
Vulnerability-Aware Spatio-Temporal Learning for Generalizable Deepfake Video Detection(针对可泛化的深度伪造视频
深度伪造视频的检测是非常有难度的,。现有的方法大多都是用真实和伪造图片序列的二元分类器,这限制了他们的泛化性。并且随着生成式人工智能的不断发展,深度伪造的伪影再空间和时间层面更加难以察觉。。我们引入了一个多任务学习框架,包含两个辅助分支,专门观察时间伪影和空间伪影。。我们的模型泛化下很好。
1.摘要
深度伪造视频的检测是非常有难度的,因为表征时空伪影的复杂性很高。现有的方法大多都是用真实和伪造图片序列的二元分类器,这限制了他们的泛化性。并且随着生成式人工智能的不断发展,深度伪造的伪影再空间和时间层面更加难以察觉。于是我们提出了一种名为FakeSTormer的细粒度深度伪造视频检测方法,该方法强调建模细微的时空不一致性,同时避免过拟合。我们引入了一个多任务学习框架,包含两个辅助分支,专门观察时间伪影和空间伪影。我们提出了一种视频级数据合成策略,可以生成具有席位时空伪影的伪造视频,进而来为我们的辅助分支提供高质量样本和无需手动标注的注释。我们的模型泛化下很好。
2.引言
随着深度伪造视频变得更加逼真,尽管他们带来了一定的引用价值,但是有也引发了真多社会问题,因此开发有效的深度伪造检测方法百年的尤为迫切。
现有的方法中,许多深度伪造检测技术都是对每一帧独立进行建模时空伪影,如果处理的是帧级别的伪影时,这种方法是合理的,但是面对视频级的操作技术时,时空为营就和相互交织,这种方法就会很乏力。
研究人员研究探索了能够建模时空伪影的基于视频的深度伪造检测方法。但是这些方法主要依赖一个由单一二元分类构成的神经网络,用真假数据集去进行训练。这样做有两个局限性,
1,泛化性不足,使用单一二元分类器训练的模型容易过拟合他们所训练的深度伪造检测类型,
2.对高质量深度伪造视频的鲁棒性不足,深度伪造技术的不断优化,是空的伪影也变得更加细微,我们更加需要引入注意力机制。
