
【AI深究】模型泛化(Generalization)与正则化(Regularization):核心原理、数学表达、工程实践与未来趋势|过拟合、欠拟合|L1、L2正则化、弹性网、早停、数据增强、集成方法
大家好,我是爱酱。本篇将会系统梳理模型泛化(Model Generalization)与正则化(Regularization)的核心原理、主流方法、数学表达、工程实践与未来趋势,配合数学公式,帮助你全面理解这一AI建模的“生命线”机制。注:本文章含大量数学算式、详细例子说明及大量代码演示,大量干货,建议先收藏再慢慢观看理解。新频道发展不易,你们的每个赞、收藏跟转发都是我继续分享的动力!
大家好,我是爱酱。本篇将会系统梳理模型泛化(Model Generalization)与正则化(Regularization)的核心原理、主流方法、数学表达、工程实践与未来趋势,配合数学公式,帮助你全面理解这一AI建模的“生命线”机制。
注:本文章含大量数学算式、详细例子说明及大量代码演示,大量干货,建议先收藏再慢慢观看理解。新频道发展不易,你们的每个赞、收藏跟转发都是我继续分享的动力!
一、什么是模型泛化?
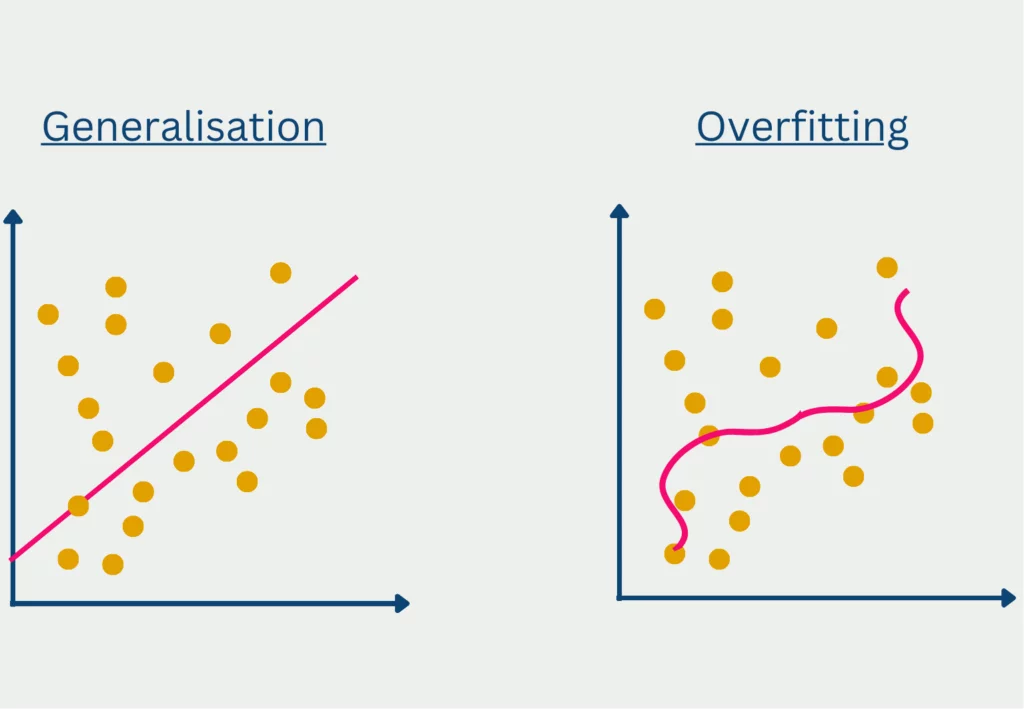
模型泛化(Model Generalization)指机器学习模型在未见过的新数据(unseen data)上依然能保持良好预测能力的能力。泛化能力强的模型不仅能拟合训练集,还能“举一反三”,适应真实世界的多样场景。
-
