
LLVM Cpu0 新后端2 第三部分 (包括mips扩栈 回栈策略)
LLVM手动开发一个新后端的系列课程的记录分享
想好好熟悉一下llvm开发一个新后端都要干什么,于是参考了老师的系列文章:
代码在这里(还没来得及准备,先用网盘暂存一下):
链接: https://pan.baidu.com/s/1yLAtXs9XwtyEzYSlDCSlqw?pwd=vd6s 提取码: vd6s
目录
1.3.2 较小栈空间:例如 0x0000 8008-0x0001 0000
1.3.3 较大栈空间:例如 0x0001 0008-0x0001 8000
1.3.4 大栈空间:0x0001 8008-0x8000 0000
1.4.3 较大栈空间:例如 0x0001 0000-0x0001 7ff8
1.4.4 更大栈空间:0x0001 8000-0x0001 fff8
1.4.5 大栈空间:0x0002 0000-0x7fff fff8
2.1 Cpu0AnalyzeImmediate.cpp/.h
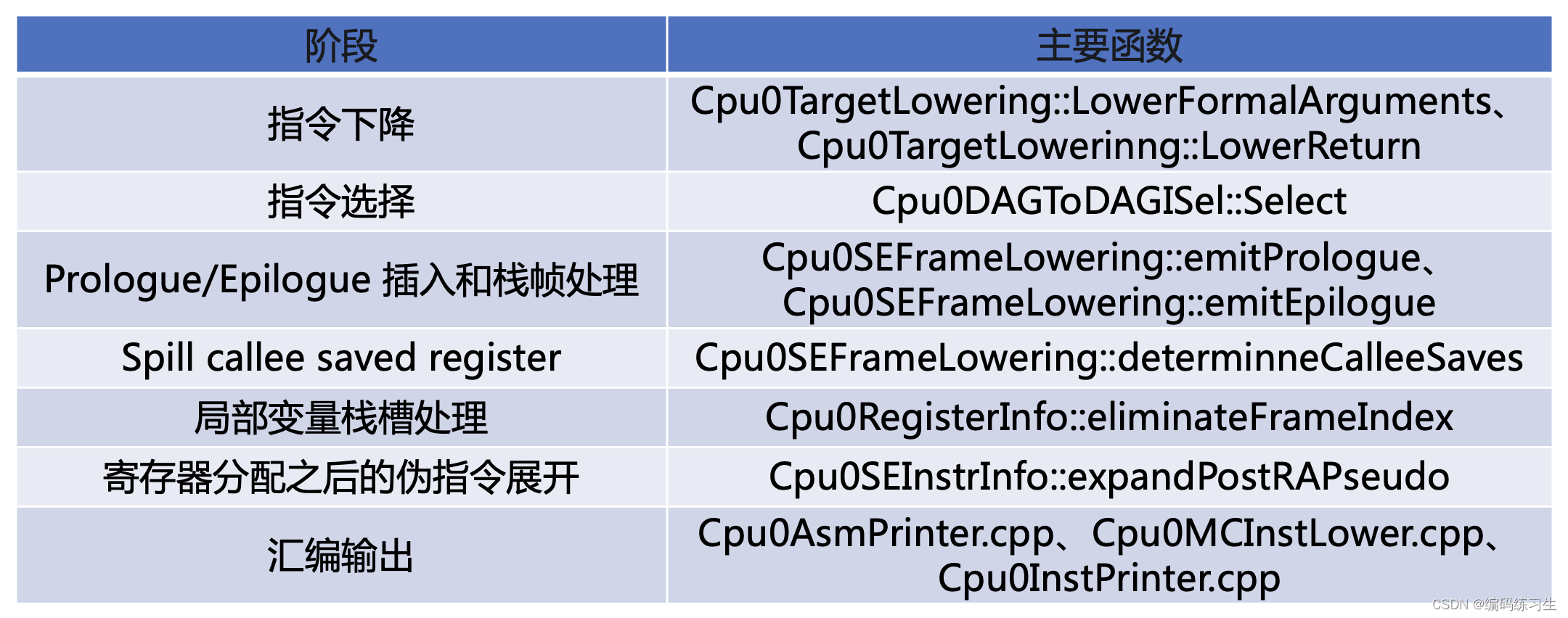
一些文件内的关键函数对应的关键阶段(目前参考原文章的,之后会进一步补充):
第五节 2-5
这一节主要增加对于栈桢的处理,增加prologue和epilogue。在了解代码之前我们先了解一下prologue、epilogue以及Cpu0的扩栈和回栈。
1. 理论基础
1.1 prologue和epilogue
proligue:在函数开始阶段,扩栈,创建当前函数的栈空间;发射一些伪指令;将callee saved寄存器存到栈上。
epilogue:在函数结束阶段,将栈上的callee saved寄存器内容重新存到对应的寄存器中,回栈。
1.2 指令缩减:addiu + shl = lui
在了解Cpu0的prologue和epilogue之前我们先了解一个接下来会用到的指令数目优化的策略。Lui指令是一个加载指令,将数据的高16位加载到寄存器的高16字节部分,然后寄存器的低16字节为0。
然而我们的shl左移操作,当移动的位数大于等于16位时,低16位为0,这里就与Lui指令不谋而合了。一定条件下我们可以通过Lui指令替换addiu+shl两条指令。
例如我们有 ADDiu 0x0111 和 SHL 18两条指令,其实这两条指令的结果可以通过一条LUi 0x444指令来实现,其中0x444是将0x111左移两位(18-16)的结果。
1.3 Cpu0的prologue
1.3.1 小栈空间:0x0000 - 0x8000
prologue扩栈是往栈底扩栈,是需要对sp进行sub获取add一个负数,16位有符号最小的负数是-0x8000,因此当栈的空间在这个范围内时,我们可以直接扩栈。
例如栈的大小为0x8000时:
# %bb.0:
addiu $13, $13, -32768 // -32768:-0x8000
...$13寄存器就是sp寄存器,我们之前在Cpu0RegisterInfo.td文件中名字写的数字,因此这里是$13。
这里有些人可能会有个疑问,我们实现的Cpu0架构是32位的,这里扩栈的时候为什么只能扩16位呢?这里是因为我们的Cpu0架构是RISC指令集,RISC指令集通常是定长的。我们之前在Cpu0InstrFormats.td文件内定义的定义的A型和L型指令的立即数的位数最多只能是16位,因此这里的范围也是16位数。再大的栈我们就不能处理了吗?当然不是,更大一些的我们要通过稍微复杂一点的方式来实现。
