
技术实践指南:多模态RAG从数据预处理到生成响应的完整流程
本文详细介绍了多模态RAG(检索增强生成)技术,在传统文本RAG基础上整合视觉、听觉等多种信息源,实现跨模态检索与生成。文章解析了多模态RAG的核心原理、技术组件(编码器、检索系统、生成模型)及实践路径(数据预处理、查询处理、生成响应),并指出模态对齐、跨模态理解等技术挑战。多模态RAG扩展了AI系统的应用范围,是通向通用人工智能的重要路径,将深刻影响未来人机交互方向。
本文较长,建议点赞收藏,以免遗失。更多AI大模型应用开发及AI算法学习视频及资料,尽在 聚客AI学院。
多模态 RAG(Retrieval-Augmented Generation)是在传统文本 RAG 基础上整合视觉、听觉等多种信息源,从而提供更丰富、准确且上下文相关的回答。这一技术极大地拓展了人工智能系统的应用范围与实用性,使其能够处理和理解图像、音频、视频等多类型数据,而不再局限于文本。今天我将深度解析多模态RAG的实践路径及其工作原理,希望对你们有所帮助。
一、多模态基本原理
多模态 RAG 的核心思想是将 RAG 的检索与生成机制扩展至多模态语境,主要包括以下三个方面:
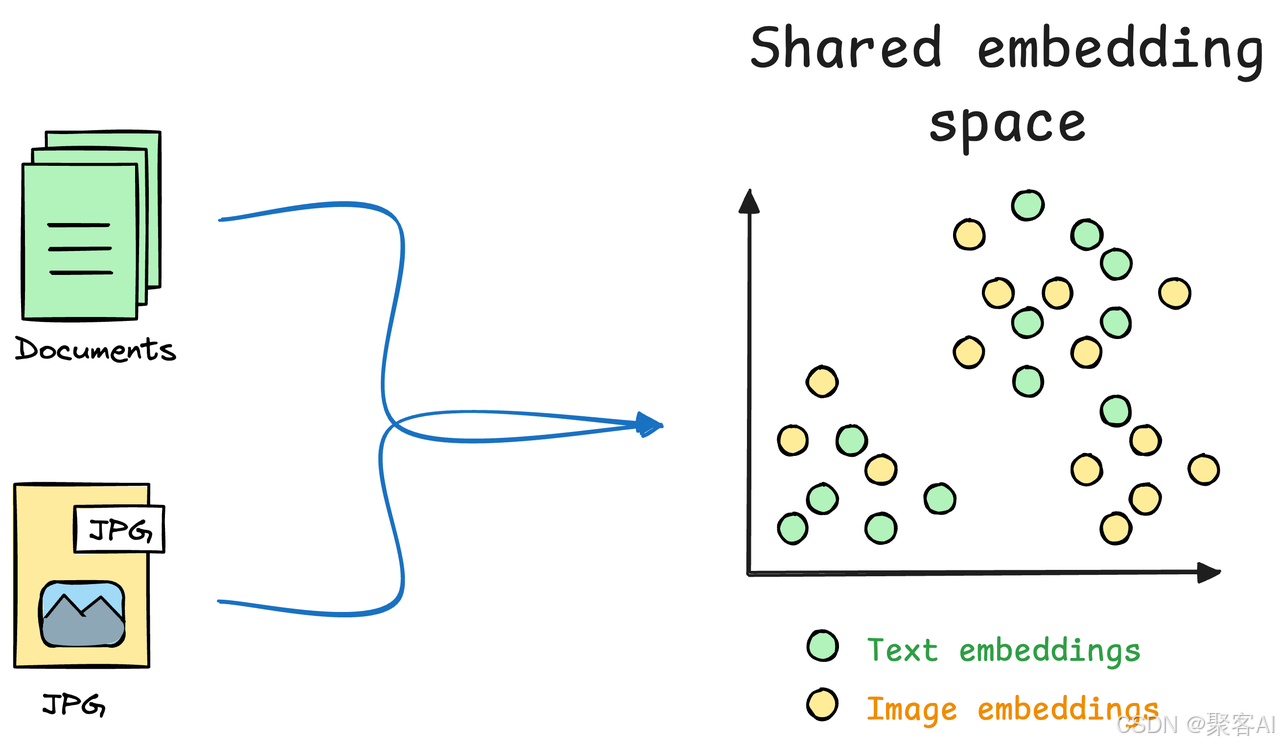
- 多模态表示学习:将文本、图像、音频等不同模态的数据映射到统一的向量表示空间。
- 跨模态检索:支持以一种模态(如图像)作为查询,检索另一种模态(如文本)的相关内容。
- 多模态生成:生成融合多类模态信息的连贯回答。
