
【中大 & TAMU & 哈工深 & 浙理工|ICML 2025】FedCEO:打破隐私与性能的权衡瓶颈,提出联邦学习新范式

我们很高兴地宣布,由中山大学、德州农工大学(TAMU) 、哈尔滨工业大学 (深圳) 以及浙江理工大学合作完成的论文《Clients Collaborate: Flexible Differentially Private Federated Learning with Guaranteed Improvement of Utility-Privacy Trade-off》已被机器学习顶级国际会议ICML 2025 (CCF A) 接收。
论文链接:https://arxiv.org/abs/2402.07002
PPT展示:https://icml.cc/virtual/2025/poster/46080
代码链接:https://github.com/6lyc/FedCEO_Collaborate-with-Each-Other
代码简洁,一键运行,欢迎star以及fork。
研究背景
联邦学习(Federated Learning, FL)作为一种隐私保护的分布式机器学习范式,允许客户端在不共享本地数据的情况下协同训练全局模型。然而,传统的联邦学习系统仍然面临隐私泄露风险,例如通过梯度反演攻击(如DLG)推断用户原始数据。
为增强隐私保护,差分隐私(Differential Privacy, DP)被广泛引入联邦学习框架(即DPFL)。然而,DP机制引入的噪声会破坏模型语义完整性,尤其是在多轮通信中噪声累积导致模型性能显著下降。如何在保证隐私的同时提升模型效用,成为当前DPFL研究的核心挑战。
方法简介:FedCEO
