
人工智能AI大模型之数据集
大模型的数据集是一个多层次、多目标的复杂生态系统预训练数据是基石,决定了模型的知识广度和深度。SFT数据是教练,决定了模型的行为模式和对话能力。RLHF数据是价值观校准器,决定了模型的输出安全性和人性化程度。构建一个成功的大模型,其核心工程挑战很大程度上在于如何大规模地收集、清洗、策划和组织这些不同类型的数据,而不仅仅是设计模型架构。好的,我们将详细说明大模型训练各个阶段(预训练、有监督微调-SF
在软件开发领域,需求管理一直是项目成功的核心关键。随着项目复杂度提升和团队规模扩大,传统依赖文档、邮件和会议的需求管理方式显露出明显短板:版本混乱、协作困难、知识难以沉淀。更值得注意的是,行业内能够真正实现需求结构化、资产化,并结合AI技术进行智能化辅助的系统并不多见。我们公司是一家垂直领域专攻企业级需求与非企业级需求管理的公司, 我们公司的大模型应用连接:http://aipoc.chtech.cn:8880/#/login 欢迎试用。
好的,我们来详细、系统地说明大模型(Large Language Models, LLMs)中所使用的数据集。这是理解大模型为何如此强大的关键,因为数据是模型能力的上限,而架构和算法只是尽可能去逼近这个上限。
大模型的训练通常分为多个阶段,每个阶段都依赖不同类型和规模的数据集。下图清晰地展示了一个典型大模型训练流程中的数据流向与阶段:
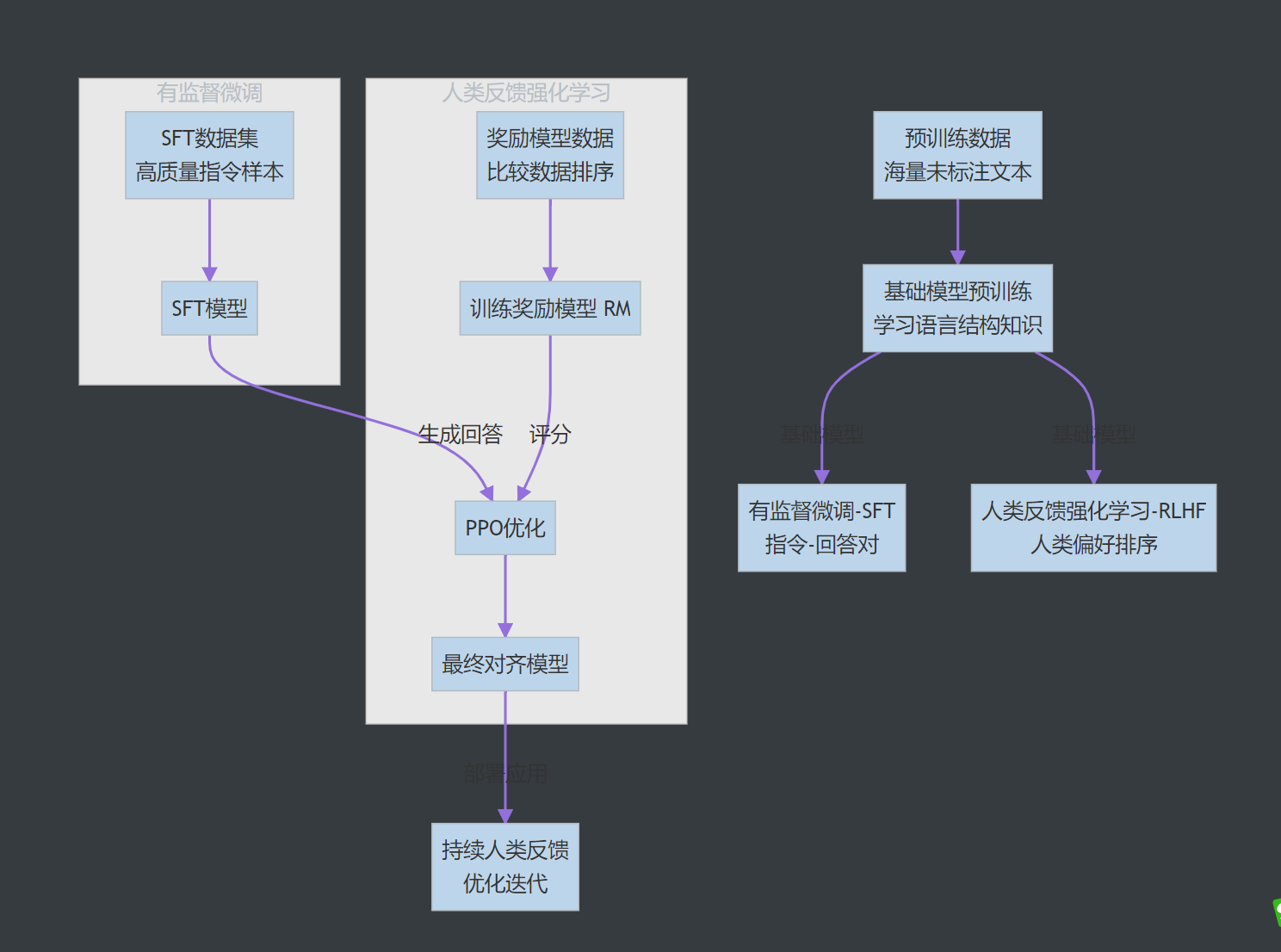
第一部分:大模型数据集的宏观特点
-
海量规模(Unprecedented Scale):
-
现代大模型的训练数据量可达数TB甚至数十TB,包含万亿(trillion)乃至数万亿个token。
-
例如,GPT-3的训练数据CommonCrawl的原始数据量就超过了45TB。
-
-
来源极其多样(Extreme Diversity):
-
数据并非来自单一源头,而是混合了来自互联网、书籍、代码、学术论文、对话记录等众多来源的文本,以确保模型获得广泛的知识和语言风格。
-
-
严格的预处理与过滤(Heavy Preprocessing & Filtering):
-
“垃圾进,垃圾出”(Garbage in, garbage out)。原始网络数据质量低下,包含大量重复、无关、低质甚至有害内容。
-
构建数据集的核心工作(约80%的精力)在于数据清洗和 curation,而非简单的收集。这个过程包括:
-
去重(Deduplication):去除文档级、段落级和句子级的重复内容。
-
质量过滤(Quality Filtering):基于分类器或启发式规则过滤掉低质量文本(如内容农场、色情暴力、机器生成的无意义文本)。
-
安全与隐私过滤:移除个人身份信息(PII)和有害内容。
-
-
-
多阶段训练,多类型数据(Multi-stage, Multi-type):
-
大模型并非一次性用光所有数据。其训练是分阶段的,每个阶段使用特定类型的数据以达到特定目的。
-
第二部分:大模型训练各阶段的数据集详解
对应于开头的流程图,我们来看看每个阶段数据的具体形态和作用。
阶段一:预训练(Pre-training)数据 - 构建“世界模型”
这是最大、最基础的数据集,用于训练基础模型(Base Model),让模型学会语言的语法、句法、事实知识和初步的推理能力。
-
目标:进行自监督学习,通常使用下一个token预测(Next Token Prediction)的任务。
-
数据形态:海量的、未标注的原始文本。不需要人工标注,互联网本身就是巨大的来源。
-
主要数据来源:
-
网络爬虫数据(Web Crawls):最大的来源。例如:
-
