
软件工程理论与实践第8期-12 软件工程前沿技术
本章目的是使学习者了解当前软件工程领域最新的研究动态和前沿技术成果。本章共介绍三个前沿技术成果:软件自动生成补丁技术能够辅助程序员修复缺陷,提高缺陷修复的效率和质量;aiXcoder工具将采用与程序员一起“结对编程”的方式为程序员提供服务,从而提高程序员的编程效率;SnowGraph能够实现面向多源异质、动态增长的软件大数据的软件知识自动识别、抽取、关联与融合过程,提炼出大规模、内容全面、语义丰富
目录
12 软件工程前沿技术
12-1 软件自动生成补丁
第1关:程序缺陷定位
任务描述
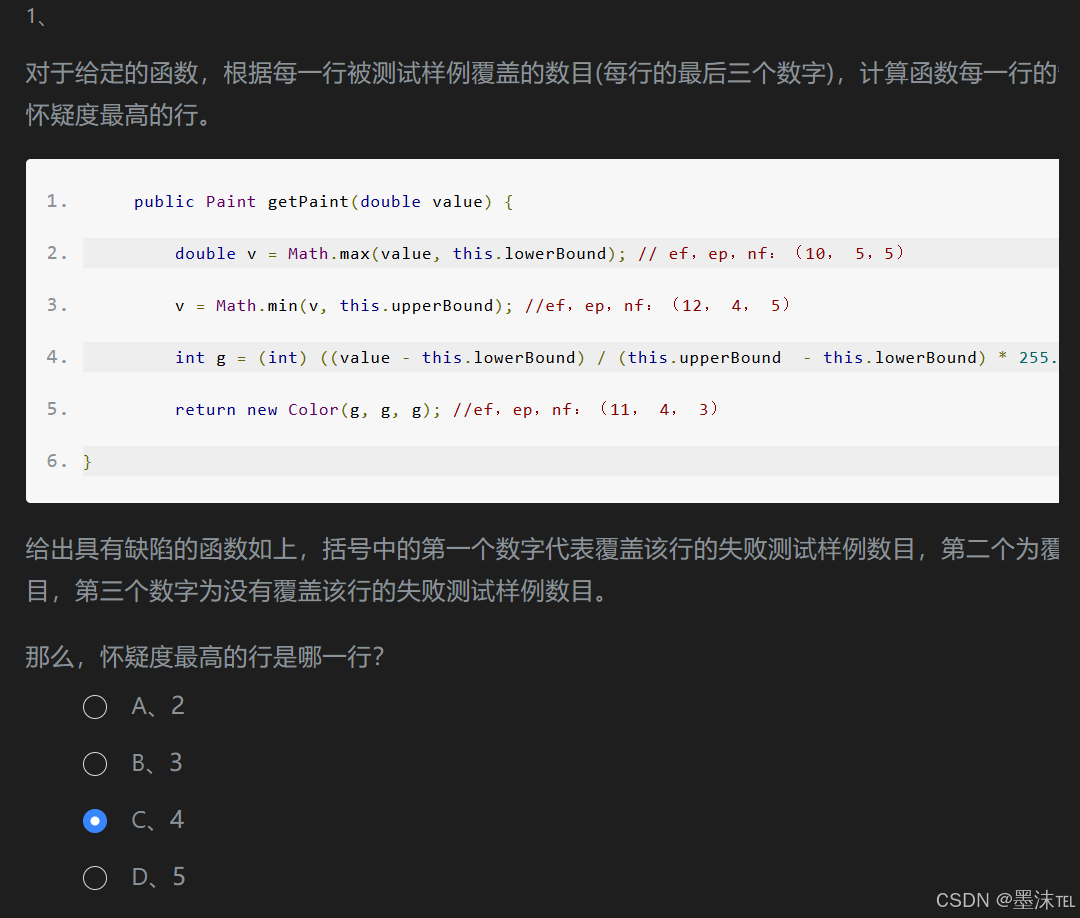
本关任务:根据怀疑度公式结合计算每一行代码最后的三个数字计算怀疑度。
相关知识
为了完成本关任务,你需要掌握:
怀疑度公式之Ochiai公式。
程序缺陷定位
在实际的软件工程中,成千上万的代码行中往往出现缺陷的代码仅有几行,但是程序员却难以判断具体出现缺陷的代码位置,程序缺陷定位技术则是用于定位缺陷代码。主流的一种缺陷定位技术是根据软件测试中编写相应的测试样例的覆盖情况,对于每一行代码进行相关怀疑度的计算,根据怀疑度进行缺陷定位。其中,最常用的一种怀疑度公式为Ochiai公式。
Ochiai值高的代码行则是具有高怀疑度的代码行,反之则是具有低怀疑度的代码行。怀疑度高的代码行很有可能是错误的代码行。
Ochiai 公式
怀疑度公式形式如下
![]()
其中e f指覆盖该行的失败的测试样例的数目,e p 指的是覆盖该行的通过的测试样例,n f 指的是没有覆盖该行的失败的测试样例数目。
第2关:程序自动修复工具:Recoder
任务描述
本关任务:了解程序自动修复工具Recoder。
相关知识
为了完成本关任务,你需要掌握:
1.程序自动修复技术
2.Recoder
程序自动修复技术
程序自动修复技术顾名思义即根据缺陷代码和程序缺陷定位结果自动生成对应的补丁。传统的程序自动修复技术大致分为两类,一类从海量的历史补丁中归纳对应的程序修复模板,针对新的缺陷程序,根据模板生成相应的补丁。另一类从相似的代码修改中生成对应的程序补丁。
随着深度学习技术的发展,基于神经网络的翻译技术被用于生成补丁。主流的技术主要用神经机器翻译(NMT,neural machine translation),输入具有缺陷的函数,直接输出对应的修改后的程序。
Recoder
现有基于深度学习的程序修复技术的不足之处
生成的补丁包括语法不正确的程序。基于翻译技术生成的补丁,由于将程序当成自然语言,因此很容易生成的程序不满足对应语言的语法限制。
