
Gemini Robotics 1.5 谷歌通用人形机器人具身智能模型
谷歌推出两款新型机器人模型Gemini Robotics 1.5和Gemini Robotics-ER 1.5,推动物理代理时代发展。前者是最强视觉-语言-动作模型,能将视觉指令转化为机器人动作并展示思考过程;后者是顶尖视觉语言模型,擅长物理世界推理和多步骤规划。两者协同工作可完成复杂任务,如物品分类回收等。新模型具备跨实体学习能力,支持不同机器人间的技能迁移。谷歌强调AI安全开发,通过ASIMO
系列文章目录
目录
一、Gemini Robotics 1.5:为物理任务解锁智能体体验
前言

我们正在推动物理代理时代的到来——使机器人能够感知、规划、思考、使用工具并采取行动,从而更好地解决复杂的多步骤任务。
今年早些时候,我们通过Gemini机器人模型家族,在将Gemini的多模态理解能力引入物理世界方面取得了重大突破。
如今,我们正朝着推进智能通用型机器人的目标迈出新步伐。我们推出两款模型,通过先进思维能力开启智能体体验:
- Gemini Robotics 1.5——我们最强大的视觉-语言-动作(VLA)模型能将视觉信息和指令转化为机器人执行任务的运动指令。该模型在行动前进行思考并展示其过程,帮助机器人更透明地评估和完成复杂任务。它还能跨实体学习,加速技能掌握。
- Gemini Robotics-ER 1.5——我们最强大的视觉语言模型(VLM)能够对物理世界进行推理,原生调用数字工具,并制定详细的多步骤计划以完成任务。该模型现已在空间理解基准测试中达到顶尖水平。
这些进展将帮助开发者打造功能更强大、用途更广泛的机器人,使其能够主动理解环境,以通用方式完成复杂的多步骤任务。
从今天起,我们通过Google AI Studio中的Gemini API向开发者开放Gemini Robotics-ER 1.5版本。Gemini Robotics 1.5目前仅向部分合作伙伴提供。更多关于使用新一代物理代理进行开发的详情,请参阅开发者博客。
一、Gemini Robotics 1.5:为物理任务解锁智能体体验
大多数日常任务需要上下文信息和多步骤操作才能完成,这使得它们对当今机器人而言极具挑战性。
例如,当机器人被问及: 基于我的位置,能否将这些物品分类放入堆肥桶、回收桶和垃圾桶?”它需要在网上搜索当地回收指南,观察眼前物品,根据规则判断分类方式——最后执行所有步骤完成收纳。为此,我们设计了两个协同运作的智能体框架模型,助力机器人完成此类复杂多步骤任务。
我们的具身推理模型Gemini Robotics-ER 1.5如同高级大脑般协调机器人活动。该模型擅长在物理环境中进行规划与逻辑决策,具备尖端空间理解能力,能进行自然语言交互,评估任务成功率与进度,并可原生调用谷歌搜索等工具获取信息或使用任何第三方用户定义函数。
