
算法岗常考面试题:transformer中的attention为什么要除以根号d_k
我们知道attention其实有很多种形式,而transformer论文中的attention是Scaled Dot-Porduct Attention,如下图所示:那么问题来了,这里的attention为什么要做除以根号d_k呢?一句话概括就是:如果不对softmax的输入做缩放,那么万一输入的数量级很大,softmax的梯度就会趋向于0,导致梯度消失。
·
我们知道attention其实有很多种形式,而transformer论文中的attention是Scaled Dot-Porduct Attention,如下图所示:
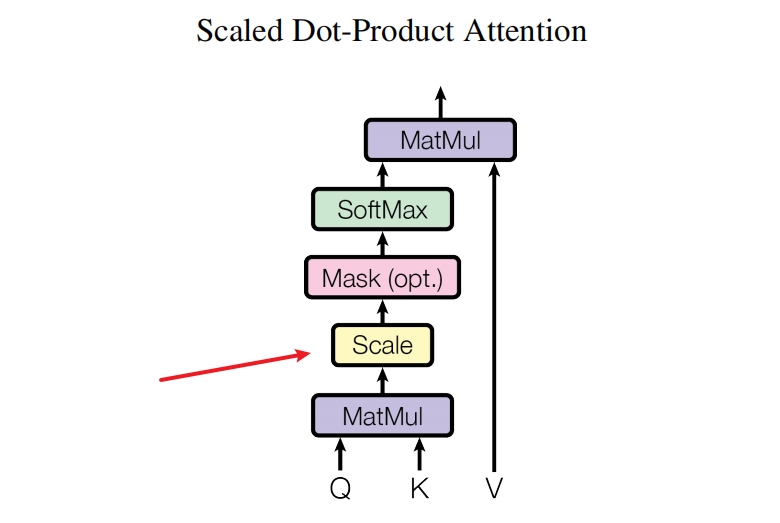
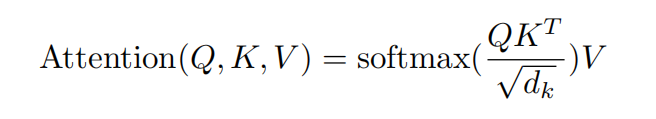
那么问题来了,这里的attention为什么要做除以根号d_k呢?
一句话概括就是:如果不对softmax的输入做缩放,那么万一输入的数量级很大,softmax的梯度就会趋向于0,导致梯度消失。

证明
Attention is All You Need并没有对下面的话进行证明:
证明:
你想现在scaled后,q*k的均值为0,方差为1,那自然数值不会很大了。
(原来的方差是d_k,d_k如果很大,比如256,那softmax就容易出现梯度消失)
相关资料

技术共进,成长同行——讯飞AI开发者社区
更多推荐

 11
11 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)