
腾讯开源高一致性视频生成模型:HunyuanVideo-Avatar
腾讯提出的HunyuanVideo-Avatar模型基于多模态扩散变换器(MM-DiT),解决了音频驱动动画中角色一致性、情感对齐和多角色交互等挑战。模型核心创新包括字符图像注入模块确保角色一致性,音频情感模块实现精准情感控制,以及面部感知音频适配器支持多角色独立动画。该模型支持多种风格和尺度的头像输入,可生成高动态视频,适用于电商、直播等场景。模型提供多GPU、单GPU和低显存多种推理方式,通过
《Tencent HunyuanVideo-Avatar 介绍》
一、研究背景
近年来,音频驱动的人类动画领域取得了显著进展,但在生成高度动态的视频同时保持角色一致性、实现角色与音频间精准情感对齐以及支持多角色音频驱动动画等方面仍面临挑战。
二、HunyuanVideo-Avatar 模型概述
为应对上述挑战,腾讯提出了基于多模态扩散变换器(MM-DiT)的 HunyuanVideo-Avatar 模型,该模型能够同时生成动态、可控制情感和多角色对话的视频。其整体架构包含多种元素,如 3D 编码器、空间交叉注意力、音频情感模块(AEM)、面部感知音频适配器(FAA)等,各部分协同工作实现复杂视频生成任务。
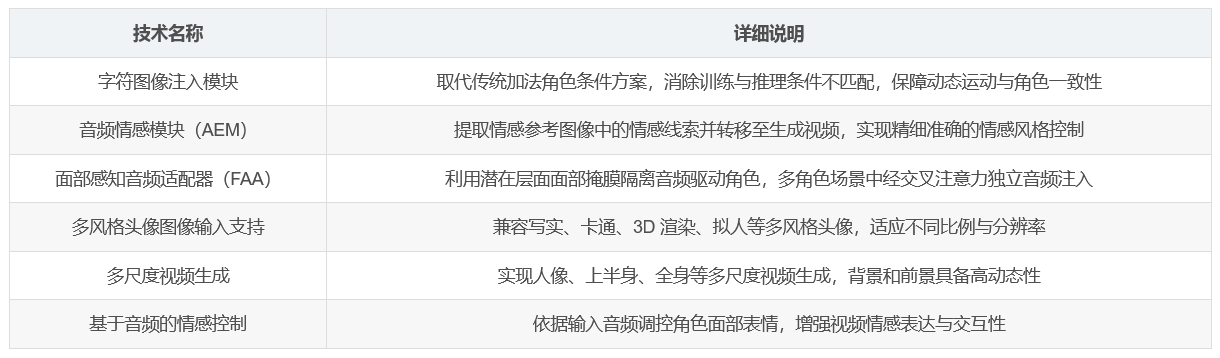
三、模型关键创新点
-
字符图像注入模块 :代替传统基于加法的角色条件方案,消除训练和推理之间的固有条件不匹配,确保动态运动和强烈的角色一致性。
-
音频情感模块(AEM) :从情感参考图像中提取并转移情感线索到目标生成视频,实现精细且准确的情感风格控制。
-
面部感知音频适配器(FAA) :通过潜在层面的面部掩膜隔离音频驱动角色,使多角色场景中能通过交叉注意力独立进行音频注入。
四、高动态和情感可控视频生成能力
HunyuanVideo-Avatar 可将任意输入的头像图像在简单音频条件下动画化为高动态和情感可控视频。支持多风格头像图像输入,包括写实、卡通、3D 渲染和拟人角色等,涵盖不同比例和分辨率。还能在人像、上半身和全身等多尺度生成视频,背景和前景具有高动态性,且可基于输入音频控制角色面部表情。
五、多样化应用
该模型支持多种下游任务和应用,例如生成用于电子商务、在线直播、社交媒体视频制作等场景的说话头像视频。其多角色动画功能还扩大了视频内容创作、编辑等应用范围。
六、推理方式
-
多 GPU 并行推理 :以 8 GPU 为例,通过特定命令实现高效视频生成,充分发挥多 GPU 并行计算优势,提升生成速度。
-
单 GPU 推理 :针对单 GPU 环境,提供相应命令进行视频生成,满足不同硬件配置下的使用需求。
-
低 VRAM 环境运行 :在极低显存情况下,也可通过特定指令运行模型,降低了硬件要求,增强了模型的适用性。
-
Gradio 服务器运行 :可通过运行脚本启动 Gradio 服务器,方便用户进行交互式操作和体验。
七、核心技术汇总

技术共进,成长同行——讯飞AI开发者社区
更多推荐
 4
4 0
0- 0



 已为社区贡献43条内容
已为社区贡献43条内容

所有评论(0)