英文专有名词:Generalization, Generalization Ability
-
本质:模型学到的是“规律”而不是“记忆”,能应对数据分布的自然波动和新环境。
1.1 泛化与过拟合、欠拟合的关系
-
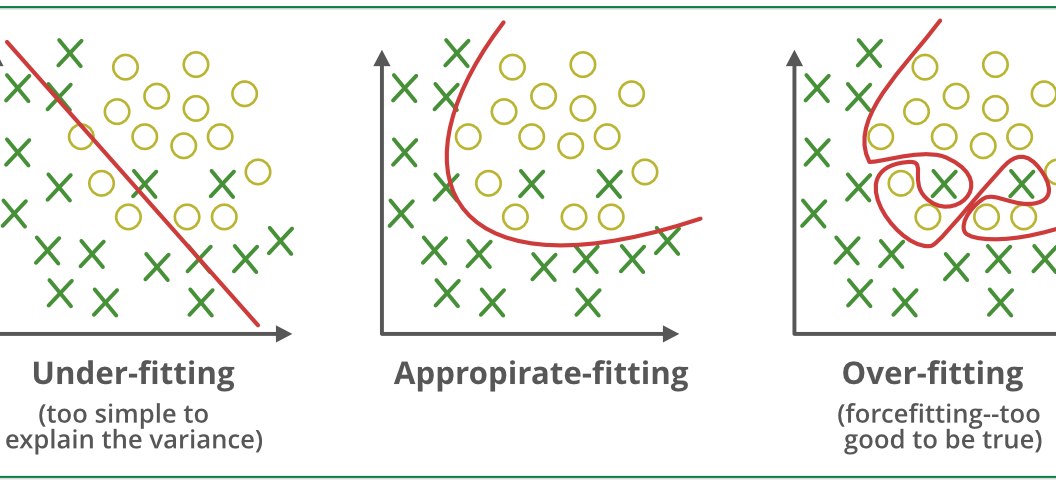
过拟合(Overfitting):模型对训练集“死记硬背”,对新数据表现差。
-
欠拟合(Underfitting):模型太简单,训练集和新数据都表现差。
-
理想状态:模型在训练集和测试集(或验证集)上都表现良好,达到“泛化最佳点”。
二、模型泛化的数学表达
假设模型参数为 ,
训练集损失(Training Loss)为 ,
测试集损失(Testing Loss)为 ,
泛化误差定义为:
泛化能力强的模型应使该误差最小化。
三、影响泛化能力的核心因素
-
模型复杂度(Model Complexity):参数越多、结构越复杂,越容易过拟合。
-
训练数据量与多样性:数据越丰富、越多样,模型越能学到本质规律。
-
特征工程与数据质量:高质量特征有助于泛化,噪声和异常值则会干扰。
-
正则化技术:通过约束模型复杂度,提升泛化能力,是工程落地的关键手段。
四、正则化技术原理与主流方法
正则化(Regularization)是一类通过在损失函数中添加惩罚项(penalty term),抑制模型复杂度、防止过拟合、提升泛化能力的技术。下面只是一个相对简短的介绍,有些概念爱酱有在其他独立文章介绍过,也会附上传送门,欢迎大家去了解更多!
