
机器学习笔记(二)常用分析工具
机器学习常用的不仅仅是各种模型,还有数据分析、数据处理和可视化等,python、R等语言也提供了很多有用的工具包。一、pandaspandas在数据分析中的作用无需多数。下文的pd表示pandas库,df表示实际中的DataFrame实例。1. df.pivotpivot是pandas中的数据透视表操作,实际上就是针对某列的行转列操作,参数如下:pivot(self, index=None, co
机器学习常用的不仅仅是各种模型,还有数据分析、数据处理和可视化等,python、R等语言也提供了很多有用的工具包。本文的目的主要是记录一些python中使用频率不是非常高,但是又非常好用的工具包,首先,给大家分享一个python学习网站。
一、pandas
pandas在数据分析中的作用无需多数。下文的pd表示pandas库,df表示实际中的DataFrame实例。
1. df.pivot
pivot是pandas中的数据透视表操作,实际上就是针对某列的行转列操作,参数如下:
pivot(self, index=None, columns=None, values=None)index是重塑的新表的索引名称是什么,也是我们关心的主键;columns是重塑的新表的列名称是什么,哪些行字段会被转换为列字段;values就是生成新列的值应该是多少,也就是新表的字段值。看下面demo操作结果:

pivot_df = data_df.pivot(index='userNum', columns='subjectCode', values='score')
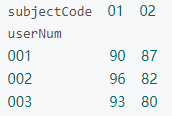
pivot需要保证index+columns不能重复。
2. df.pivot_table
pivot_table(
self,
values=None,
index=None,
columns=None,
aggfunc="mean",
fill_value=None,
margins=False,
dropna=True,
margins_name="All",
observed=False,
)pivot_table基本和pivot一样,不同的是pivot_table可以聚合操作,所以即使index+columns重复也没影响。当aggfunc="count"的时候就和pd.crosstab()一样了。
3. pd.Timestamp
ts = pd.Timestamp("2020-10-16")是pandas中的时间操作,可以通过ts.month (10)、ts.day (16)获取时间值,在index为datetime的dataframe数据中,利用index索引数据会非常方便,如 data[data.index.month==1]。ts + pd.Timedelta可以进行日期加减。另外,pandas中还有一些常用的时间操作函数(类),如pd.datetime("2020-10-16")构造时间类型,pd.date_range(start="2020-10-16",periods="10",freq="12H")构造时间序列,pd.to_datetime时间转换,resample时间采样等。
4. pd.cut
cut用来把一组数据分割成离散的区间.
##参数
cut(
x,
bins,
right: bool = True,
labels=None,
retbins: bool = False,
precision: int = 3,
include_lowest: bool = False,
duplicates: str = "raise",
)
##案例
ages = np.array([1,5,10,40,36,12,58,62,77,89,100,18,20,25,30,32])
#pd.cut(ages, 5, labels=[u"婴儿",u"青年",u"中年",u"壮年",u"老年"])
pd.cut(ages, 5)
##输出
[(0.901, 20.8], (0.901, 20.8], (0.901, 20.8], (20.8, 40.6], (20.8, 40.6], ..., (0.901, 20.8], (0.901, 20.8], (20.8, 40.6], (20.8, 40.6], (20.8, 40.6]]
Length: 16
Categories (5, interval[float64]): [(0.901, 20.8] < (20.8, 40.6] < (40.6, 60.4] < (60.4, 80.2] < (80.2, 100.0]]5. df.isnull()
isnull判断为空的字段,返回二维表格的布尔结果。df.isnull().any(axis=0/1)返回每列/行中是否含有空值。df.fillna(3)填充空值。
6. concat/merge/join
concat/merge/join是pandas中三种不同的拼接操作。pd.concat用来进行直接横向或者纵向拼接,定义如下:
concat(
objs: Union[
Iterable[FrameOrSeriesUnion], Mapping[Optional[Hashable], FrameOrSeriesUnion]
],
axis=0,
join="outer",
ignore_index: bool = False,
keys=None,
levels=None,
names=None,
verify_integrity: bool = False,
sort: bool = False,
copy: bool = True,
)- axis:axis = 0, 表示在水平方向(row)进行连接,axis = 1, 表示在垂直方向(column)进行连接。
- join:outer, 表示index全部需要; inner,表示只取index重合的部分。
import pandas as pd
import numpy as np
from pandas import DataFrame,Series
data1=pd.DataFrame(np.arange(9).reshape(3,3),columns=list('abc'))
data2=pd.DataFrame(np.arange(20,26).reshape(2,3),columns=list('ayz'))
###############################################
data1
index a b c
0 0 1 2
1 3 4 5
2 6 7 8
###############################################
data2
index a y z
0 20 21 22
1 23 24 25
###############################################
pd.concat([data1,data2],axis=0)
index a b c y z
0 0 1.0 2.0 NaN NaN
1 3 4.0 5.0 NaN NaN
2 6 7.0 8.0 NaN NaN
0 20 NaN NaN 21.0 22.0
1 23 NaN NaN 24.0 25.0
###############################################
