
[技术选型] 开源大数据OLAP引擎
文章目录1.开源OLAP综述2.开源数仓解决方案1.开源OLAP综述如今的开源数据引擎多种多样,不同种类的引擎满足了我们不同的需求。现在ROLAP计算存储一体的数据仓库主要有三种,即StarRocks(DorisDB),ClickHouse和Apache Doris。应用最广的数据查询系统主要有Druid,Kylin和HBase。MPP引擎主要有Trino,PrestoDB和Impala。这些引擎
文章目录
1.开源OLAP综述

如今的开源数据引擎多种多样,不同种类的引擎满足了我们不同的需求。现在ROLAP计算存储一体的数据仓库主要有三种,即StarRocks(DorisDB),ClickHouse和Apache Doris。应用最广的数据查询系统主要有Druid,Kylin和HBase。MPP引擎主要有Trino,PrestoDB和Impala。这些引擎在行业内有着广泛的应用。
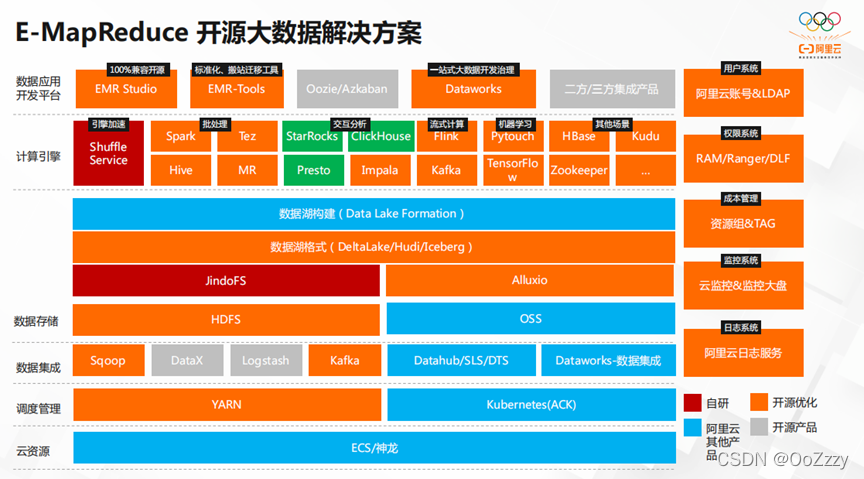
在云资源层,主要有ECS。在存储层的JindoFS提供了以OSS为基底的Hadoop接口,不但节约了成本,而且提升了整体的扩展性。数据湖格式有效解决了数据统一管理的难题。其次在计算引擎方面,它具有批处理,流式计算,机器学习和引擎加速等能力。
2.开源数仓解决方案
数据以及数仓的解决方案。
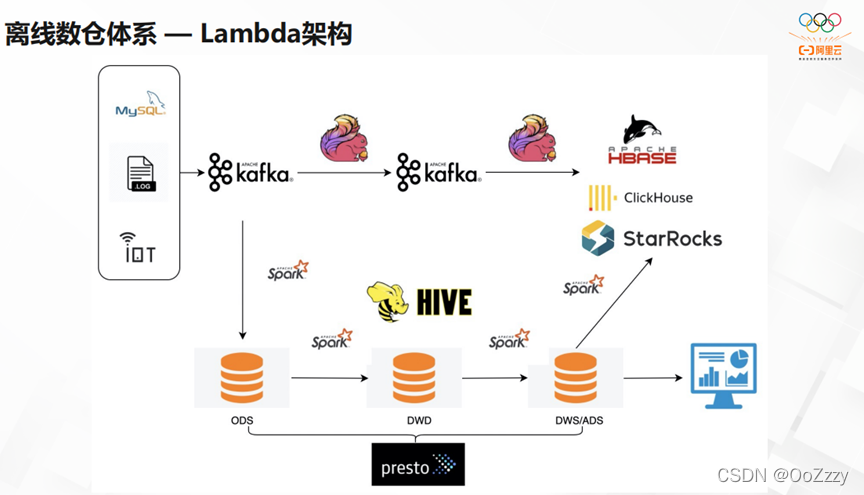
目前,大家应用最多的离线数仓体系是Lambda架构。该架构主要分为两个部分。
- 第一部分,在实时方面我们从CDC,ORTP的数据源开始,进行行为数据分析,然后通过Kafka,Flink进行加工。让数据在线系统,可以直接调用API,提升点查效率。其次,当所有聚合的数都导入Olap系统时,运营人员可以快速用它,实现自己新的想法,提升工作效率。
