
游戏数据的分析
分析从 1980 年到 2023 年的视频游戏列表,可视化展示
目录
6.我们可以使用生成NLP来生成朗朗上口的游戏标题或情节吗?
前言
数据集包含从 1980 年到 2023 年的视频游戏列表,它还提供了发布日期、用户评论评级和评论家评论评级等信息。您不仅可以找到这里提到的流行游戏,还可以找到我们及时忘记的晦涩难懂的独立游戏!
Backloggd 是一个混合了社交元素的视频游戏收藏网站,专注于让您的游戏资料栩栩如生。创建一个免费帐户,开始记录您玩过的游戏,然后随时进行评分和评论!详细记录平台、游戏时间,甚至每日日记,以跟踪您的每日游戏进度和游戏通关情况。这一切都是根据您想要记录的量身定制的,因此您的个人资料适合您。除此之外,您还可以创建游戏列表、与其他用户加好友、关注他们的活动等等!该数据集的目的是深入了解游戏类型流行趋势。
完成下列数据分析并作出相应的可视化:
哪些游戏类型最受欢迎?
每种游戏类型的流行趋势是什么?
我们能确定情节、类型和受欢迎程度之间的关系吗?
我们可以使用生成NLP来生成朗朗上口的游戏标题或情节吗?
用户现在倾向于玩哪些游戏,哪些游戏一直挂在游戏架上?
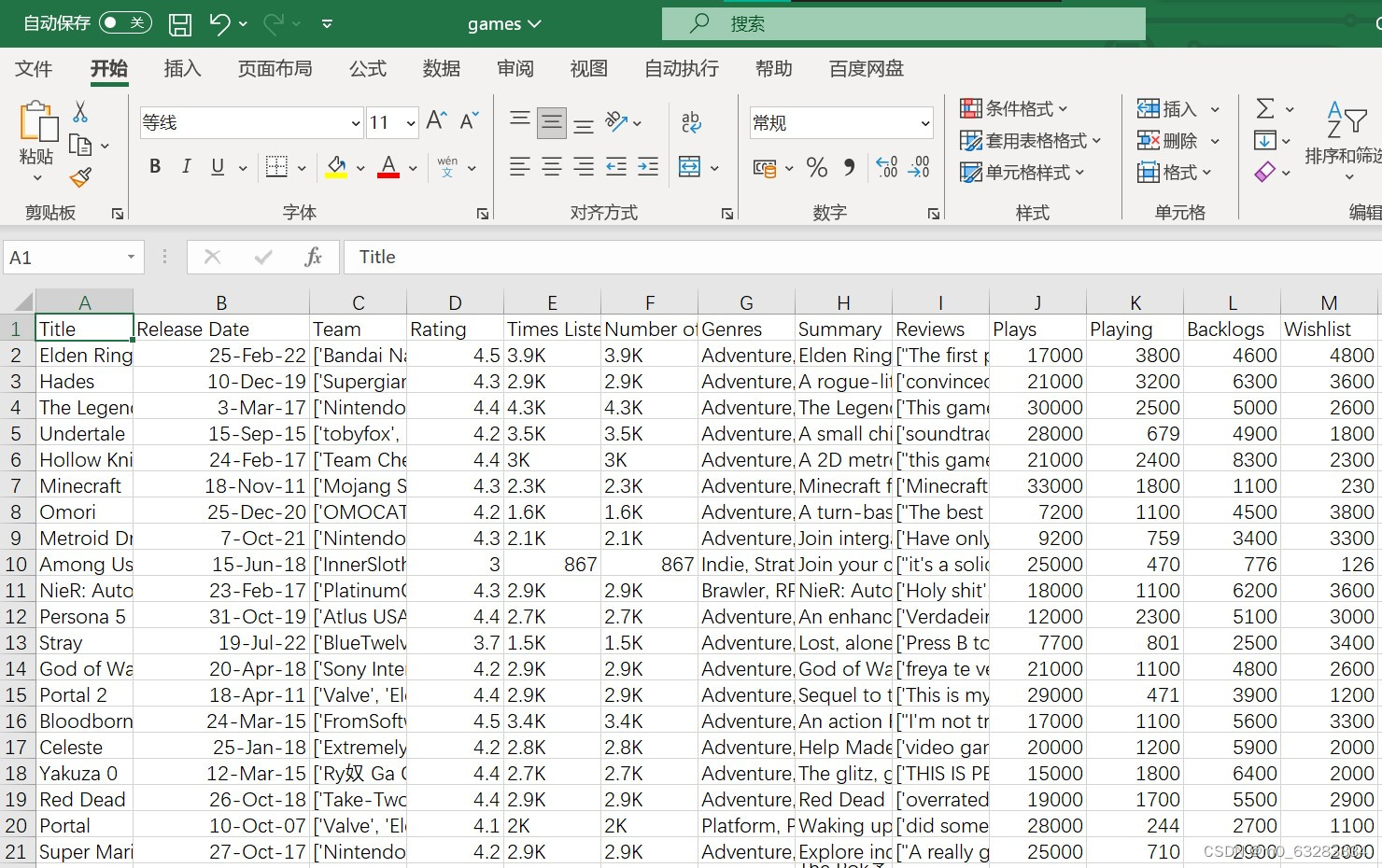
一、数据集概述
1980年至2023年的视频游戏的游玩人数、发布日期、游戏评分等并暂存于名为games的csv文件中。
二、数据分析
1.引入库
import pandas as pd
import matplotlib.pyplot as plt
from collections import Counter
import re
import numpy as np
