
目标检测算法——SSD
声明:基本参考搬运自https://zhuanlan.zhihu.com/p/33544892,该博客写的详略得当,重点突出。本文仅做格式整理,自己留存备份。其中也有些许自己添加的理解和图片。1、主要贡献SSD在Yolo的基础上主要改进了三点:多尺度特征图,利用卷积进行检测,设置先验框。这使得SSD在准确度上比Yolo更好,而且对于小目标检测效果也相对好一点。2、主要思路如上图第一个图,对比YOL
声明:基本参考搬运自https://zhuanlan.zhihu.com/p/33544892,该博客写的详略得当,重点突出。本文仅做格式整理,自己留存备份。其中也有些许自己添加的理解和图片。由于csdn不支持cvg格式图片,一部分文本以图片截图粘贴,如有需要参考上述链接或私信我。
1、主要贡献
SSD在Yolo的基础上主要改进了三点:多尺度特征图,利用卷积进行检测,设置先验框。这使得SSD在准确度上比Yolo更好,而且对于小目标检测效果也相对好一点。
2、主要思路
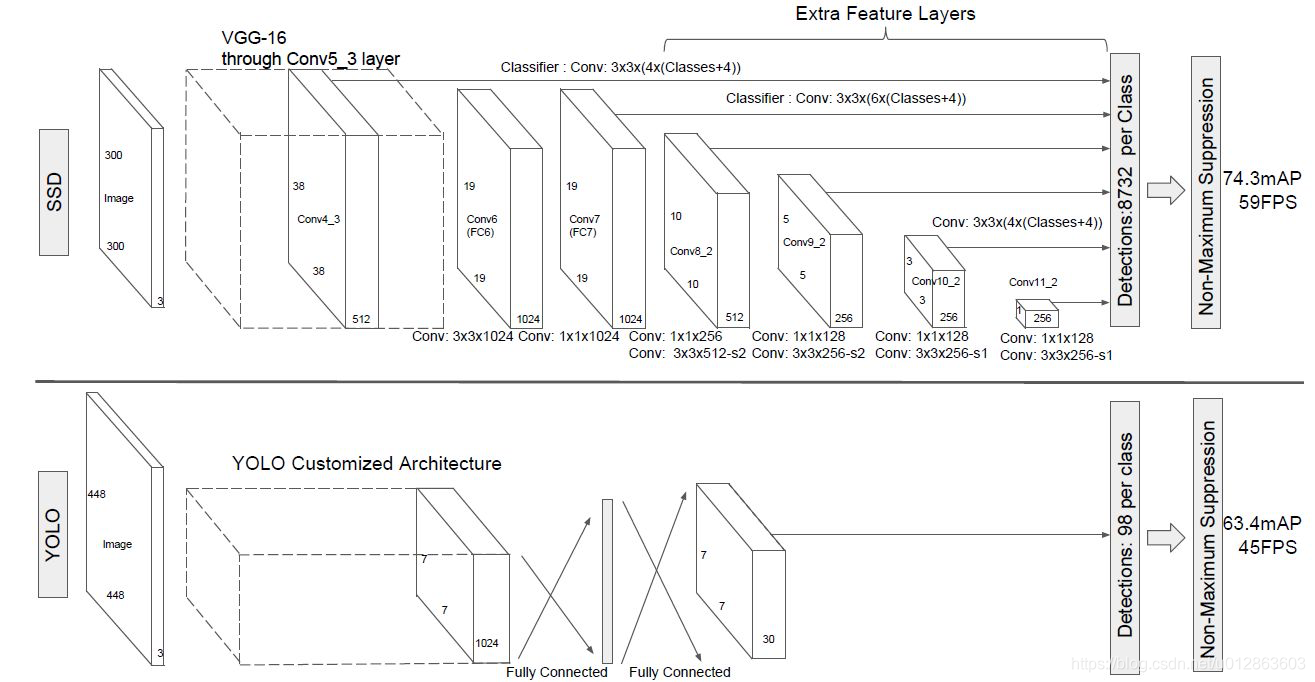
如上图第一个图,对比YOLO,主要是增加了多尺度的预测,每个尺度又增加了先验框,去除了全连接层替换成卷几层,保留了空间位置信息,最后输出8732个结果,然后进行loss回传(训练阶段),或者然后进行置信度阈值过滤+NMS(测试阶段)。
3、具体细节
1)input
输入尺寸:
由于去掉了全连接层,不用再限制模型的输入,SSD常见的尺寸有300*300,512*512.
预处理:
采用数据扩增(Data Augmentation)可以提升SSD的性能,主要采用的技术有水平翻转(horizontal flip),随机裁剪加颜色扭曲(random crop & color distortion),随机采集块域(Randomly sample a patch)(获取小目标训练样本,当然这是古老的技术,现在可以使用mosaic技术),如下图所示:


