
一文读懂运维消息中间件之KAFKA
一文读懂运维消息中间件之KAFKA,适合小白学习及上班族日常工作参考。
目录
更多精彩博文详见:
(一)、KAFKA简介
Kafka是一种高吞吐量的分布式发布订阅消息系统(消息引擎系统),简单点理解就是系统A发送消息给kafka(消息引擎系统),系统B从kafka中读取A发送的消息,而kafka就是个中间商。
Kafka的消息传递模式就是一种发布-订阅模式。在发布-订阅消息系统中,消息被持久化到一个topic中。与点对点消息系统不同的是,消费者可以订阅一个或多个topic,消费者可以消费该topic中所有的数据,同一条数据可以被多个消费者消费,数据被消费后不会立马删除。在发布-订阅消息系统中,消息的生产者称为发布者,消费者称为订阅者。
发布-订阅模式的示例图如下:

1、KAFKA基本术语
Kafka的相关术语及其之间的关系如下图所示:

说明:
- 上图中一个topic配置了3个partition。Partition1有两个offset:0和1。Partition2有4个offset。Partition3有1个offset。副本的id和副本所在的机器的id恰好相同。
- 如果一个topic的副本数为3,那么Kafka将在集群中为每个partition创建3个相同的副本。集群中的每个broker存储一个或多个partition。多个producer和consumer可同时生产和消费数据。
(1)、topic
- Kafka将消息分门别类,每一类的消息称之为一个主题(Topic)。一个topic可以有零个,一个或多个消费者订阅该主题的消息。一个topic实际是由多个partition组成的,遇到瓶颈时,可以通过增加partition的数量来进行横向扩容。单个parition内是保证消息有序。
- 类似于数据库的表名。
- Topic在逻辑上可以被认为是一个queue,每条消息都必须指定它的Topic,可以简单理解为必须指明把这条消息放进哪个queue里。对于传统的message queue而言,一般会删除已经被消费的消息,而Kafka集群会保留所有的消息,无论其被消费与否。
(2)、partition
- topic中的数据分割为一个或多个partition。每个topic至少有一个partition。每个partition中的数据使用多个segment文件存储。partition中的数据是有序的,不同partition间的数据丢失了数据的顺序。如果topic有多个partition,消费数据时就不能保证数据的顺序。在需要严格保证消息的消费顺序的场景下,需要将partition数目设为1。
(3)、producer
- 生产者即数据的发布者,该角色将消息发布到Kafka的topic中。broker接收到生产者发送的消息后,broker将该消息追加到当前用于追加数据的segment文件中。生产者发送的消息,存储到一个partition中,生产者也可以指定数据存储的partition。
(4)、consumer
- 消费者可以从broker中读取数据。消费者可以消费多个topic中的数据。
(5)、broker
- Kafka 集群包含一个或多个服务器,服务器节点称为broker。
- broker存储topic的数据。如果某topic有N个partition,集群有N个broker,那么每个broker存储该topic的一个partition。
- 如果某topic有N个partition,集群有(N+M)个broker,那么其中有N个broker存储该topic的一个partition,剩下的M个broker不存储该topic的partition数据。
- 如果某topic有N个partition,集群中broker数目少于N个,那么一个broker存储该topic的一个或多个partition。在实际生产环境中,尽量避免这种情况的发生,这种情况容易导致Kafka集群数据不均衡。
(6)、Consumer Group
- 每个Consumer属于一个特定的Consumer Group(可为每个Consumer指定group name,若不指定group name则属于默认的group)。
- 同一Topic的一条消息只能被同一个Consumer Group内的一个Consumer消费,但多个Consumer Group可同时消费这一消息。

(7)、Leader
- 每个partition有多个副本,其中有且仅有一个作为Leader,Leader是当前负责数据的读写的partition。
(8)、Follower
- Follower跟随Leader,所有写请求都通过Leader路由,数据变更会广播给所有Follower,Follower与Leader保持数据同步。如果Leader失效,则从Follower中选举出一个新的Leader。当Follower与Leader挂掉、卡住或者同步太慢,leader会把这个follower从“in sync replicas”(ISR)列表中删除,重新创建一个Follower。
2、KAFKA总体数据流图
一个典型的Kafka集群中包含若干Producer(可以是web前端产生的Page View,或者是服务器日志,系统CPU、Memory等),若干broker(Kafka支持水平扩展,一般broker数量越多,集群吞吐率越高),若干Consumer Group,以及一个Zookeeper集群。Kafka通过Zookeeper管理集群配置,选举leader,以及在Consumer Group发生变化时进行rebalance。Producer使用push模式将消息发布到broker,Consumer使用pull模式从broker订阅并消费消息。
Producers往Brokers里面的指定Topic中写消息,Consumers从Brokers里面拉去指定Topic的消息,然后进行业务处理。图中有两个topic,topic 0有两个partition,topic 1有一个partition,三副本备份。可以看到consumer gourp 1中的consumer 2没有分到partition处理,这是有可能出现的,下面会讲到。
关于broker、topics、partitions的一些元信息用zk来存,监控和路由啥的也都会用到zk。

