
【9.19日报】计算机科学、人工智能、自然语言处理、多模态技术、医学信息学等多个领域
聚焦 embodied AI 领域的全向视觉(360°视觉)技术,系统梳理全向视觉在机器人、工业检测、环境监测等领域的核心价值,分析当前全向视觉生成、感知、理解等方向的技术瓶颈,提出针对性解决方案,同时总结工业需求与学术研究驱动下全向视觉的发展趋势,为相关研究提供清晰的技术路线图。:聚焦阿拉伯语领域,构建大规模阿拉伯语中心的指令与翻译模型,通过针对性的数据构建与模型优化,解决阿拉伯语在多模态模型中
今天给大家带来9月18日的github和huggingface的热点论文项目,精选12篇前沿论文,覆盖计算机科学、人工智能、自然语言处理、多模态技术、医学信息学等多个领域,有需要开源代码和论文的,点击下方链接即可免费领取。
1、HALA Technical Report: Building Arabic-Centric Instruction & Translation Models at Scale
作者:Hasan Abed Al Kader Hammoud(King Abdullah University of Science and Technology)
亮点:聚焦阿拉伯语领域,构建大规模阿拉伯语中心的指令与翻译模型,通过针对性的数据构建与模型优化,解决阿拉伯语在多模态模型中代表性不足、指令理解与翻译精度低的问题,为阿拉伯语自然语言处理提供专用且高效的基础模型支持。
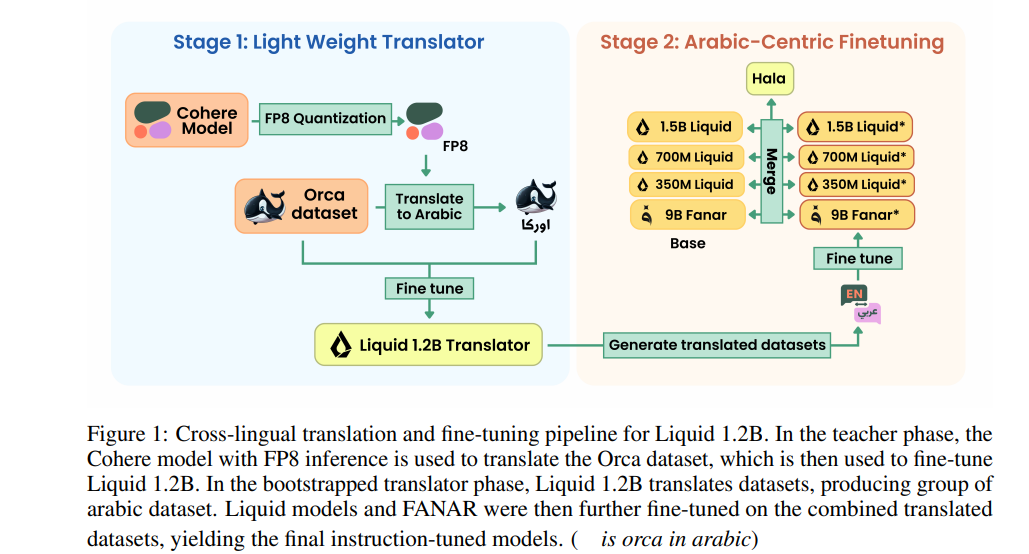
论文:https://arxiv.org/pdf/2509.14008
项目:https://github.com/hammoudhasan/Hala
意义:填补阿拉伯语专用指令与翻译模型的规模化空白,推动阿拉伯语在AI领域的应用普及,促进多语言AI生态的均衡发展。
