
大数据项目实战-基于招聘网职位数据的可视化实验教程(五、数据预处理)
/ 配置日志记录器,用于输出日志信息// 创建Hadoop的配置对象// 创建一个Job实例,用于定义和运行MapReduce任务// 设置执行该Job的Jar包// 设置Mapper类,用于处理输入数据// 设置输出键的类型为Text// 设置输出值的类型为NullWritable,表示没有实际的值输出// 添加输入路径,指定HDFS上的文件或目录// 设置输出路径,指定本地文件系统或HDFS上
文章介绍了如何使用Java编写数据清洗程序,包括创建Maven项目,引入Hadoop依赖,定义CleanJob类进行数据处理,如删除特定字符、合并字段,以及创建CleanMain和CleanMapper类来运行MapReduce任务。最后,文章提到了如何打包成jar包并在Hadoop集群上运行,以及通过HDFS查看结果。
一、分析预处理数据
(一)在任意一台虚拟机执行指令“hdfs dfs -cat /JobData/20190807/page1”打 开数据文件,查看部分数据内容。
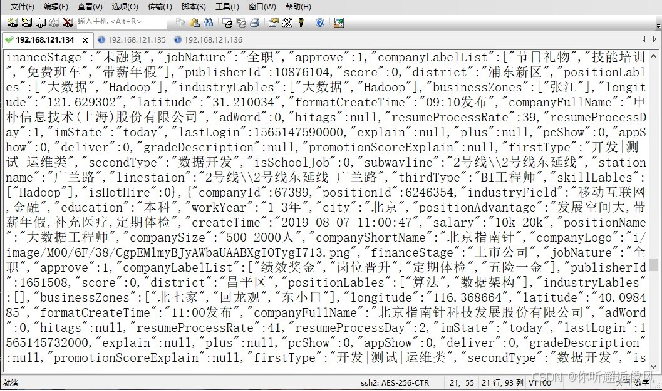
(二)通过JSON格式化工具对数据文件page1的数据内容进行格式化处理,查看储存了职位信息的result字段。

二、设计数据预处理方案
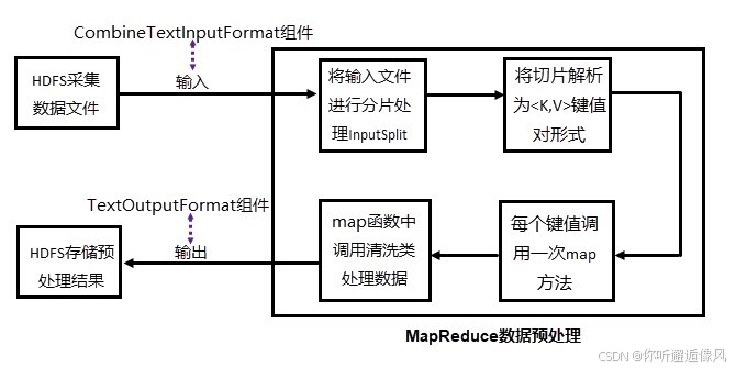
三、实现数据的预处理
(一)数据预处理环境准备
1.新建Maven项目

选择Maven项目
创建简易项目
设置Group Id 和Artifact Id
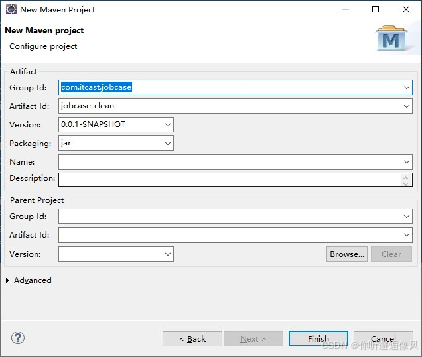
完成Maven项目创建
2.配置pom.xml 文件
打开pom.xml文件,添加与hadoop相关的依赖。
<project>
<!-- 定义项目依赖 -->
<dependencies>
<!-- 引入Hadoop Common库 -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.4</version>
</dependency>
<!-- 引入Hadoop Client库 -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.4</version>
</dependency>
</dependencies>
</project>
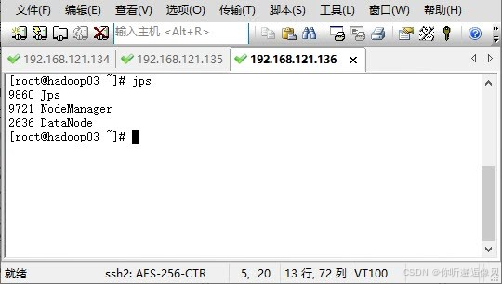
3.启动Hadoop 集群
使用远程工具连接三台服务器Hadoop01、Hadoop02和Hadoop03。在任一服务器节点通过“start-dfs.sh”和“start-yarn.sh” 指令启动Hadoop,通过“jps”命令查看进程启动情况。
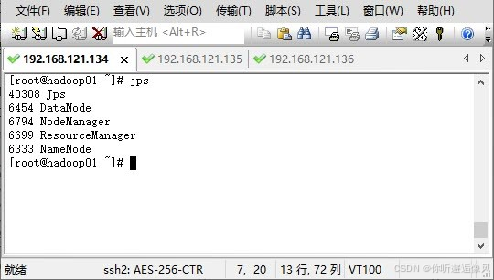
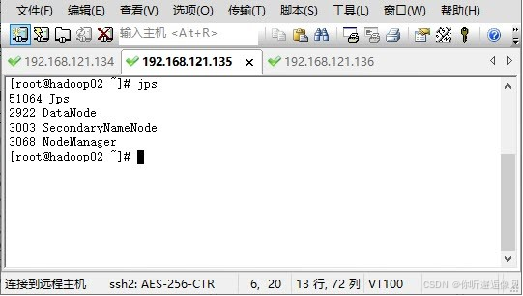
(二)创建数据转换类
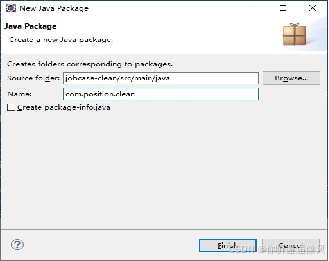
1.新建Package包
2.创建CleanJob类,用于实现对职位信息数据进行转换操作
3.在CleanJob类中添加方法deleteString(),用于对薪资字符串进行处理,即去除薪资中的‘k’字符。
public static String deleteString(String str, char delChar) {
// 创建一个空的 StringBuffer 对象,用于存储处理后的字符串
StringBuffer stringBuffer = new StringBuffer("");
// 遍历输入字符串的每一个字符
for (int i = 0; i < str.length(); i++) {
// 如果当前字符不是要删除的字符,则将其添加到 StringBuffer 中
if (str.charAt(i) != delChar) {
stringBuffer.append(str.charAt(i));
}
}