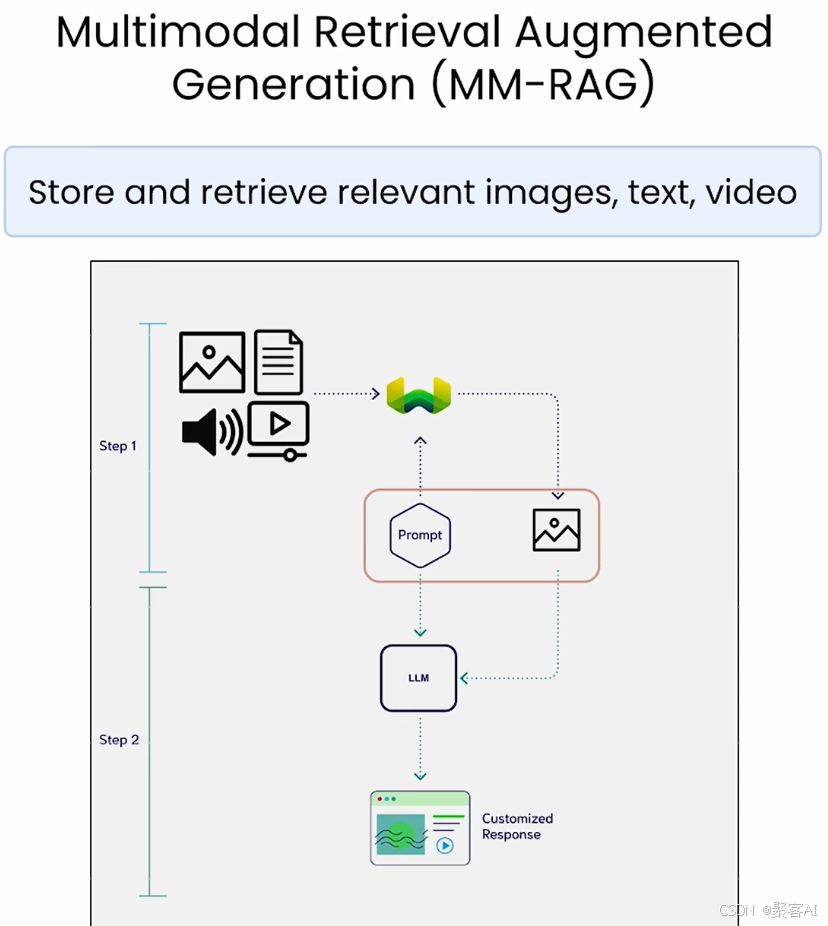
二、核心技术组件
实现多模态 RAG 系统,主要依赖以下三类技术组件:
多模态编码器
用于将不同模态原始数据转换为统一语义空间中的向量表示。常用模型包括 CLIP、ALBEF、VinVL 等。具体地:
- 文本编码器:如 BERT、RoBERTa;
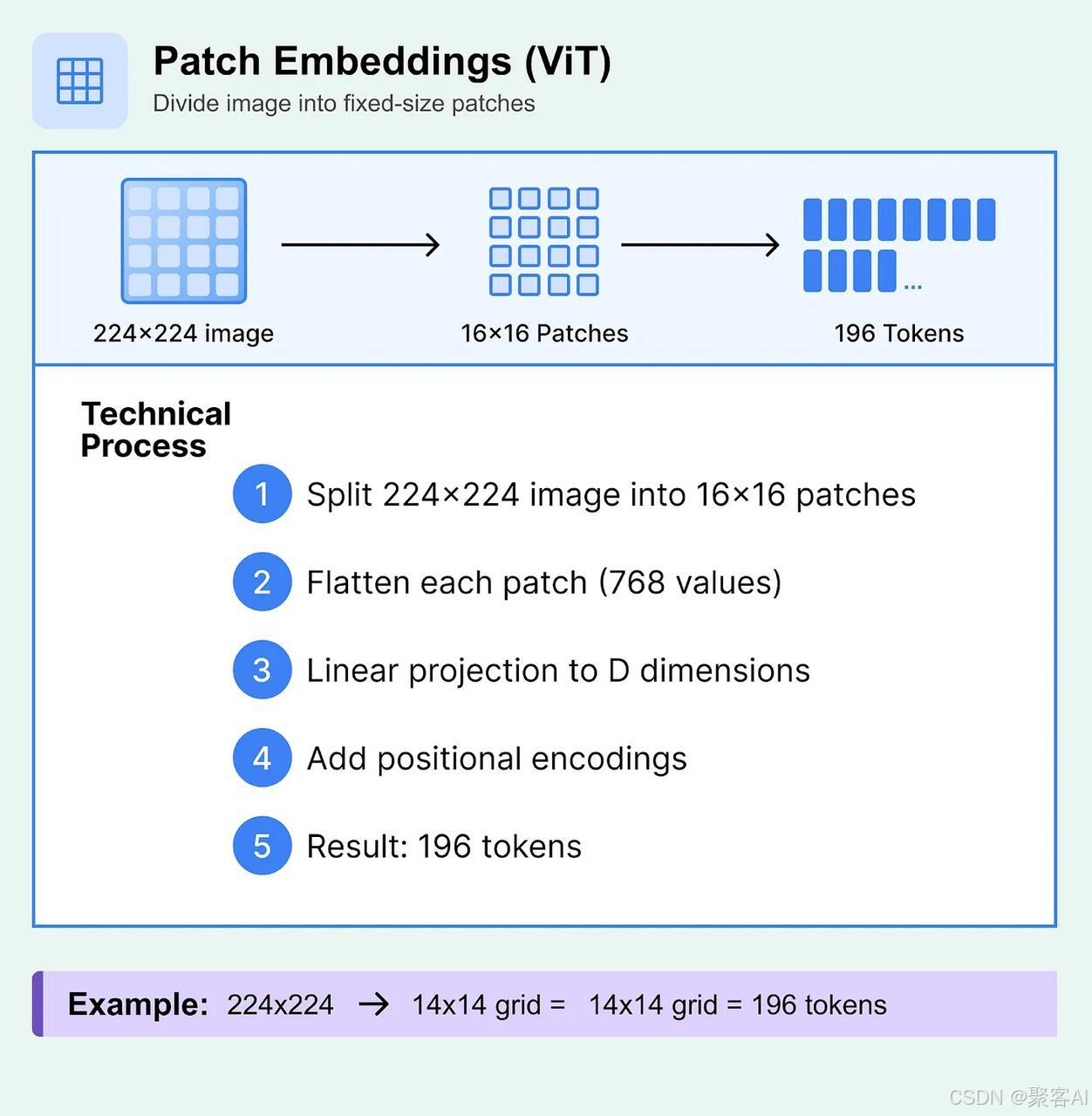
- 图像编码器:如 ViT、ResNet;
- 音频编码器:如 Wav2Vec、HuBERT。
多模态检索系统
基于统一向量空间实现跨模态的相似性搜索,支持高效检索多模态内容。
多模态生成模型
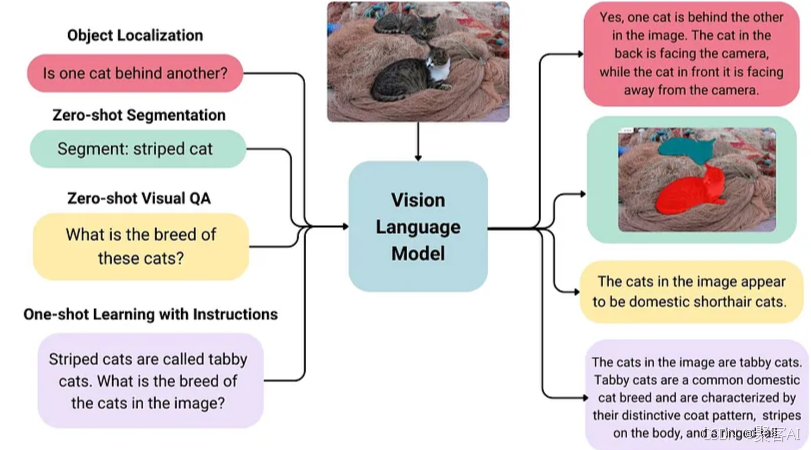
能够理解并生成融合多模态信息的回答,典型模型如 Flamingo、BLIP-2、GPT-4V 等。
三、实践路径
多模态 RAG 的工作流程可划分为三个阶段:
阶段一:数据预处理与索引构建
- 多模态数据收集:包括文本、图像、音频、视频等多种格式的文档,例如带图像和图表的产品手册。
- 多模态内容提取:
- 文本提取:从文档、OCR 识别、语音转录(ASR)中获取;
- 图像特征提取:通过视觉编码器提取;
- 音频处理:转录并提取音频特征。
- 多模态编码与向量化:使用如 CLIP 等编码器将不同模态信息映射到同一向量空间。
- 构建多模态向量索引:将向量存入支持高效跨模态检索的向量数据库中。
阶段二:查询处理与检索