3、KAFKA生产流程

(1)、生产者发布消息
1)写入方式
producer 采用 push 模式将消息发布到 broker,每条消息都被 append 到 patition 中,属于顺序写磁盘(顺序写磁盘效率比随机写内存要高,保障 kafka 吞吐率)。
2)消息路由
producer 发送消息到 broker 时,会根据分区算法选择将其存储到哪一个 partition。
其路由机制为:
- 指定了 patition,则直接使用;
- 未指定 patition 但指定 key,通过对 key 的 value 进行hash 选出一个
- patition patition 和 key 都未指定,使用轮询选出一个 patition。
3)写入流程
producer 写入消息序列图如下所示:
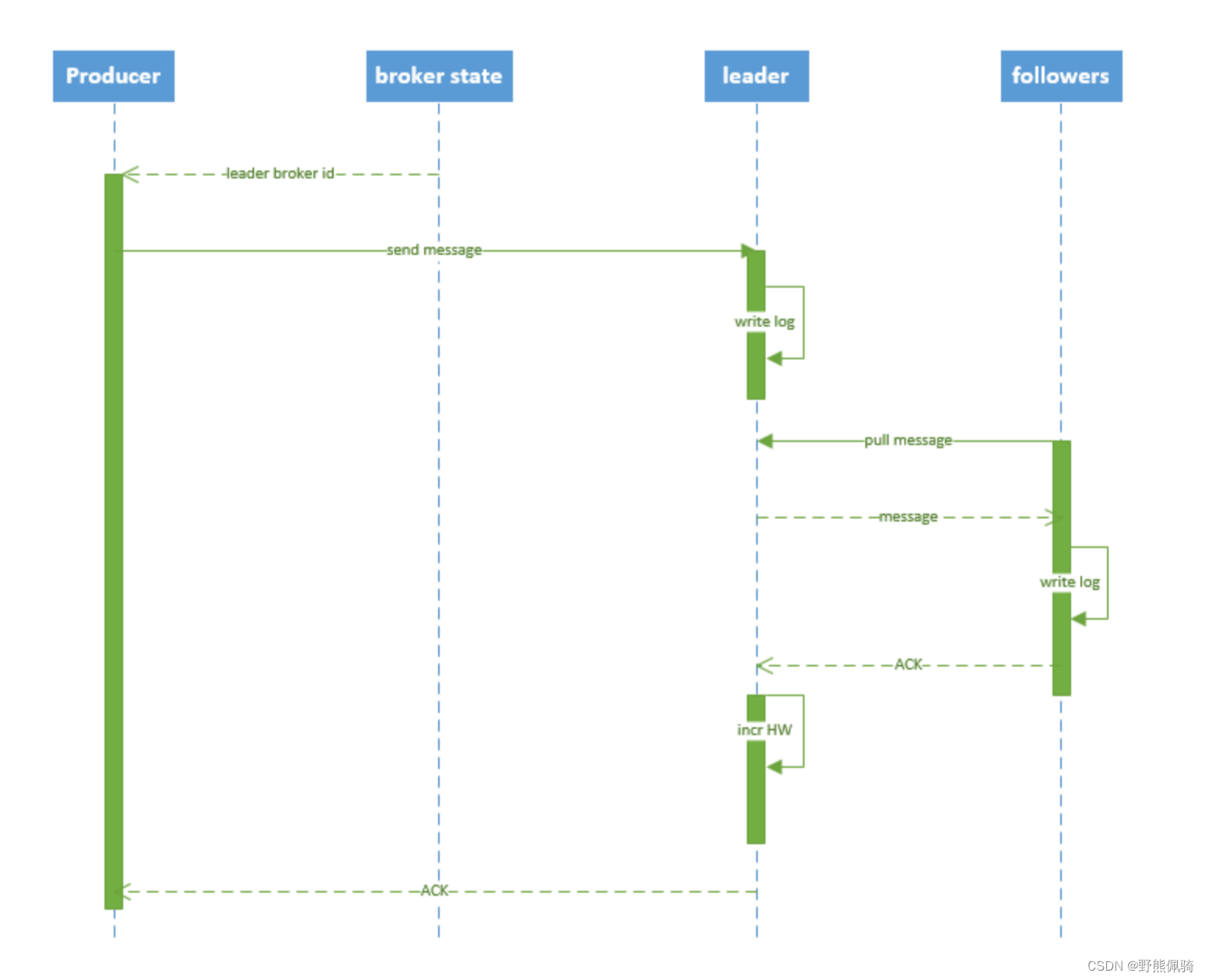
流程说明:
- producer 先从 zookeeper 的 "/brokers/.../state" 节点找到该 partition 的 leader
- producer 将消息发送给该 leader
- leader 将消息写入本地 log
- followers 从 leader pull 消息,写入本地 log 后 leader 发送 ACK
- leader 收到所有 ISR 中的 replica 的 ACK 后,增加 HW(high watermark,最后 commit 的 offset) 并向 producer 发送 ACK
(2)、broker保存消息
1)存储方式
物理上把 topic 分成一个或多个 patition(对应 server.properties 中的 num.partitions=3 配置),每个 patition 物理上对应一个文件夹(该文件夹存储该 patition 的所有消息和索引文件),如下:
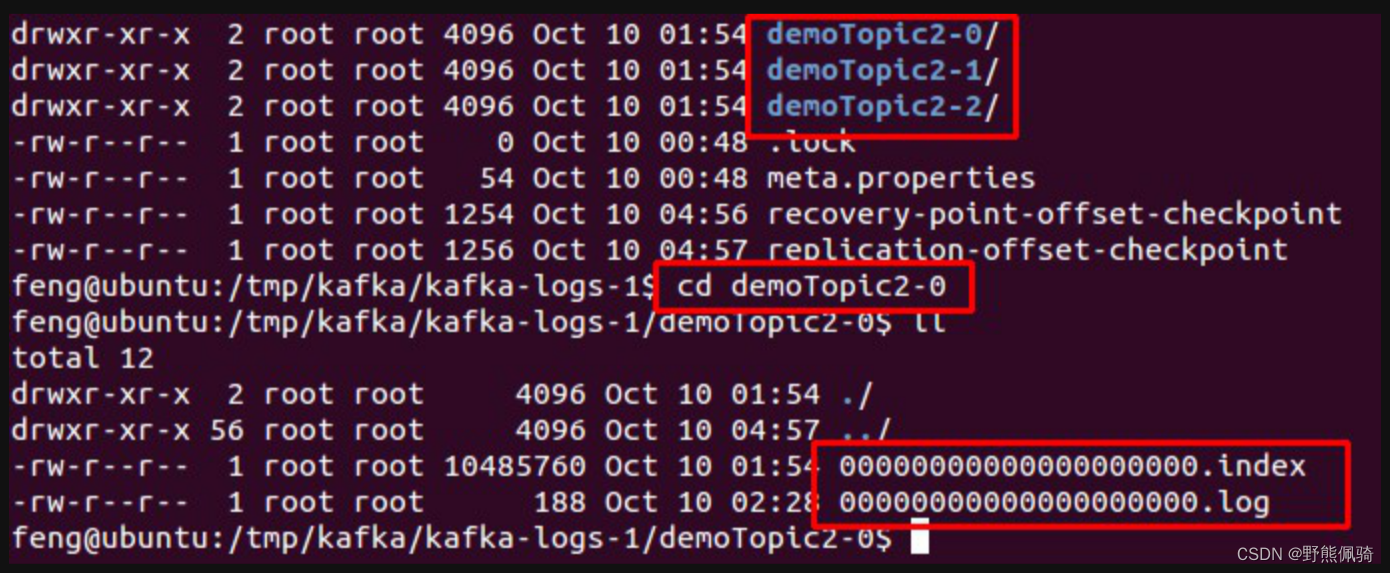
2)存储策略
无论消息是否被消费,kafka 都会保留所有消息。有两种策略可以删除旧数据:
- 基于时间:log.retention.hours=168
- 基于大小:log.retention.bytes=1073741824
(3)、Topic的创建和删除
1)创建topic
创建 topic 的序列图如下所示:
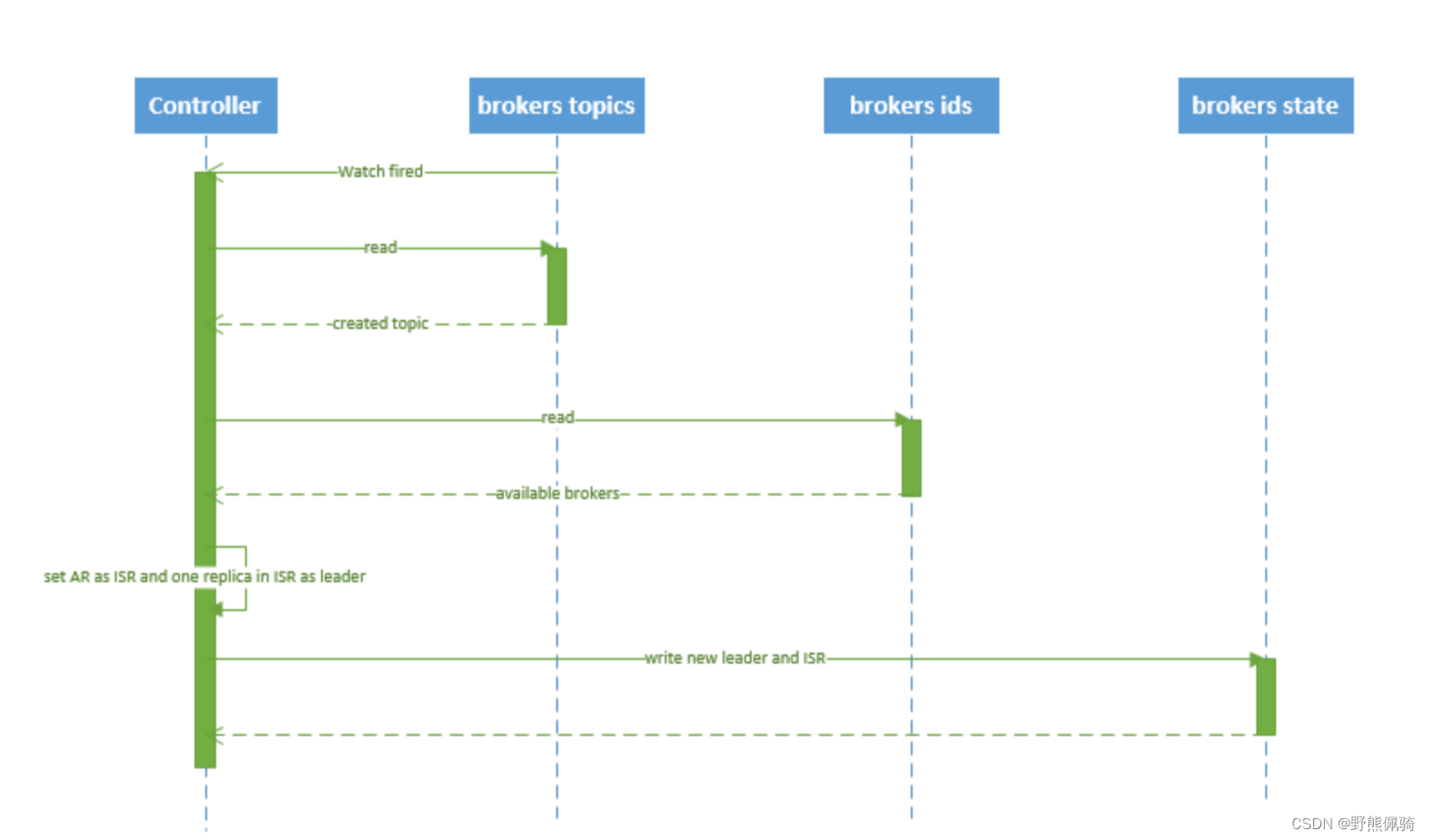
流程说明:
- controller 在 ZooKeeper 的 /brokers/topics 节点上注册 watcher,当 topic 被创建,则 controller 会通过 watch 得到该 topic 的 partition/replica 分配。
- controller从 /brokers/ids 读取当前所有可用的 broker 列表,对于 set_p 中的每一个 partition:
a.从分配给该 partition 的所有 replica(称为AR)中任选一个可用的 broker 作为新的 leader,并将AR设置为新的 ISR
b.将新的 leader 和 ISR 写入 /brokers/topics/[topic]/partitions/[partition]/state
- controller 通过 RPC 向相关的 broker 发送 LeaderAndISRRequest
2)删除topic
删除 topic 的序列图如下所示:
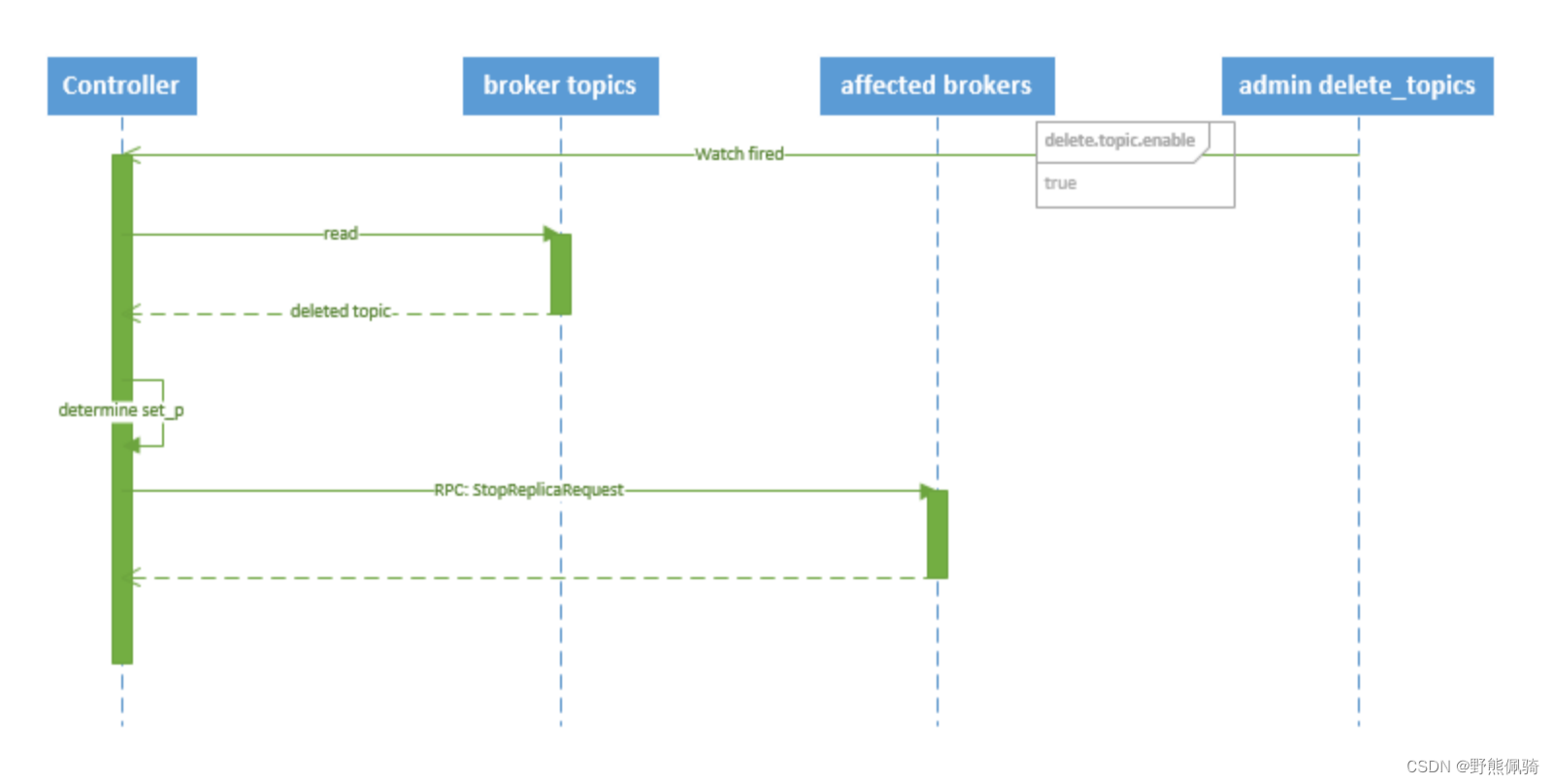
流程说明:
- controller 在 zooKeeper 的 /brokers/topics 节点上注册 watcher,当 topic 被删除,则 controller 会通过 watch 得到该 topic 的 partition/replica 分配。
- 若 delete.topic.enable=false,结束;否则 controller 注册在 /admin/delete_topics 上的 watch 被 fire,controller 通过回调向对应的 broker 发送 StopReplicaRequest。