表达补丁的方式不够高效。基于翻译技术的技术,只能够完全生成对应的修复程序。但在实际应用情况中,存在仅仅修改表达式的一小部分但是表达式本身比较复杂的情况,针对这种情况,现有技术很难生成正确的复杂表达式。
不能生成用户自定义的标识符。现有的技术不能将整个项目的上下文都输入神经网络,因此许多用户在项目中自定义的标识符都不在词库和输入的上下文中,因此许多缺陷都难以修复。
Recoder对应的解决方案
使用语法制导的解码器进行补丁的生成,同时将补丁表示成为编辑操作的序列。语法制导的解码器使得生成的补丁一定满足相应编程语言的语法约束。编辑操作能够比较简洁的表达基于复杂表达式的简单修改操作。
用placeholder代替用户自定义的标识符。生成补丁的时候,允许模型能够生成placeholder用来代替用户定义的标识符,最后再通过后处理替换掉placeholder。
实验结果
在常用的缺陷数据集Defects4J上能够取得比现有最佳模型高26.2%的性能。
第3关:Recoder模拟使用
任务描述
本关任务:使用自动修复工具生成补丁,并选择最合适的补丁。
相关知识
为了完成本关任务,你需要掌握:
1.如何使用自动修复工具。
2.根据题目使用自动修复工具纠正缺陷代码,通过本关卡。
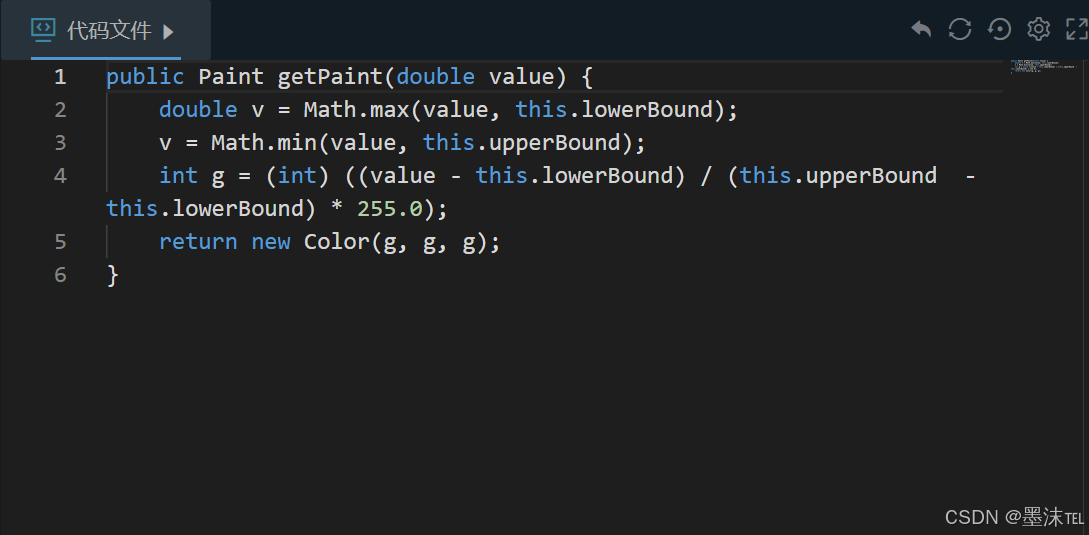
缺陷代码

这段程序的缺陷在第4行,接下来我们将使用自动修复工具体验自动修复缺陷的过程。
生成补丁
复制上述对应的缺陷代码(复制的时候注意将每行最后的分数删除)和缺陷定位结果(行号)到工具中,生成对应的补丁。
补丁选择
在工具中首先按下start generate,产生所有可能正确的结果,再按下valid patch弹出最终正确的补丁。最后将正确的补丁修改至源代码并提交(由于该例子没有提供具体的项目环境,因此此按钮仅模拟本缺陷的补丁验证过。(此工具已经安装在了镜像)
12-2 aiXcoder工具体验
第1关:aiXcoder初体验
按题目要求在vscode中安装aiXcoder插件,随便写一个代码并体验代码智能补全功能,提交就可以过。
第2关:aiXcoder的功能
aiXcoder知识点学习
aiXcoder简单介绍
aiXcoder是一款全新的智能编程机器人产品,它拥有的功能为智能代码提示、代码风格检查、编程模式学习。它采用与程序员一起“结对编程”的方式为程序员提供服务,从而提高程序员的编程效率。在aiXcoder的辅助下,程序将摆脱传统的编程模式,不再需要“逐字逐句”编写程序。