1.3.2 较小栈空间:例如 0x0000 8008-0x0001 0000
对于较小栈的空间我们通过一条指令实现不了了,这个时候我们需要搭配多条指令来实现。
例如栈的大小为0x8008时:
# %bb.0
addiu $1, $zero, -1 # 0 + (-1) = 0xffff ffff
shl $1, $1, 16 # 0xffff ffff << 16 = 0xffff 0000
addiu $1, $1, 32760 # 0xffff 0000 + 0x7ff8(32760) = 0xffff 7ff8
addu $13, $13, $1 # 0xffff 7ff8 = -0x8008
...这个时候我们可以搭配移位操作来实现。addiu执行之后$1内的数据是0xffff ffff,shl指令执行之后$1内的数据是0xffff 0000,然后我们再加上对应的后四位数据0x7ff8(32760),之后$1内为0xffff 7ff8,这个是-0x8008对应的补码。
这里我们可以使用2.1.2的指令优化策略优化一下指令数目,优化之后的结果为:
# %bb.0
lui $1, 65535 # 0xffff(65535) -> $1:0xffff 0000
addiu $1, $1, 32760 # 0xffff 0000 + 0x7ff8(32760) = 0xffff 7ff8
addu $13, $13, $1 # 0xffff 7ff8 = -0x8008
...优化前addiu和shl之后$1内为0xffff 0000,优化后lui之后$1内为0xffff 0000,不过我们能够减少一条指令。
这里就又有一个问题了,第三条指令addiu中立即数是有符号16位的,数据范围其实就是15位,如果到这一步需要修正的size的第16位有数据的话怎么办呢?这就是下一种扩栈方式。
1.3.3 较大栈空间:例如 0x0001 0008-0x0001 8000
我们先看例子,这里栈大小为0x10008:
# %bb.0
addiu $1, $zero, -1 # 0 + (-1) = 0xffff ffff
shl $1, $1, 16 # 0xffff ffff << 16 = 0xffff 0000
addiu $1, $1, -8 # 0xffff 0000 + 0xffff fff8(-8) = 0xfffe fff8
addu $13, $13, $1 # 0xfffe fff8 = -0x10008
...addiu之后$1中的内容为0xffff ffff,shl之后$1中的内容为0xffff 0000,然后通过addiu加上一个负数进行低位的修正为0xfffe fff8,也就是-0x0001 0008的补码。
使用2.1.2的指令优化策略优化一下指令数目,优化之后的结果为:
# %bb.0
lui $1, 65535 # 0xffff(65535) -> $1:0xffff 0000
addiu $1, $1, -8 # 0xffff 0000 + 0xffff fff8(-8) = 0xfffe fff8
addu $13, $13, $1 # 0xfffe fff8 = -0x10008
...栈大小为0x18000时:
# %bb.0
addiu $1, $zero, -1 # 0 + (-1) = 0xffff ffff
shl $1, $1, 16 # 0xffff ffff << 16 = 0xffff 0000
addiu $1, $1, -32768 # 0xffff 0000 + 0xffff 8000(-32768) = 0xfffe 8000
addu $13, $13, $1 # 0xfffe 8000 = -0x18000
...使用2.1.2的指令优化策略优化一下指令数目,优化之后的结果为:
# %bb.0
lui $1, 65535 # 0xffff(65535) -> $1:0xffff 0000
addiu $1, $1, -32768 # 0xffff 0000 + 0xffff 8000(-32768) = 0xfffe 8000
addu $13, $13, $1 # 0xfffe 8000 = -0x18000
...所以对于最后一步对栈大小的低位进行修正时,如果是32768-65528这种16位有符号正数直接表示不了的数据,我们可以通过addiu加上一个负数来实现。
1.3.4 大栈空间:0x0001 8008-0x8000 0000
对于更大的栈的空间的实现方式其实就是2.1.2.2和2.1.2.3两种方式,只是shl移位位数的不同,当最后能用16位有符号数据对栈大小的低位进行修正时,第三步就用addiu指令,否则的话就用ori指令。
1.4 Cpu0的epilogue
1.4.1 小栈空间:0x0000 - 0x7ff8
这里可能有人有个疑问,这里为什么是到0x7ff8呢?其实这里涉及到两个知识点,一个是我们栈的空间一般都是以一定字节(例如这里8字节)对齐的,很少(我目前没见过)有扩栈的size是以3、7这种结尾的,因此我们这里是以8结尾。然后为什么是到0x7ff8不是跟prologue一样的0x8000呢?这是因为扩栈是向下扩,我们需要加上一个负数,回栈的话我们是将当前的栈”删掉“,我们需要加上一个正数。有符号的16数字中负数最小值是0x8000,因此prologue是0x8000,然而正数最大值是0x7fff,然后我们又要进行8字节对齐,因此这里是0x7ff8。
例如栈大小是0x7ff8:
...
addiu $13, $13, 32760 # 32760 = 0x7ff8
ret $14
$func_end0:当栈空间在0x0000 - 0x7ff8范围内时我们一条指令就可以直接回栈。
1.4.2 较小栈空间:例如 0x8000-0xfff8
我们先看例子,例如栈空间为0x8000时:
...
ori $1, $zero, 32768 # 0 | 0x8000(32768) = 0x0000 8000
addu $13, $13, $1
ret $14
$func_end0:我们可以搭配ori指令(或操作)来实现,这里虽然是或操作,但是由于移位之后的数据低位都是0,因此此时对于低位来说就相当于加法,然后ori指令处理的立即数是无符号的。我们能够了解到通过ori指令我们能够间接实现16位有符号数表示不了的范围(32768-65528)的加法。因此对于这一范围我们可以通过ori指令将栈大小先存到寄存器中,然后再进行恢复。
1.4.3 较大栈空间:例如 0x0001 0000-0x0001 7ff8
我们先看例子,栈大小为0x10010时:
...