CommonCrawl:非营利组织提供的免费网络爬虫数据,是GPT-3、Llama等模型数据的主要构成。
-
C4 (Colossal Clean Crawled Corpus):由Google创建的、经过严格清洗的CommonCrawl子集,用于训练T5模型。
-
-
书籍语料库(Books):提供长程上下文、叙事结构和高质量的语言表达。
-
BookCorpus:一个广泛使用的小说数据集。
-
-
代码数据(Code):来自GitHub等平台的公开代码库。赋予模型逻辑推理、结构化思维和代码生成能力。
-
学术论文与百科(Academic & Encyclopedia):如Wikipedia、ArXiv等。提供严谨、准确的事实性知识。
-
对话数据(Conversations):来自论坛、聊天记录等。帮助模型学习对话结构和日常用语。
-
代表性预训练数据集:
-
The Pile(EleutherAI):一个825GB的、专门为训练大模型而精心策划的数据集,整合了24个不同领域的高质量子集(如学术、法律、医学等)。
-
RefinedWeb(TII):Falcon模型使用的数据集,强调对CommonCrawl的极致去重和过滤。
阶段二:有监督微调(Supervised Fine-Tuning, SFT)数据 - 教导“行为规范”
预训练模型是一个“知识渊博但不懂规矩的学者”,它可能不会遵循指令、胡言乱语或有害输出。SFT阶段用于塑造它的行为模式。
-
目标:训练模型遵循指令(Instruction-following) 并进行高质量的对话。
-
数据形态:高质量的(指令,期望回答)配对数据。通常需要人工编写或精心筛选,规模远小于预训练数据(数万到数十万条)。
-
数据内容示例:
-
指令: “写一首关于春天的诗。” -
期望回答: “春风轻拂面,百花竞相开...”
-
-
数据来源:
-
人工撰写:雇佣标注人员编写指令和回答。质量最高,但成本高昂。
-
self-instruct:使用种子指令集让模型自己生成指令和回答,再由人工筛选和修正。
-
API蒸馏:从诸如ChatGPT的API中收集用户查询和模型的优秀回答。
-
现有NLP数据集转化:将传统NLP任务(如摘要、翻译、问答)转化为指令格式。
-
代表性SFT数据集:
-
Alpaca:使用self-instruct方法,基于52k条指令数据对Llama进行微调。
-
FLAN:Google提出的指令微调数据集集合,将众多NLP任务统一转化为指令格式。
-
ShareGPT:收集用户与ChatGPT的真实对话数据。
阶段三:人类反馈强化学习(RLHF)数据 - 对齐“人类偏好”
这是让模型变得“有用、诚实、无害”(Helpful, Honest, Harmless)的关键一步,使其输出更符合人类的价值标准和审美。
-
目标:训练一个奖励模型(Reward Model, RM),然后用它通过强化学习(如PPO)来微调SFT模型,使其输出能获得更高的奖励分数。
-
数据形态:比较数据(Comparison Data)。对于同一个指令,给出模型的不同输出(通常是2-4个),让标注者对这些输出进行排序。
-
数据内容示例:
-
指令: “解释一下光合作用。” -
回答A: “光合作用是植物吃饭的过程。” (差) -
回答B: “光合作用是植物利用光能...(详细准确)” (好) -
回答C: “光合作用就是植物晒太阳。” (一般) -
人类排序:
B > C > A
-
-
数据来源:严重依赖人工标注。标注员需要根据帮助性、相关性、无害性等标准对回答进行排序。
第三部分:数据处理的挑战与未来趋势
-
数据瓶颈:高质量的网络文本即将耗尽,未来需要寻找新的数据来源或更高效的数据利用方法(如“课程学习”)。
-