(4)、broker failover
kafka broker failover 序列图如下所示:
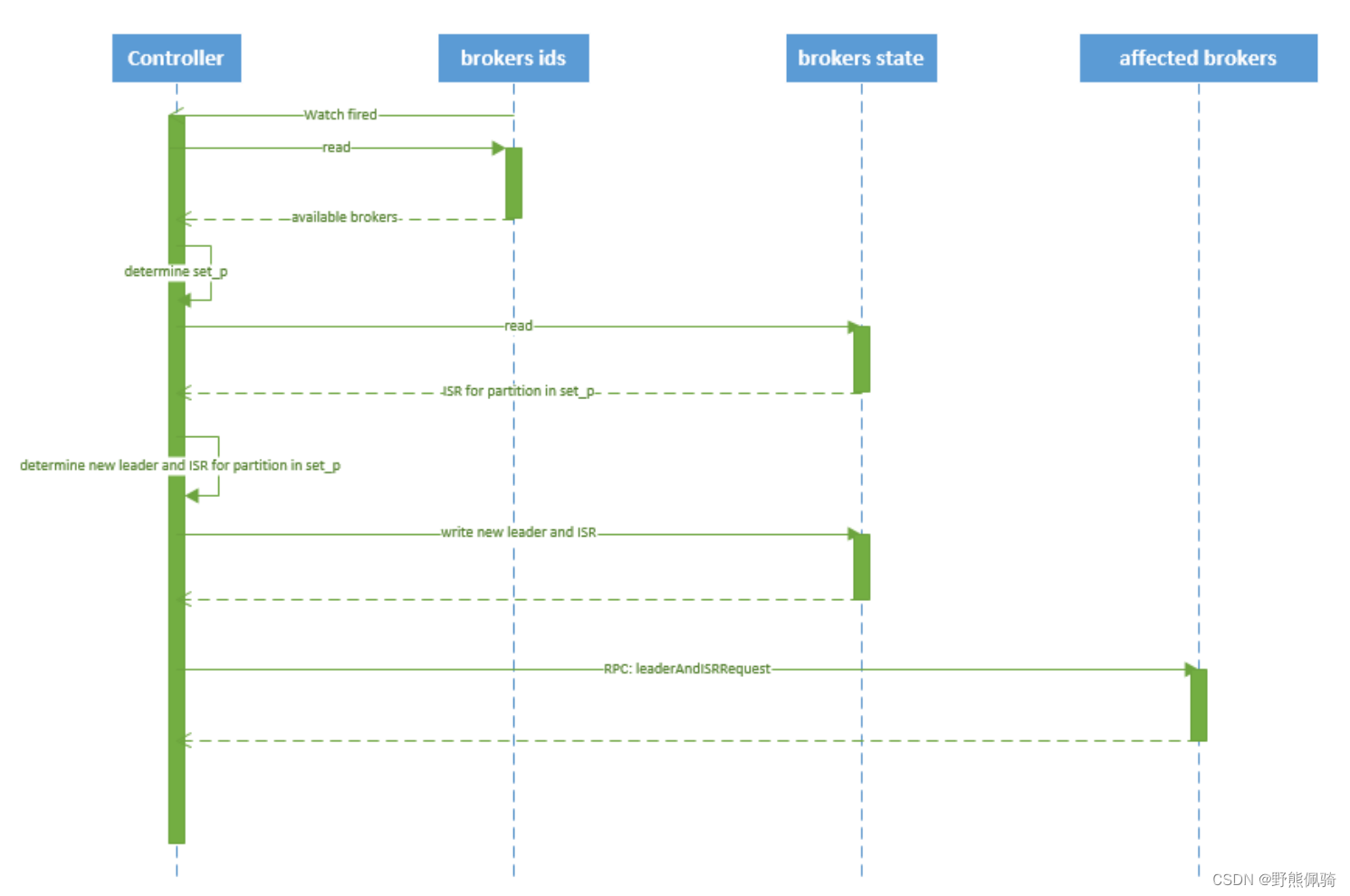
流程说明:
- controller 在 zookeeper 的 /brokers/ids/[brokerId] 节点注册 Watcher,当 broker 宕机时 zookeeper 会 fire watch
- controller 从 /brokers/ids 节点读取可用broker
- controller决定set_p,该集合包含宕机 broker 上的所有 partition
- 对 set_p 中的每一个 partition
a、从/brokers/topics/[topic]/partitions/[partition]/state 节点读取 ISR决定新 leader
b、将新 leader、ISR、controller_epoch 和 leader_epoch 等信息写入 state 节点
- 通过 RPC 向相关 broker 发送 leaderAndISRRequest 命令
(5)、controller failover
当 controller 宕机时会触发 controller failover。每个 broker 都会在 zookeeper 的 "/controller" 节点注册 watcher,当 controller 宕机时 zookeeper 中的临时节点消失,所有存活的 broker 收到 fire 的通知,每个 broker 都尝试创建新的 controller path,只有一个竞选成功并当选为 controller。
当新的 controller 当选时,会触发 KafkaController.onControllerFailover 方法,在该方法中完成如下操作:
- 读取并增加 Controller Epoch。
- 在 reassignedPartitions Patch(/admin/reassign_partitions) 上注册 watcher。
- 在 preferredReplicaElection Path(/admin/preferred_replica_election) 上注册 watcher。
- 通过 partitionStateMachine 在 broker Topics Patch(/brokers/topics) 上注册 watcher。
- 若 delete.topic.enable=true(默认值是 false),则 partitionStateMachine 在 Delete Topic Patch(/admin/delete_topics) 上注册 watcher。
- 通过 replicaStateMachine在 Broker Ids Patch(/brokers/ids)上注册Watch。
- 初始化 ControllerContext 对象,设置当前所有 topic,“活”着的 broker 列表,所有 partition 的 leader 及 ISR等。
- 启动 replicaStateMachine 和 partitionStateMachine。
- 将 brokerState 状态设置为 RunningAsController。
- 将每个 partition 的 Leadership 信息发送给所有“活”着的 broker。
- 若 auto.leader.rebalance.enable=true(默认值是true),则启动 partition-rebalance 线程。
- 若 delete.topic.enable=true 且Delete Topic Patch(/admin/delete_topics)中有值,则删除相应的Topic。
(二)、KAFKA搭建集群模式
1、配置详解
(1)、配置文件重点解释
- 服务主配置文件:config/server.properties
主要内容如下:
# 当前机器在集群中的唯一标识,和zookeeper的myid性质一样
broker.id=1