addiu $1, $zero, 1 # 0 + 1 = 0x0000 0001
shl $1, $1, 16 # 0x0000 0001 << 16 = 0x0001 0000
addiu $1, $1, 16 # 0x0001 0000 + 0x0000 0010(16) = 0x0001 0010
addu $13, $13, $1
ret $14
$func_end0:我们是搭配移位操作来实现的,addiu之后$1中的数据为0x0000 0001,移位之后$1为0x0001 0000,然后我们再通过addiu对低位进行修正,修正之后为0x0001 0010,就是我们要回栈的大小。
使用2.1.2的指令优化策略优化一下指令数目,优化之后的结果为:
...
lui $1, 1 # 0x0000 0001 -> $1: 0x0001 0000
addiu $1, $1, 16 # 0x0001 0000 + 0x0000 0010(16) = 0x0001 0010
addu $13, $13, $1
ret $14
$func_end0:同理,根据上边我们了解到在进行低位修正时,addiu修正的数据的范围有限,这个时候我们就需要依赖加上负数来实现了,也就是下边的情况。
1.4.4 更大栈空间:0x0001 8000-0x0001 fff8
我们先看例子,栈大小为0x0001 fff8时:
...
addiu $1, $zero, 1 # 0 + 1 = 0x0000 0001
shl $1, $1, 17 # 0x0000 0001 << 17 = 0x0002 0000
addiu $1, $1, -8 # 0x0002 0000 + 0xffff fff8(-8) = 0x0001 fff8
addu $13, $13, $1
ret $14
$func_end0:addiu之后$1内的数据为0x0000 0001,shl之后为0x0002 0000,再通过addiu对低位进行修正,为0x0001 fff8。
其实整体的方案跟上一种情况是一样的,只是通过多移一位+减法操作实现。
使用2.1.2的指令优化策略优化一下指令数目,优化之后的结果为:
...
lui $1, 2 # 0x0000 0002 -> $1: 0x0002 0000
addiu $1, $1, -8 # 0x0002 0000 + 0xffff fff8(-8) = 0x0001 fff8
addu $13, $13, $1
ret $14
$func_end0:1.4.5 大栈空间:0x0002 0000-0x7fff fff8
对于更大的栈的空间的实现方式其实就是2.1.4.4和2.1.4.5两种方式,只是shl移位位数的不同,当最后能用16位有符号数据对栈大小的低位进行修正时,第三步就用addiu指令,否则的话就用addiu 负数来实现。
2. 新增文件
2.1 Cpu0AnalyzeImmediate.cpp/.h
实现了一个 Cpu0AnalyzeImmediate 类,这个类的主要作用是用来分析一些带立即数的指令,将一些不支持的形式转化为支持的形式,比如 ADDiu 操作立即数、ORi 操作立即数、SHL 操作立即数,甚至是他们的组合。
我们这里特殊处理立即数是因为当立即数比较大时,指令编码的空间有限,就可能无法用单条指令来实现了。而本节我们还需要支持大栈空间的调栈操作,当栈空间足够大时,立即数偏移就可能无法直接支持,就需要我们对立即数做特殊处理。
void Cpu0AnalyzeImmediate::GetInstSeqLsADDiu(uint64_t Imm, unsigned RemSize,
InstSeqLs &SeqLs) {
GetInstSeqLs((Imm + 0x8000ULL) & 0xffffffffffff0000ULL, RemSize, SeqLs);
AddInstr(SeqLs, Inst(ADDiu, Imm & 0xffffULL));
}
void Cpu0AnalyzeImmediate::GetInstSeqLsORi(uint64_t Imm, unsigned RemSize,
InstSeqLs &SeqLs) {
GetInstSeqLs(Imm & 0xffffffffffff0000ULL, RemSize, SeqLs);
AddInstr(SeqLs, Inst(ORi, Imm & 0xffffULL));
}
void Cpu0AnalyzeImmediate::GetInstSeqLsSHL(uint64_t Imm, unsigned RemSize,
InstSeqLs &SeqLs) {
unsigned Shamt = countTrailingZeros(Imm);
GetInstSeqLs(Imm >> Shamt, RemSize - Shamt, SeqLs);
AddInstr(SeqLs, Inst(SHL, Shamt));
}
void Cpu0AnalyzeImmediate::GetInstSeqLs(uint64_t Imm, unsigned RemSize,
InstSeqLs &SeqLs) {
uint64_t MaskedImm = Imm & (0xffffffffffffffffULL >> (64 - Size));
// Do nothing if Imm is 0.