2、SAIL-VL2 Technical Report
作者:Douyin SAIL Team(Bytedance)、LV-NUS Lab(National University of Singapore)
亮点:提出SAIL-VL2多模态视觉语言基础模型,创新采用大规模数据筛选与评分 pipeline 提升训练数据质量与分布合理性,设计“预训练视觉编码器→多模态预训练→思维融合SFT-RL混合训练”的渐进式训练框架,同时引入高效稀疏混合专家(MoE)架构,在2B和8B参数规模下刷新106个图像与视频数据集性能,尤其在MMMU、MathVista等复杂推理基准上表现突出。
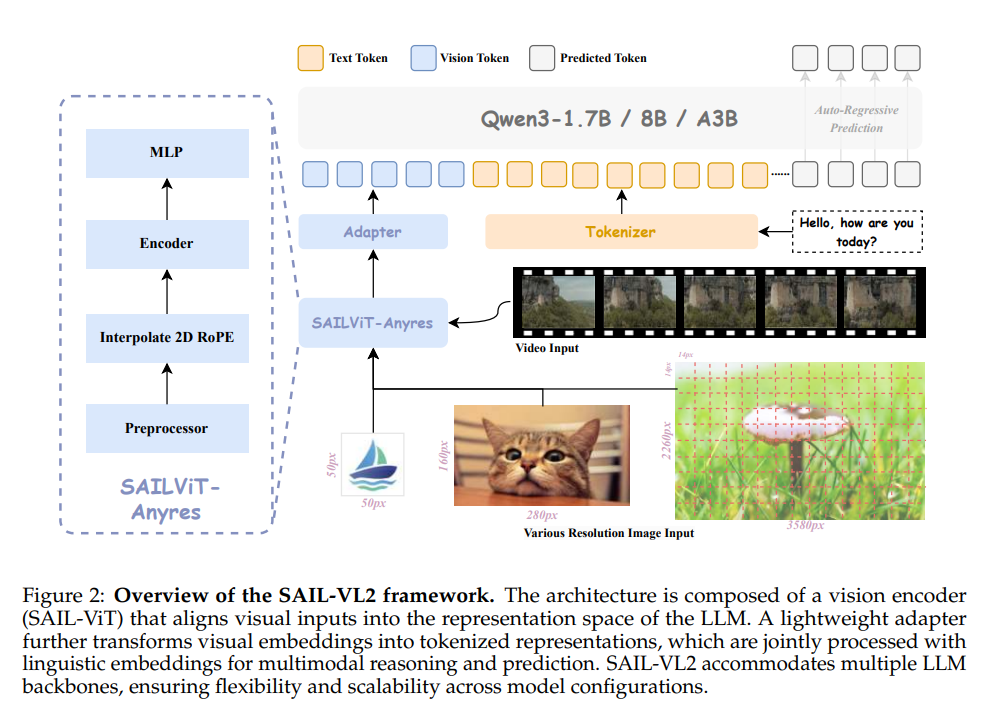
论文:https://arxiv.org/pdf/2509.14033
项目:https://github.com/BytedanceDouyinContent; https://huggingface.co/BytedanceDouyinContent
意义:为开源多模态社区提供高效可扩展的基础模型,推动视觉语言模型在细粒度感知到复杂推理场景的能力突破,降低多模态AI技术的应用门槛。
3、PANORAMA: The Rise of Omnidirectional Vision in the Embodied AI Era
作者:Xu Zheng(Hong Kong University of Science and Technology (Guangzhou))
亮点:聚焦 embodied AI 领域的全向视觉(360°视觉)技术,系统梳理全向视觉在机器人、工业检测、环境监测等领域的核心价值,分析当前全向视觉生成、感知、理解等方向的技术瓶颈,提出针对性解决方案,同时总结工业需求与学术研究驱动下全向视觉的发展趋势,为相关研究提供清晰的技术路线图。