# 套接字服务器监听的地址。如果没有配置,主机名将等于的值
listeners=PLAINTEXT://192.168.1.101:9092
# 当前kafka对外提供服务的端口默认是9092
port=9092
# 这个是borker进行网络处理的线程数
num.network.threads=3
# 这个是borker进行I/O处理的线程数
num.io.threads=8
# 发送缓冲区buffer大小,数据不是一下子就发送的,先回存储到缓冲区了到达一定的大小后在发送,能提高性能
socket.send.buffer.bytes=102400
# kafka接收缓冲区大小,当数据到达一定大小后在序列化到磁盘
socket.receive.buffer.bytes=102400
# 这个参数是向kafka请求消息或者向kafka发送消息的请请求的最大数,这个值不能超过java的堆栈大小
socket.request.max.bytes=104857600
# 消息存放的目录,这个目录可以配置为“,”逗号分割的表达式,上面的num.io.threads要大于这个目录的个数这个目录,如果配置多个目录,新创建的topic他把消息持久化的地方是,当前以逗号分割的目录中,那个分区数最少就放那一个
log.dirs=/opt/kafka/log/kafka-logs
# 默认的分区数,一个topic默认1个分区数
num.partitions=1
# 每个数据目录用来日志恢复的线程数目
num.recovery.threads.per.data.dir=1
# 默认消息的最大持久化时间,168小时,7天
log.retention.hours=168
# 这个参数是:因为kafka的消息是以追加的形式落地到文件,当超过这个值的时候,kafka会新起一个文件
log.segment.bytes=1073741824
# 每隔300000毫秒去检查上面配置的log失效时间
log.retention.check.interval.ms=300000
# 是否启用log压缩,一般不用启用,启用的话可以提高性能
log.cleaner.enable=false
# 设置zookeeper的连接端口
zookeeper.connect=192.168.1.101:2181,192.168.1.102:2181,192.168.1.103:2181
# 设置zookeeper的连接超时时间
zookeeper.connection.timeout.ms=6000
- 生产者配置文件:config/producer.properties
主要内容如下:
末行加入:
metadata.broker.list=192.168.110.131:2181,192.168.110.132:2181,192.168.110.133:2181
- 生产者配置文件:config/consumer.properties
主要内容如下:
末行加入:
metadata.broker.list=192.168.110.131:2181,192.168.110.132:2181,192.168.110.133:2181
2、集群模式
(1)、环境准备
系统版本:CentOS Linux release 7.7.1908 (Core)
必要条件:安装JDK、先搭建Zookeeper集群环境(此处集群环境为192.168.31.131:2181,192.168.31.132:2181,192.168.31.133:2181)
规划:
kafka01 192.168.31.131
kafka02 192.168.31.132
kafka03 192.168.31.133
(2)、集群搭建部署过程
每个服务节点都按照以下步骤进行按照,不同节点的配置根据实际修改。
步骤一:下载kafka
[root@localhost zookeeper-3.5.10]# cd /data/tmp/
[root@localhost tmp]# wget --no-check-certificate 'https://dlcdn.apache.org/kafka/3.2.0/kafka_2.12-3.2.0.tgz' /data/tmp
