
# URLError是一个上层的类,因此HttpERROR是可以被捕获到的。code是HttpError里面的一个字段
if hasattr(e, 'code') and 500 <= e.code < 600:
return download(url, num_retries - 1)
return html
# 获得页面内容
def get_content(page_url):
html_result = download(page_url)
if html_result is None:
print('is None')
exit(1)
else:
pass
# 分析得到的结果,从中找到需要访问的内容
soup = BeautifulSoup(html_result, 'html.parser')
return soup请求头配置
headers = {
# 用户代理
'User-Agent': '"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36"'
}
USER_AGENT_LIST = [
'MSIE (MSIE 6.0; X11; Linux; i686) Opera 7.23',
'Opera/9.20 (Macintosh; Intel Mac OS X; U; en)',
'Mozilla/4.8 [en] (X11; U; SunOS; 5.7 sun4u)'
]主要函数
这段代码定义了一个名为GetNews()的函数,用于获取三个新闻网站的头条新闻,并返回一个包含这些新闻数据的二维数组allNews。具体过程如下:
- 声明了一个空数组
allNews,用于存储所有的新闻数据。 - 针对每个网站,调用
get_content()函数获得该网站的HTML文档对象。 - 针对每个网站,通过分析HTML文档对象,获取到该网站的新闻页面中的头条新闻,并提取出这些新闻的标题和URL链接,并将它们以[title, link]的形式添加到
pairs数组中。 - 将每个网站提取到的新闻数据的
pairs数组添加到allNews数组中,形成一个二维数组。 - 返回
allNews数组。 在代码中存在多处占位符'',这里我们并不知道其实际URL值,需要根据实际情况进行替换和确认。
# 获取新闻头条
def GetNews():
allNews = []
# 中国JS网
second_html = get_content('http://military.china.com.cn/')
pairs = []
num_list = second_html.find('div', attrs={'class': "layout_news"})
num_list = num_list.find_all('div', attrs={'class': "plist1"})
for i in num_list[:10]:
# 提取头条文本和链接
pairs.append([i.find('a').text, i.find('a')['href']])
allNews.append(pairs)
# 中国J网
second_html = get_content('http://www.81.cn/bq_208581/index.html')
pairs = []
num_list = second_html.find('ul', attrs={'id': "main-news-list"})
num_list = num_list.find_all('li')
for i in num_list[:10]:
# 提取头条文本和链接
pairs.append([i.find('img')['alt'],i.find('a')['href']])
allNews.append(pairs)
# 央广JS网
second_html = get_content('https://military.cnr.cn/zdgz/')
pairs = []
num_list = second_html.find('div', attrs={'class': "articleList"})
num_list = num_list.find_all('div', attrs={'class': 'item url_http'})
for i in num_list:
# 提取头条文本和链接
pairs.append([i.find('strong').text,i.find('a')['href']])
print(pairs)
allNews.append(pairs)
return allNews这段代码实现了一个名为NewsCrawl(newsList)的函数,用于自动抓取三个JS新闻网(中国J网、环球网、新华网)的头条新闻。具体步骤如下:
- 定义了三个获取各网站新闻数据的函数,分别为
GetZGJWNews(url)、GetHQNews(url)和GetXHNews(url),其中每个函数接受一个URL参数,并返回该网站的头条新闻数据。 - 在
NewsCrawl(newsList)函数中,根据用户的链接列表newsList,通过遍历判断每个链接属于哪个网站,并分别调用相应的函数来抓取对应网站的新闻数据,并将其存储到变量NewsClips中。 - 通过打开一个名为
fileName的文件,并以追加模式写入的方式,使用JSON格式存储每条新闻数据,然后将它们一起压缩在一个zip格式文件中。 - 最后函数返回压缩好的zip文件的路径。
# 环球网
def GetHQNews(url):
second_html = get_content(url)
pairs = []
# 获取文章主体
num_list = second_html.find('article')
# 获取文章所有段落
num_list = num_list.find_all('p')
for i in num_list:
c = i.text.replace('\xa0', ' ')
if c != '':
pairs.append(c)
return pairs
# GetHQNews('https://mil.huanqiu.com/article/4C7g93f4deM')
# 中国J网
def GetZGJWNews(url):
second_html = get_content(url)
pairs = []
# 获取文章主体
num_list = second_html.find('div', attrs={'id': "article-content"})
# 获取文章所有段落
num_list = num_list.find_all('p', attrs={'tag': "ueditor-text-p_display"})
for i in num_list:
c = i.text.replace('\xa0', ' ')
if c != '':
pairs.append(c)
return pairs
# print(GetZGJWNews('http://www.81.cn/bq_208581/16214803.html'))
# 新华网
# XHurl = 'http://www.news.cn/mil/2023-03/16/c_1211738298.htm'
def GetXHNews(url):
second_html = get_content(url)
pairs = []
# 获取文章主体
num_list = second_html.find('div', attrs={'id': "detail"})
# 获取文章所有段落
num_list = num_list.find_all('p')
for i in num_list:
c = i.text.replace('\xa0', ' ')
if c != '':
pairs.append(c)
return pairs
# GetXHNews(XHurl)
# 新闻爬虫
def NewsCrawl(newsList):
NewsClips=[]
fileName = newsClips_root + r'crawlData/NewsClips.json'
# 遍历用户输入的链接,判断链接属于哪个网站
for i in newsList:
if '81' in i :
NewsClips+=GetZGJWNews(i)
if 'huanqiu' in i :
NewsClips+=GetHQNews(i)
if 'www.news.cn' in i :
NewsClips+=GetXHNews(i)
with open(fileName, 'w') as f:
f.write('')
# 处理获取的数据,存入Json文件,并打包返回文件路径
for i in NewsClips:
dic = {}
dic['text'] = i
dic['nodes'] = {}
dic['rels'] = {}
with open(fileName, 'a') as f:
f.write(json.dumps(dic, ensure_ascii=False))
f.write('\n')
shutil.make_archive(fileName, 'zip', newsClips_root + 'crawlData')
return fileName + '.zip'
技术共进,成长同行——讯飞AI开发者社区
更多推荐


 2
2 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)