泛化能力详解——传送门:
【AI概念】泛化能力(Generalization)详解 | 训练准确率 vs 测试准确率(附详尽Python代码演示)|定义、数学表达、影响因素、实际意义、三者的关系与工程实践建议|典型案例与可视化-CSDN博客
过拟合(Overfitting)vs 欠拟合(Underfitting)详解——传送门:
【AI概念】过拟合(Overfitting)vs 欠拟合(Underfitting)详解 | 他们有什么区别?|定义、数学表达、几何直观、典型案例、成因、检测方法以及工程应对策略|偏差方差权衡、正则化-CSDN博客
-
英文专有名词:Regularization, L1 Regularization, L2 Regularization, Dropout, Early Stopping, Data Augmentation
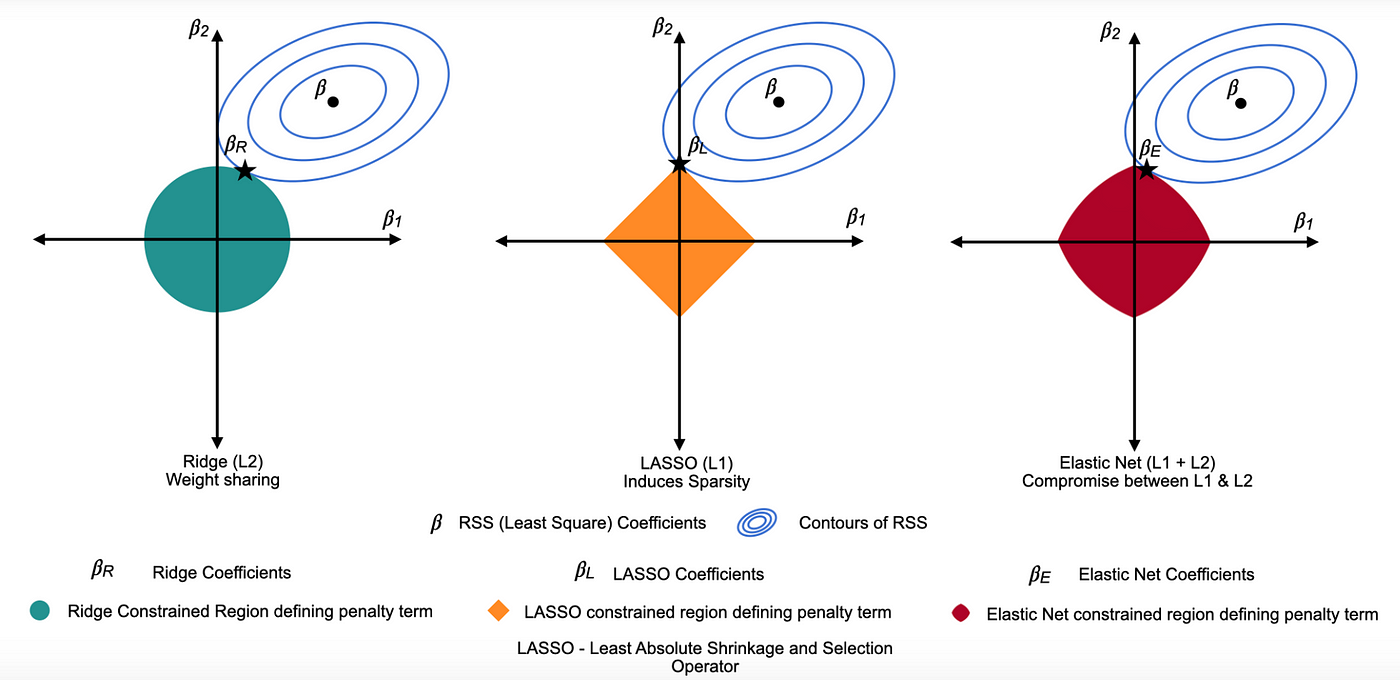
4.1 L1正则化(Lasso Regularization)
-
原理:对参数绝对值加惩罚,鼓励稀疏解(部分参数为0),兼具正则化与特征选择作用。
-
公式:
其中
,
为正则化强度。
4.2 L2正则化(Ridge Regularization)
-
原理:对参数平方加惩罚,抑制权重过大,提升模型稳定性。
-
公式:
其中
,
4.3 弹性网(Elastic Net)
-
原理:结合L1与L2惩罚,兼顾稀疏性与稳定性。
-
公式:
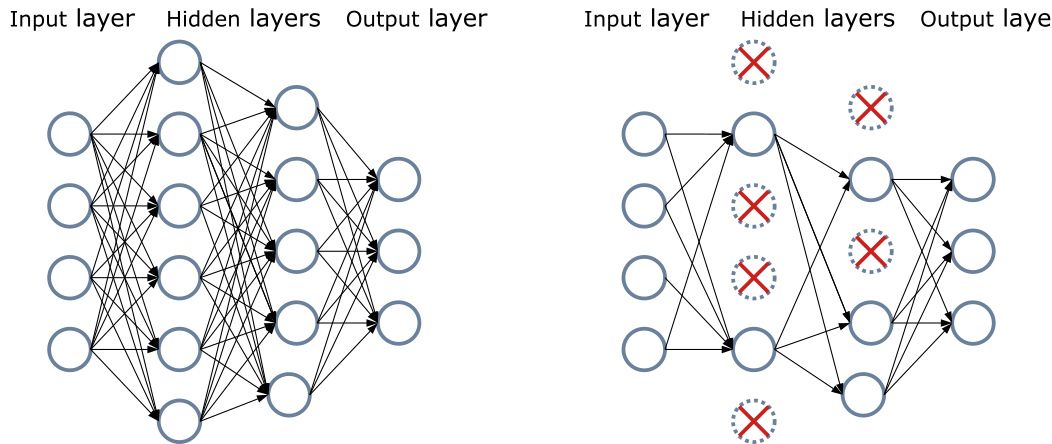