- 多模态查询解析:用户可提交混合模态的查询,例如“上传产品图片询问技术规格”。
- 多模态查询编码:使用相同编码器将查询转换为向量表示。
- 跨模态检索:在向量数据库中进行相似性搜索,如以图搜文。
- 结果重排序与融合:对检索结果重新排序并融合多模态内容,以提升相关性。
阶段三:生成与响应
- 多模态上下文构建:将检索出的多模态内容(如图像、文本、评论等)整合为上下文。
- 多模态生成:利用多模态生成模型构建回答,模型可引用图像、文本等多种信息。
- 响应呈现:最终输出可包含嵌入式图像、图表等多模态元素的回答。
ps:这里再补充一个知识点,就是我之前这里的一个关于CLIP 模型训练与实战技术文档,建议粉丝朋友都可以看看:《CLIP 模型训练与实战》
四、核心技术挑战
多模态 RAG 的发展仍面临多项关键挑战:
- 模态对齐:不同模态在向量空间需保持语义一致性;
- 跨模态理解:模型需深入理解多模态之间的语义关联;
- 计算效率:多模态数据处理对算力要求较高;
- 训练数据质量:依赖大规模高质量多模态数据集;
- 系统评估:多模态输出的评估比单模态更复杂。
多模态 RAG 不仅是技术的扩展,更是通向AGI的必经之路,其能力边界的拓展将深刻影响未来人机交互与应用创新的方向。好了,今天的分享就到这里,点个小红心,我们下期见。

技术共进,成长同行——讯飞AI开发者社区
更多推荐

 12
12 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)