
2019年全国研究生数学建模竞赛华为杯D题汽车行驶工况构建求解全过程文档及程序
2019年全国研究生数学建模竞赛华为杯D题汽车行驶工况构建求解全过程文档及程序
2019年全国研究生数学建模竞赛华为杯
D题 汽车行驶工况构建
原题再现:
一、问题背景
汽车行驶工况(Driving Cycle)又称车辆测试循环,是描述汽车行驶的速度-时间曲线(如图1、2,一般总时间在1800秒以内,但没有限制标准,图1总时间为1180秒,图2总时间为1800秒),体现汽车道路行驶的运动学特征,是汽车行业的一项重要的、共性基础技术,是车辆能耗/排放测试方法和限值标准的基础,也是汽车各项性能指标标定优化时的主要基准。目前,欧、美、日等汽车发达国家,均采用适应于各自的汽车行驶工况标准进行车辆性能标定优化和能耗/排放认证。
本世纪初,我国直接采用欧洲的NEDC行驶工况(如图1)对汽车产品能耗/排放的认证,有效促进了汽车节能减排和技术的发展。近年来,随着汽车保有量的快速增长,我国道路交通状况发生很大变化,政府、企业和民众日渐发现以NEDC工况为基准所优化标定的汽车,实际油耗与法规认证结果偏差越来越大,影响了政府的公信力(譬如对某型号汽车,该车标注的工信部油耗6.5升/100公里,用户体验实际油耗可能是8.5-10升/100公里)。另外,欧洲在多年的实践中也发现NEDC工况的诸多不足,转而采用世界轻型车测试循环(WLTC,如图2)。但该工况怠速时间比和平均速度这两个最主要的工况特征,与我国实际汽车行驶工况的差异更大。作为车辆开发、评价的最为基础的依据,开展深入研究,制定反映我国实际道路行驶状况的测试工况,显得越来越重要。
另一方面,我国地域辽广,各个城市的发展程度、气候条件及交通状况的不同,使得各个城市的汽车行驶工况特征存在明显的不同。因此,基于城市自身的汽车行驶数据进行城市汽车行驶工况的构建研究也越来越迫切,希望所构建的汽车行驶工况与该市汽车的行驶情况尽量吻合,理想情况下是完全代表该市汽车的行驶情况(也可以理解为对实际行驶情况的浓缩),目前北京、上海、合肥等都已经构建了各城市的汽车行驶工况。
为了更好地理解构建汽车行驶工况曲线的重要性,以某型号汽车油耗为例,简单说明标注的工信部油耗是如何测试出来?标注的工信部油耗并不是该型号汽车在实际道路上的实测油耗,而是基于国家标准(如《GB27840-2011重型商用车辆燃料消耗量测量方法》),在实验室里根据汽车行驶工况曲线,按照一定的标准,经检测、计算得出。由此可见,标注的工信部油耗是否与实际油耗相吻合,与汽车行驶工况曲线有密切关系。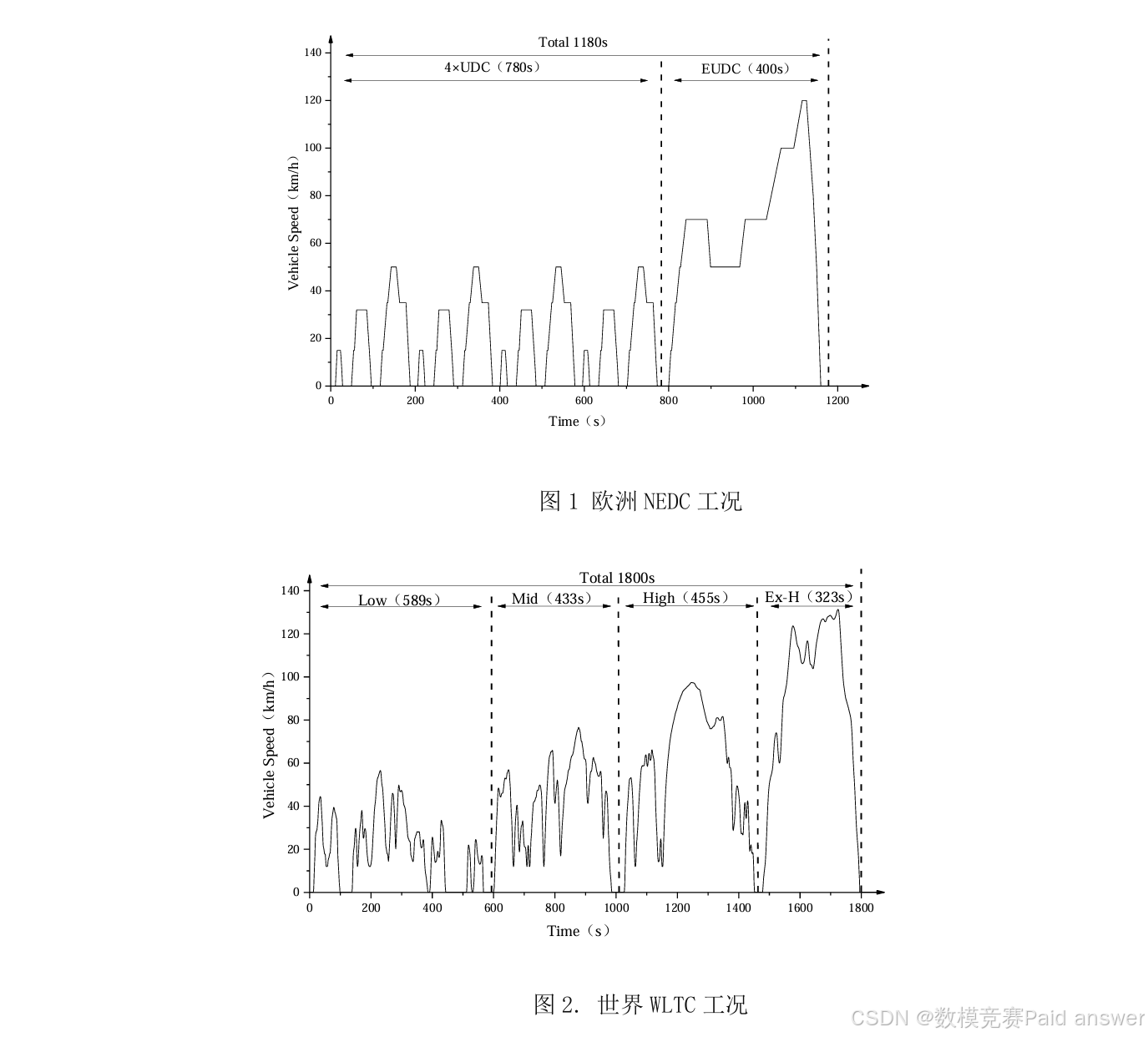
二、目标的提出
在上述背景下,请根据附件(3个数据文件,每个数据文件为同一辆车在不同时间段内所采集的数据)所提供的某城市轻型汽车实际道路行驶采集的数据(采样频率1Hz),构建一条能体现参与数据采集汽车行驶特征的汽车行驶工况曲线(1200-1300秒),该曲线所体现的汽车运动特征(如平均速度、平均加速度等)能代表所采集数据源的相应特征,两者间的误差越小,说明所构建的汽车行驶工况的代表性越好。
三、解决的问题
1.数据预处理
由汽车行驶数据的采集设备直接记录的原始采集数据往往会包含一些不良数据值,不良数据主要包括几个类型:
(1) 由于高层建筑覆盖或过隧道等,GPS信号丢失,造成所提供数据中的时间不连续;
(2) 汽车加、减速度异常的数据(普通轿车一般情况下:0至100km/h的加速时间大于7秒,紧急刹车最大减速度在7.5~8 m/s2);
(3) 长期停车(如停车不熄火等候人、停车熄火了但采集设备仍在运行等)所采集的异常数据。
(4) 长时间堵车、断断续续低速行驶情况(最高车速小于10km/h),通常可按怠速情况处理。