import nltk
from nltk.corpus import stopwords
from nltk.stem import SnowballStemmer
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.metrics import accuracy_score
import csv
from wordcloud import WordCloud 2.读入数据并查看基本信息
data = pd.read_csv('./games.csv')
data.info() #查看数据基本信息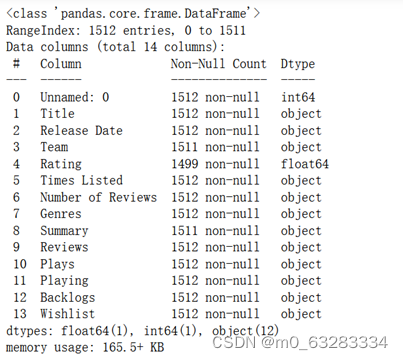
一共涉及1512个游戏 提示:rating 评分、numbers of reviews评论数量、Times Listed被加入列表的次数、backlogs加入游戏列表的用户数量.
发现rating栏有部分缺失值,但是不多,可以直接删除缺失值
data.dropna(inplace=True) #在原始数据上删除缺失值
data.isnull().sum() #统计缺失值,删除成功
data = data.drop(data.columns[0], axis=1) #删除第一列索引,方便数据去重
data.drop_duplicates(inplace=True) #删除重复的行
data.to_csv('D:/python/python大作业/games.csv', index=False)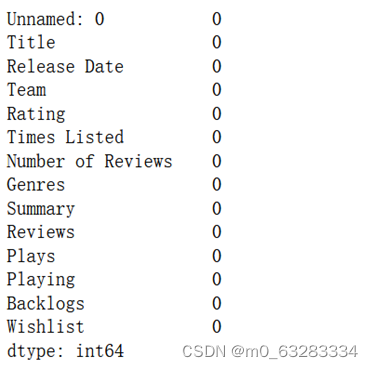
3.哪类游戏最受欢迎?