数据质量 vs. 数量:研究表明,高质量、高多样性的数据远比单纯堆砌数据量更重要。未来重点将是“少而精”的数据 curation。
-
数据隐私与版权:使用网络数据面临严峻的版权和隐私挑战。合成数据(Synthetic Data)和完全使用获授权数据(如TII的Falcon模型)是重要方向。
-
数据偏见与毒性:互联网数据中固有的偏见和有害内容会被模型放大。如何有效识别和过滤这些内容仍是巨大挑战。
-
多模态数据:下一代大模型(如GPT-4V、Gemini)的训练数据将包含图像、音频、视频等多模态信息,数据集的构建和管理将更加复杂。
总结
大模型的数据集是一个多层次、多目标的复杂生态系统:
-
预训练数据是基石,决定了模型的知识广度和深度。
-
SFT数据是教练,决定了模型的行为模式和对话能力。
-
RLHF数据是价值观校准器,决定了模型的输出安全性和人性化程度。
构建一个成功的大模型,其核心工程挑战很大程度上在于如何大规模地收集、清洗、策划和组织这些不同类型的数据,而不仅仅是设计模型架构。
好的,我们将详细说明大模型训练各个阶段(预训练、有监督微调-SFT、人类反馈强化学习-RLHF)中数据集的具体使用方式,并提供清晰的示例代码。
我们将使用 Hugging Face Transformers 和 Datasets 库作为示例,这是当前最主流和实用的工具。
环境准备
首先,确保安装了必要的库:
bash
pip install transformers datasets accelerate torch peft trl
第一阶段:预训练 (Pre-training)
目标:使用海量无标注文本训练基础模型,学习语言建模(下一个token预测)。 数据形态:原始文本文件(如.txt),每行一个文档或一段文本。
使用情况与代码示例
1. 数据格式与加载 假设我们有一个文本文件 my_corpus.txt,内容如下:
text
The quick brown fox jumps over the lazy dog. Hello world! This is a sample text corpus for pretraining. Machine learning is a subset of artificial intelligence. ...
我们可以使用 datasets 库加载这种文本数据:
python
from datasets import load_dataset
# 方式1: 从文本文件加载
dataset = load_dataset('text', data_files={'train': 'path/to/my_corpus.txt'})
# 方式2: 使用Hugging Face Hub上的经典预训练数据集(例如C4的一个子集)
# dataset = load_dataset('c4', 'en', split='train', streaming=True) # 流式模式,处理超大数据集
print(dataset['train'][0]) # 查看第一条数据
# 输出: {'text': 'The quick brown fox jumps over the lazy dog.'}
2. 核心处理:Tokenization与分块 预训练数据需要被tokenize并切成模型可接受的固定长度序列。
python
from transformers import AutoTokenizer
model_name = "gpt2" # 以GPT-2的tokenizer为例
tokenizer = AutoTokenizer.from_pretrained(model_name)
tokenizer.pad_token = tokenizer.eos_token # 设置pad token