2)backbone
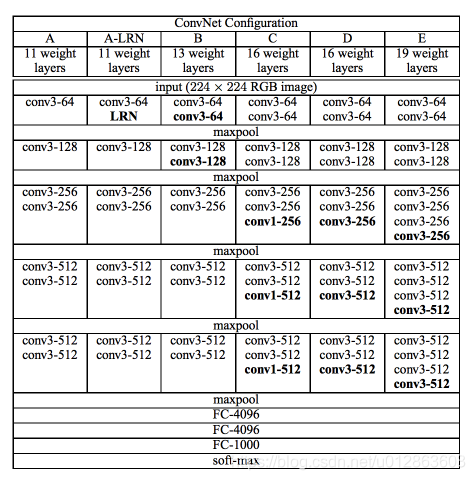
backbone采用了VGG16。

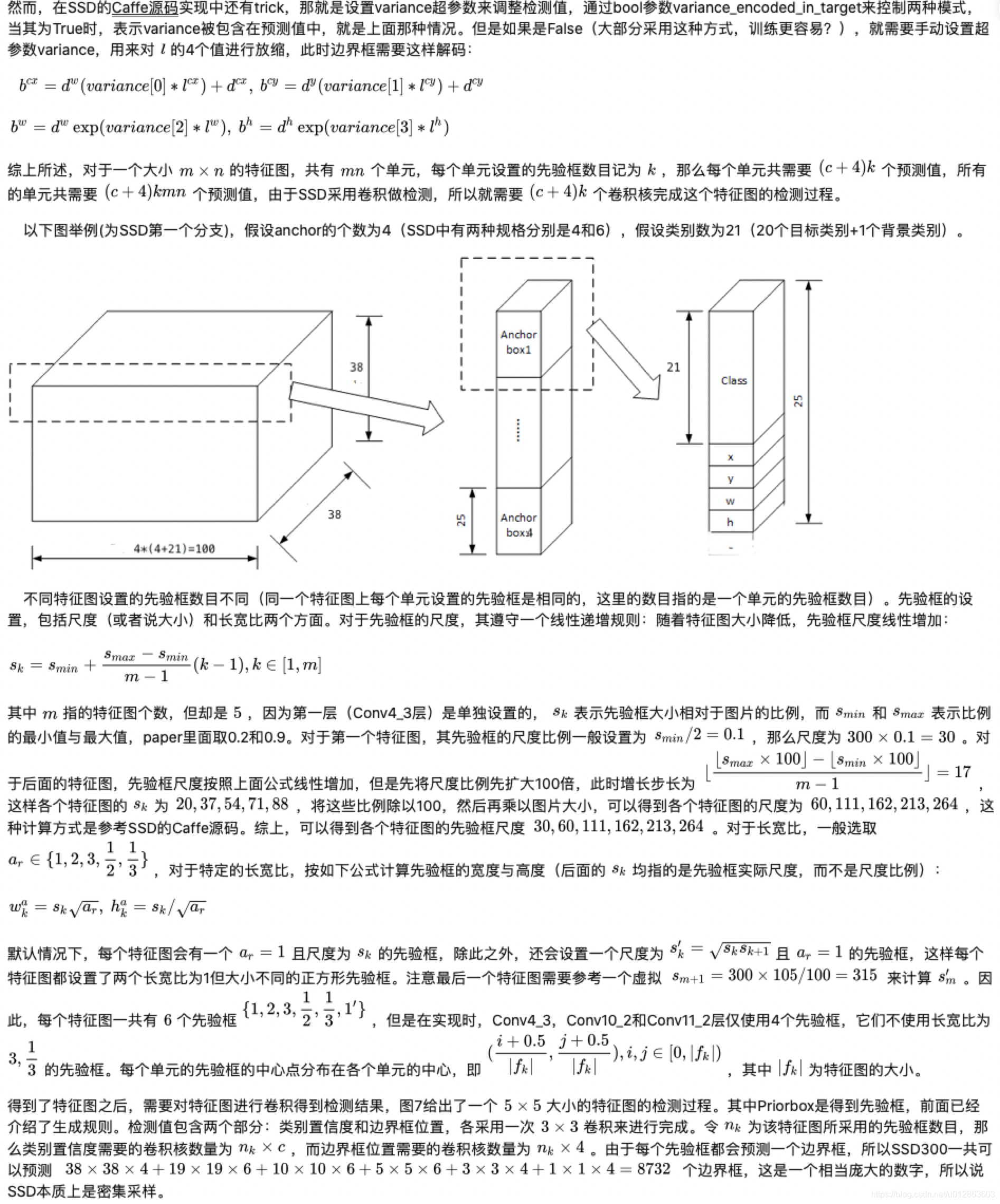
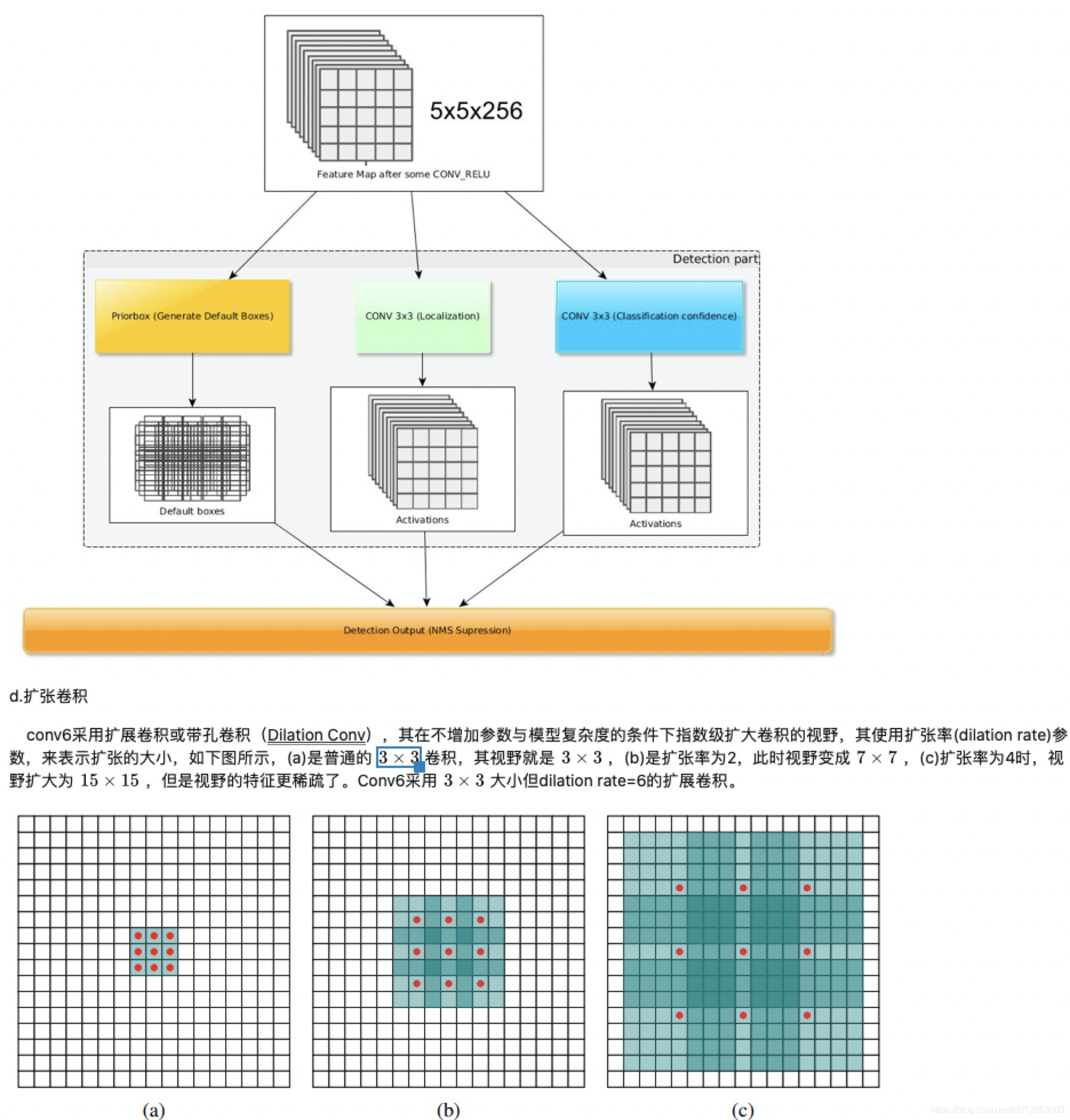