4.4 Dropout(神经网络专用)
-
原理:训练时随机“丢弃”部分神经元,等价于集成多个子模型,提升泛化能力。
-
实现:每轮训练以概率
将部分神经元输出置零。
4.5 早停(Early Stopping)
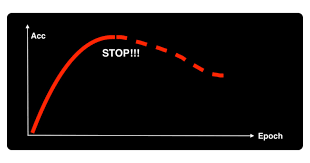
-
原理:当验证集损失不再下降时提前终止训练,防止模型在训练集上过拟合。
4.6 数据增强(Data Augmentation)
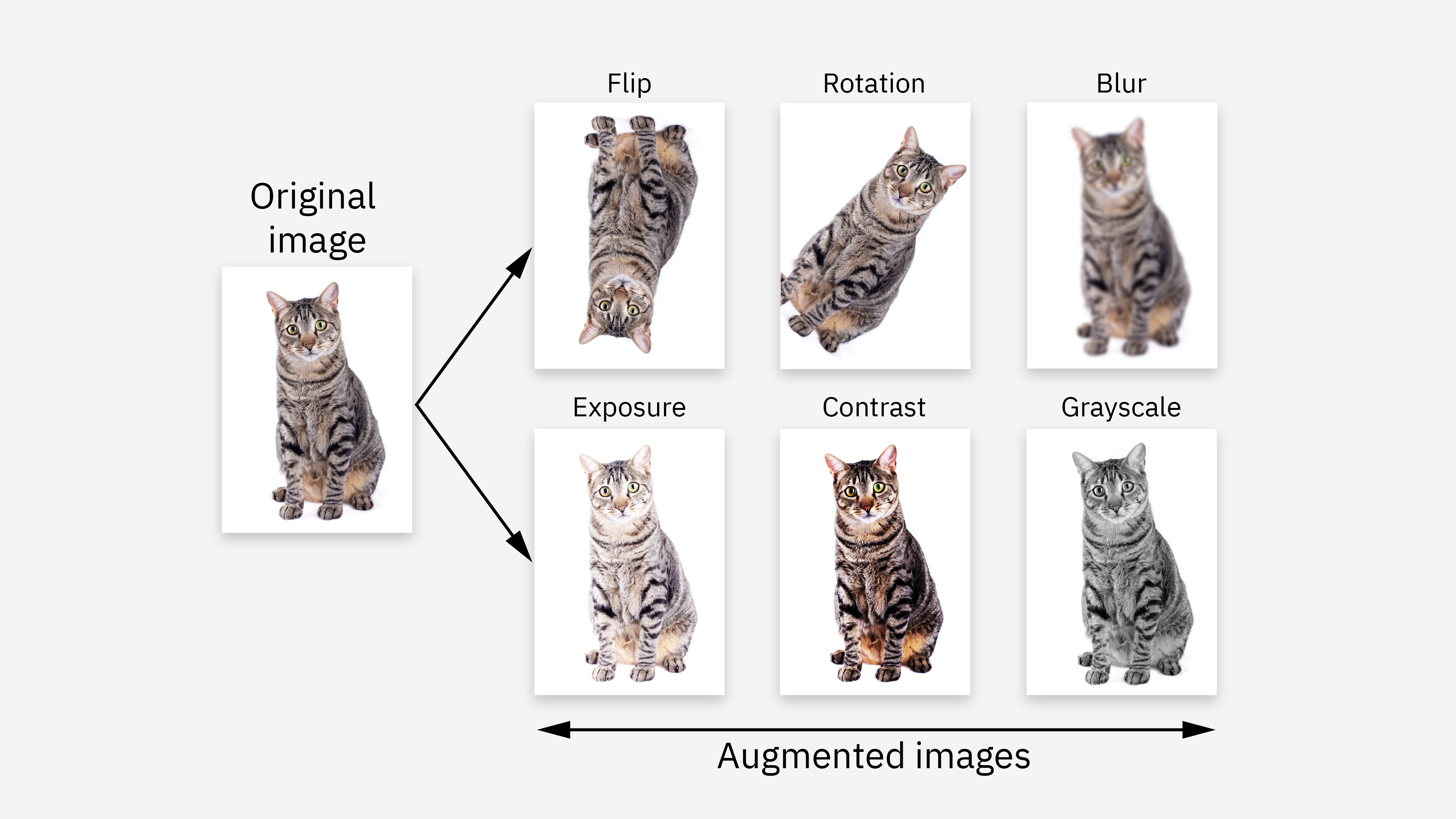
-
原理:通过对训练数据做变换(如旋转、裁剪、加噪声等),提升数据多样性,间接提升泛化能力。
数据增强(Data Augmentation)深度解析——传送门:
【AI深究】数据增强(Data Augmentation)深度解析:原理、算法与工程实践——全网最详细流程|核心原理、主流方法、数学表达、工程实践与未来趋势|主流数据增强方法详解与工程实现、工程细节-CSDN博客
数据增强(Data Augmentation)vs 合成数据(Synthetic Data)vs 数据生成(Data Generation)概念——传送门:
【AI概念】数据增强(Data Augmentation)vs 合成数据(Synthetic Data)vs 数据生成(Data Generation)|数学表达与流程、典型技术与应用场景、常见误区-CSDN博客
4.7 集成方法(Ensemble Methods)
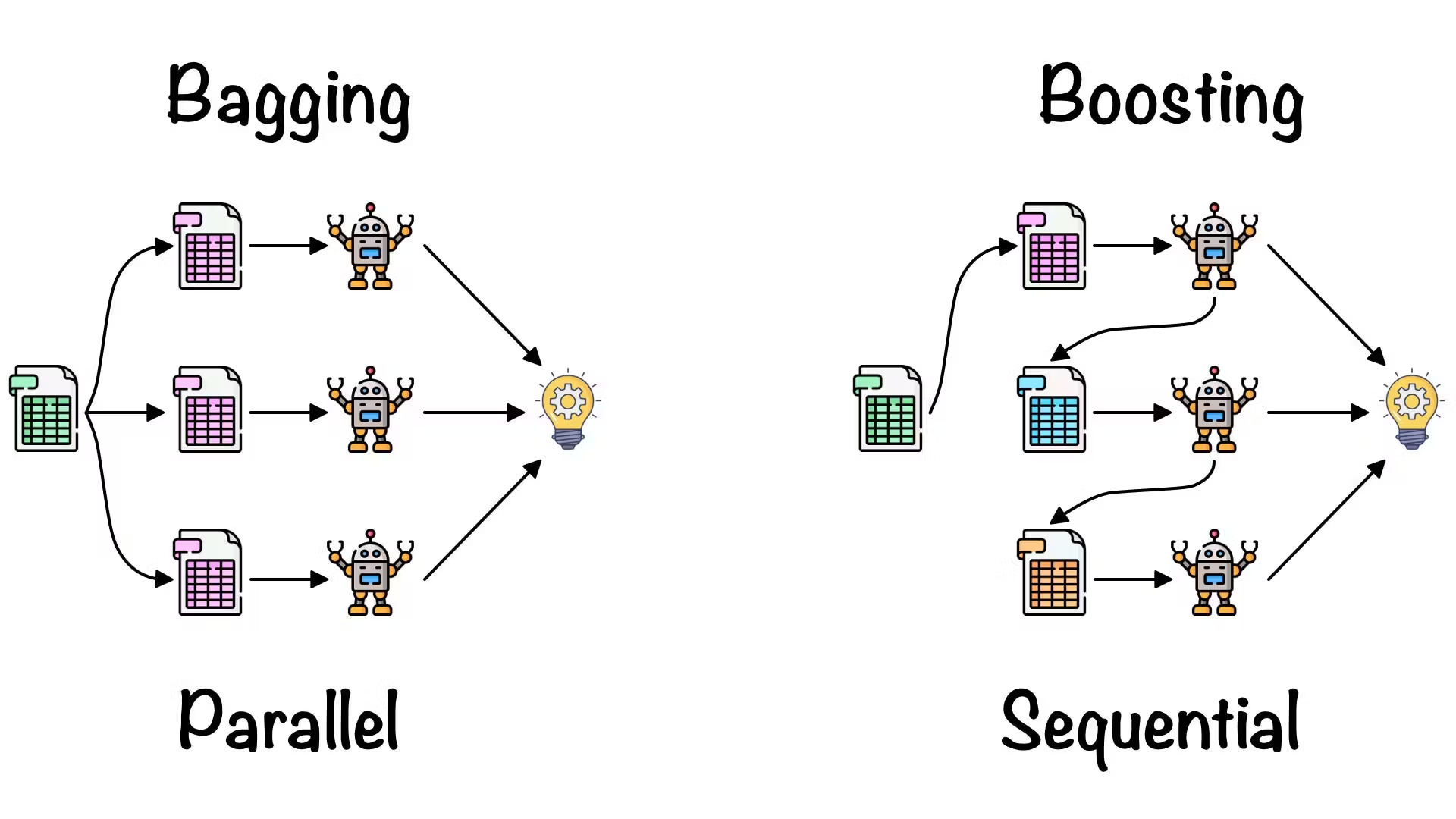