if (!MaskedImm)
return;
// A single ADDiu will do if RemSize <= 16.
if (RemSize <= 16) {
AddInstr(SeqLs, Inst(ADDiu, MaskedImm));
return;
}
// Shift if the lower 16-bit is cleared.
if (!(Imm & 0xffff)) {
GetInstSeqLsSHL(Imm, RemSize, SeqLs);
return;
}
GetInstSeqLsADDiu(Imm, RemSize, SeqLs);
// If bit 15 is cleared, it doesn't make a difference whether the last
// instruction is an ADDiu or ORi. In that case, do not call GetInstSeqLsORi.
if (Imm & 0x8000) {
InstSeqLs SeqLsORi;
GetInstSeqLsORi(Imm, RemSize, SeqLsORi);
SeqLs.insert(SeqLs.end(), SeqLsORi.begin(), SeqLsORi.end());
}
}这里是Cpu0AnalyzeImmediate 类的核心处理逻辑,针对不同的size计算合适的指令,我们以0x10008为例:
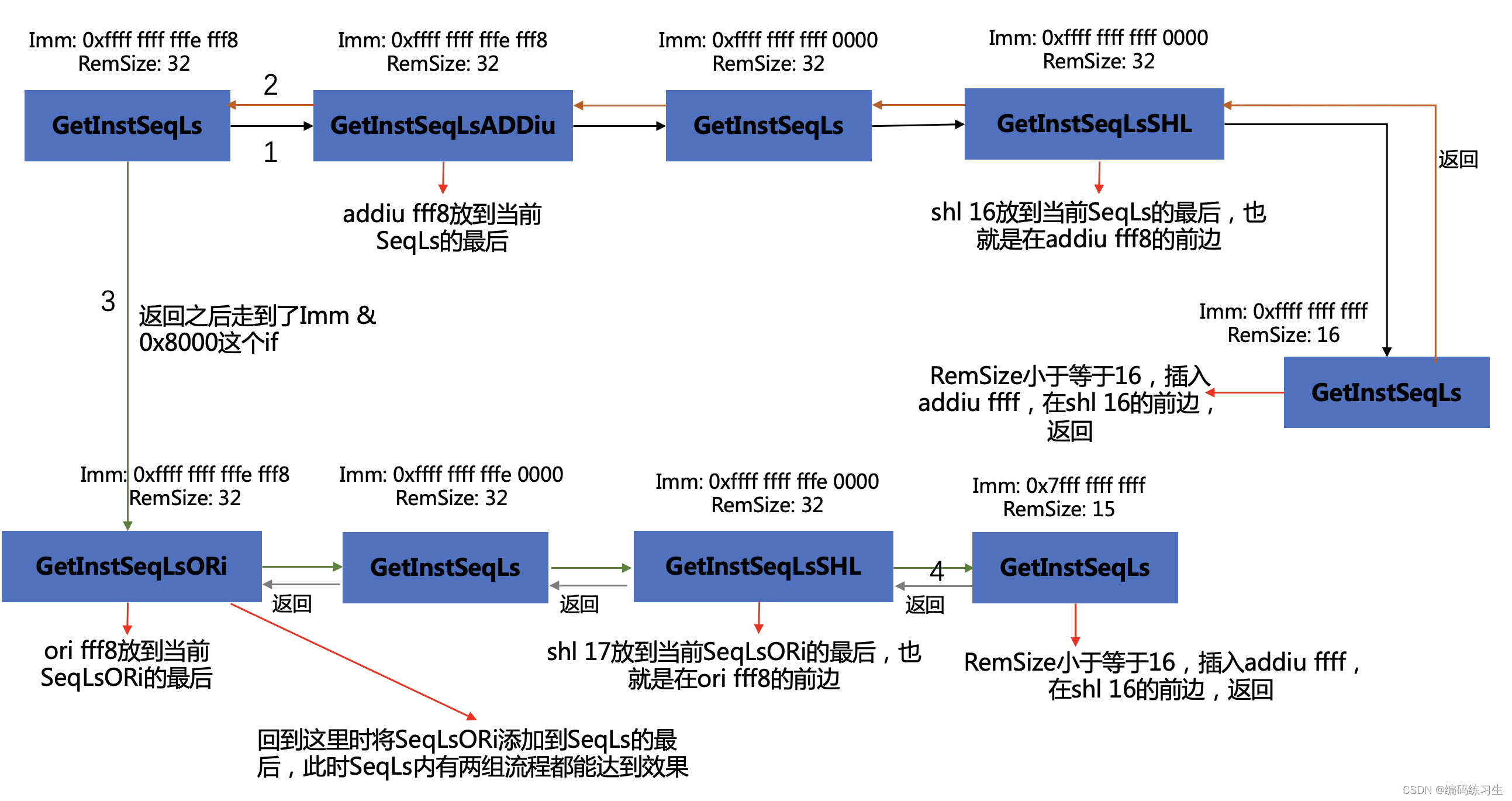
执行到最后的时候SeqLs内有两组可行解,然后我们会执行GetShortestSeq函数,通过lower成lui指令来对指令数目进行优化,同时我们会在多组可行解内选择指令树木最少的最为最终的结果进行返回。
3. 修改文件
3.1 Cpu0InstrInfo.cpp/.h
将基类的 loadRegFromStack 和 storeRegToStack 虚函数声明出来,并定义了 loadRegFromStackSlot 和 storeRegToStackSlot 用来当做 Offset 为 0 的特殊情况使用。实现了一个 GetMemOperand 函数用来构造出内存操作数。
3.2 Cpu0InstrInfo.td
新增了一些用于 load/store 和 立即数处理的 pattern。LUi 指令用于将一个 16 位立即数放到寄存器的高 16 位,寄存器的低 16 位赋值 0。SHL 是左移指令。
// Immediate can be loaded with LUi (32-bit int with lower 16-bit cleared).
def immLow16Zero : PatLeaf<(imm), [{
int64_t Val = N->getSExtValue();
return isInt<32>(Val) && !(Val & 0xffff);
}]>;
// Transformation Function: get the higher 16 bits.
def HI16 : SDNodeXForm<imm, [{
return getImm(N, (N->getZExtValue() >> 16) & 0xffff);
}]>;
def LUi : LoadUpper<0x0f, "lui", GPROut, uimm16>;
def : Pat<(i32 immLow16Zero:$in), (LUi (HI16 imm:$in))>;定义了lui指令,指令的立即数是16位无符号数。然后定义了一个匹配模式,将低 16 位为 0 的立即数映射为 LUi HI16 imm。
其中,也注意到将 16 位无符号数映射为 ORi ZERO, imm。
