
【Python爬虫篇-2】UA伪装反爬机制以及实现搜索信息爬取
总结:在次实验过程中,存在url地址获取错误,我原本在Edge中来获取的,但是运行多次后仍跳转到百度首页界面,我便下载搜狗浏览器来获取url和User-Agent,运行第一次就成功了。:门户网站的服务器会检测对应请求的载体身份标识,如果检测到请求的载体身份标识为某一款浏览器说明该请求是个正常的请求。3、以下可获取动态参数,即输入‘成龙’运行是便会爬取该页面,输入其他文字也是同理。1、获取User-
·
UA :User-Agent: 请求载体的身份标识
UA检测:门户网站的服务器会检测对应请求的载体身份标识,如果检测到请求的载体身份标识为某一款浏览器说明该请求是个正常的请求。但是,如果检测到请求的载体身份标识不是基于某一款浏览器的,则一般为爬虫,则服务端可能拒绝爬取。
UA伪装: 让爬虫对应的请求载体身份标识伪装成某一款浏览器
本篇依据爬虫篇-1的基础进而实现
1、获取User-Agent,并将其封装在headers中作为一个字典
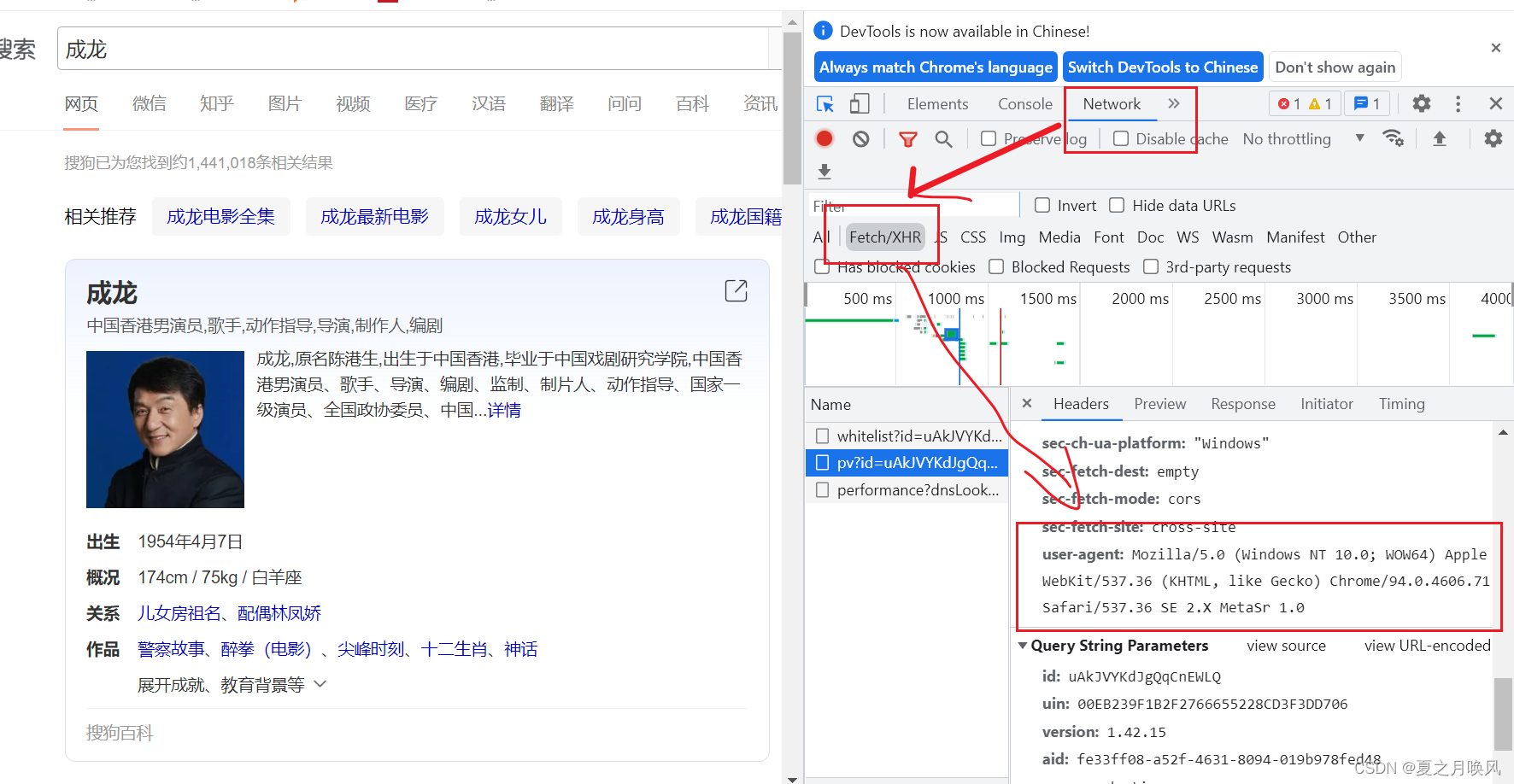
# UA伪装: 将对应网址上的User-Agent封装到一个字典中
headers ={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36 SE 2.X MetaSr 1.0'
}2、获取url地址