// 将 StringBuffer 转换为字符串并返回
return stringBuffer.toString();
}
4.在CleanJob类中添加方法mergeString(),用于将companyLabelList字段中的数据内容和positionAdvantage字段中的数据内容进行合并处理,生成新字符串数据(以“-”为分隔符)。
public static String mergeString(String position, JSONArray company) throws JSONException {
String result = "";
if (company.length() != 0) {
for (int i = 0; i < company.length(); i++) {
result += company.get(i) + "-";
}
}
if (!position.isEmpty()) {
String[] positionList = position.split("\\s|;|,|、|,|;|/");
for (String pos : positionList) {
result += pos.replaceAll("[\\pP\\p{Punct}]", "") + "-";
}
}
return result.substring(0, result.length() - 1);
}
5.在CleanJob类中添加方法killResult,用于将技能数据以“-”为分隔符进行分隔,生成新的字符串数据。
public static String killResult(JSONArray killData) throws JSONException {
// 初始化结果字符串为空
String result = "";
// 检查传入的 JSONArray 是否为空
if (killData.length() != 0) {
// 遍历 JSONArray 中的每一个元素
for (int i = 0; i < killData.length(); i++) {
// 将当前元素转换为字符串并追加到结果字符串中,同时加上连字符
result = result + killData.get(i) + "-";
}
// 返回结果字符串,但去掉最后一个多余的连字符
return result.substring(0, result.length() - 1);
} else {
// 如果 JSONArray 为空,则返回字符串 "null"
return "null";
}
}
6.在CleanJob类中添加方法resultToString()将数据文件中 的每一条职位信息数据进行处理 并重新组合成新的字符串形式
public static String resultToString(JSONArray jobdata) throws JSONException {
// 初始化结果字符串为空
String jobResultData = "";
// 遍历传入的 JSONArray 中的每一个元素
for (int i = 0; i < jobdata.length(); i++) {
// 获取当前索引位置的元素并转换为字符串
String everyData = jobdata.get(i).toString();
// 将字符串转换为 JSONObject 对象
JSONObject everyDataJson = new JSONObject(everyData);
// 从 JSONObject 中提取所需的字段
String city = everyDataJson.getString("city");
String salary = everyDataJson.getString("salary");
String positionAdvantage = everyDataJson.getString("positionAdvantage");
JSONArray companyLabelList = everyDataJson.getJSONArray("companyLabelList");