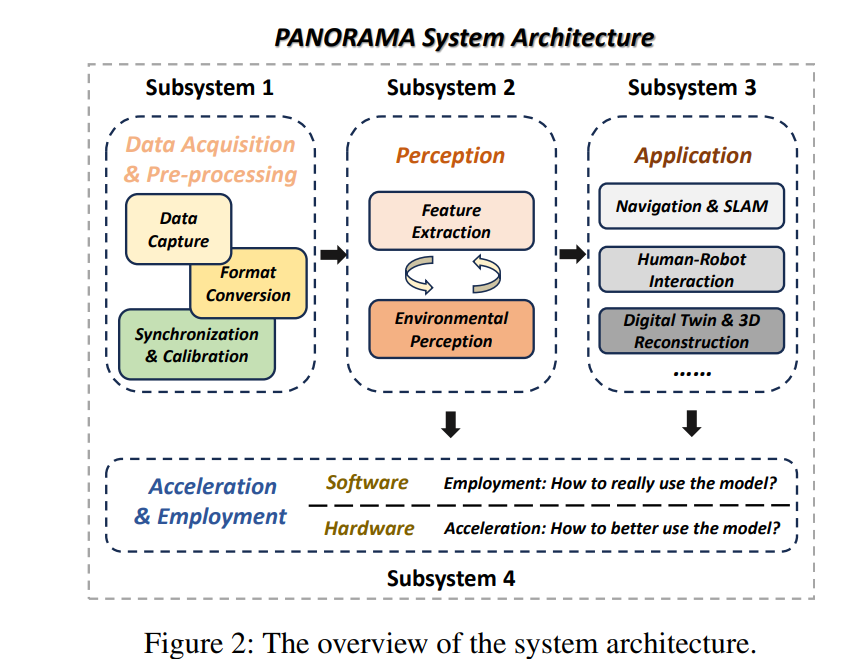
论文:https://arxiv.org/pdf/2509.12989
意义:填补全向视觉在 embodied AI 领域的研究综述空白,引导学术与工业界关注全向视觉技术,推动其在复杂环境感知与决策场景的落地应用。
4、GENEXAM: A MULTIDISCIPLINARY TEXT-TO-IMAGE EXAM
作者:Zhaokai Wang(Shanghai Jiao Tong University、Shanghai AI Laboratory)
亮点:构建跨学科文本到图像生成评测基准GENEXAM,设计具有严格生成约束的复杂多样提示(如化学反应方程式绘制、物理实验装置示意等),提供精准参考答案(真值图像)与定制化详细评分标准,以层级化知识体系覆盖多学科领域,同时集成“理解-推理-生成”全流程能力评估,全面衡量模型在专业领域的文本到图像生成精度。
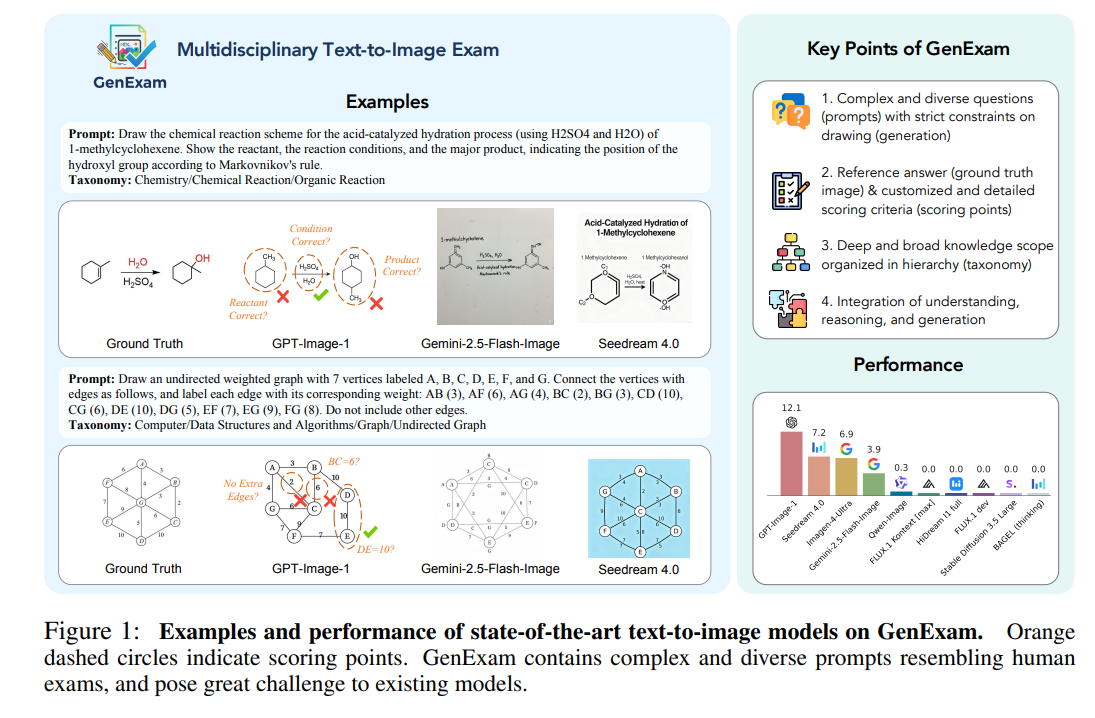
论文:https://arxiv.org/pdf/2509.14232
项目:https://github.com/OpenGVLab/GenExam
意义:解决现有文本到图像评测基准在专业领域覆盖不足、评分标准模糊的问题,为多学科场景下的图像生成模型提供精准评测工具,推动专业领域AIGC技术的性能提升。
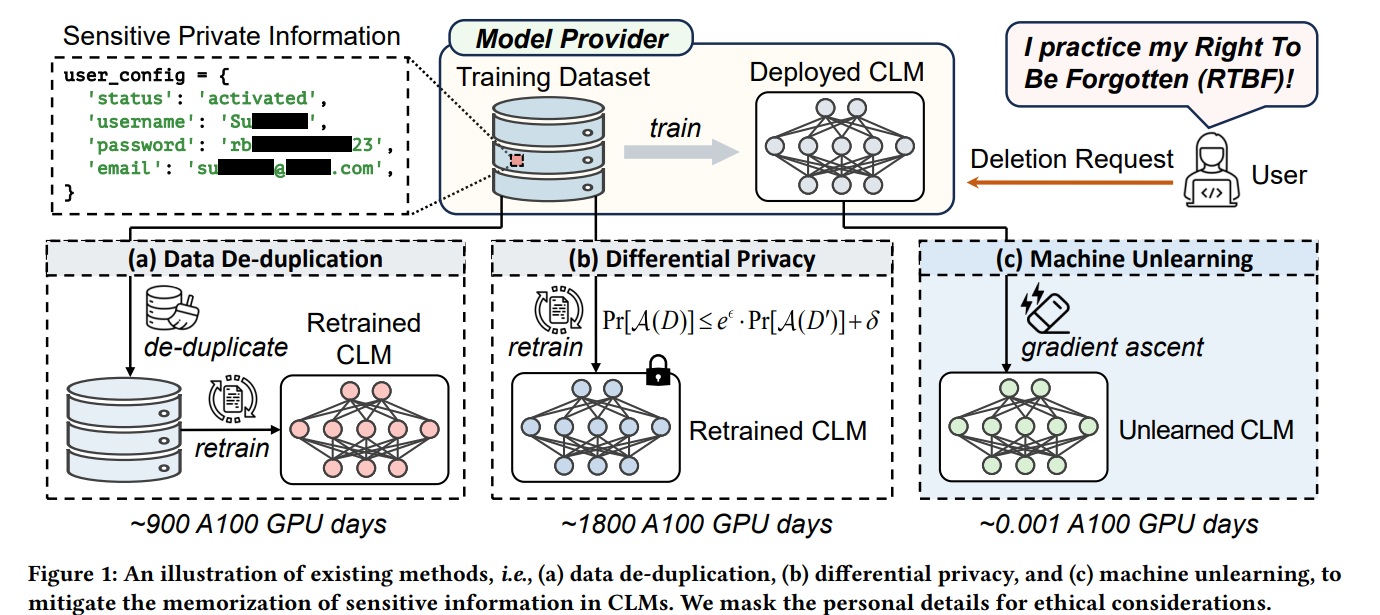
5、Scrub It Out! Erasing Sensitive Memorization in Code Language Models via Machine Unlearning