def tokenize_function(examples):
# 对文本进行tokenization,truncation和padding由DataCollator处理
return tokenizer(examples["text"])
# 应用tokenization
tokenized_datasets = dataset.map(
tokenize_function,
batched=True,
num_proc=4, # 并行进程数
remove_columns=dataset["train"].column_names # 移除原始文本列,只保留input_ids
)
# 定义数据整理器,用于动态padding和分块
from transformers import DataCollatorForLanguageModeling
data_collator = DataCollatorForLanguageModeling(
tokenizer=tokenizer,
mlm=False, # 对于GPT这类自回归模型,使用CLM而不是MLM
return_tensors="pt"
)
# 现在tokenized_datasets中的每个样本已经被转换成了token IDs
block_size = 512 # 序列长度
def group_texts(examples):
# 连接所有文本,然后切分成block_size长的块
concatenated_examples = {k: sum(examples[k], []) for k in examples.keys()}
total_length = len(concatenated_examples[list(examples.keys())[0]])
# 丢弃最后的余数部分
total_length = (total_length // block_size) * block_size
# 按block_size切片
result = {
k: [t[i : i + block_size] for i in range(0, total_length, block_size)]
for k, t in concatenated_examples.items()
}
result["labels"] = result["input_ids"].copy() # 对于CLM,labels就是input_ids
return result
lm_datasets = tokenized_datasets.map(
group_texts,
batched=True,
num_proc=4,
)
3. 创建DataLoader并训练
python
from torch.utils.data import DataLoader train_dataloader = DataLoader( lm_datasets["train"], shuffle=True, batch_size=4, collate_fn=data_collator, # 使用上面的collator进行动态padding ) # 训练循环伪代码 # for batch in train_dataloader: # input_ids = batch['input_ids'].to(device) # labels = batch['labels'].to(device) # outputs = model(input_ids, labels=labels) # loss = outputs.loss # loss.backward() # optimizer.step() # ...