JSONArray skillLables = everyDataJson.getJSONArray("skillLables");
// 调用 deleteString 方法删除 salary 中的 'k' 字符
String salaryNew = deleteString(salary, 'k');
// 调用 mergeString 方法合并 positionAdvantage 和 companyLabelList
String welfare = mergeString(positionAdvantage, companyLabelList);
// 调用 killResult 方法处理 skillLables
String kill = killResult(skillLables);
// 根据是否是最后一个元素决定是否添加换行符
if (i == jobdata.length() - 1) {
jobResultData = jobResultData + city + "," + salaryNew + "," + welfare + "," + kill;
} else {
jobResultData = jobResultData + city + "," + salaryNew + "," + welfare + "," + kill + "\n";
}
}
// 返回最终的结果字符串
return jobResultData;
}
(三)创建实现Map任务的Mapper类
1.创建CleanMapper类,用于实现MapReduce程序的Map方法
2.将创建的CleanMapper类继承Mapper基类,并定义Map程序输入和输出的key和value。
public class CleanMapper extends Mapper<LongWritable, Text, Text, NullWritable>{ }
3.在Mapper类中实现承担主要的处理工作的map()方法
@Override
protected void map(LongWritable key, Text value, Conte xt context)
throws IOException, InterruptedException {
String jobResultData = "";
}
4.数据文件中包含两个字段code和content,前者代表响应状态码,后者 代表响应的内容即爬取的数据内容,,在map()方法中定义获取content字段内容的代码。
String reptileData = value.toString();
String jobData = reptileData.substring(
reptileData.indexOf("=",reptileData.indexOf("=")+1)+1,
reptileData.length()-1);
5.在content字段中的result部分包含职位信息数据,content字段的数据内容为JSON 格式,为了便于从content字段中获取result部分的数据内容,这里通过将content字段的字符串形式转为JSON 对象形式来获取,将获取的result内容传入数据转换类进行处理,处理结果作为Map输出的Key值。
try {
// 将传入的 jobData 字符串转换为 JSONObject 对象
JSONObject contentJson = new JSONObject(jobData);
// 从 contentJson 中提取 "content" 字段的值,并存储在 contentData 变量中
String contentData = contentJson.getString("content");
// 将 contentData 字符串转换为 JSONObject 对象
JSONObject positionResultJson = new JSONObject(contentData);
// 从 positionResultJson 中提取 "positionResult" 字段的值,并存储在 positionResultData 变量中