作者:Zhaoyang Chu(Huazhong University of Science and Technology)
亮点:针对代码语言模型中敏感信息记忆问题,提出基于机器遗忘的敏感记忆清除方法,通过设计针对性的数据筛选与遗忘训练策略,精准定位并清除模型对敏感代码片段(如私有算法、涉密项目代码)的记忆,同时保证模型在正常代码生成任务中的性能不受显著影响,平衡模型安全性与可用性。
论文:https://arxiv.org/pdf/2509.13755
项目:https://github.com/Zhaoyang-Chu/code-unlearning
意义:解决代码语言模型的敏感信息泄露风险,为代码生成AI的安全部署提供关键技术支撑,推动AI在软件开发领域的合规应用。
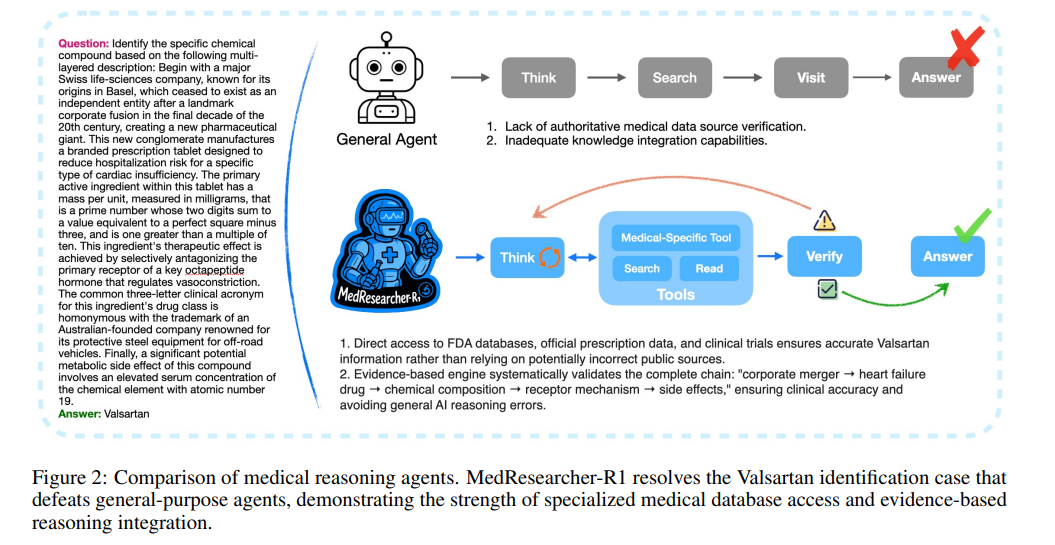
6、MedResearcher-R1: Expert-Level Medical Deep Researcher via A Knowledge-Informed Trajectory Synthesis Framework
作者:Ailing Yu(Ant Group)
亮点:提出医疗领域深度研究智能体MedResearcher-R1,创新基于医疗知识图谱提取稀有医疗实体子图的最长链,生成复杂多跳问答对以补充模型密集型医疗知识;同时集成定制化医疗专用检索工具,解决通用深度研究Agent在医疗领域知识不足、检索工具不匹配的问题,提升复杂医疗任务的推理与信息合成精度。
论文:https://arxiv.org/pdf/2508.14880
项目:https://github.com/AQ-MedAI/MedResearcher-R1