aiXcoder能够自动预测程序员的编程意图,连续向程序员推荐“即将书写的下一段代码”,程序员可以通过“一键补全”的方式,直接确认接下来输入的代码,从而大大提升代码的编写效率。同时,aiXcoder还能够在程序编程的过程中,不断智能地搜索并推荐与当前程序功能相似的规范程序代码,为程序员提供有力的编程参考。例如条件语句、循环语句这些控制流,aiXcoder 不仅能预测出「if、for、while」这些关键词,同时还会尽可能完成内部的逻辑。
目前最新版本的aiXcoder所支持的功能:
1.新增 Python 语言支持:在 PyCharm 上可直接安装使用
2.反馈速度提升:2.5.0 比 2.0.0 在反馈时间上减少了50%到70%
3.底层模型更新:更合理的深度学习模型结构,以及优化数据预处理等过程,提升预测准确率
4.新增等号右预测(For Java):考虑到开发者可能在变量定义部分先写等号右侧的表达式,再返回来定义变量名,aiXcoder 支持在未定义变量名的情况下直接预测表达式。
5.修复一些已知 Bug:包括重复预测问题、分词问题、Python 长预测问题等等。
支持 TensorFlow 框架搭模型
在写 TensorFlow 的时候,aiXcoder 可以直接预测出正确的 API,甚至很多时候还能根据上下文预测出正确的参数。当然,尽管我们已经做过非常多的优化,但aiXcoder背后毕竟是深度学习模型,我们同样提供了滚动条,来平衡「补全能力」和「计算性能」之间的关系。
任务要求
相信你在第一关完成了aixcoder的初体验后,对这款插件有了更深的了解。接下啦请认真阅读关于aixcoder的知识点介绍,并完成以下题目。
12-3 SnowGraph工具体验
第1关:SnowGraph 基本信息
任务描述
阅读SnowGraph的介绍,并完成题目。
SnowGraph介绍
总体介绍
SnowGraph(Software Knowledge Graph)是一个软件项目知识图谱自动生成和问答系统。它能够实现面向多源异质、动态增长的软件大数据的软件知识自动识别、抽取、关联与融合过程,提炼出大规模、内容全面、语义丰富的软件知识图谱,为实现面向特定软件项目的知识检索和问答系统提供了知识基础。针对开发者提出的自然语言问题,SnowGraph 提供了智能化的软件项目知识图谱的自然语言查询工具和融合代码知识的软件文档自然语言检索工具,从而为程序理解和软件开发提供了基础支撑。
软件项目知识图谱构造