5)trics
多尺度特征图、卷积层检测、先验框、扩张卷积、GT与先验框匹配规则、包含困难样本挖掘
6)inference
预测过程比较简单,对于每个预测框,首先根据类别置信度确定其类别(置信度最大者)与置信度值,并过滤掉属于背景的预测框。然后根据置信度阈值(如0.5)过滤掉阈值较低的预测框。对于留下的预测框进行解码,根据先验框得到其真实的位置参数(解码后一般还需要做clip,防止预测框位置超出图片)。解码之后,一般需要根据置信度进行降序排列,然后仅保留top-k(如400)个预测框。最后就是进行NMS算法,过滤掉那些重叠度较大的预测框。最后剩余的预测框就是检测结果了。
4、结果
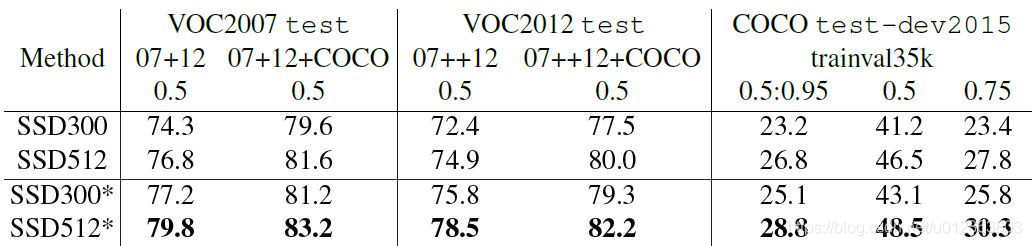
首先整体看一下SSD在VOC2007,VOC2012及COCO数据集上的性能,如下表所示。相比之下,SSD512的性能会更好一些。加*的表示使用了image expansion data augmentation(通过zoom out来创造小的训练样本)技巧来提升SSD在小目标上的检测效果,所以性能会有所提升。
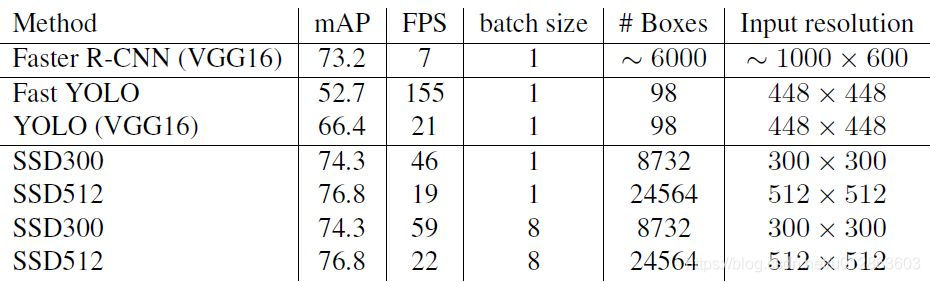
SSD与其它检测算法的对比结果(在VOC2007数据集)如下表所示,基本可以看到,SSD与Faster R-CNN有同样的准确度,并且与Yolo具有同样较快地检测速度。
文章还对SSD的各个trick做了更为细致的分析,下表为不同的trick组合对SSD的性能影响,从表中可以得出如下结论:
-
数据扩增技术很重要,对于mAP的提升很大;
-
使用不同长宽比的先验框可以得到更好的结果;

同样的,采用多尺度的特征图用于检测也是至关重要的,这可以从下表中看出:

参考链接:
1、https://zhuanlan.zhihu.com/p/33544892
2、https://www.pyimagesearch.com/2017/03/20/imagenet-vggnet-resnet-inception-xception-keras/

技术共进,成长同行——讯飞AI开发者社区
更多推荐


 9
9 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)