意义:推动AI在医疗领域的深度应用,为临床研究、医学文献分析、患者咨询等场景提供专业级智能支持,助力医疗行业的智能化升级。
7、MARS2 2025 Challenge on Multimodal Reasoning: Datasets, Methods, Results, Discussion, and Outlook
作者:Peng Xu(未明确标注核心机构,联合团队含Argonne National Laboratory、University of Chicago等)

亮点:组织MARS2 2025多模态推理挑战赛,发布大规模多模态推理数据集,涵盖图像、文本、音频等多模态输入与复杂推理任务;系统汇总参赛队伍的主流方法(如跨模态注意力融合、知识图谱增强推理等)、竞赛结果与性能排名,深入分析当前多模态推理技术的优势与不足,并对未来研究方向(如长序列多模态推理、低资源模态适配)提出展望。
论文:https://arxiv.org/pdf/2509.14142
项目:https://github.com/mars2workshop/
意义:为多模态推理领域提供统一的评测基准与技术交流平台,推动学术界与工业界对多模态推理技术的深入研究,加速技术突破与落地。
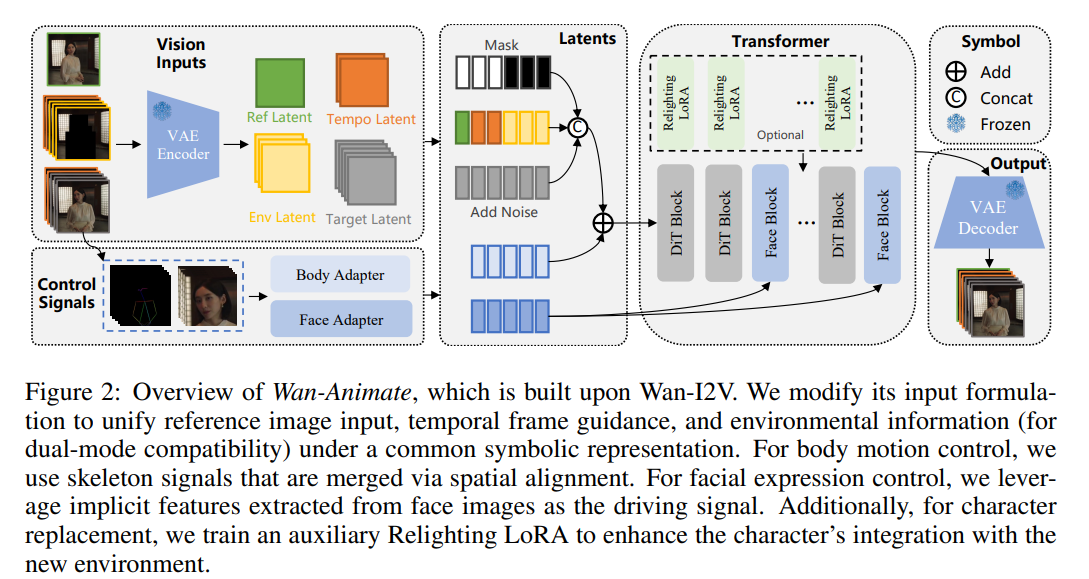
8、WAN-ANIMATE: UNIFIED CHARACTER ANIMATION AND REPLACEMENT WITH HOLISTIC REPLICATION
作者:HumanAIGC Team(Tongyi Lab, Alibaba)
亮点:提出统一角色动画与替换框架WAN-Animate,基于WAN模型改进输入范式以区分参考条件与生成区域,实现“角色动画生成”与“角色替换”任务的统一表示;通过空间对齐骨架信号复现身体动作,结合从源图像提取的隐式面部特征还原表情,保证生成视频的可控性与表现力;额外设计重光照LoRA模块,在角色替换时适配场景光照与色调,实现无缝环境融合。
