
【论文阅读】具身人工智能:从大型语言模型到世界模型
本文全面综述了具身人工智能领域的现状,特别强调了整合多模态大语言模型(MLLM)和世界模型(WM)的协同潜力。它提出了一种联合MLLM-WM驱动的架构,以克服各自的局限性,并推进具有物理基础和语义智能的智能体。
论文链接:https://arxiv.org/pdf/2509.20021
本文全面综述了具身人工智能领域的现状,特别强调了整合多模态大语言模型(MLLM)和世界模型(WM)的协同潜力。它提出了一种联合MLLM-WM驱动的架构,以克服各自的局限性,并推进具有物理基础和语义智能的智能体。
引言
具身人工智能 (EAI) 代表着一种根本性的转变,它将传统的在数字环境中运行的AI系统转变为能够在物理世界中感知、推理和行动的智能代理。Feng 等人撰写的这份综合性调查报告审视了具身人工智能从其理论基础到由大型语言模型 (LLMs)、多模态大型语言模型 (MLLMs) 和世界模型 (WMs) 驱动的尖端实现的演变。该研究通过提出一种集成架构,将 MLLMs 的语义推理能力与 WMs 的物理感知模拟能力相结合,解决了该领域的一个关键空白,并将这种综合视为实现通用人工智能 (AGI) 的关键。
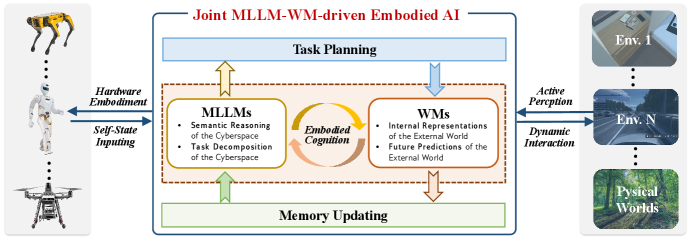
图:所提出的由 MLLM-WM 驱动的具身 AI 联合架构,展示了语义推理能力与物理感知世界建模的整合,以实现全面的任务规划、主动感知和动态交互。
理论基础与演进
该论文将具身人工智能的哲学根源追溯到艾伦·图灵 (Alan Turing) 1950 年提出的“具身图灵测试”概念,该概念认为真正的智能源于与环境的物理交互。这一观点建立在认知科学原理之上,特别是 Lakoff 和 Johnson 的具身认知理论以及 Harnad 的符号接地问题,这些理论都认为有意义的智能需要物理世界中的感觉运动经验。
从以 Brooks 的包容式架构和 Cog 项目为代表的早期基于行为的机器人技术,到现代深度学习支持的系统,历史进程展示了向更复杂的感知-行动循环持续发展的轨迹。作者们确定了定义具身人工智能系统的三个核心组成部分:
主动感知 包括代理通过视觉SLAM、3D场景理解和主动探索策略获取和解释环境信息的能力。与被动感知不同,主动感知涉及指导后续行动的蓄意信息搜寻行为。
具身认知 涉及处理多模态输入以生成语义理解、任务规划和记忆管理。该组件将高级推理与环境背景相结合,使代理能够将复杂目标分解为可执行的子任务。
动态交互 涵盖在物理世界中执行动作,包括运动控制、行为适应以及与其他代理或人类的协作决策。
LLMs 和 MLLMs 在具身 AI 中的作用
大型语言模型通过引入复杂的语义推理能力,实现了自然语言指令遵循和复杂任务分解,从而彻底改变了具身人工智能。该论文追溯了从早期语言条件下的机器人系统(如 SayCan (2022))到包括 PaLM-E、RT-2 和 OpenVLA 在内的更近期多模态方法的演变。
MLLMs 通过将视觉、听觉和触觉输入与语言处理相结合,扩展了 LLM 的能力,创建了能够将高级多模态指令映射到低级运动动作的端到端系统。作者将这些模型分为:
视觉-语言模型 (VLMs),它们结合视觉感知和语言理解,用于具身情境中的场景描述和视觉问答等任务。
视觉-语言-行动模型 (VLAs),它们直接输出运动指令,实现从多模态输入到物理动作的端到端控制。
MLLM驱动的具身智能(EAI)的关键创新在于它能够弥合人类指令与机器人动作之间的语义鸿沟。例如,当收到“清理厨房”的指令时,MLLM能将其分解为具体的子任务,如“找到脏盘子”、“拿起盘子”和“放入洗碗机”,同时处理视觉输入以识别相关物体并规划适当的动作。
用于物理感知交互的世界模型
世界模型解决了MLLM驱动系统的一个根本性限制:缺乏物理感知推理和预测能力。世界模型创建环境动态的内部表征,使智能体能够在真实世界中执行之前模拟潜在的动作序列及其后果。
该论文将世界模型分为三种架构范式:
基于循环状态空间模型(RSSM)的世界模型 例如Dreamer-v3,利用循环神经网络建模时间依赖性和状态转换,在连续控制任务和长周期规划方面表现出色。