根据官网实际提供的版本进行下载
步骤二:将kafka压缩包复制到/data/kafka路径下,并解压
[root@localhost tmp]# cp kafka2.12-3.2.0.tgz /data/kafka/
[root@localhost tmp]# cd /data/kafka/
[root@localhost kafka]# tar -xvf kafka2.12-3.2.0.tgz
步骤三:修改配置文件
[root@localhost kafka]# cd /data/kafka/kafka_2.12-3.2.0/config/
[root@localhost config]# vim server.properties
修改的配置项如下:
#默认是0,这里定义:kafka01:1, kafka02:2, kafka03:3,根据实际修改
broker.id=1
#值为true时,删除topic时会立即被删除
delete.topic.enable=true
#本机监听端口,根据实际修改
listeners=PLAINTEXT://192.168.31.131:9092
#日志路径
log.dirs=/data/logs/kafka-logs
#zookeeper集群环境
zookeeper.connect=192.168.31.131:2181,192.168.31.132:2181,192.168.31.133:2181
步骤四:分别启动3个服务节点
- kafka01 192.168.31.131节点
[root@kafka01 config]# cd /data/kafka/kafka_2.12-3.2.0/bin/
[root@kafka01 bin]# ./kafka-server-start.sh -daemon ../config/server.properties
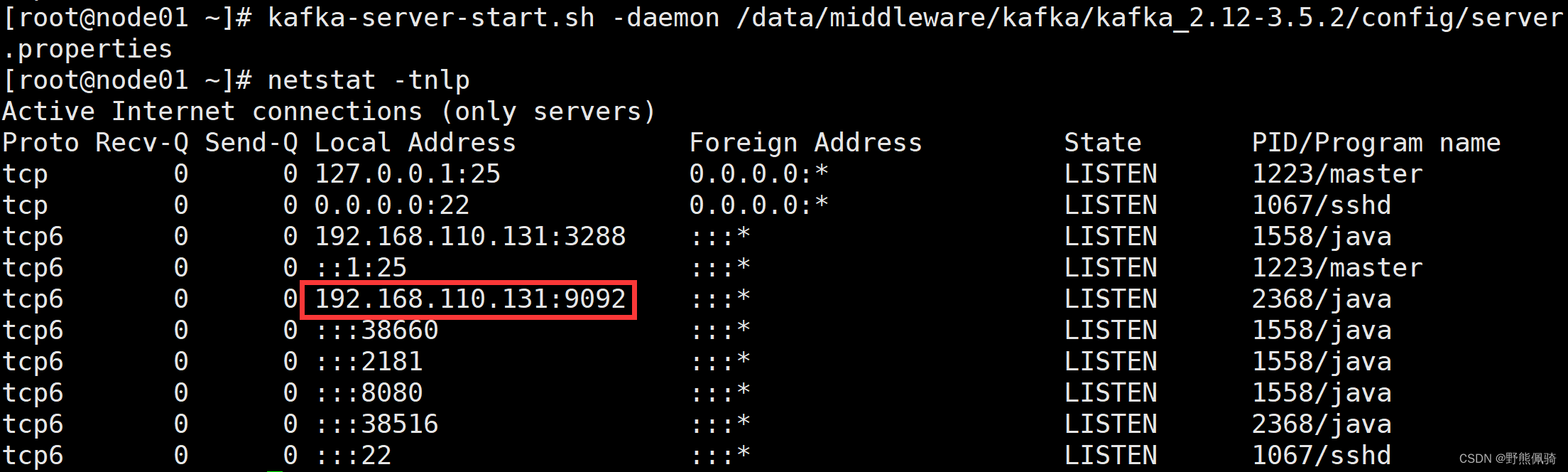
[root@kafka01 bin]# netstat -tnlp
- kafka02 192.168.31.132节点
[root@kafka02 bin]# ./kafka-server-start.sh -daemon ../config/server.properties
[root@kafka02 bin]# netstat -tnlp
- kafka03 192.168.31.133节点
[root@kafka03 bin]# ./kafka-server-start.sh -daemon ../config/server.properties
[root@kafka03 bin]# netstat -tnlp
步骤五:查看是否连接上zookeeper
[root@kafka03 bin]# cd /data/Zookeeper/zookeeper-3.5.10/bin
[root@kafka03 bin]# ./zkCli.sh -server 192.168.31.133:2181
Connecting to 192.168.31.133:2181
[zk: 192.168.31.133:2181(CONNECTED) 0] ls /
[admin, brokers, cluster, config, consumers, controller, controllerepoch, feature, isrchangenotification, latestproduceridblock, logdirevent_notification, zookeeper]
[zk: 192.168.31.133:2181(CONNECTED) 1] ls /brokers
[ids, seqid, topics]
[zk: 192.168.31.133:2181(CONNECTED) 2] ls /brokers/ids
[1, 2, 3]
[zk: 192.168.31.133:2181(CONNECTED) 3] ls /brokers/topic