3.3 Cpu0MachineFunctionInfo.h
实现了几个辅助函数,用来读写一些特殊属性,比如 IncomingArgSize,CallsEhReturn 等。
3.4 Cpu0RegisterInfo.cpp
主要实现 了eliminateFrameIndex 函数。输入这个函数之前的指令,带有一个 FrameIndex 的操作数,这个函数用来将 FrameIndex 替换为寄存器与一个偏移的组合。对于输出参数、动态分配栈空间的指针和全局保存的寄存器,不需要调整 offset,如果是其他的,则需要调整,比如输入参数、callee saved 寄存器或局部变量。根据FrameIndex计算的是寄存器在栈上的offset,通过之前我们知道了在prologue中我们要将callee saved 寄存器存到栈上,在epilogue中我们要将callee saved 寄存器恢复回去,因此我们要能够知道这些寄存器在栈上的具体位置才能准确处理。
3.5 Cpu0SEFrameLowering/.h
主要实现之前就留空的函数:emitPrologue 和 emitEpilogue 函数,这两个函数是基类定义好的虚函数。
emitPrologue 函数的主要内容有:
- 拿到栈空间大小,并调整栈指针,创建新的栈空间。
- 发射一些伪指令。
- 获取 CalleeSavedInfo,将 Callee Saved Register 保存到栈中。
emitEpilogue 函数的主要内容有:
- 还原 Callee Saved Register。
- 拿到栈空间大小,并调整栈指针,丢弃栈空间。
另外还有几个函数。hasReservedCallFrame 用来判断最大的调用栈空间是否能用 16 位立即数表示且栈中没有可变空间的对象。determineCalleeSaves 和 setAliasRegs 用来在插入 Prologue 和 Epilogue 代码之前判断需要 spill 的 callee saved 寄存器,当确定 spill 寄存器后, eliminateFrameIndex 就可以将确定的寄存器保存到栈中正确位置,或从栈中正确位置取出寄存器值。
void Cpu0SEFrameLowering::emitPrologue(MachineFunction &MF,
MachineBasicBlock &MBB) const {
assert(&MF.front() == &MBB && "Shrink-wrapping not yet supported");
MachineFrameInfo &MFI = MF.getFrameInfo();
Cpu0MachineFunctionInfo *Cpu0FI = MF.getInfo<Cpu0MachineFunctionInfo>();
const Cpu0SEInstrInfo &TII =
*static_cast<const Cpu0SEInstrInfo*>(STI.getInstrInfo());
const Cpu0RegisterInfo &RegInfo =
*static_cast<const Cpu0RegisterInfo*>(STI.getRegisterInfo());
MachineBasicBlock::iterator MBBI = MBB.begin();
DebugLoc dl = MBBI != MBB.end() ? MBBI->getDebugLoc() : DebugLoc();
Cpu0ABIInfo ABI = STI.getABI();
unsigned SP = Cpu0::SP;
const TargetRegisterClass *RC = &Cpu0::GPROutRegClass;
// First, compute final stack size.