pd.concat([data1,data2],axis=0,join='inner')
index a
0 0
1 3
2 6
0 20
1 23
###############################################
pd.concat([data1,data2],axis=1)
index a b c a y z
0 0 1 2 20.0 21.0 22.0
1 3 4 5 23.0 24.0 25.0
2 6 7 8 NaN NaN NaN
###############################################
pd.concat([data1,data2],axis=1,join='inner')
index a b c a y z
0 0 1 2 20 21 22
1 3 4 5 23 24 25pd.merge相当于sql中的join操作,也分left join/right join/inner join/outer join
merge(
left,
right,
how: str = "inner",
on=None,
left_on=None,
right_on=None,
left_index: bool = False,
right_index: bool = False,
sort: bool = False,
suffixes=("_x", "_y"),
copy: bool = True,
indicator: bool = False,
validate=None,
)- left与right:合并操作时左右两个不同的df
- how:inner(默认)、outer、left、right——相当于SQL中的连接方式
- on:需要连接的列名,必须是在左右两边都有的列名,相当于sql join 中的on,可以有多个字段。不写默认会找同名字段,如果有多个同名字段,会用多字段关联。
- left_on/right_on:左右关联字段,如果两个表的关联字段名不一样,可以使用该字段分别指定。
- sort:对结果按照on字段排序。
df12 = pd.DataFrame({'key1':['b','b','a','c'],'data1':range(4)})
df12
index key1 data1
0 b 0
1 b 1
2 a 2
3 c 3
###############################################
df22 = pd.DataFrame({'key2':['b','a','b','d'],'data2':range(4)})
df22
index key2 data2
0 b 0
1 a 1
2 b 2
3 d 3
###############################################
pd.merge(df12,df22,left_on='key1',right_on='key2',sort=True)
index key1 data1 key2 data2
0 a 2 a 1
1 b 0 b 0
2 b 0 b 2
3 b 1 b 0
4 b 1 b 2
###############################################
pd.merge(df12,df22,left_on=['key1','data1'],right_on=['key2','data2'])
index key1 data1 key2 data2
0 b 0 b 0df.join
join(self, other, on=None, how="left", lsuffix="", rsuffix="", sort=False)参数的意义与merge方法基本相同,只是join方法默认为左外连接how=’left’,且默认使用索引关联,当两边有相同的列名时,需要指定后缀。建议使用merge处理数据。
left=pd.DataFrame({'key':['foo','bar1'],'val':[1,2]})
index key val
0 foo 1
1 bar1 2
########################################################
right=pd.DataFrame({'key':['foo','bar'],'val':[4,5]})
index key val
0 foo 4
1 bar 5
########################################################
left.join(right.set_index('key'),on='key',lsuffix='_l',rsuffix='_r')
index key val_l val_r
0 foo 1 4.0
1 bar1 2 NaN7. df.groupby
groupby是DataFrame数据类型常用的操作,和sql 中的group by功能也也是大同小异。对于groupby来说,重点往往不是groupby本身,而是跟在后面的操作。groupby得到结果是一个DataFrameGroupBy对象,可以通过 (k, v) 的形式进行迭代遍历,其中 k就是groupby的主键,v就是每个group的子DataFrame。
和sql类似,groupby后常常进行一些聚合操作,常见的有:
| 函数 | 功能 |
| min | 最小值 |
| max | 最大值 |
| sum | 求和 |
| mean | 均值 |
| median | 中位数 |
| std | 标准差 |
| var | 方差 |
| count | 计数 |
实现这些操作的方法就是在groupby后使用agg(也写作aggregate)进行操作。
df.groupby(['UserId']).agg('count').head(5)
df.groupby(['UserId']).count().head(5)
df.groupby('UserId').agg(np.max).head()
df.groupby('Country').agg(lambda x : np.max(x))
df.groupby('UserId').aggregate([np.max, np.min, np.mean]) #支持多种聚合操作
df.groupby('UserId').aggregate({'Age' : [np.max, np.sum]}) #只查看特定字段的多个统计值
df.groupby('UserId')['Age'].aggregate(np.max) #同上
df.groupby('UserId').get_group('1001').aggregate({'Income' : [np.mean, np.sum]}) #只看某个key的统计值
可以看到groupby的操作是非常灵活的,需要注意的是groupby的聚合操作是会忽略空值的,例如count操作,会返回其他所有字段的计数值,并且很可能同一个key值对应的数据不同字段计数值不同,就是因为空值导致的。
此外,groupby后还可以接apply操作进行更加灵活的操作。
参考资料
https://blog.csdn.net/weixin_42782150/article/details/89546357

技术共进,成长同行——讯飞AI开发者社区
更多推荐
 1
1 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)