-
原理:集成多个模型(如Bagging、Boosting),降低方差,提升泛化。
集成学习(Ensemble Learning):Bagging与Boosting详解(附Python代码演示)——传送门:
【AI概念】集成学习(Ensemble Learning):Bagging与Boosting详解(附Python代码演示)|有什么分别?原理、数学推导与应用|随机森林|AdaBoost、XGBoost-CSDN博客
集成方法(Ensemble)全网最详细全流程详解与案例(附Python代码演示)——传送门:
【AI深究】集成方法(Ensemble)全网最详细全流程详解与案例(附Python代码演示)|详解:Bagging与Boosting|随机森林|AdaBoost|XGBoost|优、缺点|选择应用建议-CSDN博客
五、正则化技术的工程实践与对比
| 技术 | 适用模型 | 主要作用 | 工程特点 |
|---|---|---|---|
| L1/Lasso | 线性/树/神经网络 | 稀疏、特征选择 | 适合高维、冗余特征场景 |
| L2/Ridge | 线性/神经网络 | 权重收敛、平滑 | 参数不易为0,抗噪性好 |
| Dropout | 神经网络 | 防止神经元协同过拟合 | 训练速度略慢,需调概率 |
| Early Stopping | 所有模型 | 防止过拟合 | 需监控验证集性能 |
| Data Augment | CV/NLP/音频等 | 提升数据多样性 | 需结合领域知识设计 |