本文提出了一种名为 FedCEO (letting clients “Collaborate with Each Other”) 的新框架,其核心思想是让客户端在语义层面进行动态的协同互补,以缓解DP噪声对模型效用的负面影响。
关键创新点:
-
张量低秩近端优化:
在服务器端将客户端上传的噪声参数堆叠成高阶张量,通过截断张量奇异值分解(T-tSVD)动态地截断高频成分,恢复语义完整性。 -
自适应平滑机制:
根据不同的隐私预算 (ε) 和训练轮次 (E),动态调整截断阈值,实现全局语义空间的自适应平滑。 -
理论保障的效用-隐私权衡:
在理论上证明了得益于参数优化的低秩性,FedCEO在效用-隐私权衡上比现有SOTA方法提升O(√d),其中d为输入维度。
理论贡献
我们首次将用户级差分隐私与张量低秩优化相结合,提出了一套完整DPFL效用-隐私权衡的理论分析框架,包括:
- 效用上界:
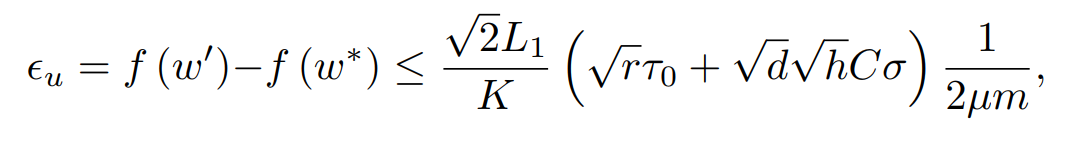
- 隐私预算:
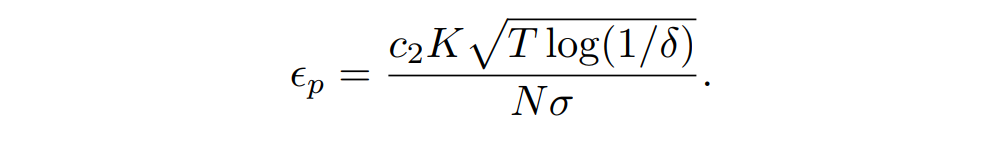
- 权衡关系:
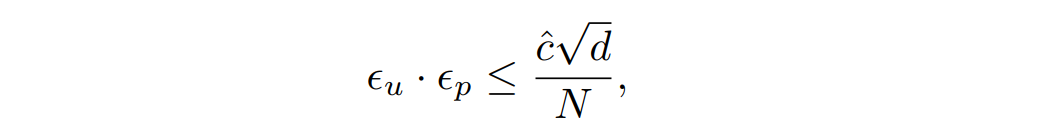
该结果显著优于现有方法(如J et al. 的O(d^{1.5}) 和CENTAUR的O(d))。
实验结果
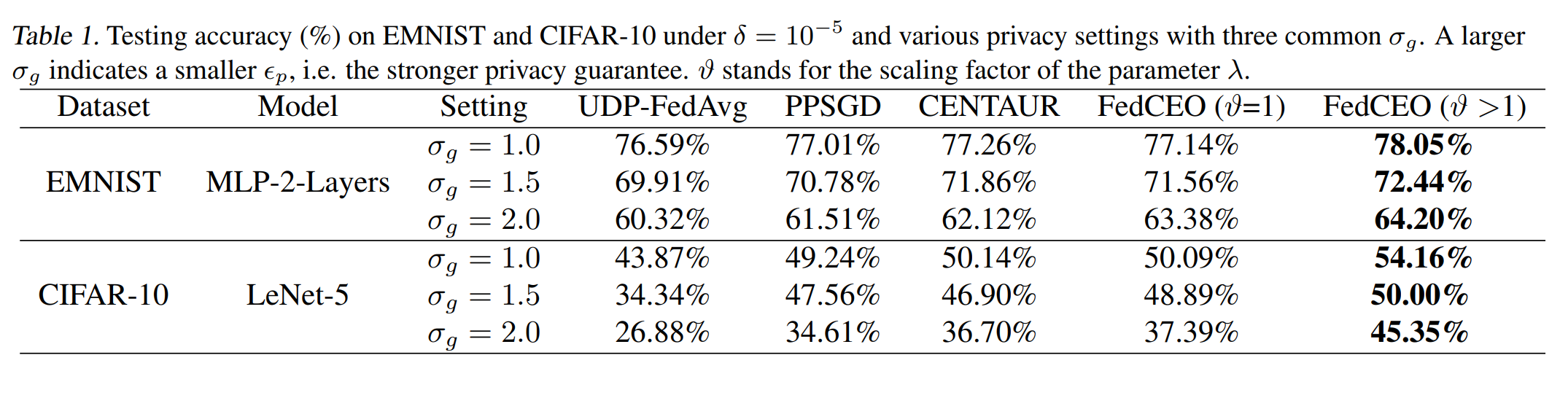
我们在多个标准数据集(如CIFAR-10、EMNIST等)和模型架构(MLP、LeNet、AlexNet等)上进行了广泛实验,结果表明:
-
效用提升:在相同隐私预算(添加噪声水平)下,FedCEO相比UDP-FedAvg、PPSGD、CENTAUR等方法在测试准确率上显著提升;
-
隐私保护:即使经过低秩处理,FedCEO仍能有效抵御梯度反演攻击(DLG),PSNR值显著降低;

