
【论文阅读】具身竞技场:面向具身智能的全面、统一、演进式评估平台
论文题目: Embodied Arena: A Comprehensive, Unified, and Evolving Evaluation Platform for Embodied AI论文地址:https://arxiv.org/pdf/2509.15273来自包括天津大学和华为诺亚方舟实验室在内的全球联盟研究人员开发了Embodied Arena,这是一个评估具身人工智能(Embodie
论文题目: Embodied Arena: A Comprehensive, Unified, and Evolving Evaluation Platform for Embodied AI
论文地址:https://arxiv.org/pdf/2509.15273
来自包括天津大学和华为诺亚方舟实验室在内的全球联盟研究人员开发了Embodied Arena,这是一个评估具身人工智能(Embodied AI)代理的综合平台,其特点是具有系统的能力分类和自动化的、由LLM驱动的数据生成流水线。该平台集成了22多个基准和30多个模型,揭示了专门的具身模型在目标任务上通常优于通用模型,并确定了物体和空间感知是关键的性能瓶颈。
引言
具身智能(Embodied AI)通过使AI代理能够在物理环境中感知、推理和交互,代表着实现通用人工智能(AGI)的关键途径。虽然大型基础模型在文本和视觉方面展示了卓越的能力,但具身智能领域面临着阻碍其进展的重大挑战。来自包括天津大学、华为诺亚方舟实验室、上海交通大学和伦敦大学学院等众多知名机构的研究人员,共同开发了Embodied Arena——一个旨在解决这些根本挑战的综合评估平台。
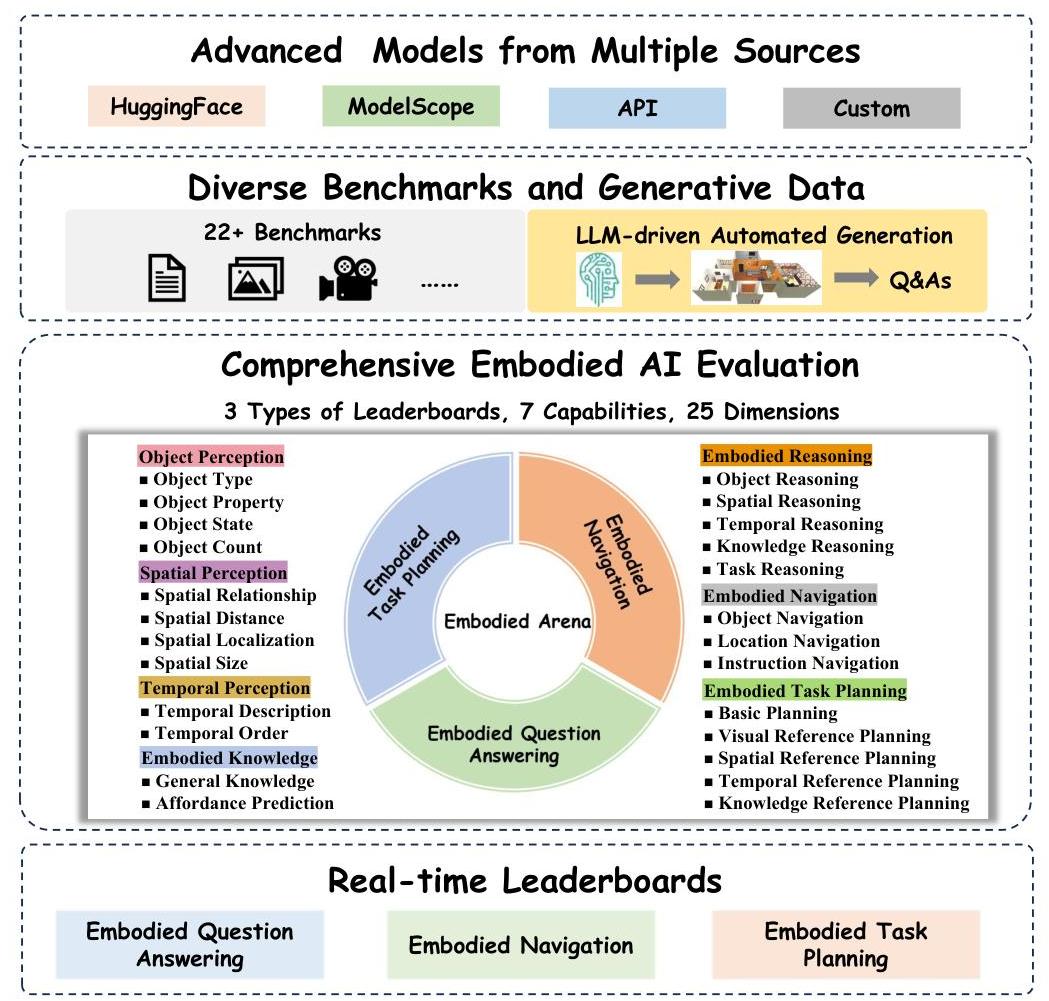
图1:Embodied Arena平台概述,展示了其具身AI评估的综合方法,包括支持多种模型来源、具有自动生成功能的各种基准、跨7项核心能力和25个维度的能力导向评估,以及三大主要任务的实时排行榜。