(1)根据每种游戏类型在Genres中出现的次数初步分析。
# 处理第10列
data['Genres'] = data['Genres'].str.replace('[','').str.replace(']','').str.replace("'","")
#保存到原文件
data.to_csv('D:/python/python大作业/games.csv', index=False)
genres_count = {} #创建空字典
for genres in data['Genres']:
for genre in str(genres).split(','):
genre = genre.strip()
if genre in genres_count:
genres_count[genre] += 1
else:
genres_count[genre] = 1
#取出前十名
top10 = sorted(genres_count.items(), key=lambda x: x[1], reverse=True)[:10]
# 打印前10名
for i, (key, value) in enumerate(top10):
print(f'{i+1}. {key}: {value}')
# 绘制彩色条形图
keys = [x[0] for x in top10]
values = [x[1] for x in top10]
colors = np.random.rand(len(keys), 3) #颜色随机选择彩色
plt.xticks(rotation=45) #x轴旋转45°显示
plt.bar(keys, values, color=colors)
plt.title('Top 10 Game Genres by Total Plays')
plt.xlabel('Genre')
plt.ylabel('Number')
plt.show()
运行结果:
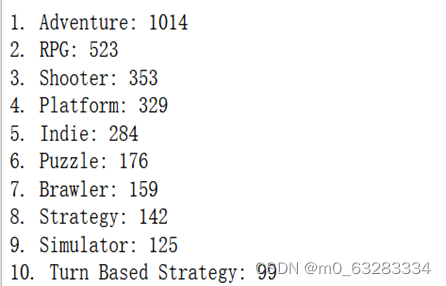
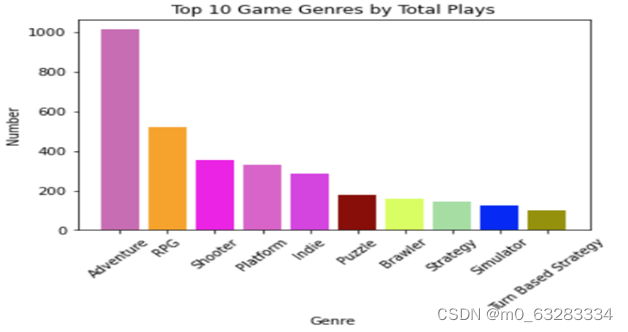
初步分析得到,前3名最受欢迎的游戏类型是:Adventure、RPG、Shooter。
(2)根据每种类型的Plays人数
# 定义转换函数,把形如17K的字符串转换成17000
def convert(s):
s = str(s)
if s.endswith('K'):
return float(s[:-1]) * 1000
else:
return s# 对Play单元格应用转换函数
data['Plays'] = data['Plays'].apply(convert)
# 保存处理后的数据到原文件中
data.to_csv('D:/python/python大作业/games.csv', index=False)games_df = pd.read_csv('./games.csv')
# 将Genres列中的字符串转换为列表
games_df['Genres'] = games_df['Genres'].str.split(',')
# 将每个游戏的类型拆分成多行
games_df = games_df.explode('Genres')
# 按照类型计算总游玩人数
genre_play_counts = games_df.groupby('Genres')['Plays'].sum()
# 按照游玩人数排序并取前十名
top_genres = genre_play_counts.sort_values(ascending=False).head(7)
# 打印结果
print(top_genres)
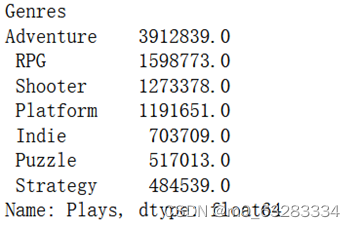
将前7名用柱状图表示出来
根据每种游戏类型玩的人数,前7名受欢迎的游戏如上图所示。其中,最受欢迎的前三名是Adventure、RPG、Platform.
4.每种游戏类型的流行趋势是什么?
根据每种游戏类型的Plays、Playing、Backlogs、Wishlist画图综合分析。
# 对Playing、backlogs、wishlist单元格应用转换函数
data['Playing'] = data['Playing'].apply(convert)
data['Backlogs'] = data['Backlogs'].apply(convert)
data['Wishlist'] = data['Wishlist'].apply(convert)
#转换为浮点型方便计算:Plays、Playing、Backlogs、Wishlist
data.iloc[:, 9] = data.iloc[:, 9].astype(float)
data.iloc[:, 10] = data.iloc[:, 10].astype(float)
data.iloc[:, 11] = data.iloc[:, 11].astype(float)
data.iloc[:, 12] = data.iloc[:, 12].astype(float)
# 保存处理后的数据到原文件中
data.to_csv('./games.csv', index=False)genres_dict = {}
for i in range(len(data)):