| Ensemble | 所有模型 | 降低方差,提升鲁棒性 | 训练/部署资源消耗较大 |
六、正则化与泛化的数学关系
泛化误差可分解为偏差(Bias)与方差(Variance):
正则化通过提升偏差、降低方差,实现泛化能力的最优平衡。
七、典型案例与工程细节
-
神经网络:Dropout+L2正则是深度学习防过拟合的标配组合。
-
树模型:通过剪枝(Pruning)、设置最大深度、最小样本数等参数实现正则化。
-
SVM:C参数控制正则化强度,核函数选择影响泛化。
-
实际流程:通常需结合交叉验证(Cross Validation)调参,寻找泛化能力最优点。
八、未来趋势与发展方向
-
自适应正则化:动态调整正则化强度,实现更智能的模型复杂度控制。
-
生成式正则化:用生成模型自动扩充训练数据,提升泛化能力。
-
多任务、多模态正则化:支持多任务学习、跨模态泛化的新型正则化技术。
-
理论完善:泛化误差界、可解释性正则化等前沿理论不断突破。
九、结语
模型泛化与正则化技术是现代机器学习与深度学习系统能够真正“走出实验室、服务现实世界”的基石。只有具备良好泛化能力的模型,才能在面对未知数据、复杂环境和多变业务需求时,持续保持高水平的表现,而正则化则是实现这一目标的最有效武器。
泛化能力不仅仅是模型在测试集上的高分,更是其在真实生产环境下应对数据分布漂移、样本多样性和噪声扰动时的稳健性。泛化能力的本质,是模型对“规律”的学习,而非对“记忆”的依赖。它直接决定了AI系统的可靠性、可扩展性与商业价值。