基于联合嵌入预测架构(JEPA)的世界模型 学习抽象表征,捕捉关键环境特征同时舍弃不相关细节,从而实现高效的预测和规划。
基于Transformer的世界模型 利用注意力机制来建模复杂的时空关系,对于处理多模态感知输入和长序列预测尤其有效。
世界模型的数学基础可以表示为学习一个预测未来状态的函数$f$:
$$
s_{t+1} = f(s_t, a_t, \theta)
$$
其中$s_t$表示当前状态,$a_t$是采取的动作,$\theta$是学习到的模型参数。这种预测能力支持基于想象的规划,智能体可以在模拟中评估多个动作序列,然后再进行真实世界中的执行。
所提出的联合MLLM-WM架构
该论文的核心贡献在于识别出纯MLLM方法和纯WM方法中互补的局限性,从而提出了一种整合架构,该架构利用了两种范式的优势。
MLLM的局限性 包括未能将预测基于符合物理的动力学,以及对环境变化的实时适应性差。尽管MLLM擅长语义推理和任务分解,但它们通常生成的动作可能违反物理约束,或在环境条件意外变化时无法适应。
WM的局限性 包括在开放式语义推理方面的不足以及缺乏可泛化的任务分解能力。世界模型可以准确模拟物理动力学,但无法解释自然语言指令或将抽象目标分解为具体的动作序列。
所提出的联合架构创造了协同互动:
MLLM增强世界模型:来自MLLM的语义知识丰富了WM的表征,从而实现更好的任务分解和长周期规划。例如,一个理解“准备早餐”的MLLM可以引导世界模型关注相关的厨房物品及其相互作用。
世界模型增强MLLM:来自世界模型的物理约束和时空上下文将MLLM的推理锚定在现实中,通过基于仿真的反馈提供迭代细化。这确保了规划的动作在物理上是可行的,并且环境上是合适的。
该架构的工作流程涉及感知系统、MLLM推理模块、WM仿真组件和动作执行系统之间的持续交互,从而形成一个闭环学习过程,实现终身适应和改进。
应用与实际影响
该调查展示了具身智能(EAI)在不同领域的实际意义:
服务机器人应用包括家庭辅助、老年护理和酒店服务,在这些应用中,机器人必须理解自然语言指令,在复杂环境中导航,并能安全地在人类周围操作物体。
救援无人机需要快速环境评估、在危险条件下自主导航以及为搜救行动进行智能决策。
工业机器人受益于能够学习新任务、与人类工人协作并根据不同的生产要求保持质量标准的自适应制造系统。
这些应用突出了集成多模态大语言模型-世界模型(MLLM-WM)系统的必要性,该系统结合了语义理解和物理感知交互能力。
未来研究方向
本文确定了几个需要进一步研究的关键领域:
自主具身智能发展侧重于通过改进的自学习和适应能力来减少人工干预,使智能体能够在新环境中独立操作。
硬件优化解决了集成多模态大语言模型-世界模型(MLLM-WM)系统的计算需求,需要高效架构、实时处理能力和节能实现方面的进步。
群体具身智能探索多智能体协调和协作,即多个具身智能体共同完成超出个体能力的复杂任务。
可信度和可解释性确保具身智能体能为其行为提供透明的推理,这对于安全关键应用和人机交互场景尤为重要。
意义与影响
这项工作为理解具身人工智能研究的现状和未来方向提供了一个全面的框架。通过识别多模态大语言模型(MLLM)和世界模型(World Model)的互补性,本文为开发更强大、更可靠的具身智能体提供了清晰的路线图。所提出的联合架构解决了当前方法中的根本局限性,同时保持了两种范式的优势。
其意义不仅限于学术贡献,还延伸到对机器人技术、自主系统和人机交互的实际影响。通过将语义推理与物理感知仿真相结合,这项工作推动了该领域向真正智能的智能体发展,使其能够在复杂、动态的环境中有效运行,同时保持实际部署所需的安全性与可靠性标准。
对现有文献的全面分析、对研究空白的清晰识别以及具体的架构提案,使这项综述成为致力于下一代具身人工智能系统的研究人员和实践者的宝贵资源。

技术共进,成长同行——讯飞AI开发者社区
更多推荐

 10
10 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)