String positionResultData = positionResultJson.getString("positionResult");
// 将 positionResultData 字符串转换为 JSONObject 对象
JSONObject resultJson = new JSONObject(positionResultData);
// 从 resultJson 中提取 "result" 字段的值,并存储在 resultData 变量中
JSONArray resultData = resultJson.getJSONArray("result");
// 调用 CleanJob 类的 resultToString 方法,将 resultData 转换为字符串格式,并存储在 jobResultData 变量中
jobResultData = CleanJob.resultToString(resultData);
// 将 jobResultData 写入到 Hadoop 的上下文中,作为输出键值对的一部分
context.write(new Text(jobResultData), NullWritable.get());
} catch (JSONException e) {
// 捕获 JSONException 异常,并打印堆栈跟踪信息
e.printStackTrace();
}
(四)创建并执行MapReduce程序
1.创建CleanMain类,用于实现MapReduce程序配置
2.配置MapReduce程序,定义主类、Mapper类、数据输入目录以及结果输出目录等信息。
public class CleanMain {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// 配置日志记录器,用于输出日志信息
BasicConfigurator.configure();
// 创建Hadoop的配置对象
Configuration conf = new Configuration();
// 创建一个Job实例,用于定义和运行MapReduce任务
Job job = new Job(conf, "job");
// 设置执行该Job的Jar包
job.setJarByClass(CleanMain.class);
// 设置Mapper类,用于处理输入数据
job.setMapperClass(CleanMapper.class);
// 设置输出键的类型为Text
job.setOutputKeyClass(Text.class);
// 设置输出值的类型为NullWritable,表示没有实际的值输出
job.setOutputValueClass(NullWritable.class);
// 添加输入路径,指定HDFS上的文件或目录
FileInputFormat.addInputPath(job, new Path("hdfs://hadoop01:9000/JobData/2024xxxx"));
// 设置输出路径,指定本地文件系统或HDFS上的目录
FileOutputFormat.setOutputPath(job, new Path("D:\\JobData\\out"));
// 提交作业并等待完成,根据返回结果决定程序退出状态码
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
3.在Eclipse中实现MapReduce程序的本地运行.
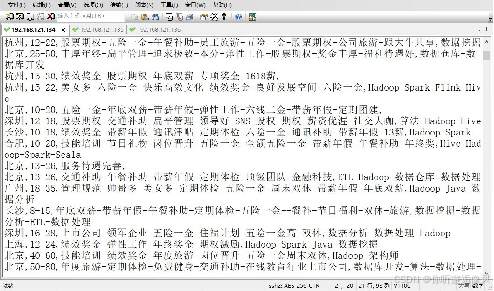
4.在“D:\\JobData\\out”目录下使用文本编辑器Notepad++打开“part-r-00000”文件查看最终输出结果.
四、将数据预处理程序提交到集群中运行
Maven的安装
Step1:从官网https://maven.apache.org/download.cgi或班级钉钉群下载安装包for windows。(apache-maven-3.3.9-bin.zip) Step2:将安装包解压到硬盘某一英文目录中,如E:\Tools\Maven\Apache-Maven-3.3.9。
Maven的配置