- 第二部分,在离线方面当需要长久保存数据时,大家都会使用hive。如果没有增量数据库格式,大家一般通过insert overwrite,在detail上做一些数据集市。除此之外,我们通过离线t+1的方式,实现离线数仓的实时数据订正。因为实时数据一般得出的是近似值,离线数据得到的是准确值。
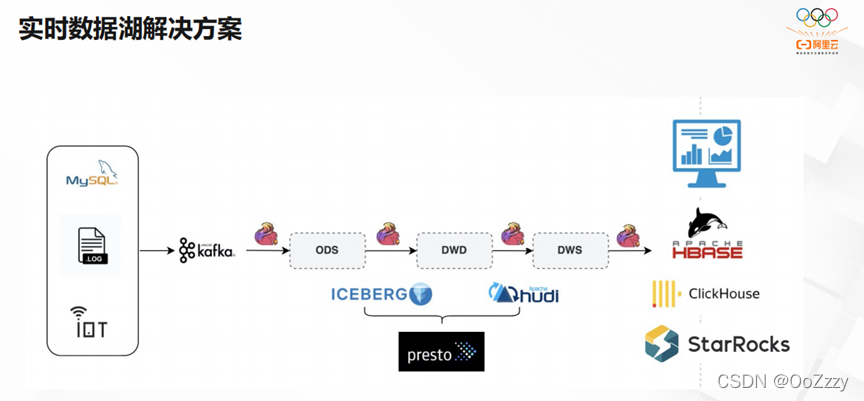
3. 第三部分,实时数据湖的解决方案,其数据量在PB+级别。我们希望统一离线和实时数仓,用一套代码构建业务。数据湖的数据存储在OSS/HDFS,由于我们的部分业务有Upsert变更需求,所以我们希望建设分钟级到小时级的数仓。能够将最热的数据导入StarRocks/CK,OLAP的查询时长保证在500毫秒到2秒之间。与此同时,我们利用Presto查询Hudi/Iceberg/Delta时,其速率能够保证在5秒至30秒之间。
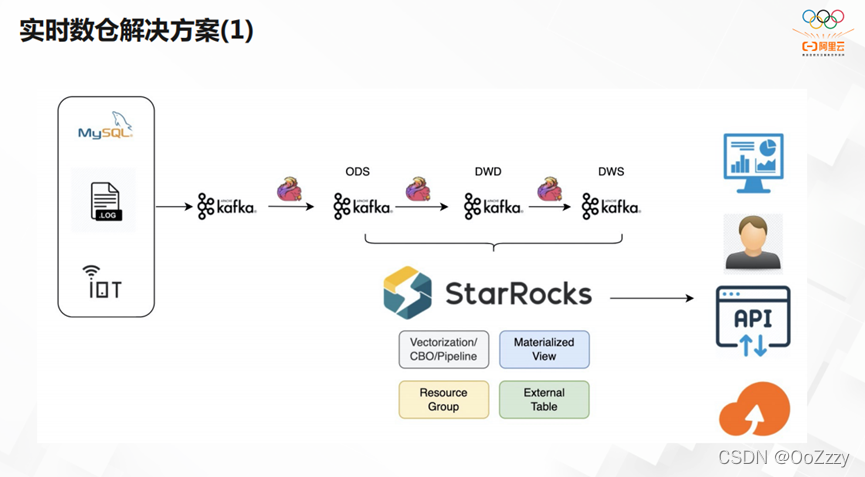
上图是比较传统的实时数仓方案。当每天增量数据达到10TB+,我们希望直接以单软件构建业务底座,让数据先存储在CK/StarRocks,让冷数据转存到OSS。不必再运维Hadoop的庞大体系,极大简化运维操作,可以媲美全托管。
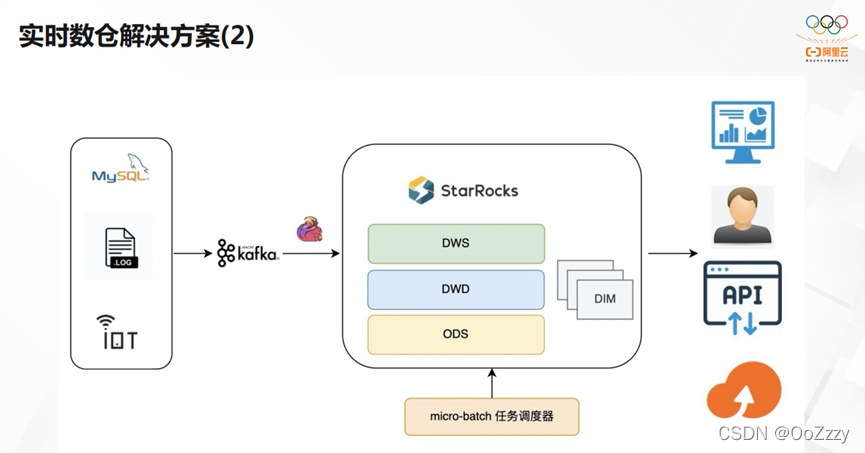
第二种实时数仓的解决方案,我们通过micro-batch任务调度器去处理DWS,DWD和ODS。其实时性非常强,极大简化了开发效率,数据的一致性最高。后续我们将推出存算分离方案,用OSS存储海量数据,用Cache加速热数据。

技术共进,成长同行——讯飞AI开发者社区
更多推荐


 0
0 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)