软件项目知识图谱自动生成框架 SnowGraph 采取一种以源代码为核心、多种信息抽取方法协同的方式全自动化地进行软件知识图谱的构造,并采取插件机制进行图谱未来知识的扩展。软件项目知识图谱基于图数据库,实现了对知识图谱的存储、索引、查询等基础支持的建立,为软件项目数据的解析、关联融合与知识挖掘提炼提供了支撑环境。在数据解析方面,图谱兼容多种不同类型的软件工程数据,包括:软件源代码、各种版本控制系统(例如:svn,git)的版本记录、 邮件列表日志、缺陷追踪系统日志、html 网页文档、word 文档、pdf 文档等。对开源软件开发和企业软件开发中的绝大部分数据源都能实现支持。在知识关联融合提炼方面,该工具内置了多种可追踪性关联分析与知识补全模块,能够充分对不同来源的软件数据间的语义关联进行智能恢复补全,且能够从数据中提炼出更适合管理者、开发者与复用者理解的知识。
与其他主流软件知识图谱相比,SnowGraph 知识图谱在构造方法自动化程度、可扩展性以及图谱相关类型信息等方面具有明显优势:
1、SnowGraph 知识图谱在构造知识图谱的过程中,以源代码为核心,采取了多种信息抽取的方法协同进行知识图谱的全自动化构造,相较于其他主流软件知识图谱,SnowGraph 的知识图谱构造方法自动化程度最高;
2、SnowGraph 知识图谱采取一种插件机制,使得知识图谱对于其他数据源的软件相关数据具备很好的通用性和可扩展性,能够对未来可能出现的新的知识需求、知识来源和知识抽取、关联、提炼等进行支持;
3、SnowGraph 知识图谱的数据来源多样、广泛关联、语义丰富,其中,实体类型和关系类型明显丰富于其他主流软件知识图谱,从而,在对应的软件知识表示和知识利用的任务上,具备更好的效果。
软件项目图谱示例:Apache Lucene
Apache Lucene是被广泛使用的开源全文搜索引擎库。目前,收集到的 Lucene 项目数据超过8GB,包括:
全部67个版本,超过80万行源代码
24万条邮件记录
5200条缺陷报告
500多个官方文档
大量相关技术博客
SnowGraph 为 Lucene 项目抽取出16种不同类型的378,897个实体,包含3,434,974条属性;关联融合了31种不同类型的1,902,683条边。具体的实体类型和边的分布如图所示。
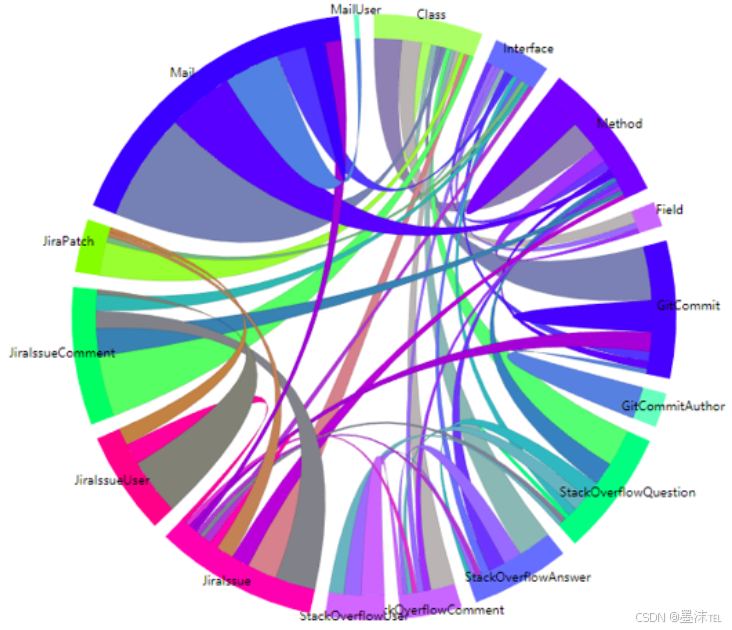
图1 Lucene项目
软件项目知识图谱的自然语言查询工具
针对自然语言查询软件知识图谱中的实体和关系,SnowGraph 提供一套基于推理子图的自然语言-形式化查询转化方法。对于复用者给出的一个自然语言形式的问句,将其转换为软件项目知识图谱上的一个形式化的查询语句,从而返回准确的查询结果。