(5) 一般认为怠速时间超过180秒为异常情况,怠速最长时间可按180秒处理。
请设计合理的方法将上述不良数据进行预处理,并给出各文件数据经处理后的记录数。
2.运动学片段的提取
运动学片段是指汽车从怠速状态开始至下一个怠速状态开始之间的车速区间,如图3所示(基于运动学片段构建汽车行驶工况曲线是日前最常用的方法之一,但并不是必须的步骤,有些构建汽车行驶工况曲线的方法并不需要进行运动学片段划分和提取)。请设计合理的方法,将上述经处理后的数据划分为多个运动学片段,并给出各数据文件最终得到的运动学片段数量。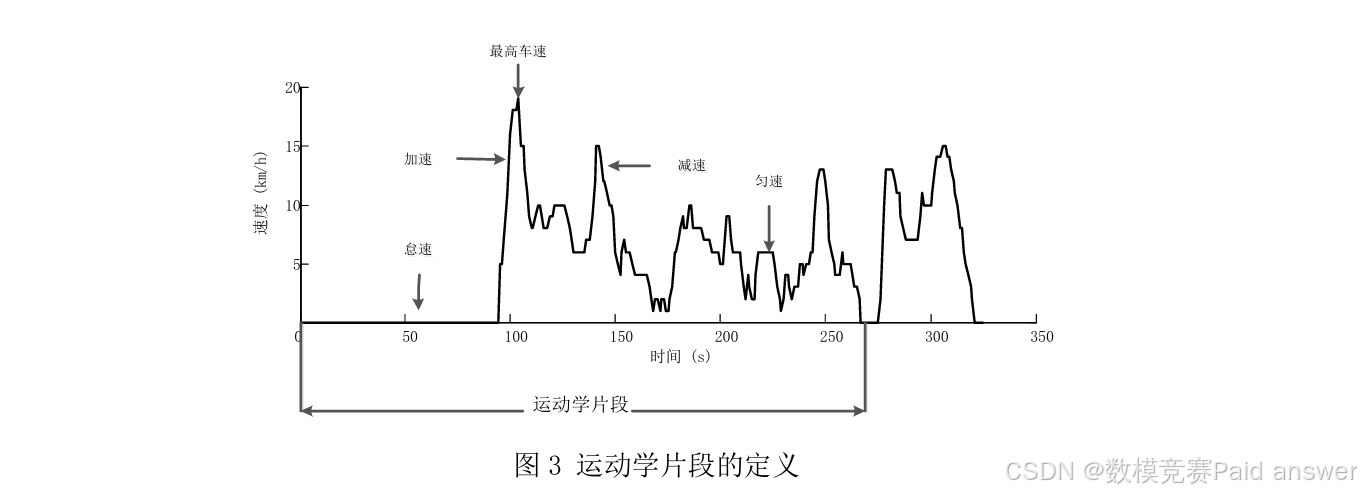
3. 汽车行驶工况的构建
请根据上述经处理后的数据,构建一条能体现参与数据采集汽车行驶特征的汽车行驶工况曲线(1200-1300秒),该曲线的汽车运动特征能代表所采集数据源(经处理后的数据)的相应特征,两者间的误差越小,说明所构建的汽车行驶工况的代表性越好。要求:
(1)科学、有效的构建方法(数学模型或算法,特别鼓励创新方法,如果采用已有的方法,必须注明来源);
(2)合理的汽车运动特征评估体系(至少包含但不限于以下指标:平均速度(km/h)、平均行驶速度(km/h)、平均加速度(m/ )、平均减速度(m/ )、怠速时间比(%)、加速时间比(%)、减速时间比(%)、速度标准差(km/h)、加速度标准差(m/ )等);
(3)按照你们所构建的汽车行驶工况及汽车运动特征评估体系,分别计算出汽车行驶工况与该城市所采集数据源(经处理后的数据)的各指标(运动特征)值,并说明你们所构建的汽车行驶工况的合理性。
四、名词解释与参考文献
1. 部分名词解释
怠速:汽车停止运动,但发动机保持最低转速运转的连续过程。
加速:汽车加速度大于0.1m/s2的连续过程。
减速:汽车加速度小于-0.1m/s2的连续过程。
巡航/匀速:汽车加速度的绝对值小于0.1m/s2非怠速的连续过程。
平均速度:一段时间周期内,汽车速度的算术平均值。
平均行驶速度:汽车在行驶状态下汽车速度的算术平均值,即不包含汽车怠速状态。
怠速时间比:一段时间周期内,怠速状态的累计时间长度占该时间周期总时间长度的百分比。
平均加速度:汽车在加速状态下各单位时间(秒)加速度的算术平均值。
平均减速度:汽车在减速状态下各单位时间(秒)减速度的算术平均值。
加速时间比:一段时间周期内,处在加速状态的累计时间长度占该时间周期总时间长度的百分比。
减速时间比:一段时间周期内,处在减速状态的累计时间长度占该时间周期总时间长度的百分比。
速度标准差:一段时间周期内,汽车速度的标准差,即包括怠速状态。
加速度标准差:一段时间周期内,处在加速状态的汽车加速度的标准差。
整体求解过程概述(摘要)
汽车行驶工况是描述汽车在不同工况下运动特征的速度时间曲线,广泛使用于汽车能效分析、动力性能分析和运动特征分析。我国目前使用欧洲提出的NEDC工况,然而由于汽车行驶工况与地理环境、自然气候、驾驶习惯等具有较大关系,所以国外的汽车行驶工况标准并不能很好地对我国汽车的实际行驶工况进行分析和预测。与此同时,随着新能源汽车的快速发展,新能源动力汽车将逐渐取代传统燃油汽车,因此用近 20 年前的标准也明显无法适应新的发展要求。所以,构建具有我国特色的汽车行驶工况具有十分重要的意义。本文按照数据预处理、运动片段提取、汽车运动特征评估体系构建、主成分分析降维、K-Means 聚类对运动片段进行分类、基于指标偏差的运动片段提取、汽车行驶工况分析、误差分析这几个步骤,建立了一套完整的汽车行驶工况构建方法,并按照题目要求解决相关问题。