(3)、HA相关ZooKeeper结构
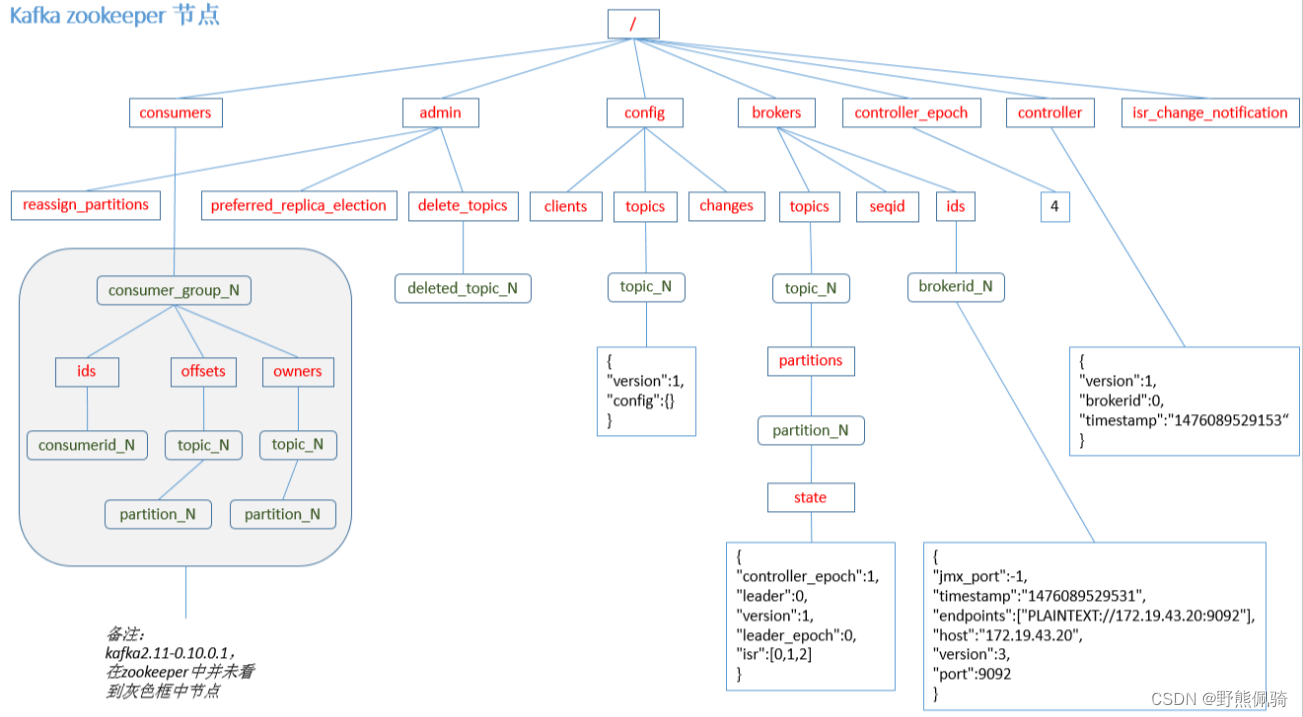
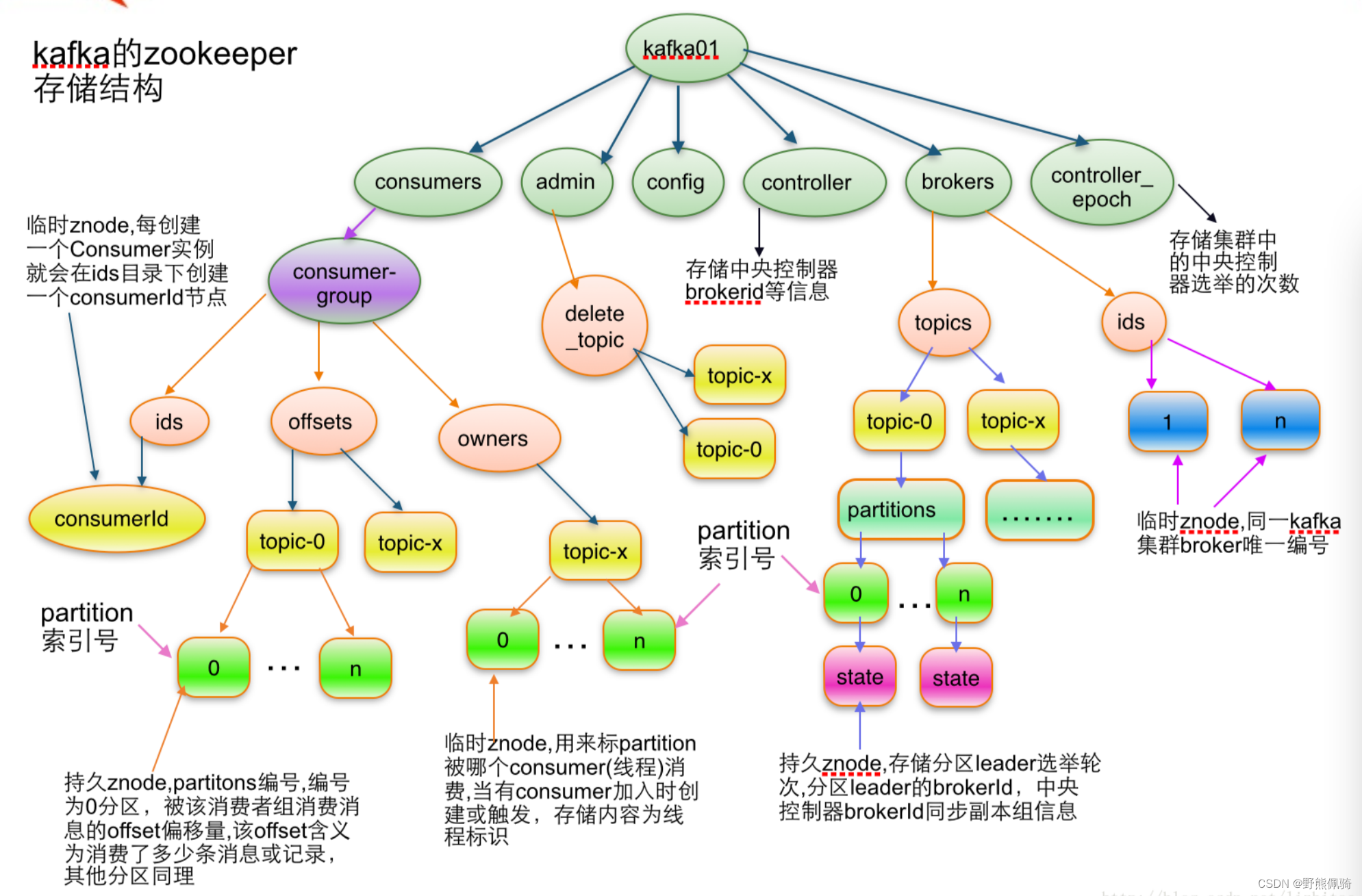
1)admin
- 该目录下znode只有在有相关操作时才会存在,操作结束时会将其删除
- /admin/reassign_partitions用于将一些Partition分配到不同的broker集合上。对于每个待重新分配的Partition,Kafka会在该znode上存储其所有的Replica和相应的Broker id。该znode由管理进程创建并且一旦重新分配成功它将会被自动移除。
2)broker
- 即/brokers/ids/[brokerId])存储“活着”的broker信息。
- topic注册信息(/brokers/topics/[topic]),存储该topic的所有partition的所有replica所在的broker id,第一个replica即为preferred replica,对一个给定的partition,它在同一个broker上最多只有一个replica,因此broker id可作为replica id。
3)controller
- /controller -> int (broker id of the controller)存储当前controller的信息
- /controller_epoch -> int (epoch)直接以整数形式存储controller epoch,而非像其它znode一样以JSON字符串形式存储。
(三)、常用命令
1、服务管理命令
(1)、连接zookeeper客户端
[root@kafka03 bin]# ./zkCli.sh -server 192.168.31.133:2181
(2)、启动kafka
启动Kafka服务器并加载指定的配置文件
[root@node01 config]# kafka-server-start.sh -daemon /data/middleware/kafka/kafka_2.12-3.5.2/config/server.properties
2、数据操作命令
- kafka 2.2+以下版本,执行命令时需要依赖参数 --zookeeper 节点IP:2181或者--zookeeper-server 节点IP:2181
- kafka 2.2+以上版本,执行命令时需要依赖参数--bootstrap-server 节点IP:9092替换
--zookeeper 节点IP:2181或者--zookeeper-server 节点IP:2181
如果使用错误,会出现报错Exception in thread "main" joptsimple.UnrecognizedOptionException: zookeeper is not a recognized option
以下命令操作均以kafka_2.12-3.5.2版本为基础。
(1)、创建topic命令
1)创建topic
参数说明:
--topic:创建的主题名称
--bootstrap-server:本机的kafka服务
--partitions:主题的分片数。一般来说,kafka集群有N个broker就配置N个分区
--replication-factor:每个分片的副本数
- 创建myTopic,分片数为3,每个分片的副本数为1
[root@node01 kafka-logs]# kafka-topics.sh --create --topic myTopic --bootstrap-server 192.168.110.131:9092 --partitions 3 --replication-factor 1