url = 'https://www.sogou.com/web?'3、以下可获取动态参数,即输入‘成龙’运行是便会爬取该页面,输入其他文字也是同理
# 处理url携带的参数:封装到字典中
kw = input('搜索:')
param = {
'query': kw
}4、对指定的url发起的请求反应
# 对指定的url发起的请求对应的url是携带参数的,并且请求过程中处理了参数
response = requests.get(url=url, params=param, headers=headers)
page_text = response.text
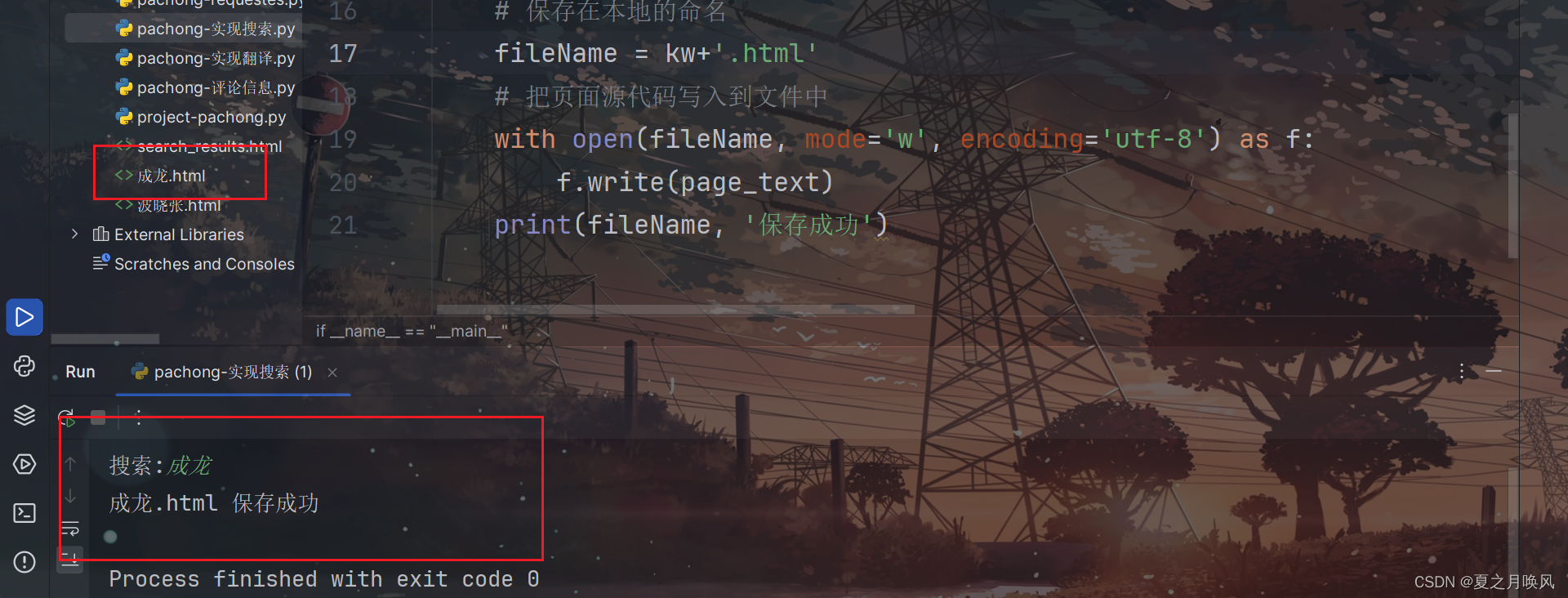
5、将爬取的信息保存在 html 文件中
# 保存在本地的命名
fileName = kw+'.html'
# 把页面源代码写入到文件中
with open(fileName, mode='w', encoding='utf-8') as f:
f.write(page_text)
print(fileName, '保存成功')总实现代码:
import requests
if __name__ == "__main__":
# UA伪装: 将对应网址上的User-Agent封装到一个字典中
headers ={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36 SE 2.X MetaSr 1.0'
}
url = 'https://www.sogou.com/web?'