针对问题一:根据题中所提出的五种不良数据类型,本文对原始数据进行了变速异常数据处理、数据填充处理及异常怠速和停车状态处理三个步骤,首先,进行变速异常数据处理,筛选出加速度和减速度超过最大阈值的数据行,予以删除;然后,进行数据填充处理,找到原始数据中时间不连续的点,统计不连续点之间的间隔,对缺失时间较短的数据利用缺失前后数据信息进行数据填补;最后,对异常怠速和停车状态进行判别,对于异常怠速数据,超过怠速最长时间(180s)以上的数据全部予以删除,对于停车状态,前后保留5s的0值余量,把中间数据全部删除。最终,经过数据预处理过后,文件1、文件2和文件3剩余的数据总量分别为177760行,141378行和154302行。
针对问题二:通过对预处理后数据进行分析和参考相关文献,本文为运动学片段的筛选制定了 3 条规则:(1)满足运动学片段的基本定义,即从一个怠速状态开始到下一个怠速状态开始间的行驶区间里,包含加速、减速和匀速三个过程;(2)片段时长限制,为保证片段的有效性,运动学片段的时长必须大于20s;( 3)运动学片段数据缺失率限制,保障片段的完整性, GPS 车速数据缺失率小于10%;基于3条规则对预处理后数据进行运动学片段提取,文件1、文件2和文件3提取出的运动学片段个数分别为876,668和560。
针对问题三:本文首先建立能广泛评估汽车运行特征的11个运动学指标(运行时间、平均速度、平均行驶速度、速度标准差、最大速度、最大加速度、最大减速度、平均加速度、平均减速度、加速度标准差、运行路程)和4个统计学指标(怠速时间比、加速时间比、减速时间比、匀速时间比),以便描述和比较运动片段、运动工况的运动特征。在此基础上使用主成分分析法简化数据结构,最终将15个运动特征指标降为3个综合指标,且这3个综合指标的累计贡献率达到99%。接着利用K-Means聚类方法,以综合指标间的距离为分类标准,将提取出的2104个运动片段分为3类,3个聚类集合中分别包含1904、184、16 个运动片段。在聚类的基础上,本文以一个运动片段的去量纲指标和与该片段所属聚类集合的去量纲指标和的偏差大小为依据,优先选取偏差小的运动片段作为所属聚类集合最具代表性的运动片段。按照汽车运行工况时间范围1200s~1300s的规定,最终得到总长1268s的汽车行驶工况曲线,其中第一类运动片段(低速)占时301s、第二类运动片段(中速)占时392s、第三类运动片段(高速)占时575s。观察所构建汽车行驶工况,发现提取片段速度时间曲线所包含汽车运动特征信息与通过 15 个指标分析出的三种工况基本吻合。同时,本文比较所构建汽车运行工况指标值与经处理后的采集数据指标值,各指标误差率集中在2%~30%,其中速度标准差误差率为2.046%、最大速度误差率为5.651%,相似系数为0.983,欧氏距离偏差率为1.199%。综合上述结果,可以说明本文所构建汽车运行工况具有一定代表性。
模型假设:
1. 假设汽车在采样时间1s内的任何变速过程皆为均匀的;
2. 假设汽车无故障行驶,行驶过程不考虑天气,汽车自身故障等情况的影响;
3. 假设汽车启动之后,汽车进入怠速状态,车主5s后起步;
4. 假设车主从停车到熄火存在5s间隔,该阶段仍属于怠速状态;
5. 假设所有参考资料都是真实无误的;
问题分析(部分):
本题要求使用原始数据文件夹中提供的同一汽车在三个不同时段的实际道路行驶数据,构建出能描述该汽车行驶工况的速度-时间曲线,并将所构建曲线的特征与采集数据的相应特征进行对比和误差分析,以验证本文所构建汽车行驶工况的准确性和合理性,即构建汽车行驶工况并分析验证其代表性优劣,对于题目中提出的问题具体分析如下:
针对问题一,为了对文件1、文件2和文件3采集到的数据进行预处理,首先需要对数据缺失、变速异常、停车数据、持续低速、异常怠速五个类别的数据情况进行统计和分析,然后制定相应的数据删减和添补的方案,最后依照处理方案,调整数据,得到预处理后的数据,其中异常怠速和停车状态存在交叉环节,如何对两者进行区分,并制定相应的数据删减方案是问题一的重点。
针对问题二,运动学片段是从一个怠速状态开始,经历加速、匀速和减速运行后,在下一个怠速状态开始前一个时间点结束的片段。通过考虑运动学片段的定义特征、时间连续性、过程完整性、结构正确性、长度合理性等原则制定运动片段筛选规则,根据规则从问题一处理后的数据中提取有效运动学片段。
针对问题三,通过运动片段构建运行工况,是一个从众多运动片段中选取最具有代表性的几个运动片段的过程,如何评判这个运动片段具有代表性以及如何评判最终构建工况曲线具有代表性是首先要解决的问题。因此,本题首先需要找到合理的指标来描述运动学片段以及工况曲线,在选取好汽车运动特征指标后,我们需要把众多的运动学片段通过聚类方法分为几个大的类别,然后,从每一大类中提取最能代表该类运动片段特征的运动学片段,最后根据各类运动片段在处理后的总运动曲线上的时间占比,得到各类运动片段在总运行工况上所占时间,结合排序后的备选片段和所占时间拼接得到最终的汽车运行工况曲线,得到运行工况曲线后,按照题目要求还需要进行误差分析,根据误差值判断所构建汽车运行工况的准确性。
论文缩略图(全部):


全部论文及程序请见下方“ 只会建模 QQ名片” 点击QQ名片即可
程序代码(部分代码):
import numpy as np
import pandas as pd
import datetime
import copy
time_inc=[]
speedU=[]
speedD=[]
#时间不连续节点
#加速不合要求Vup>100/7
#减速不合要求Vdn>28.8
data1 = pd.read_excel('C:/Users/19946/Desktop/redata/文件 3.xlsx') #原始数据
data1 = pd.DataFrame(data1)
data1 = np.array(data1)
data1_out=copy.deepcopy(data1)
#寻找断续时间节点
fori in range(data1.shape[0]-1):
#原始数据副本(记录处理后最终数据)
date1 = datetime.datetime.strptime(data1[i][0].replace('.000.',''),'%Y/%m/%d %H:%M:%S')
date2
datetime.datetime.strptime(data1[i+1][0].replace('.000.',''),'%Y/%m/%d %H:%M:%S')
ss=(date2-date1).seconds
ifss!=1:
time_inc+=[[i,ss]]
time_inc=np.array(time_inc)
time_inc=time_inc+np.array([1,0]*time_inc.shape[0]).reshape([time_inc.shape[0],2])
time_inc = pd.DataFrame(time_inc)
time_inc.to_excel('C:/Users/19946/Desktop/time_inc.xlsx')
#缺失数据补充(仅补充间隔1秒)
ff1=[]
#过渡列表,给原始数据补充1秒缺失数据
i=0
j=data1_out.shape[0]-1
data1_out=data1_out.tolist()
while(i<j):
date3
#向量转列表
#输出断续时间节点
#跟踪待补充数据表维度