论文:https://arxiv.org/pdf/2509.14055
项目:https://humanaigc.github.io/wan-animate/
意义:突破现有角色动画工具任务单一、生成效果与场景融合度低的问题,为影视制作、游戏开发、虚拟人交互等领域提供高效的角色动画与替换解决方案。
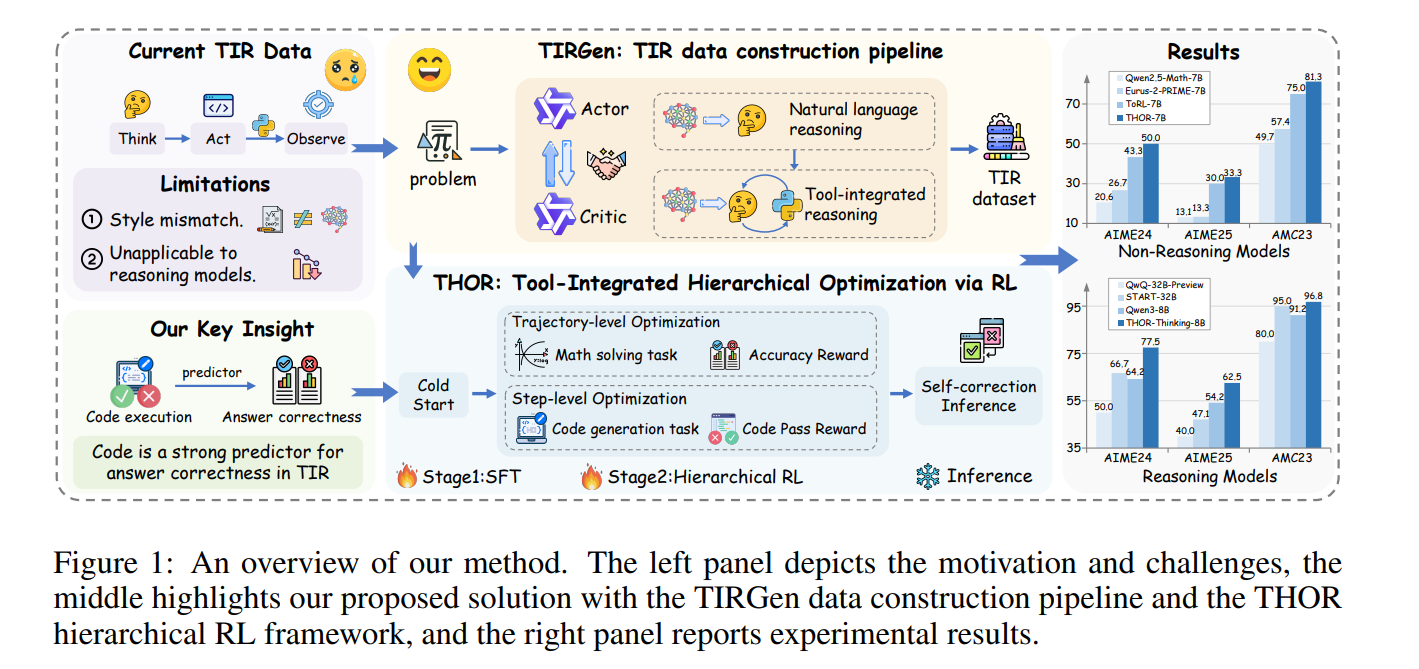
9、THOR: TOOL-INTEGRATED HIERARCHICAL OPTIMIZATION VIA RL FOR MATHEMATICAL REASONING
作者:Qikai Chang(University of Science and Technology of China、iFLYTEK Research)
亮点:针对语言模型在数学推理中高精度计算与符号操作能力不足的问题,提出THOR框架:首先通过多智能体演员-评论家(Actor-Critic)流水线TIRGen构建高质量工具集成推理路径数据集,保证数据与模型策略的对齐性;其次设计层级化强化学习(RL)策略,联合优化轨迹级问题解决与步骤级代码生成,同时引入工具使用反馈机制提升推理精度,在数值计算、符号推导等任务中显著提升模型性能。
论文:https://arxiv.org/pdf/2509.13761
项目:https://github.com/JingMog/THOR
意义:推动数学推理AI从“定性推理”向“定量精准计算”升级,为科学计算、工程建模、教育辅导等依赖高精度数学推理的场景提供技术支撑。
10、Improving Context Fidelity via Native Retrieval-Augmented Reasoning