uint64_t StackSize = MFI.getStackSize();
// No need to allocate space on the stack.
if (StackSize == 0 && !MFI.adjustsStack()) return;
MachineModuleInfo &MMI = MF.getMMI();
const MCRegisterInfo *MRI = MMI.getContext().getRegisterInfo();
// Adjust stack.
TII.adjustStackPtr(SP, -StackSize, MBB, MBBI);
// emit ".cfi_def_cfa_offset StackSize"
unsigned CFIIndex = MF.addFrameInst(
MCCFIInstruction::cfiDefCfaOffset(nullptr, -StackSize));
BuildMI(MBB, MBBI, dl, TII.get(TargetOpcode::CFI_INSTRUCTION))
.addCFIIndex(CFIIndex);
const std::vector<CalleeSavedInfo> &CSI = MFI.getCalleeSavedInfo();
if (CSI.size()) {
// Find the instruction past the last instruction that saves a callee-saved
// register to the stack.
for (unsigned i = 0; i < CSI.size(); ++i)
++MBBI;
// Iterate over list of callee-saved registers and emit .cfi_offset
// directives.
for (std::vector<CalleeSavedInfo>::const_iterator I = CSI.begin(),
E = CSI.end(); I != E; ++I) {
int64_t Offset = MFI.getObjectOffset(I->getFrameIdx());
unsigned Reg = I->getReg();
{
// Reg is in CPURegs
unsigned CFIIndex = MF.addFrameInst(MCCFIInstruction::createOffset(
nullptr, MRI->getDwarfRegNum(Reg, 1), Offset));
BuildMI(MBB, MBBI, dl, TII.get(TargetOpcode::CFI_INSTRUCTION))
.addCFIIndex(CFIIndex);
}
}
}
}这里是prologue的实现,adjustStackPtr函数实现扩栈的操作,然后插入一些cfi信息,接下来的for循环就是遍历当前函数内使用的callee saved 寄存器。
3.6 Cpu0SEInstrInfo.cpp/.h
实现两个重要函数:storeRegToStack 和 loadRegFromStack 函数,这两个函数是基类定义好的虚函数。前者用于生成将寄存器 store 入栈中的动作,后者用于生成将栈中值 load 到寄存器的动作。目前我们生成的都是使用 st 和 ld 指令来完成。因为每个局部变量都对应一个 frame index,所以他们在寄存器分配阶段对应的虚拟寄存器的 offset 都是 0,这两个函数虽然定义了,但目前还没有使用。
还实现了 adjustStackPtr 和loadImmediate函数,用来做栈指针调整的动作。 adjustStackPtr 需要根据调整距离是否大于 16 位能表示的范围,分为两种操作分别使用 ADDiu 和 ADDu 来处理,如果是16位有符号的数据的话,就直接生成对应指令,如果超过范围了的话,需要调用loadImmediate函数,loadImmediate函数函数调用了Cpu0AnalyzeImmediate来计算当前的大小最少需要依赖哪些指令来实现。

技术共进,成长同行——讯飞AI开发者社区
更多推荐
 14
14 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)