该工具通过一种基于隐藏结点扩展的推理子图转换技术,结合最小生成树算法和最短编辑距离算法,能够快速生成一个自然语言问题的候选推理子图;同时,基于推理子图的结构特征和自然语言的文本信息,能够对不同形状的推理子图进行度量,最终推荐出一个得分最高的推理子图,并据此生成相应的形式化查询语句、在知识图谱上查询得到答案。
在这个方法中,我们首次提出了推理子图的概念,并通过构造和度量推理子图,建立自然语言到形式化查询语句之间的转化桥梁。一方面,相较于传统的语义解析的逻辑形式系统,子图转化的方法更容易表达自然语言的语义信息;另一方面,利用推理子图的生成与度量可以很好地解决自然语言的歧义问题。
基于知识图谱的软件文档自然语言查询
对于复杂的自然语言提问,SnowGraph 提供了融合代码知识的答案检索工具。该工具借助软件项目的知识图谱来计算不同单词之间的潜在语义相关度,从而对候选文本集合进行筛选与评估,返回更为准确的答案。
在软件项目中,源代码可以看作是对领域知识的具体实现。对于具有良好的代码规范和设计模式的源代码而言,其中的各个代码实体的命名以及这些代码实体之间的结构依赖关系可以很好地反映出这个软件项目中的领域知识。因此,工具可以利用软件项目的知识图谱来帮助机器理解软件文本的语义,从而提升文档搜索的效果。
具体解决方案是:以单词匹配为主,结合多种歧义消除技术,识别出与一段软件文本相关的代码实体集合;参考信息检索领域的指标,度量软件文本与代码实体之间 的关联关系的强弱程度,从而将软件文本的语义结构化地表示为一个带权重的代码实体的集合;基于知识图谱表示学习技术,以代码实体之间的关联关系作为桥梁,度量软件文本间的语义相似度;以语义相似度作为核心特征,综合考虑多方面特征建立对候选答案段落的评估模型从而抽取出最为合适的文本片段作为答案返回给复用者。
第2关:智能问答工具体验
任务描述
以 Lucene 项目为例,体验使用 SnowGraph ,了解、学习软件项目。
访问SnowGraph主页
点击左侧“Use It"模块,找到 Lucene 项目,并查看 Lucene 项目的知识图谱。
Lucene 是一个被广泛使用的开源全文搜索引擎库,提供非常丰富的 API 。那么,将文档存储到索引中需要使用哪些 API 呢?选择智能问答模块,提问“How to write a document into an index?”,看看 SnowGraph 的回答!

技术共进,成长同行——讯飞AI开发者社区
更多推荐


 21
21 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)