作者:Suyuchen Wang(Université de Montréal、Mila - Quebec AI Institute)
亮点:提出CARE原生检索增强推理框架,解决语言模型在基于给定上下文回答时的一致性(保真度)问题。该框架不依赖昂贵的监督微调或额外网页搜索,而是教会模型在推理过程中显式集成给定上下文的检索信息,通过“推理+原生检索增强”的双流程设计,提升模型对上下文信息的利用率,减少因信息遗漏或误读导致的回答不一致。
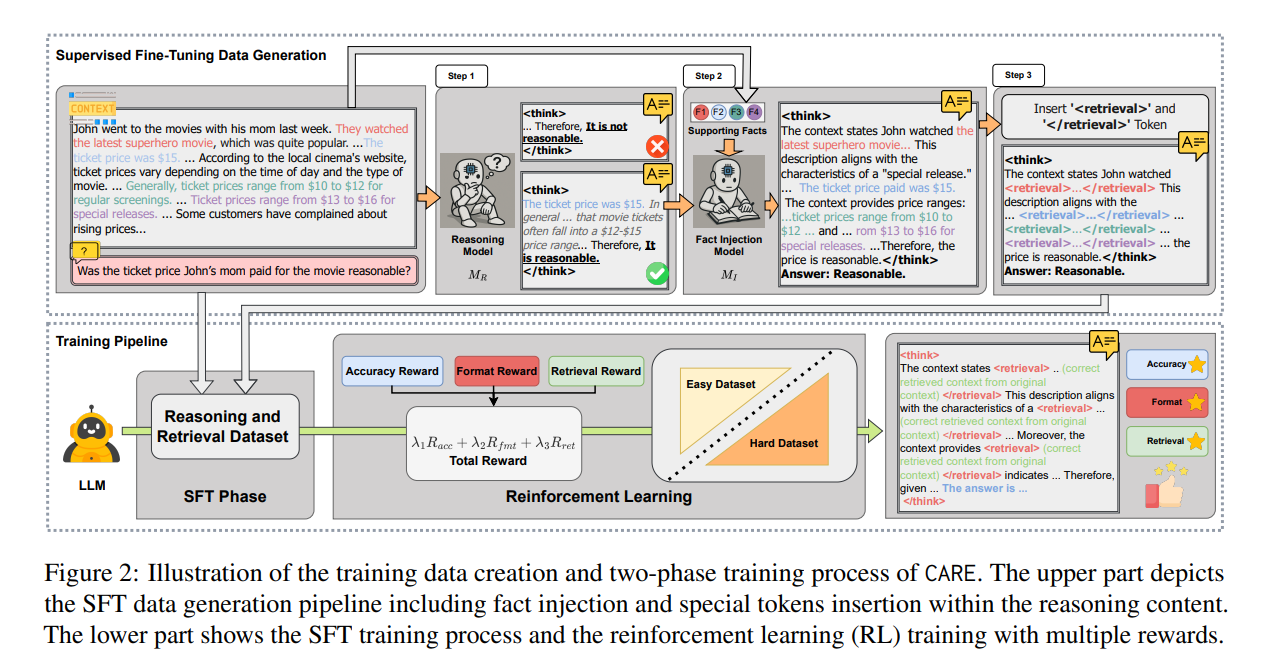
论文:https://arxiv.org/pdf/2509.13683
项目:https://github.com/FoundationAgents/CARE
意义:提升语言模型在信息密集型任务(如文档问答、知识问答)中的回答可靠性,为需要精准依赖给定上下文的AI应用(如智能客服、法律文档分析)提供关键技术保障。
11、AERIS: Argonne Earth Systems Model for Reliable and Skillful Predictions
作者:Väinö Hatanpää(Argonne National Laboratory)
亮点:提出地球系统预测模型AERIS,采用1.3B到80B参数的像素级Swin扩散Transformer架构,解决现有扩散基天气预测方法在高分辨率下难以稳定缩放的问题;创新设计SWiPe技术,将窗口并行与序列、流水线并行结合,实现基于窗口的Transformer分片,无额外通信成本且不增加全局批次大小;在Aurora超级计算机(10080节点)上实现10.21 ExaFLOPS(混合精度)算力,显著提升天气与季节尺度预测的精度与效率。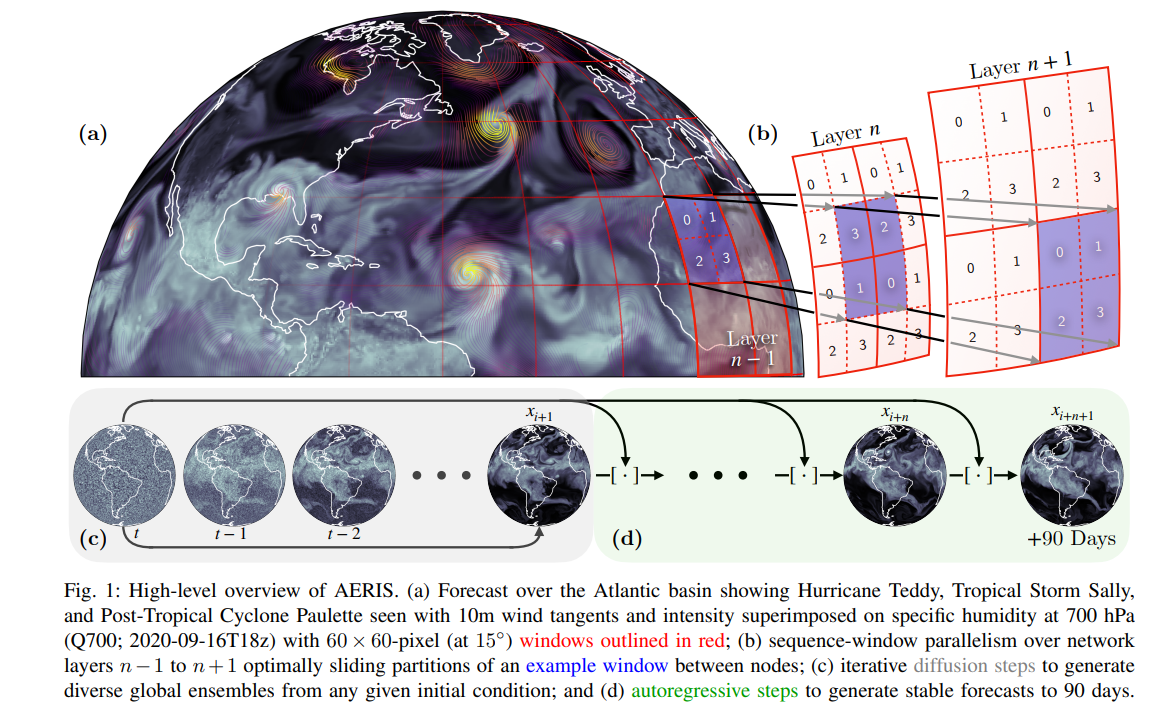