为了进一步鼓励模型学习到通用表示,已经引入视频级的数据合成方法。这个意思是不是就是我们的深度伪造检测方法自己生成一些视频级的伪影视频,然后再把这个伪影视频一起学习,相当于进一步增加他的训练数据的量。但是这种方法通常无法保证细粒度伪影痕迹的识别。
也有人使用多任务学习框架来关注易出现伪影的肖区域, 并且对那些数据去进行伪造合成,从而增强对高质量深度伪造检测泛化性的能力。这种方法经常被忽视,举个例子,比如人脸,人脸面部区域也就是鼻子眼睛嘴巴什么的容易被伪造,现在大多数人都是对一整张图片生成假图片,但是很少有人专门针对鼻子眼睛嘴巴进行伪造。这个就是他们忽略的问题。
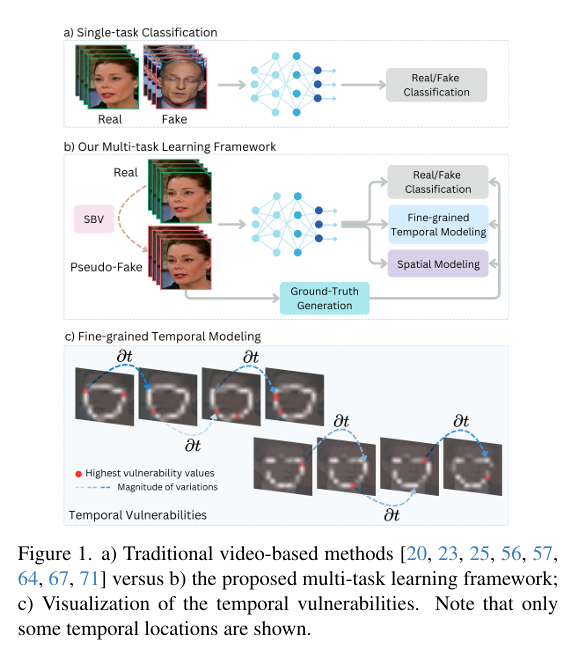





我们引入了一个专门用于针对微妙空间和时空伪影的学习目标,提出了一个名为 FakeSTormer 的多分支网络,该网络利用合成数据,整合了专门针对微妙时空伪影的学习目标。具体来说,FakeSTormer 包括两个辅助分支和一个标准分类头:
-
回归时间分支:包含显式注意力机制,旨在定位易出现漏洞的时间位置。通过回归空间易出现漏洞的块中的时间高变化,增强模型的泛化能力。
-
空间分支:预测帧级空间漏洞,确保空间和时间领域之间的平衡,提高检测的准确性。
我们提出了一种一种名为 “自混合视频(SBV)” 的高质量视频级数据合成算法。我们的模型具有很好的性能。为了增强空间和时间建模,我们重写甚至了骨干网络的TimerSformer架构。我们利用这个架构分解时间注意力和空间注意力,再每帧和跨帧中附加分类标记,而不是整个视频使用单个标记(就是其他人可能是一整个视频使用一个标记来进行分类,而我们是对每一帧以及跨帧使用标记)。我们的模型泛化性效果很好。
3.相关工作
基于视频的深度伪造检测