第二阶段:有监督微调 (SFT / Instruction Tuning)
目标:教会模型遵循指令并进行高质量对话。 数据形态:JSON格式的指令-回答对。
使用情况与代码示例
1. 数据格式 一个典型的SFT数据集是JSONL文件(sft_data.jsonl),每行一个样本:
json
{"instruction": "写一首关于秋天的诗。", "input": "", "output": "秋风起兮白云飞,草木黄落兮雁南归..."}
{"instruction": "将下面的英文翻译成中文:", "input": "Hello, world!", "output": "你好,世界!"}
{"instruction": "计算10的阶乘。", "input": "", "output": "10的阶乘是3628800。"}
2. 数据加载与模板格式化
python
sft_dataset = load_dataset('json', data_files={'train': 'path/to/sft_data.jsonl'})
# 定义一个模板函数,将指令、输入和输出组合成模型所需的对话格式
def format_instruction(sample):
# 使用ChatML格式等,这里是一个简单示例
return {
"text": f"### Instruction:\n{sample['instruction']}\n\n### Input:\n{sample['input']}\n\n### Response:\n{sample['output']}<|endoftext|>"
}
formatted_dataset = sft_dataset.map(format_instruction)
# Tokenization (与预训练类似,但不需要分块)
def tokenize_sft(examples):
return tokenizer(examples["text"], truncation=True, max_length=1024) # 设置最大长度
tokenized_sft = formatted_dataset.map(tokenize_sft, batched=True, remove_columns=formatted_dataset['train'].column_names)
# 对于SFT,我们通常只需要计算response部分的loss,忽略instruction部分的loss
# 这需要通过构造attention_mask和labels来实现
def mask_non_response_labels(examples):
# 这是一个简化示例。实际实现更复杂,需要找到"### Response:" token的位置
# 并将其后的labels保留,之前的labels设置为-100(被CrossEntropyLoss忽略)
labels = examples["input_ids"].copy()
# ... (此处应有逻辑找到response开始的位置idx)
# labels[:idx] = [-100] * idx
examples["labels"] = labels
return examples
tokenized_sft_with_labels = tokenized_sft.map(mask_non_response_labels, batched=True)
3. 使用TRL库进行高效SFT Hugging Face的 trl 库提供了 SFTTrainer,极大简化了流程。
python
from trl import SFTTrainer from transformers import TrainingArguments trainer = SFTTrainer( model=model, tokenizer=tokenizer, train_dataset=tokenized_sft_with_labels["train"], dataset_text_field="text", # 数据集中文本字段的名称 # 或者使用formatting_func来自定义格式 # formatting_func=format_instruction, max_seq_length=1024, args=TrainingArguments( output_dir="./sft-model", per_device_train_batch_size=4, gradient_accumulation_steps=4, learning_rate=2e-5, num_train_epochs=3, logging_steps=10, save_steps=500, ), ) trainer.train()
第三阶段:人类反馈强化学习 (RLHF)
目标:根据人类偏好进一步微调模型,使其输出更符合人类价值观。 数据形态:包含排序信息的比较数据。
使用情况与代码示例
RLHF分为两步:1. 训练奖励模型(RM);2. 使用RM通过PPO算法微调SFT模型。
1. 奖励模型(RM)数据格式与训练 数据格式(rm_data.jsonl):
json
{"prompt": "解释一下量子计算。", "chosen": "量子计算是一种利用量子力学原理...(详细、准确的回答)", "rejected": "量子计算就是很快的计算。(过于简单、不准确的回答)"}
{"prompt": "写一个关于友谊的故事。", "chosen": "从前,有两个好朋友...(温暖、有趣的故事)", "rejected": "他们打架了,然后不再是朋友。(负面、不好的故事)"}
python