Gemini Robotics-ER 1.5随后为Gemini Robotics 1.5生成各步骤的自然语言指令,后者通过视觉与语言理解能力直接执行具体操作。该系统还能协助机器人思考行动策略以解决语义复杂任务,甚至能用自然语言阐释其思维过程——使决策过程更具透明度。
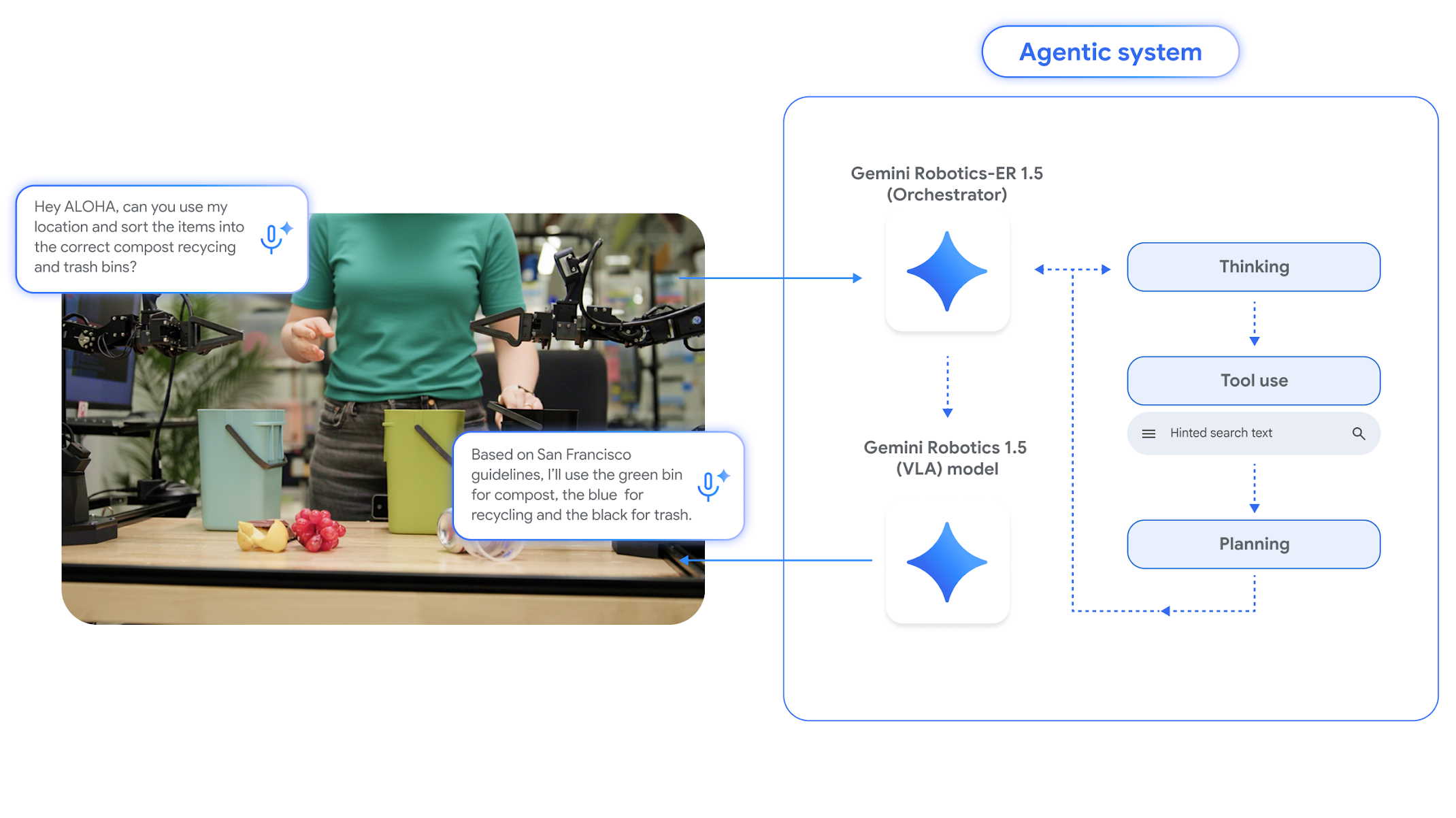
示意图展示了我们的具身推理模型Gemini Robotics-ER 1.5与视觉-语言-动作模型Gemini Robotics 1.5如何协同运作,在物理世界中执行复杂任务。
这两种模型均基于核心Gemini模型家族构建,并通过不同数据集进行微调以专精各自职能。二者结合后,显著提升了机器人在更长任务周期和多样化环境中的泛化能力。
二、理解其环境
Gemini Robotics-ER 1.5 是首个针对具身推理进行优化的思考模型。它在学术和内部基准测试中均达到顶尖水平,其设计灵感源自我们可信测试者计划中的真实世界应用场景。
我们通过15项学术基准测试评估了Gemini Robotics-ER 1.5的性能,包括具身推理问答(ERQA)和Point-Bench,衡量该模型在指物识别、图像问答及视频问答方面的表现。
详情请参阅我们的技术报告。
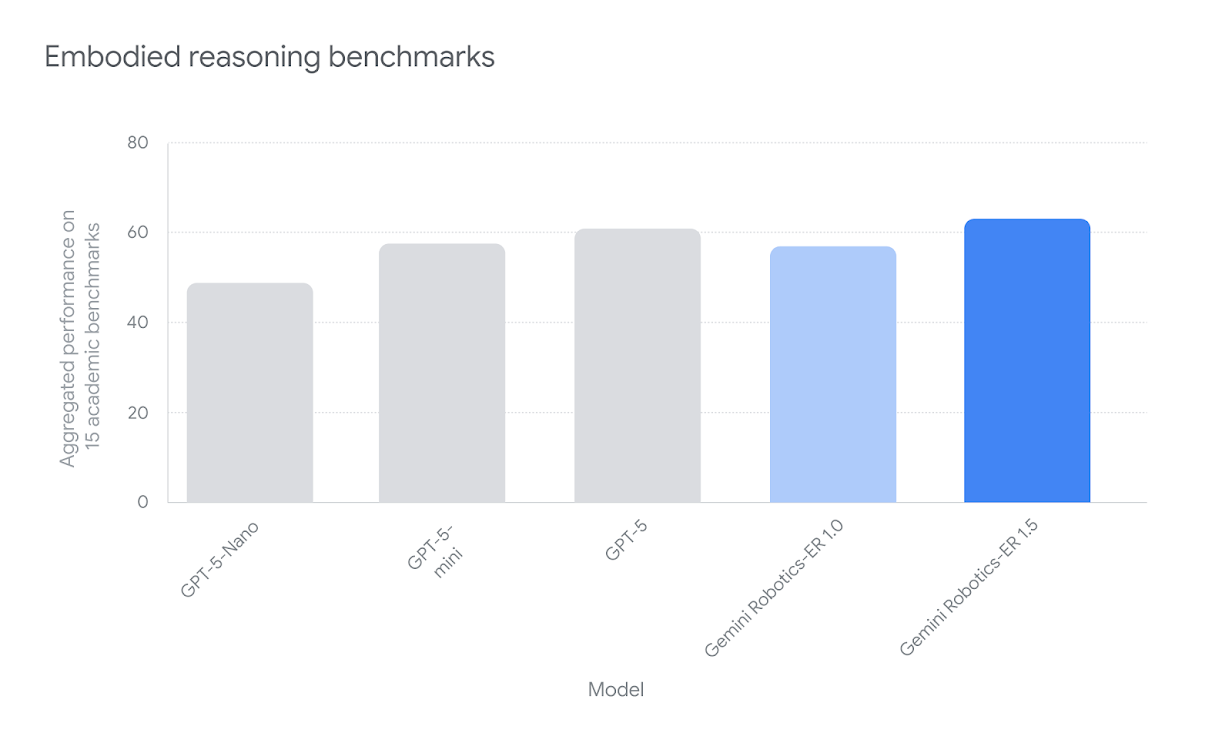
柱状图展示了Gemini Robotics-ER 1.5相较于同类模型的顶尖性能表现。本模型在15项学术化具身推理基准测试中取得最高综合性能,涵盖Point-Bench、RefSpatial、RoboSpatial-Pointing、Where2Place、BLINK、CV-Bench、ERQA、EmbSpatial、MindCube、RoboSpatial-VQA、SAT、Cosmos-Reason1、Min Video Pairs、OpenEQA及VSI-Bench等测试。

一组展示Gemini Robotics-ER 1.5部分能力的GIF拼贴图,包括物体检测与状态估计、分割掩膜、指向操作、轨迹预测、任务进度评估及成功检测。
三、先思考后行动
传统视觉-语言-动作模型通常将指令或语言计划直接转化为机器人动作。而Gemini Robotics 1.5不仅能执行指令,更能实现先思考后行动。这意味着它能生成自然语言的内部推理序列,从而完成需要多步骤操作或深度语义理解的任务。
例如在执行“按颜色分类我的衣物”任务时,下图视频中的机器人会进行多层次思考:首先理解“按颜色分类”意味着将白色衣物放入白色箱子,其他颜色放入黑色箱子;随后规划具体步骤(如拿起红色毛衣放入黑色箱子),并思考精细动作(如将毛衣移近以便更轻松拾取)。