-
效用-隐私权衡:
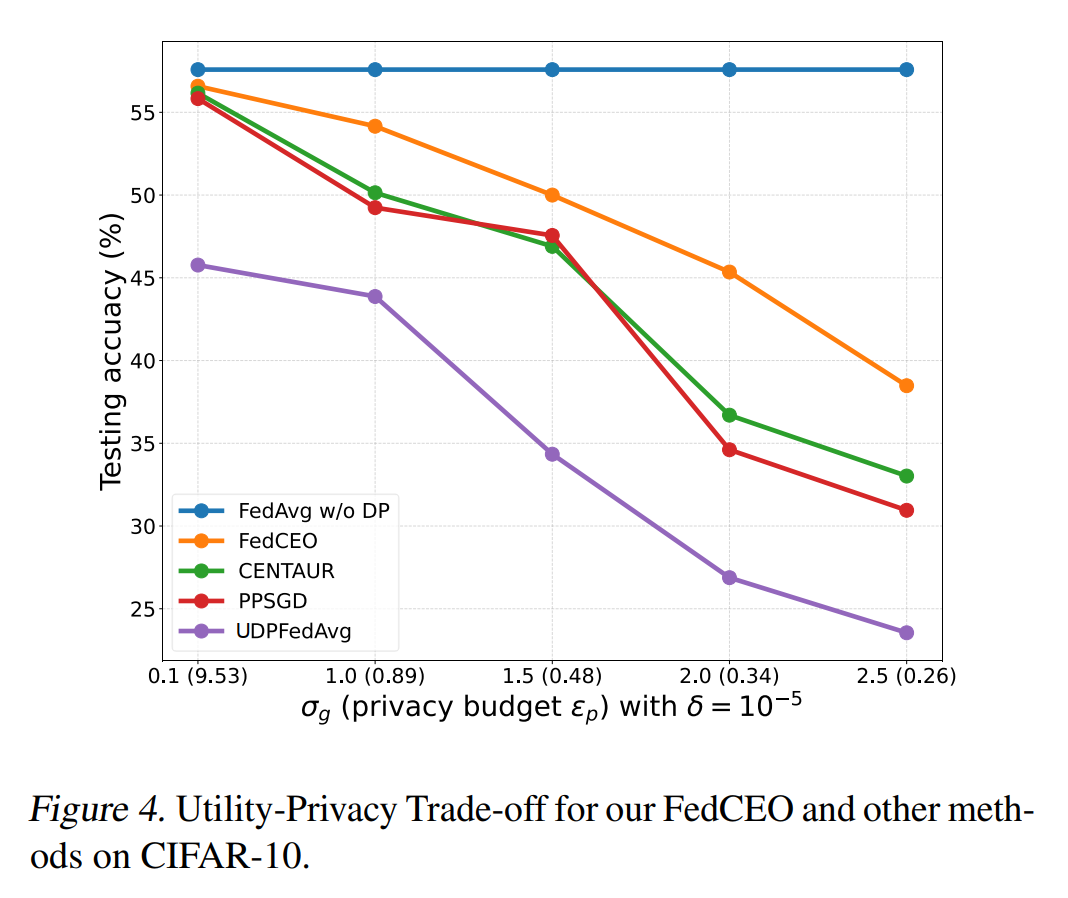
-
异质环境适用性:在非独立同分布(non-IID)数据设置下仍保持优越性能。
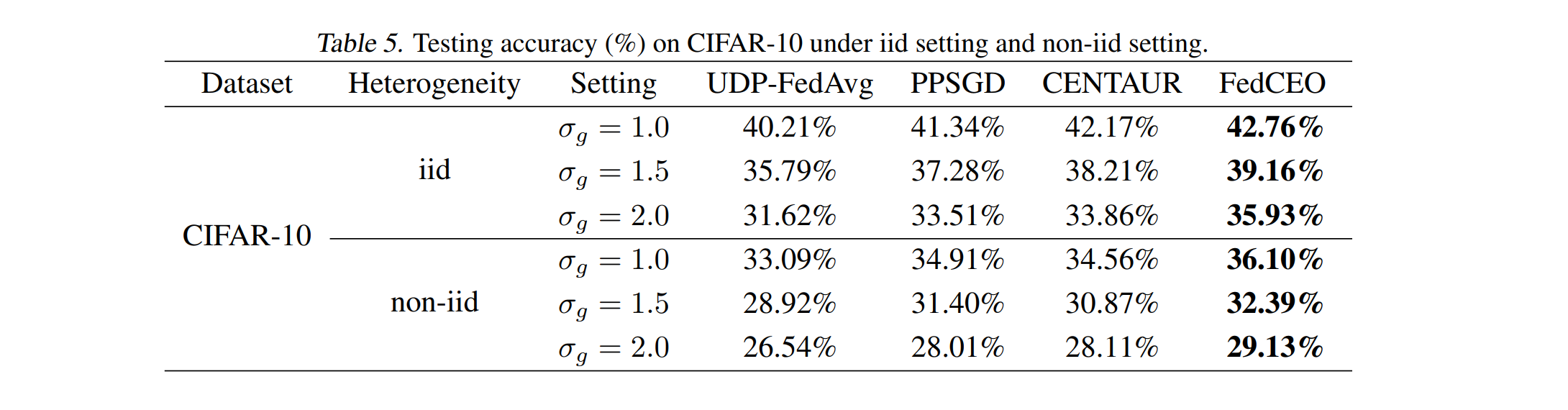
-
高效性:

更多实验参见论文:https://arxiv.org/abs/2402.07002
代码与资源
论文代码已开源,欢迎访问以下链接获取:
GitHub项目地址:https://github.com/6lyc/FedCEO_Collaborate-with-Each-Other
总结
FedCEO为差分隐私联邦学习提供了一种新颖的客户端协同优化范式,不仅在理论上实现了效用-隐私权衡的显著提升,也在多个实际场景中验证了其有效性与实用性。我们相信这项工作将为隐私保护机器学习的实际工业应用提供重要推动力。

技术共进,成长同行——讯飞AI开发者社区
更多推荐

 38
38 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)