rm_dataset = load_dataset('json', data_files={'train': 'path/to/rm_data.jsonl'})
# Tokenize prompt和两个回答
def tokenize_rm_data(examples):
chosen_tokens = tokenizer(examples["chosen"], truncation=True, max_length=512)
rejected_tokens = tokenizer(examples["rejected"], truncation=True, max_length=512)
# 通常也需要tokenize prompt,这里简化了
return {
"input_ids_chosen": chosen_tokens["input_ids"],
"attention_mask_chosen": chosen_tokens["attention_mask"],
"input_ids_rejected": rejected_tokens["input_ids"],
"attention_mask_rejected": rejected_tokens["attention_mask"],
}
tokenized_rm = rm_dataset.map(tokenize_rm_data, batched=True)
# 使用TRL的RewardTrainer或自己编写损失函数
# 损失函数的核心是:maximize (score(chosen) - score(rejected))
# 具体训练代码较为复杂,通常直接使用库实现
2. 使用PPO进行强化学习微调 这是最复杂的部分,但 trl 库的 PPOTrainer 将其封装得很好。
python
from trl import PPOTrainer, PPOConfig, AutoModelForCausalLMWithValueHead
from transformers import AutoModelForCausalLM
# 1. 加载SFT阶段训练好的模型,并包装成带价值头(Value Head)的模型,用于PPO
model = AutoModelForCausalLMWithValueHead.from_pretrained("./sft-model")
# 2. 加载之前训练好的奖励模型
reward_model = AutoModelForSequenceClassification.from_pretrained("./reward-model")
# 3. 准备 prompts 数据
ppo_prompts = [example["prompt"] for example in rm_dataset["train"]]
# ... (tokenize prompts)
# 4. 配置和初始化PPOTrainer
ppo_config = PPOConfig(
batch_size=4,
learning_rate=1.4e-5,
)
ppo_trainer = PPOTrainer(
model=model,
config=ppo_config,
tokenizer=tokenizer,
dataset=ppo_prompts_dataset, # 包含tokenized prompts的数据集
)
# 5. PPO训练循环
for epoch in range(ppo_config.epochs):
for batch in ppo_trainer.dataloader:
# 生成回答
response_tensors = ppo_trainer.generate(
batch["input_ids"], attention_mask=batch["attention_mask"], return_prompt=False
)
batch["response"] = tokenizer.batch_decode(response_tensors, skip_special_tokens=True)
# 使用奖励模型为生成的回答打分
with torch.no_grad():
rewards = reward_model(**response_tensors).logits # 获取奖励分数
# 执行PPO更新步骤
stats = ppo_trainer.step([rt for rt in response_tensors], rewards)
ppo_trainer.log_stats(stats, batch, rewards)
总结
| 阶段 | 数据核心 | 关键处理步骤 | 实用工具 |
|---|---|---|---|
| 预训练 | 无标注文本 | Tokenization、分块、动态Padding | DataCollatorForLanguageModeling |
| SFT | 指令-回答对 | 模板格式化、Mask非Response部分的Loss | SFTTrainer (from trl) |
| RLHF | 排序比较数据 | 训练奖励模型、PPO循环 | RewardTrainer, PPOTrainer (from trl) |
核心要点:
-
预训练数据处理重在规模化和效率,使用流式加载和动态分块。
-
SFT数据处理重在格式化和精准的Loss计算,确保模型只从期望的回答中学习。
-
RLHF数据处理和训练最为复杂,严重依赖高级库(如
trl) 来抽象化强化学习的细节。
在实际工业级应用中,每个阶段的数据管道都远比示例复杂,但上述代码提供了最核心的概念和入门实践路径。

技术共进,成长同行——讯飞AI开发者社区
更多推荐

 23
23 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)