
python中文文本情感分析
这里写自定义目录标题导语导语要做一个项目要用到中文文本情感分析,查找了多种资料,在网上看了很多博客后,终于完成,对自己帮助最大的两篇博客为【python机器学习】中文情感分析和 [Python开发 之 Sklearn的模型 和 CountVectorizer 、Transformer 保存 和 使用](Python开发 之 Sklearn的模型 和 CountVectorizer 、Transfo
·
python中文文本情感分析
导语
要做一个项目要用到中文文本情感分析,查找了多种资料,在网上看了很多博客后,终于完成,对自己帮助最大的两篇博客为【python机器学习】中文情感分析和 Python开发之Sklearn的模型和CountVectorizer Transformer保存和使用中模型的加载与保存,之后又在之前手写数字识别中采用svm、决策树、朴素贝叶斯、knn等算法分别训练模型,采用了data1.csv作为数据集
训练模型保存并测试正确率
import pickle
from sklearn import svm
# 离散型朴素贝叶斯
from sklearn.naive_bayes import MultinomialNB
import os
import joblib
import jieba
import numpy as np
import pandas as pd
import jieba
from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier
from snownlp import SnowNLP
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import CountVectorizer
def make_label(star):
if star > 3:
return 1
else:
return 0
def snow_result(comment):
s = SnowNLP(comment)
if s.sentiments >= 0.5:
return 1
else:
return 0
# jieba分词
def chinese_word_cut(mytext):
return " ".join(jieba.cut(mytext))
def get_custom_stopwords(stop_words_file):
with open(stop_words_file, 'r', encoding='UTF-8') as f:
stopwords = f.read()
stopwords_list = stopwords.split('\n')
custom_stopwords_list = [i for i in stopwords_list]
return custom_stopwords_list
def nb_mode_train(x_train,y_train,Vectorizer):
nb = MultinomialNB()
nb.fit(x_train, y_train)
# 创建文件目录
dirs = 'testModel'
if not os.path.exists(dirs):
os.makedirs(dirs)
# 保存模型
joblib.dump(nb, dirs + '/nb.pkl')
feature_path = 'testFeature'
if not os.path.exists(feature_path):
os.makedirs(feature_path)
feature_path = feature_path + '/nb.pkl'
with open(feature_path, 'wb') as fw:
pickle.dump(Vectorizer.vocabulary_, fw)
return nb
# svm训练模型
def svm_model_train(x_train,y_train,Vectorizer):
svm_model = svm.LinearSVC()
svm_model.fit(x_train, y_train)
# 创建文件目录
dirs = 'testModel'
if not os.path.exists(dirs):
os.makedirs(dirs)
# 保存模型
joblib.dump(svm_model, dirs + '/svm_model.pkl')
feature_path = 'testFeature'
if not os.path.exists(feature_path):
os.makedirs(feature_path)
feature_path = feature_path + '/svm_model.pkl'
with open(feature_path, 'wb') as fw:
pickle.dump(Vectorizer.vocabulary_, fw)
return svm_model
# 决策树算法训练模型
def tree_model_train(x_train,y_train,Vectorizer):
tree_model = DecisionTreeClassifier(criterion="entropy")
tree_model.fit(x_train, y_train)
# 创建文件目录
dirs = 'testModel'
if not os.path.exists(dirs):
os.makedirs(dirs)
# 保存模型
joblib.dump(tree_model, dirs + '/tree_model.pkl')
feature_path = 'testFeature'
if not os.path.exists(feature_path):
os.makedirs(feature_path)
feature_path = feature_path + '/tree_model.pkl'
with open(feature_path, 'wb') as fw:
pickle.dump(Vectorizer.vocabulary_, fw)
return tree_model
# Knn算法训练模型
def knn_model_train(x_train,y_train,Vectorizer):
knn_model = KNeighborsClassifier(n_neighbors=3)
knn_model.fit(x_train, y_train)
# 创建文件目录
dirs = 'testModel'
if not os.path.exists(dirs):
os.makedirs(dirs)
# 保存模型
joblib.dump(knn_model, dirs + '/knn_model.pkl')
feature_path = 'testFeature'
if not os.path.exists(feature_path):
os.makedirs(feature_path)
feature_path = feature_path + '/knn_model.pkl'
with open(feature_path, 'wb') as fw:
pickle.dump(Vectorizer.vocabulary_, fw)
return knn_model
if __name__ == '__main__':
data = pd.read_csv('data1.csv')
data['sentiment'] = data.star.apply(make_label)
data['snlp_result'] = data.comment.apply(snow_result)
counts = 0
for i in range(len(data)):
if data.iloc[i, 2] == data.iloc[i, 3]:
counts += 1
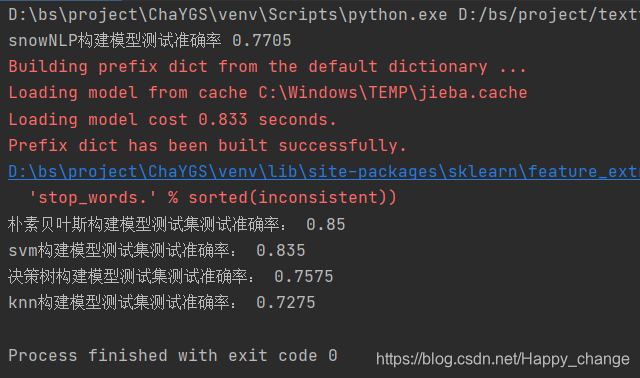
print("snowNLP构建模型测试准确率",counts / len(data))
# jieba分词
data['cut_comment'] = data.comment.apply(chinese_word_cut)
# 划分数据集
X = data['cut_comment']
y = data.sentiment
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=19113122)
# 设置停用词表
stop_words_file = '哈工大停用词表.txt'
stopwords = get_custom_stopwords(stop_words_file)
# print(stopwords)
Vectorizer = CountVectorizer(max_df=0.8,
min_df=3,
token_pattern=u'(?u)\\b[^\\d\\W]\\w+\\b',
stop_words=frozenset(stopwords))
test = pd.DataFrame(Vectorizer.fit_transform(X_train).toarray(),
columns=Vectorizer.get_feature_names())
X_train_vect = Vectorizer.fit_transform(X_train)
X_test_vect = Vectorizer.transform(X_test)
# 训练模型并保存训练模型和特征
nb = nb_mode_train(X_train_vect,y_train,Vectorizer)
z = nb.predict(X_test_vect)
print('朴素贝叶斯构建模型测试集测试准确率:', np.sum(z == y_test) / z.size)
#train_score = nb.score(X_train_vect, y_train)
#print('朴树贝叶斯训练集测试正确率',train_score)
#print('朴树贝叶斯测试集测试正确率',nb.score(X_test_vect, y_test))
# 训练模型并保存训练模型和特征
svm_model = svm_model_train(X_train_vect, y_train, Vectorizer)
z = svm_model.predict(X_test_vect)
print('svm构建模型测试集测试准确率:', np.sum(z == y_test) / z.size)
# 训练模型并保存训练模型和特征
tree_model = tree_model_train(X_train_vect, y_train, Vectorizer)
z = tree_model.predict(X_test_vect)
print('决策树构建模型测试集测试准确率:', np.sum(z == y_test) / z.size)
# 训练模型并保存训练模型和特征
knn_model = knn_model_train(X_train_vect, y_train, Vectorizer)
z = knn_model.predict(X_test_vect)
print('knn构建模型测试集测试准确率:', np.sum(z == y_test) / z.size)
使用保存的模型
import pickle
import joblib
import jieba
from sklearn.feature_extraction.text import CountVectorizer
# jieba分词
def chinese_word_cut(mytext):
return " ".join(jieba.cut(mytext))
def get_custom_stopwords(stop_words_file):
with open(stop_words_file, 'r', encoding='UTF-8') as f:
stopwords = f.read()
stopwords_list = stopwords.split('\n')
custom_stopwords_list = [i for i in stopwords_list]
return custom_stopwords_list
# 处理文本数据
def content_handler(content,Vectorizer):
content = chinese_word_cut(content)
content = [content]
content_ver = Vectorizer.transform(content)
return content_ver
# 使用模型
def useModel(model_name,feature_name,content):
dirs = 'testModel'
nb = joblib.load(dirs + '/' +model_name)
features = 'testFeature'
feature_path = features + '/' +feature_name
Vectorizer = CountVectorizer(decode_error="replace", vocabulary=pickle.load(open(feature_path, "rb")))
return nb,content_handler(content,Vectorizer)
if __name__ == '__main__':
content = '开心有时也很容易啊,比如刚到车站车就来了,随机播放正好是最近喜欢的歌,还有今天的风真舒服。'
nb,content_vec = useModel('nb.pkl','nb.pkl',content)
result = nb.predict(content_vec)
print(result)
print('___________________')
print("朴素贝叶斯")
print(float(nb.predict_proba(content_vec)[:, 1]))

技术共进,成长同行——讯飞AI开发者社区
更多推荐
 1
1 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)