- 在kafka集群节点查看myTopic是否创建成功
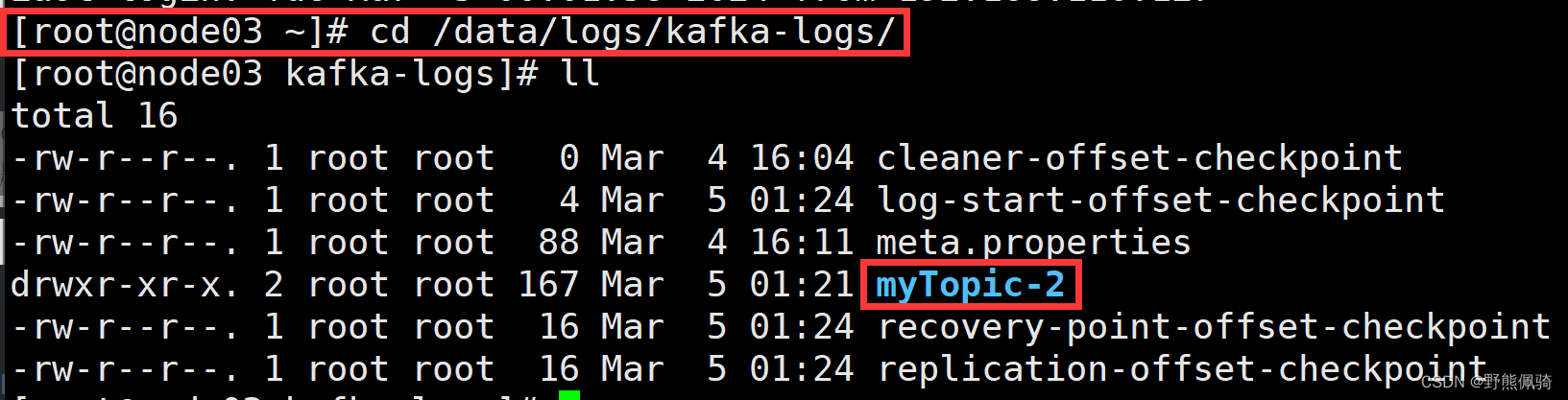
在kafka日志路径下查看是否已经生成myTopic相关的路径,根据分片数,会在每个节点生成一个分片路径。此次kafka集群有3个节点,myTopic配置了3个分片,所以在kafka每个集群节点都会创建一个myTopic的分区文件夹,如下所示:
node01
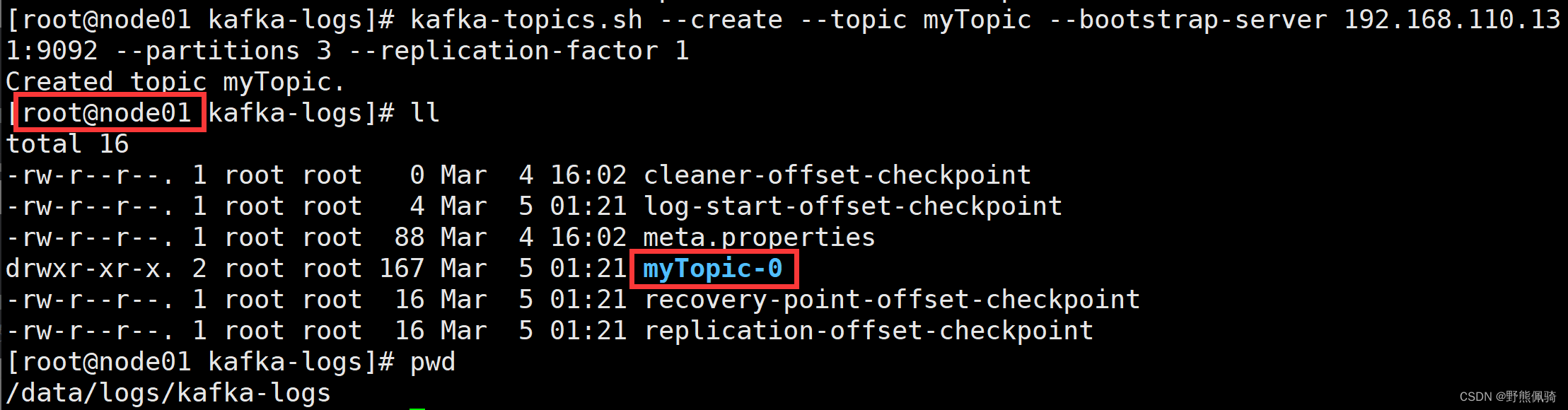
node02
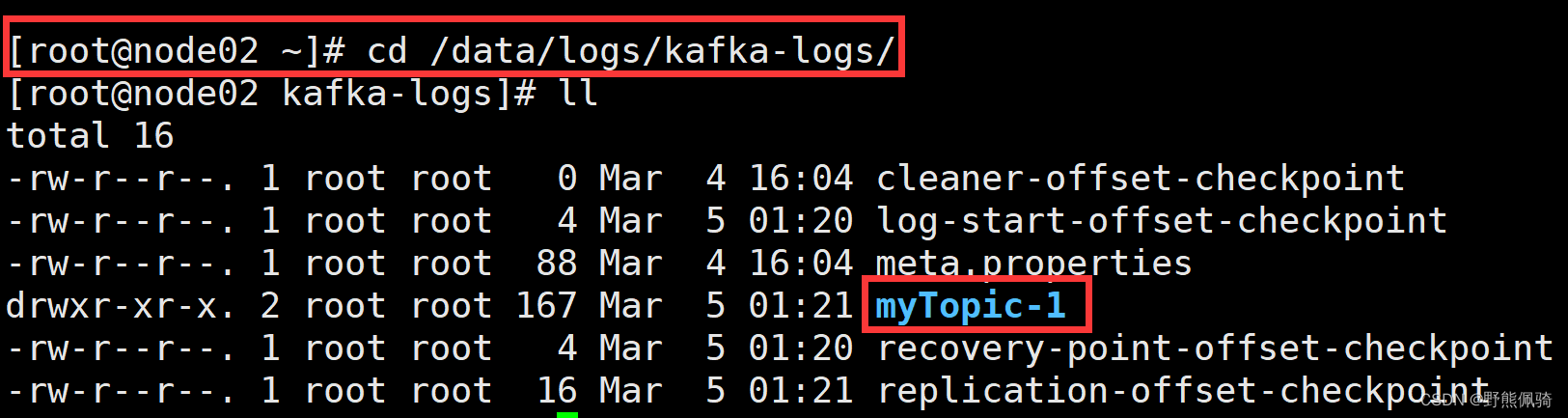
node03
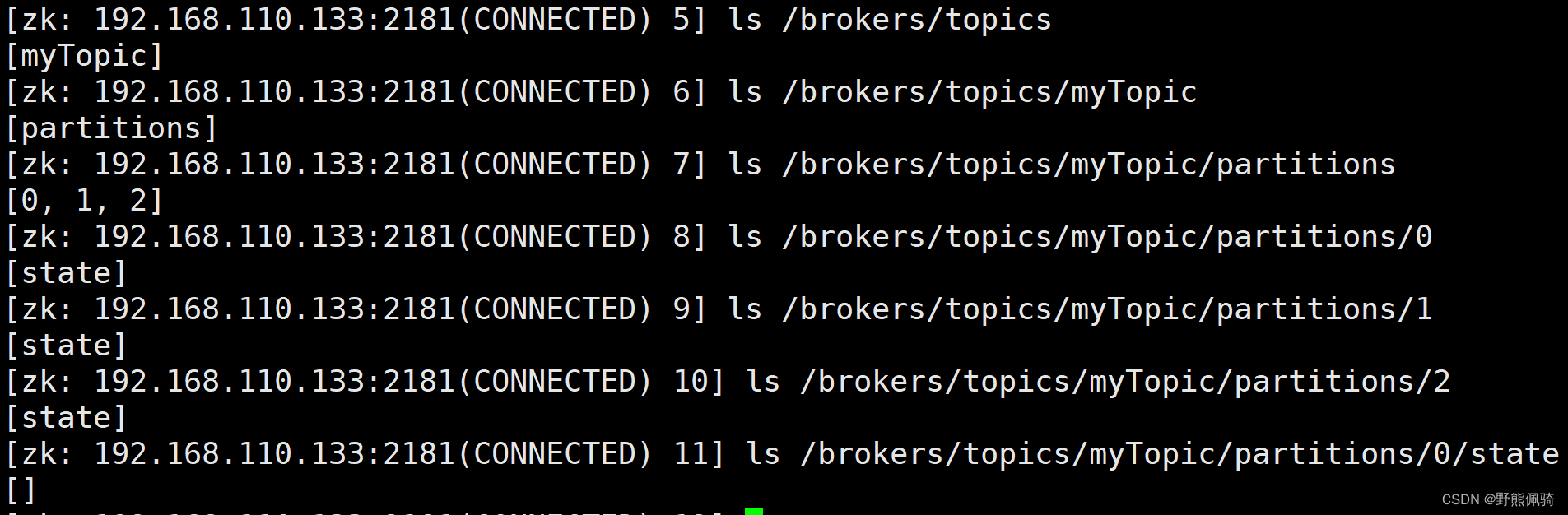
- 在zookeeper中查看myTopic是否创建成功
[zk: 192.168.110.133:2181(CONNECTED) 5] ls /brokers/topics
[myTopic]
[zk: 192.168.110.133:2181(CONNECTED) 6] ls /brokers/topics/myTopic
[partitions]
[zk: 192.168.110.133:2181(CONNECTED) 7] ls /brokers/topics/myTopic/partitions
[0, 1, 2]
2)查看topic详细信息
该命令将显示名为myTopic的主题的分区信息,包括分区ID,副本分配和ISR(已同步副本)。
[root@node01 kafka-logs]# kafka-topics.sh --bootstrap-server 192.168.110.131:9092 --topic myTopic --describe