简单的时空二元分类模型进行视频级深度伪造检测可能导致模型过拟合明显的伪影,从而在泛化到未见过的操纵方法时表现不佳。为了解决这个问题,有人提出了完全基于时空卷积的网络,将空间核大小减少到1,从而降低了只关注空间伪影的可能。也有人只考虑嘴部区域,不要空间信息,也有人将卷积层分为空间和时间层,但是他却没有建模长期的依赖关系。也有人不适用卷积层,而是使用基于视频的视觉变化其和自注意力来去提高更长距离视频的相关性。上面的方法都很有前景,但是他们最大的问题就是太过依赖单一的二元分类器,他隐式地指导了特征提取,但是会让我们的模型过度拟合某些伪影,缺乏对时空伪影伪影易发区域地显示注意力机制,可能会导致模型的鲁棒性差。
数据合成
提高深度检测器泛化性的很有效的方法就是使用合成数据去训练模型。虽然处理帧级问题已经被广泛应用,但是视频级的增强仍然很少被探索。但是目前很多细微信息的引入仍然不能达到现有的更细微时间不一致性的深度伪造。
4.方法
4.1. 视频级数据合成与增强
自混合视频:。基于混合的数据合成方法在基于图像的深度伪造检测中表现出色。事实上,由于混合步骤是不同操纵类型的共同点,它们有助于提高深度伪造检测的泛化能力。但是他们都不去思考去伪造那些容易被伪造的区域。所以我们提出了SBV,可以生成高质量的伪造图像,他由两个组件组成,一个CSP模块 一个LI模块。
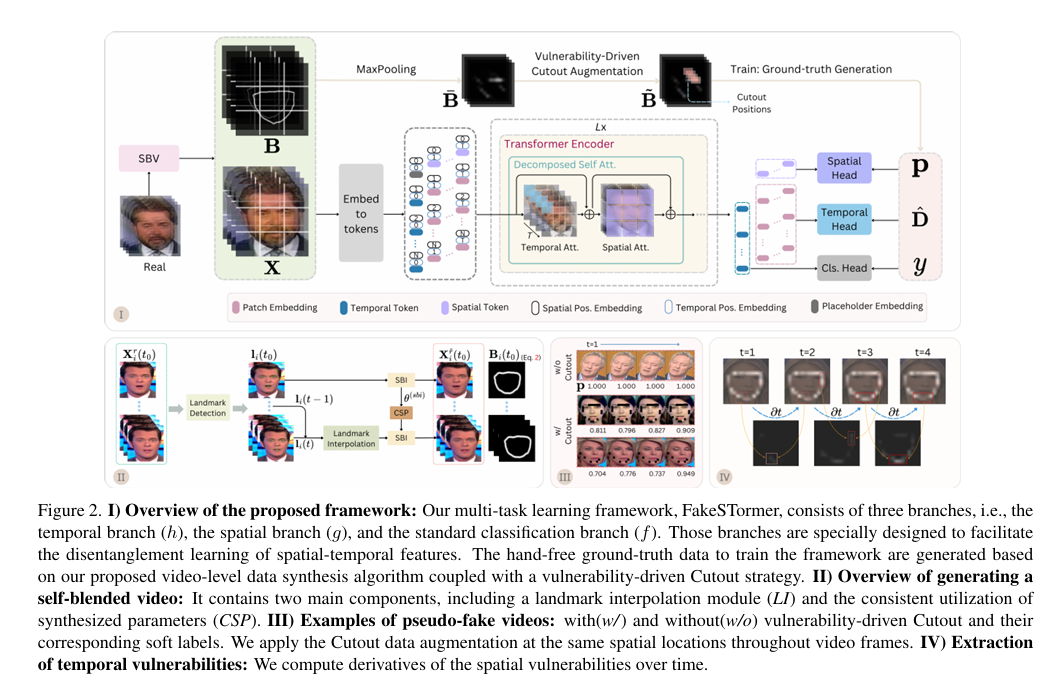
图 2. I) 提出的框架概述:我们的多任务学习框架,FakeSTormer,包含三个分支,即时间分支( h)、空间分支( g)和标准分类分支( f)。这些分支专门设计用于促进时空特征的解耦学习。
该框架的训练无需手动标注的地面真实数据,而是基于我们提出视频级数据合成算法结合易损性驱动的Cutout策略生成的数据。
II) 生成自混合视频的概述:它包含两个主要组件,包括地标插值模块( LI)和一致合成参数( CSP)的持续利用。
III) 伪伪造视频的示例:展示了使用/未使用易损性驱动Cutout及其对应软标签的伪伪造视频。我们在视频帧中相同的空间位置应用Cutout数据增强。
IV) 提取时间漏洞:我们计算空间漏洞随时间的变化


-