genres = str(data.iloc[i]['Genres']).split(', ')
for genre in genres:
if genre not in genres_dict:
genres_dict[genre] = [data.iloc[i]['Plays'], data.iloc[i]['Playing'], data.iloc[i]['Backlogs'], data.iloc[i]['Wishlist']]
else:
genres_dict[genre][0] += data.iloc[i]['Plays']
genres_dict[genre][1] += data.iloc[i]['Playing']
genres_dict[genre][2] += data.iloc[i]['Backlogs']
genres_dict[genre][3] += data.iloc[i]['Wishlist']#绘制每种游戏类型的流行趋势图
genres_list = []
plays_list = []
playing_list = []
backlogs_list = []
wishlist_list = []
for genre, nums in genres_dict.items():
genres_list.append(genre)
plays_list.append(nums[0])
playing_list.append(nums[1])
backlogs_list.append(nums[2])
wishlist_list.append(nums[3])
plt.figure(figsize=(15, 10))
plt.plot(genres_list, plays_list, label='Plays')
plt.plot(genres_list, playing_list, label='Playing')
plt.plot(genres_list, backlogs_list, label='Backlogs')
plt.plot(genres_list, wishlist_list, label='Wishlist')
plt.xticks(rotation=45)
plt.legend()
plt.show()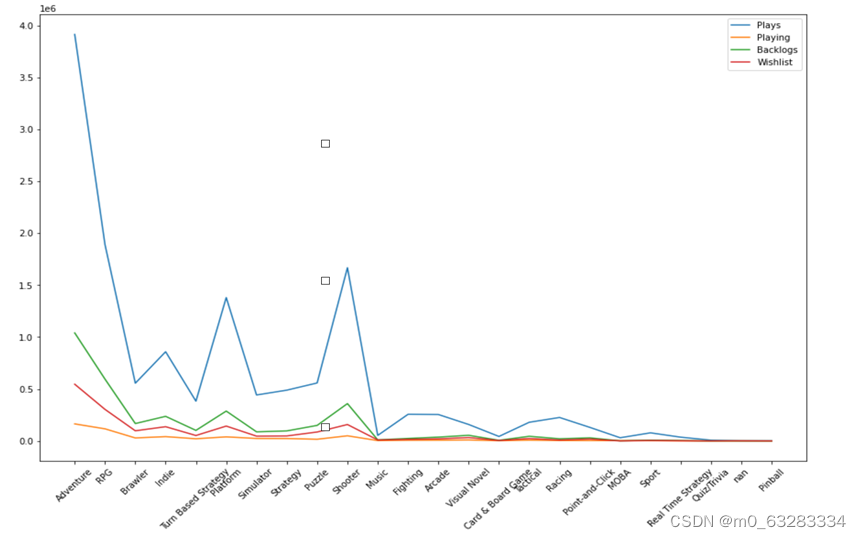
从上图可以看出每种游戏类型的流行趋势。蓝色的线Plays表示游玩的人数,可以看出Adventure等类型的游戏比较受欢迎。橙色的线表示Playing,即正在玩的人数。中间的Backlogs、Wishlist是用户加入游戏列表的人数,展现了每种游戏类型的未来的趋势,可以看出Adventure、Platform、Shooter类型的未来会持续受欢迎,同时,这三者的四项指标都很高。
5.我们能确定情节、类型和受欢迎程度之间的关系吗?
问题(1)已经分析出游戏类型和受欢迎程度之间的关系,此环节运用nltk,统计Summary栏出现的高频名词和动词,进一步确定情节、类型和受欢迎程度三者之间的关系。
#下载nltk数据包中的停用词列表和分词器所需的数据
nltk.download('stopwords')
nltk.download('punkt')# 提取Summary列中的单词
words = []
for summary in data['Summary']:
summary = str(summary)
words += nltk.word_tokenize(summary.lower())
# 去除停用词
stopwords = nltk.corpus.stopwords.words('english')
words = [word for word in words if word.isalpha() and word not in stopwords]
# 统计词频
word_count = Counter(words)
# 提取高频动词和名词
#选verb出现频率大于60的
top_verbs = [word for word, count in word_count.items() if nltk.pos_tag([word])[0][1].startswith('VB') and count > 60]
#选noun出现频率大于150的
top_nouns = [word for word, count in word_count.items() if nltk.pos_tag([word])[0][1].startswith('NN') and count > 150]
#150和60是先绘制所有的高频名词和动词,得到大概前10个左右的频率修改的参数
#打印高频词
print('Top Verbs:')
print(top_verbs)
print('Top Nouns:')
print(top_nouns)
运行结果:

# 将词语存储在CSV文件中
with open('./words.csv', 'w', newline='') as file:
writer = csv.writer(file)
writer.writerow(['words'])
for word in top_verbs:
writer.writerow([word])