# 处理url携带的参数:封装到字典中
kw = input('搜索:')
param = {
'query': kw
}
# 对指定的url发起的请求对应的url是携带参数的,并且请求过程中处理了参数
response = requests.get(url=url, params=param, headers=headers)
page_text = response.text
# 保存在本地的命名
fileName = kw+'.html'
# 把页面源代码写入到文件中
with open(fileName, mode='w', encoding='utf-8') as f:
f.write(page_text)
print(fileName, '保存成功')
这样便实现了
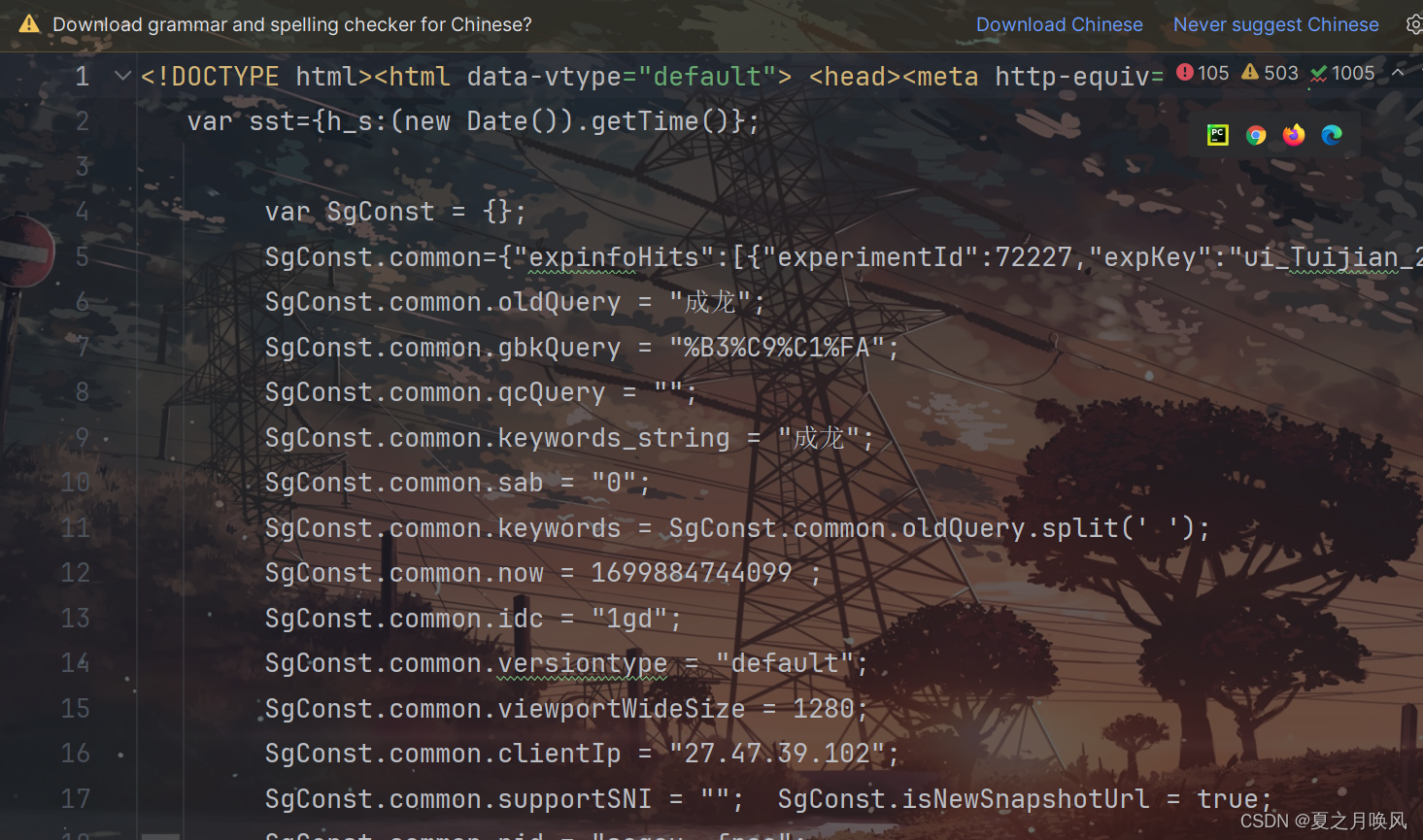
总结:在次实验过程中,存在url地址获取错误,我原本在Edge中来获取的,但是运行多次后仍跳转到百度首页界面,我便下载搜狗浏览器来获取url和User-Agent,运行第一次就成功了。
注意:本文以学习技术为主,不可以用于非法行为, 如有侵权请联系删除

技术共进,成长同行——讯飞AI开发者社区
更多推荐

 26
26 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)