该平台解决了阻碍具身AI发展的三大关键障碍:核心能力缺乏系统性理解、统一评估标准的缺失以及可扩展数据获取的瓶颈。通过提供标准化的评估基础设施、系统的能力分类法和自动化数据生成管道,Embodied Arena旨在加速具身智能研究的进展。
系统能力分类法
Embodied Arena的基础是一个层次化的分类法,它将具身能力系统地组织成七个核心领域,涵盖25个细粒度维度。该分类法借鉴了认知心理学、人类经验和现有具身任务,为理解具身代理需要实现什么提供了全面的框架。
该分类法按三个递增的复杂性级别构建:
感知层面包含感知和理解环境的基本能力:
- 物体感知:包括物体类型识别、属性理解、状态评估和计数
- 空间感知:涵盖空间关系、距离估计、定位和大小理解
- 时间感知:涉及时间描述和序列排序
推理层面在感知能力的基础上,实现更高阶的认知过程:
- 物体推理:对物体的深入理解和推断
- 空间推理:复杂的空间关系分析和推断
- 时间推理:理解时间序列和因果关系
- 知识推理:将通用知识应用于具身情境
- 任务推理:为完成任务进行规划和决策
任务执行层面代表自主行动的最高级别能力:
- 具身导航:包括基于物体、基于位置和遵循指令的导航
- 具身任务规划:涵盖从基本规划到复杂基于引用的规划场景
这个系统性框架允许研究人员将现有基准映射到特定的能力维度,并识别当前评估实践中的空白。作者通过成功将22个不同的现有具身基准映射到这些能力维度,证明了该分类法的全面性。
统一评估系统
Embodied Arena的核心创新在于其统一评估系统,该系统对不同基准和模型进行标准化评估。该平台目前集成了超过22个高质量基准,涵盖三大主要具身任务:具身问答(2D和3D)、具身导航和具身任务规划,总计超过64,000个任务实例。
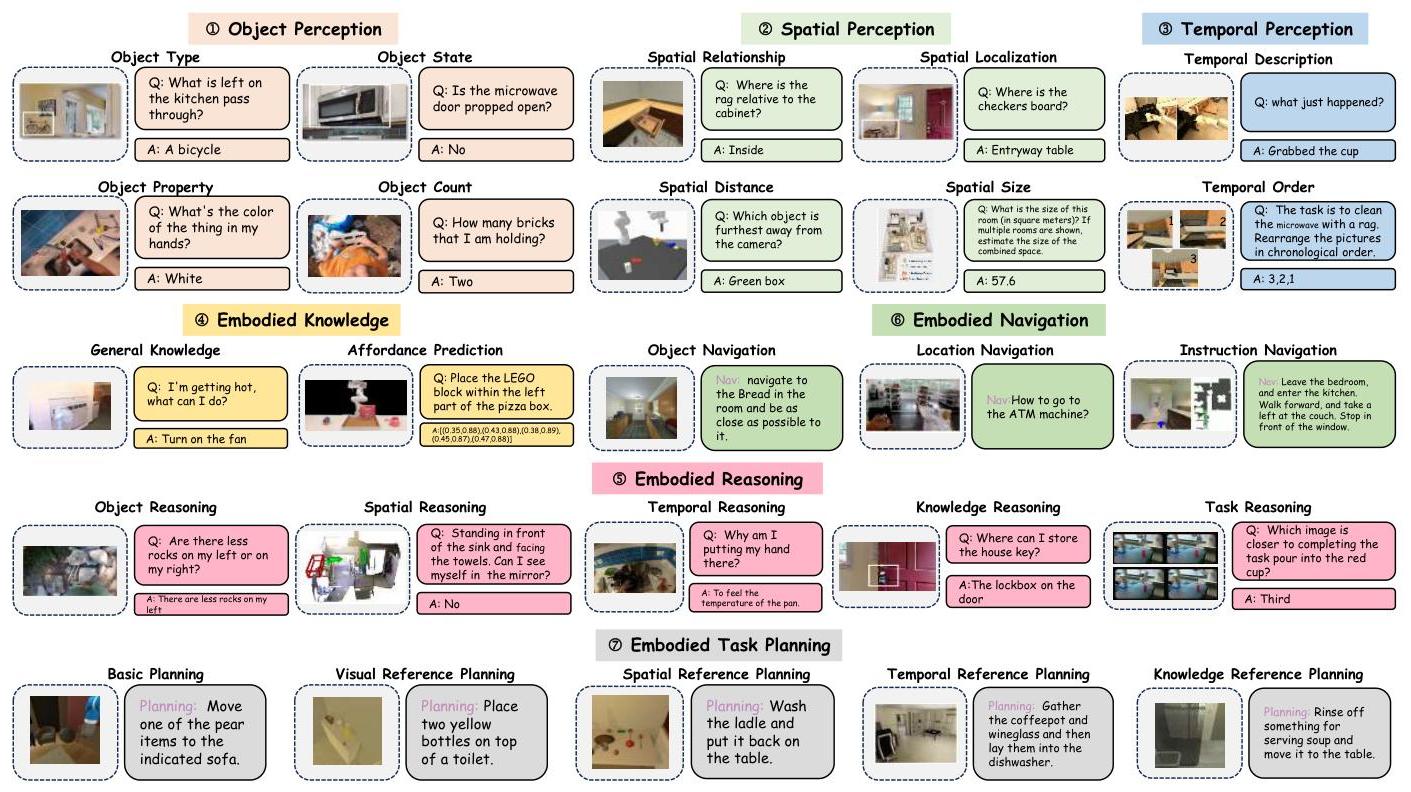
图2:具身竞技场分类体系中七项核心能力示例,展示了从物体感知、空间推理到复杂任务规划场景的各种任务。
该评估系统支持来自20多家机构的30多种先进模型,包括通用多模态大型语言模型(来自OpenAI、Google DeepMind、阿里巴巴、字节跳动等)和专用具身AI模型。该平台通过基于API、基于参数和自定义接口提供灵活的模型集成,以适应开源和商业模型。