for word in top_nouns:
writer.writerow([word])
# 从CSV文件中读取词语
with open('./words.csv', 'r') as file:
reader = csv.reader(file)
next(reader) # 跳过标题行
words = [row[0] for row in reader]
# 绘制词云图
wordcloud = WordCloud(width=800, height=400, background_color='white')
wordcloud.generate(' '.join(words))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.show()生成的word.csv截图:
词云图:

可以看出,出现的高频名词有fighting、find、released、save等,出现的高频动词有action、world、battle、adventure等。 分析:在高频词中,出现的更多的是竞技、冒险、对抗类的词汇,与受欢迎程度高的Adventure、RPG、Shooter等游戏类型相吻合。可以看出,玩家更喜欢玩竞技、冒险、对抗类等刺激有趣的游戏。
# 绘制词频图
plt.figure(figsize=(20, 10))
plt.subplot(1, 2, 1)
plt.bar([word.upper() for word in top_verbs], [word_count[word] for word in top_verbs])
plt.xticks(rotation=45)
plt.title('Top Verbs')
plt.subplot(1, 2, 2)
plt.bar([word.upper() for word in top_nouns], [word_count[word] for word in top_nouns])
plt.xticks(rotation=45)
plt.title('Top Nouns')
plt.tight_layout()
plt.show()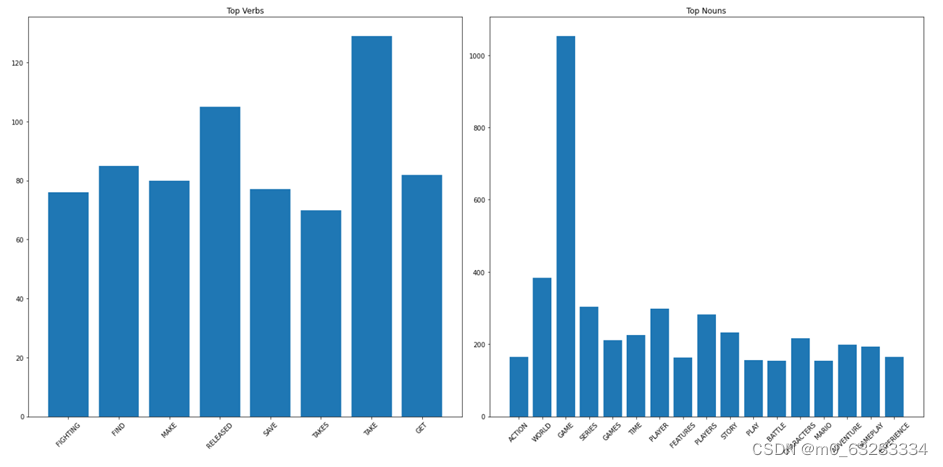
6.我们可以使用生成NLP来生成朗朗上口的游戏标题或情节吗?
使用NLTK库中的文本分类模块进行实现
#1. 将游戏简介和游戏标题分别存储到两个列表中:
summaries = data['Summary'].tolist()
titles = data['Title'].tolist()#2. 对游戏简介进行预处理,包括去除停用词、词干提取等操作:
stop_words = set(stopwords.words('english'))
stemmer = SnowballStemmer('english')
def preprocess(summary):
summary = str(summary)
words = nltk.word_tokenize(summary.lower())
words = [w for w in words if w.isalpha() and w not in stop_words]
words = [stemmer.stem(w) for w in words]
return words
summaries_processed = [preprocess(summary) for summary in summaries]#3. 构建特征向量,将每个游戏简介表示成一个向量。使用词袋模型,即将每个单词看作一个特征,向量的每个维度表示该单词在游戏简介中出现的次数。
vectorizer = CountVectorizer(analyzer=lambda x: x)
summaries_vectorized = vectorizer.fit_transform(summaries_processed)
#4. 使用朴素贝叶斯分类器进行训练和预测。
#首先将游戏标题转换成数字标签,然后将游戏简介向量和标签作为输入,训练分类器。
#然后对每个游戏简介向量进行预测,得到游戏标题的数字标签,最后将数字标签转换回游戏标题。
label_map = {}
for i, title in enumerate(titles):
if title not in label_map:
label_map[title] = len(label_map)
labels = [label_map[title] for title in titles]
clf = MultinomialNB()
clf.fit(summaries_vectorized, labels)
predictions = clf.predict(summaries_vectorized)
predicted_titles = [title for title, label in label_map.items() if label in predictions]
#predicted_titles即预测的游戏标题列表
print(predicted_titles[:20]) #打印前20个
前20个如上,经过比对,发现与游戏原本的标题基本吻合。基本能通过情节生成游戏标题。
7.用户现在倾向于玩哪些游戏,哪些游戏一直挂在游戏架上?