论文:https://arxiv.org/pdf/2509.13523
项目:暂未公开具体项目网址
意义:推动地球系统预测从传统数值方法向AI驱动的高分辨率、高可靠性方向升级,为极端天气预警、气候变化研究、农业生产规划等提供更精准的科学支撑。
12、LLM-I: LLMs are Naturally Interleaved Multimodal Creators
作者:Zirun Guo(Zhejiang University、ByteDance BandAI)
亮点:提出LLM-I交错多模态生成框架,将图像-文本交错生成重构为工具使用问题,突破现有统一模型“单一工具”瓶颈(仅支持合成图像,缺乏事实 grounding 与程序精度)。框架让核心LLM/MLLM智能体通过强化学习(RL)训练,灵活调度在线图像搜索、扩散生成、代码执行、图像编辑等专用视觉工具,结合规则逻辑与LLM/MLLM评估器的混合奖励系统优化工具选择与应用,在4个基准上大幅超越现有方法。
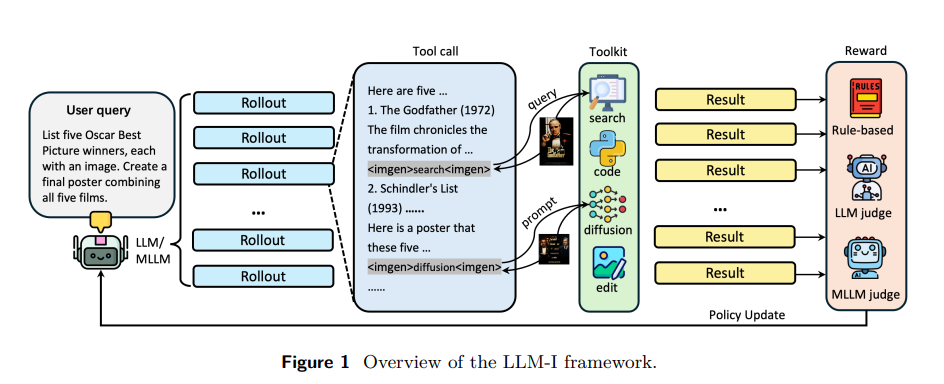
论文:https://arxiv.org/pdf/2509.13642
项目:https://github.com/ByteDance-BandAI/LLM-I
意义:拓展语言模型在多模态生成中的灵活性与实用性,为内容创作(如图文博客、教程制作)、智能设计等场景提供更符合人类创作流程的AI工具链。
关注下方《AI前沿速递》🚀🚀🚀
各种重磅干货,第一时间送达
码字不易,欢迎大家点赞评论收藏

技术共进,成长同行——讯飞AI开发者社区
更多推荐



 23
23 0
0- 0



 已为社区贡献24条内容
已为社区贡献24条内容

所有评论(0)