数据准备和自混合视频(SBV)生成真实视频输入:从真实视频数据集 V 中选取一个视频样本 X。自混合视频(SBV):对真实视频 X 应用SBV方法,生成伪伪造视频 \tilde{X} 和混合边界 \tilde{B}。地标检测:在视频帧中检测关键地标。地标插值:利用地标插值模块(LI)和一致合成参数(CSP)保持地标在帧间一致性。合成视频:生成包含微妙时空伪影的伪伪造视频。2. 特征提取和令牌嵌入特征提取:将伪伪造视频 \tilde{X} 送入特征提取器,提取特征表示。令牌嵌入:将特征嵌入到不同类型的令牌中:空间令牌:捕捉视频中的空间信息。时间令牌:捕捉视频中的时间信息。分类令牌:用于分类任务,区分真实和伪造视频。3. Transformer编码器处理编码器处理:将嵌入的令牌输入到Transformer编码器。分解自注意力:编码器利用分解的自注意力机制(时间注意力和空间注意力)进一步提取时空特征。4. 多任务学习分支空间分支:处理空间令牌,预测每帧视频中的空间漏洞。时间分支:处理时间令牌,预测视频中时间漏洞的变化。分类分支:使用分类令牌进行最终的真实/伪造分类。5. 数据增强和训练易损性驱动的Cutout增强:在视频帧的脆弱区域应用Cutout增强,减少过拟合风险。训练真实数据生成:使用生成的伪伪造视频和真实视频训练模型,优化三个分支。6. 训练目标和损失函数损失函数:通过最小化分类损失、时间损失和空间损失的组合来训练网络,每个损失函数对应一个分支。
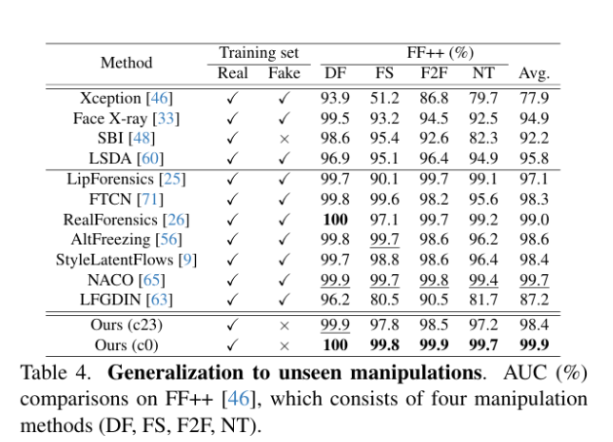
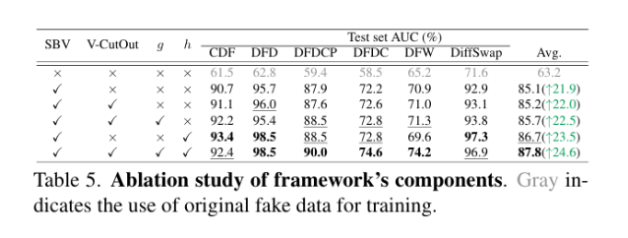
5.实验

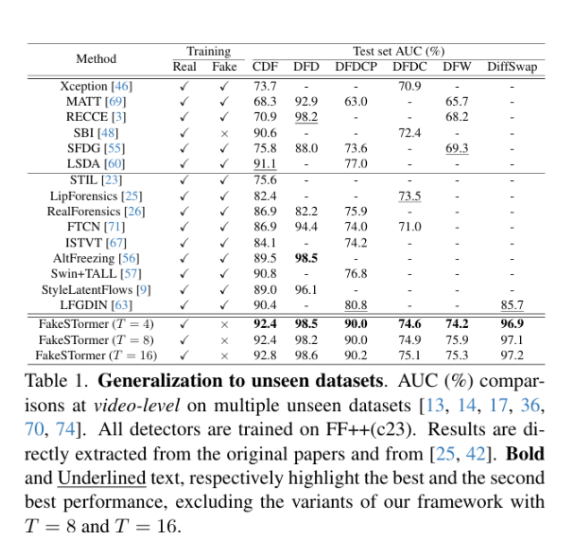
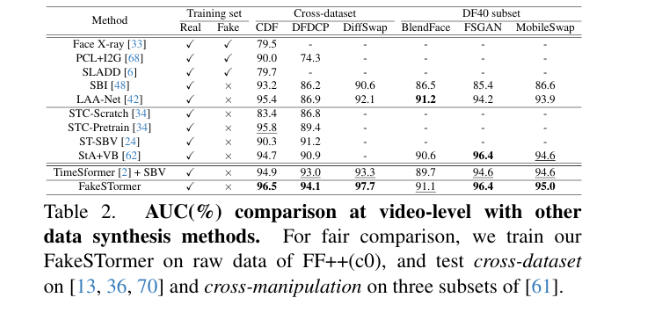
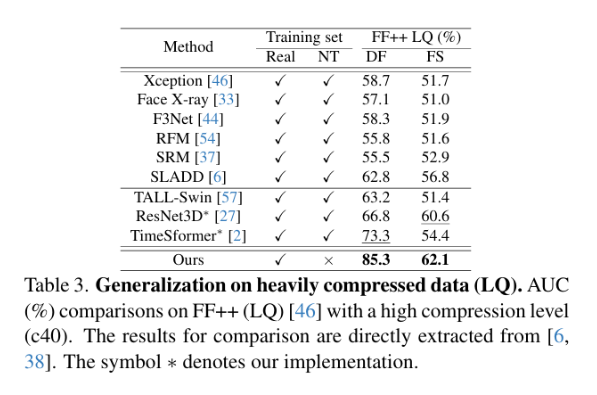
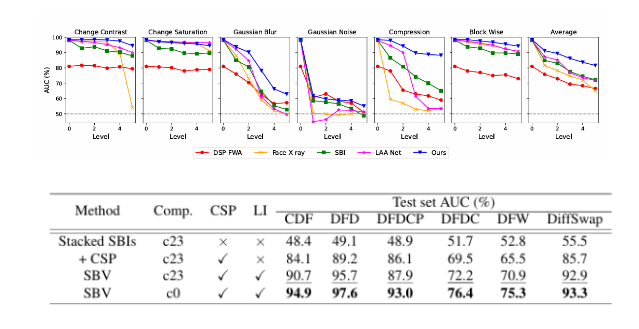

技术共进,成长同行——讯飞AI开发者社区
更多推荐

 11
11 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)