评估方法采用针对每个领域量身定制的任务特定指标:
- 对于具身问答:精确匹配的准确性,以及模糊匹配指标(CIDEr、BLEU、ROUGE、MRA)和基于LLM的自然语言生成评估。
- 对于具身导航:成功率和路径长度加权成功率(SPL),用于衡量有效性和效率。
- 对于具身任务规划:任务完成成功率作为主要指标。
该平台从两个互补的角度生成综合排行榜:基准视图显示模型在各个基准上的排名,能力视图显示模型在七项核心能力上的表现。这些排行榜每月更新,并采用透明的提交政策,以确保公平性和社区参与。
自动化数据生成管道
具身竞技场的一项重要贡献是其LLM驱动的自动化数据生成框架,该框架解决了手动基准创建的可扩展性限制。该系统通过两个集成模块协同工作,以创建多样化、高质量的评估数据。
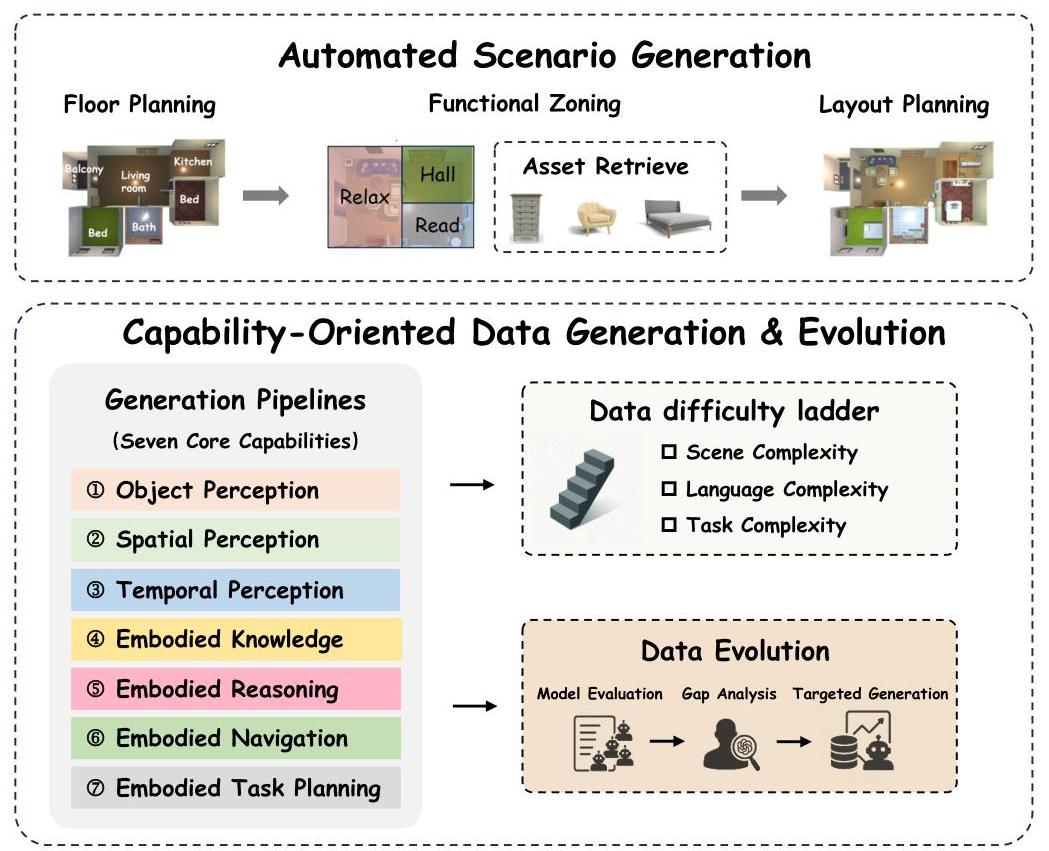
图3:自动化数据生成管道,展示了通过平面规划、功能分区和布局规划进行的场景生成,以及通过难度阶梯和演化机制进行的能力导向数据生成。
自动化场景生成通过分层过程构建逼真的多房间室内环境:
- 平面规划:利用建筑原则定义房间类型和空间关系
- 功能分区:根据常见使用模式将房间划分为特定活动区域
- 布局规划:用适当的资产填充区域并优化空间布局
大型语言模型和视觉语言模型指导这些决策,以确保语义连贯性和常识有效性。该系统生成高保真渲染,包括RGB图像、深度图和结构化对象图,并采用领域随机化技术确保环境多样性。
能力导向数据生成通过程序化管道为七项核心能力中的每一项创建有针对性的数据集。这些管道定义任务模板,加载适当的资产,执行脚本化程序,并利用模拟器访问来生成真实标注。
该系统实现了难度阶梯方法,沿三个维度生成数据:
- 场景复杂度:从简单的单房间环境到复杂的多房间场景
- 语言复杂度:从基本指令到复杂的多步骤命令
- 任务复杂度:从简单的物体识别到复杂的推理和规划任务
一项关键创新是数据演化机制,它持续分析模型性能差距,自主生成新的、有针对性的挑战。这可以防止模型过度拟合静态基准,并确保评估集随着该领域的发展而保持全面和演进。
主要发现和见解
通过具身竞技场(Embodied Arena)进行的综合评估揭示了九项重要发现,阐明了具身人工智能研究的当前状况和未来方向:
模型性能模式:虽然大规模闭源通用模型由于其规模实现了强大的整体性能,但在控制模型大小时,专门的具身模型在特定领域基准测试上始终优于通用模型。这凸显了高质量具身数据集和有针对性微调的有效性。
基准限制:模型在不同基准测试中表现出显著的性能差异,表明单个基准测试不足且可能存在偏见。这表明普遍存在对基准特定模式的过度拟合,而非通用具身能力的开发。
能力依赖性:评估揭示了基础能力和高级能力之间存在强烈的依赖关系,其中物体感知和空间感知被认为是主要瓶颈。具有更强基础感知能力的模型在复杂推理任务上表现出显著更好的性能。
扩展行为:与传统语言模型不同,具身任务尚未出现一致的扩展定律。虽然增加参数可以在局部提高性能,但这种趋势在不同模型和能力之间不一致,表明需要更复杂的架构设计和训练方法。
强化微调优势:采用强化学习方法(RFT)进行微调的模型在各种基准测试中始终取得显著的性能改进,并常常创造新的最先进结果。RFT似乎能使模型更好地激活并将基础感知能力组合成复杂的推理技能。
意义和影响
具身竞技场(Embodied Arena)是一项基础性基础设施贡献,解决了具身人工智能研究中的关键空白。通过提供第一个全面的统一评估平台,它实现了客观的跨模型比较,并有助于识别阻碍进展的特定能力差距。
该平台的系统能力分类学提供了清晰的研究目标,将重点从孤立的任务性能转向整体能力发展。自动化数据生成管道解决了可扩展数据采集的长期挑战,提供了一种持续评估演进的机制,防止过度拟合,并鼓励开发更具通用性的具身智能体。
开放的评估访问和对社区贡献的支持营造了一个协作生态系统,鼓励可复现性和广泛参与。通过与大型语言模型开发的成功范式进行类比,具身竞技场有助于弥合传统人工智能与具身智能之间的鸿沟,为该领域的成熟和有效扩展提供了必要的脚手架。
这一综合平台使具身人工智能社区能够系统地朝着能够在物理环境中有效感知、推理和行动的真正智能代理迈进,最终通过具身理解推进通用人工智能的目标。

技术共进,成长同行——讯飞AI开发者社区
更多推荐

 12
12 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)