datetime.datetime.strptime(data1_out[i][0].replace('.000.',''),'%Y/%m/%d %H:%M:%S')
date4
datetime.datetime.strptime(data1_out[i+1][0].replace('.000.',''),'%Y/%m/%d %H:%M:%S')
ss=(date4-date3).seconds
ifss==2:
i=i+1
ff1=[(date3+datetime.timedelta(seconds=1)).strftime('%Y/%m/%d %H:%M:%S')]
ff1=ff1+(1/2*(np.array(data1_out[i+1][1:])+np.array(data1_out[i][1:]))).tolist()
data1_out.insert(i+1,ff1)
j=j+1
#新数据中寻找加减速异常数据
fori in range(len(data1_out)-1):
date5
datetime.datetime.strptime(data1_out[i][0].replace('.000.',''),'%Y/%m/%d %H:%M:%S')
date6
datetime.datetime.strptime(data1_out[i+1][0].replace('.000.',''),'%Y/%m/%d %H:%M:%S')
ss=(date6-date5).seconds
if (data1_out[i+1][1]-data1_out[i][1])/ss>100/7:
speedU.append(i+1)
if (data1_out[i][1]-data1_out[i+1][1])/ss>28.8:
speedD.append(i+1)
data1_out=np.array(data1_out)
#剔除异常数据
data1_out=np.delete(data1_out,speedU,axis=0)
data1_out=np.delete(data1_out,speedD,axis=0)
#数据导出,加减速异常数据节点
speedU=np.array(speedU)
speedD=np.array(speedD)
speedU=speedU+np.ones([1,speedU.shape[0]])
speedD=speedD+np.ones([1,speedD.shape[0]])
speedU=pd.DataFrame(speedU.T)
speedD=pd.DataFrame(speedD.T)
speedU.to_excel('C:/Users/19946/Desktop/speedU.xlsx')
speedD.to_excel('C:/Users/19946/Desktop/speedD.xlsx')
'''
#全0片段提取
n=0
count=[]
count1=[]
i=0
while(i<data1.shape[0]-1):
if data1[i][1]==0:
while(data1[i][1]==0):
n=n+1
i=i+1
ifi==data1.shape[0]:
break
count.append([i-n,n])
i=i+1
n=0
fori in range(len(count)-1):
if count[i][1]>=180:
count1.append([count[i][0],count[i][1]])
count=np.array(count)
count1=np.array(count1)
count=pd.DataFrame(count)
count1=pd.DataFrame(count1)