(2)、查询topic列表
- 在kafka查询
[root@node01 myTopic-0]# kafka-topics.sh --list --bootstrap-server 192.168.110.131:9092

- 在zookeeper查询
[zk: 192.168.110.133:2181(CONNECTED) 19] ls /brokers/topics

(3)、删除topic
删除名称为exampleTopic的主题
[root@node01 kafka-logs]# kafka-topics.sh --delete --topic exampleTopic --bootstrap-server 192.168.110.131:9092

删除操作后,会将每个节点的分片目录先更名为删除,然后再彻底删除目录
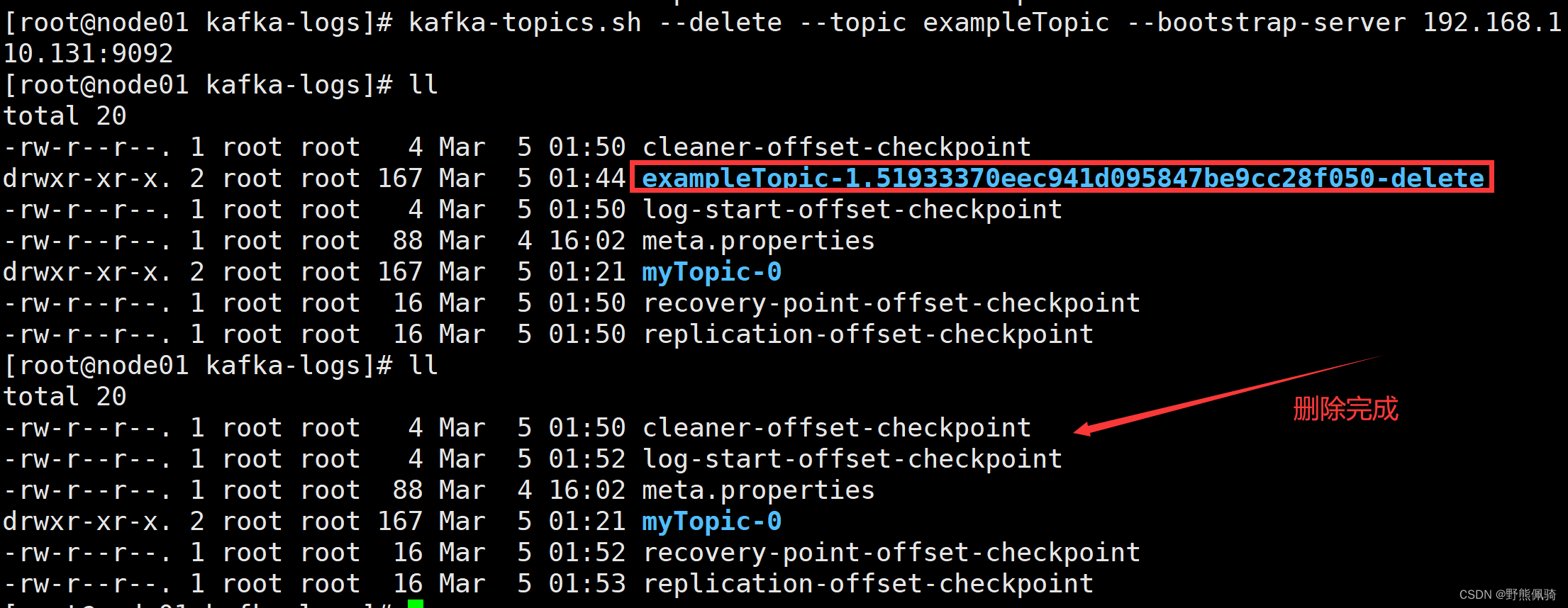
zookeeper中也会删除exampleTopic相关的内容
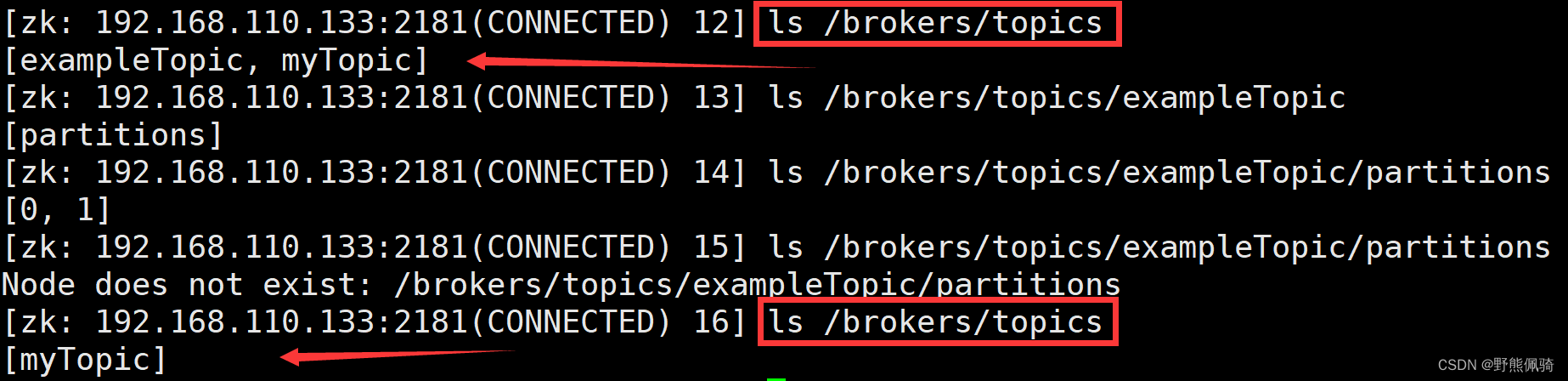
(4)、kafka生产者相关
1)启动名为myTopic的控制台生产者
[root@node01 kafka-logs]# kafka-console-producer.sh --broker-list 192.168.110.131:9092 --topic myTopic

或者
[root@node02 myTopic-1]# kafka-console-producer.sh --bootstrap-server 192.168.110.131:9092 --topic myTopic

2)将消息发送到名为myTopic的主题中
[root@node01 kafka-logs]# kafka-console-producer.sh --broker-list 192.168.110.131:9092 --topic myTopic
>this is 1121 messages
>this is 1126 messages

(5)、kafka消费者相关
启动Kafka的控制台消费者,并从名为myTopic的主题的开头开始消费消息。
控制台生产者实时生产消息,控制台消费者实时消费消息
[root@node01 kafka-logs]# kafka-console-consumer.sh --bootstrap-server 192.168.110.131:9092 --topic myTopic --from-beginning

通过上述命令,也可从侧面看出myTopic中是否有数据。因为执行命令后,消费者会将生产者所有的消息再重新消费一次。
(6)、消费组相关
1)查看所有的消费组group
[root@node01 kafka-logs]# kafka-consumer-groups.sh --list --bootstrap-server 192.168.110.131:9092
2)查看指定的消费组消费情况
[root@node01 kafka-logs]# kafka-consumer-groups.sh --bootstrap-server 192.168.110.131:9092 --group console-consumer-34196 --describe
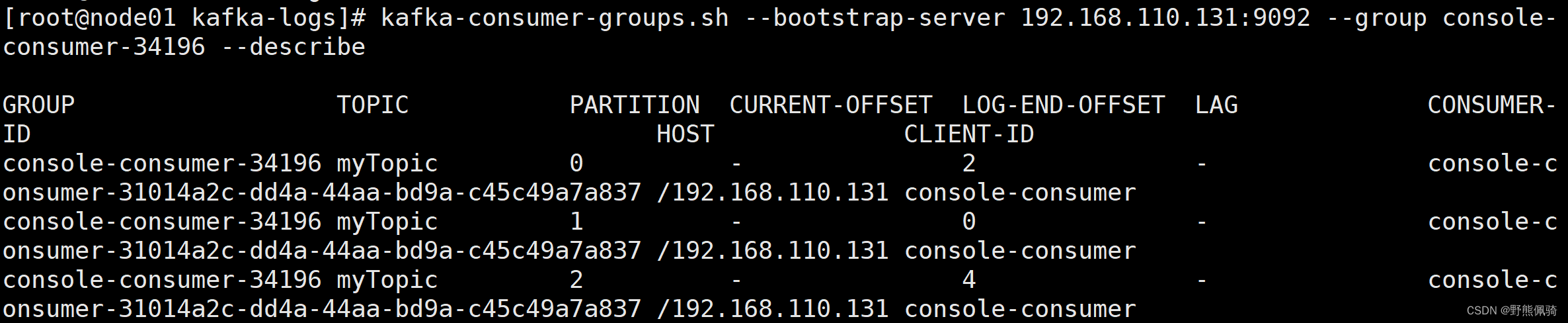
这将显示名为console-consumer-34196的消费者组的偏移量详细信息,包括消费者组内每个消费者的偏移量和分区信息。
字段名称详解:
TOPIC:topic名称
PARTITION:分区id
CURRENT-OFFSET:当前已消费的消息条数
LOG-END-OFFSET:消息总条数
LAG:未消费的消息条数
CONSUMER-ID:消费者id
HOST:主机IP
CLIENT-ID:消费者客户端ID
3)指定(创建)消费者组
该命令将启动一个命令行控制台消费者消费主题myTopic,并将其添加到名为myGroup的消费者组中。同一个消费者组中的消费者将共享消息的消费。
[root@node01 myTopic-0]# kafka-console-consumer.sh --bootstrap-server 192.168.110.131:9092 --topic myTopic --group myGroup
- 消费组

- 生产者

- 消费者


技术共进,成长同行——讯飞AI开发者社区
更多推荐


 36
36 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)