在这个多层次的思考过程中,视觉-语言-动作模型能够将较长的任务分解为更简单的短任务段,使机器人能够成功执行。它还帮助模型实现泛化能力,从而解决新任务,并对环境变化具有更强的鲁棒性。
四、跨实体学习
机器人形态各异,尺寸不一,具有不同的感知能力和自由度,这使得从一个机器人学习到的动作难以转移到另一个机器人上。
Gemini Robotics 1.5展现出卓越的跨实体学习能力。它能将从某台机器人习得的动作迁移至另一台,无需针对新实体专门调整模型。这项突破显著加速了新行为的学习进程,助力机器人变得更智能、更实用。
例如,我们观察到:训练期间仅在ALOHA 2机器人上呈现的任务,同样能在Apptronik人形机器人Apollo和双臂Franka机器人上完美运行,反之亦然。
五、我们如何负责任地推进人工智能与机器人技术
在释放具身人工智能全部潜能的同时,我们正积极开发创新的安全与对齐方案,确保具有自主行为能力的人工智能机器人能够在以人为本的环境中负责任地部署。
我们的责任与安全委员会(RSC)及负责任开发与创新团队(ReDI)与机器人团队通力合作,确保这些模型的开发符合我们的人工智能原则。
Gemini Robotics 1.5通过高级语义推理实现整体安全策略:包括行动前预判安全风险、通过与现有Gemini安全策略对齐确保与人类的尊重性对话,并在必要时触发机器人内置的低级安全子系统(如避障系统)。
为指导Gemini机器人模型的安全开发,我们同步发布升级版ASIMOV基准测试——该综合数据集用于评估和提升语义安全性,具备更优的尾部覆盖率、改进的标注、新型安全问题类型及新增视频模态。
在ASIMOV基准的安全评估中,Gemini Robotics-ER 1.5展现出顶尖性能,其推理能力显著提升了语义安全理解水平,并增强了对物理安全约束的遵守能力。
了解更多安全研究详情,请查阅我们的技术报告或访问安全专题网站。
六、迈向解决物理世界通用人工智能的重要里程碑
Gemini Robotics 1.5标志着解决物理世界通用人工智能的重要里程碑。通过引入智能体能力,我们正超越仅能响应指令的模型,创建能够真正推理、规划、主动使用工具并实现泛化的系统。
这是构建智能灵巧机器人迈出的基础性步伐——它们将能智能应对物理世界的复杂性,最终成为更贴近生活的得力助手。
我们期待与更广泛的研究社群共同推进这项工作,并热切期盼机器人领域利用我们最新的Gemini Robotics-ER模型创造出更多成果。

技术共进,成长同行——讯飞AI开发者社区
更多推荐

 16
16 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)