count.to_excel('C:/Users/19946/Desktop/count.xlsx')
count1.to_excel('C:/Users/19946/Desktop/count1.xlsx')
'''
#怠速异常片段提取
#怠速片段提取
n=0
i=0
cnt=[]
cnt1=[]
#记录怠速点
#记录怠速异常点
data1_out=data1_out.tolist()
while(i<len(data1_out)-1):
if float(data1_out[i][1])<10:
while(float(data1_out[i][1])<10):
n=n+1
i=i+1
ifi==len(data1_out):
break
cnt.append([i-n,n])
i=i+1
n=0
#怠速异常片段提取
fori in range(len(cnt)-1):
ifcnt[i][1]>180:
cnt1.append([cnt[i][0],cnt[i][1]])
cnt2=copy.deepcopy(cnt1)
cnt1=np.array(cnt1)+np.ones([len(cnt1),1])
cnt1=pd.DataFrame(cnt1)
cnt1.to_excel('C:/Users/19946/Desktop/cnt1.xlsx')
#确定怠速异常数据和停车异常数据片段
cut=[] #异常片段删除区间记录
fori in range(len(cnt2)-1):
if float(data1_out[cnt2[i][0]+179][1])!=0:
cut.append([cnt2[i][0]+180,cnt2[i][0]+cnt2[i][1]-1])
else:
cut1=[]
n=0
j=cnt2[i][0]
while(j<cnt2[i][0]+cnt2[i][1]-1):
if float(data1_out[j][1])==0:
while(float(data1_out[j][1])==0):
n=n+1
j=j+1
if j==cnt2[i][0]+cnt2[i][1]:
break
cut1.append([j-n,j-1])
j=j+1
n=0
ind=[]
for m in range(len(cut1)):
ind.append(cut1[m][1]-cut1[m][0])
if m==len(cut1):
break
index=ind.index(max(ind))
cut.append([cut1[index][0]+5,cut1[index][1]-5])
#删除异常数据片段
data1_out=np.array(data1_out)
for i in range(len(cut)):
data1_out=np.delete(data1_out,range(cut[i][0],cut[i][1]+1),axis=0)
#数据输出
cut=np.array(cut)
cut=pd.DataFrame(cut)
cut.to_excel('C:/Users/19946/Desktop/cut.xlsx')
data1_out=pd.DataFrame(data1_out)
#输出待删除异常数据片段
data1_out.to_excel('C:/Users/19946/Desktop/data1_out.xlsx')
#最终数据输出
全部论文及程序请见下方“ 只会建模 QQ名片” 点击QQ名片即可

技术共进,成长同行——讯飞AI开发者社区
更多推荐


 28
28 0
0- 0



 已为社区贡献38条内容
已为社区贡献38条内容

所有评论(0)