(1)根据playing的人数,分析现在用户倾向于玩哪些游戏。
# 按Playing列降序排列,取前10行
top10 = data.sort_values(by='Playing', ascending=False).head(10)
# 绘制水平条形图
plt.barh(top10['Title'], top10['Playing'])
plt.title('Top 10 Most Played Games')
plt.xlabel('Number of Players')
plt.show()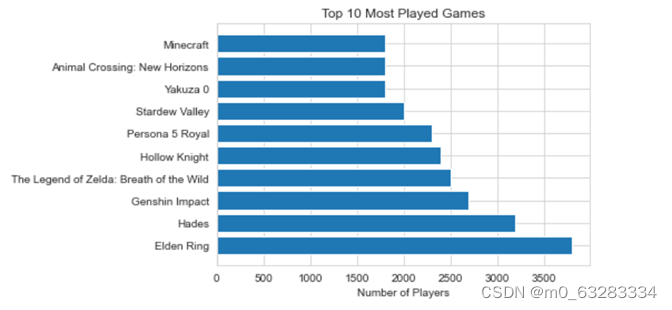
现在受欢迎的游戏前10名如上图,其中最受欢迎的前三个游戏是Elden Ring、Hades、Genshin Impact.
(2)根据发行的时间,来分析游戏挂在游戏架上的时间。
其中,releases on TBD是待定发布,还没有上架。
# 筛选出Release Date不是TBD的游戏
data = data[data['Release Date']!='releases on TBD']
# 将Release Date转换成日期格式
data['Release Date'] = pd.to_datetime(data['Release Date'])
# 按Release Date升序排序
df = data.sort_values('Release Date')
# 选出最老的十款游戏
df_top10 = df.head(10)
# 绘制散点图
plt.figure(figsize=(12,6))
plt.scatter(df_top10['Title'], df_top10['Release Date'])
plt.xticks(rotation=45)
plt.xlabel('Game Title')
plt.ylabel('Release Date')
plt.title('Top 10 Oldest Games')
plt.show()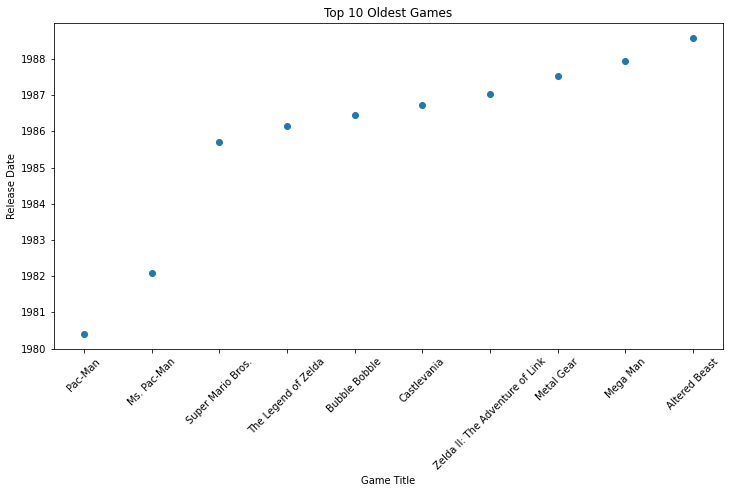
发行时间最长的十款游戏如上图所示。其中发行最早的三款游戏是Pac-Man、Ms.Pac-Man、Super Mario Bros。

技术共进,成长同行——讯飞AI开发者社区
更多推荐

 50
50 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)