正则化作为提升泛化能力的核心工具,已经从传统的L1/L2惩罚项,发展到Dropout、Early Stopping、数据增强、集成学习等多元化体系。每一种正则化方法都在抑制模型复杂度、防止过拟合、提升模型稳定性方面发挥着独特作用。在深度学习时代,正则化不仅仅是“防过拟合”的手段,更是模型结构设计、训练流程和数据管道中的有机组成部分。
工程实践中,泛化与正则化不是孤立存在的,它们与数据质量、特征工程、损失函数设计、优化算法等环节密切耦合。一个优秀的AI工程师,必须能够针对具体任务、数据特性和业务目标,灵活组合和调优各类正则化技术,动态监控模型的泛化表现,及时调整策略以应对实际场景的变化。
未来趋势方面,随着AI模型规模的持续扩大和应用场景的不断复杂化,正则化与泛化的理论和技术也在不断进化。自适应正则化、生成式正则化、多模态与多任务正则化、理论泛化界限的深入研究,以及与AutoML、可解释AI的深度融合,都将推动AI系统向着更智能、更稳健、更透明的方向发展。
掌握模型泛化与正则化,不仅是提升模型性能和工程落地能力的“必修课”,更是AI系统可持续创新与产业化的核心保障。只有理解其原理、精通其方法、善于在实际项目中灵活应用,才能让AI系统真正具备“举一反三”的能力,在复杂多变的现实世界中持续创造价值。
谢谢你看到这里,你们的每个赞、收藏跟转发都是我继续分享的动力。
如需进一步案例、代码实现或与其他聚类算法对比,欢迎留言交流!我是爱酱,我们下次再见,谢谢收看!

技术共进,成长同行——讯飞AI开发者社区
更多推荐



 16
16 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)