Step1:右键此电脑–>属性–>高级系统设置–>环境变量
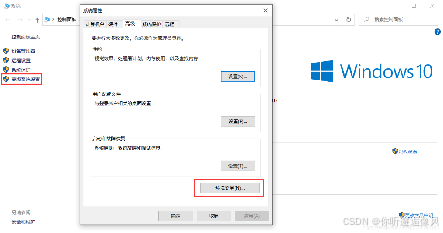
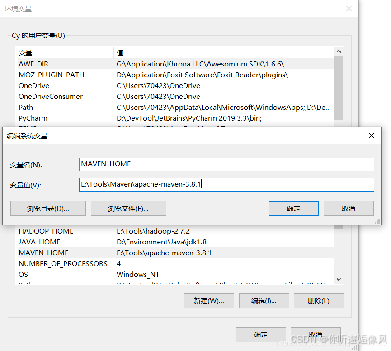
Step2:新建变量MAVEN_HOME = E:\Tools\Maven\apache-maven-3.8.1
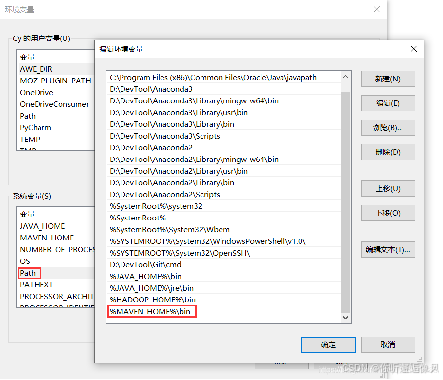
Step3:找到Path变量并点击选中–>点击下方编辑按钮–>新建变量值%MAVEN_HOME%\bin
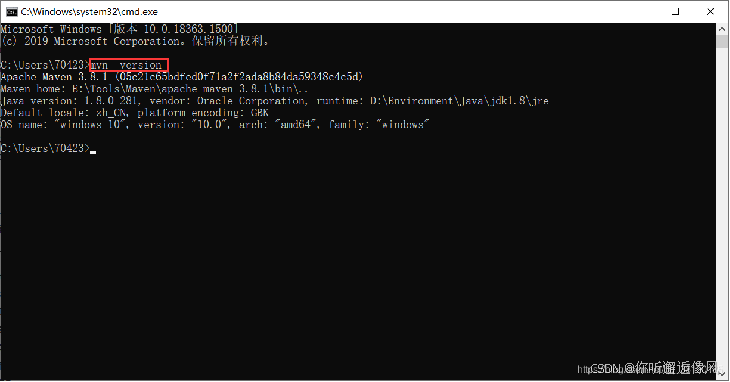
Maven的验证
win+R运行cmd,输入mvn -version,如图所示则配置成功
(一)修改MapReduce程序主类
在3.4节的基础上修改MapReduce程序主类内容,修改完的代码如下,其中加黑红部分为修改内容
public class CleanMain {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// 配置日志记录器,用于输出日志信息
BasicConfigurator.configure();
// 创建Hadoop的配置对象
Configuration conf = new Configuration();
// 解析命令行参数,获取输入和输出路径
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
// 如果参数数量不等于2,则打印用法并退出程序
if (otherArgs.length != 2) {
System.err.println("Usage: wordcount <in> <out>");
System.exit(2);
}
// 创建一个Job实例,用于定义和运行MapReduce任务
Job job = new Job(conf, "job");
// 设置执行该Job的Jar包
job.setJarByClass(CleanMain.class);
// 设置Mapper类,用于处理输入数据
job.setMapperClass(CleanMapper.class);
// 设置输入格式类,这里使用CombineTextInputFormat来合并小文件
job.setInputFormatClass(CombineTextInputFormat.class);
// 设置最小输入分片大小为2MB
CombineTextInputFormat.setMinInputSplitSize(job, 2097152);
// 设置最大输入分片大小为4MB
CombineTextInputFormat.setMaxInputSplitSize(job, 4194304);
// 设置输出键的类型为Text
job.setOutputKeyClass(Text.class);
// 设置输出值的类型为Text
job.setOutputValueClass(Text.class);
// 添加输入路径,指定HDFS上的文件或目录
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
// 设置输出路径,指定本地文件系统或HDFS上的目录
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
// 提交作业并等待完成,根据返回结果决定程序退出状态码
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
(二)创建jar包
1.进入预处理程序本地项目目录
2.在该目录下进行如下操作,按住键 盘上的Shift键,点击鼠标右键,选 择“在此处打开PowerShell窗口” 或者如果右键菜单中没有此选项,用windows查找功能找到powershell并运行程序,用磁盘操作命令进入目录。
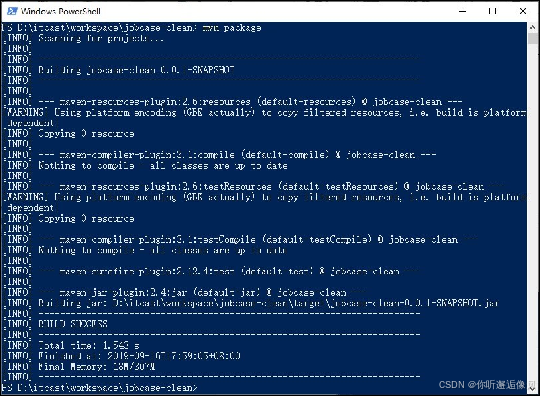
3.在PowerShell窗口中输入“mvn package” 将数据预处理程序打成jar包。
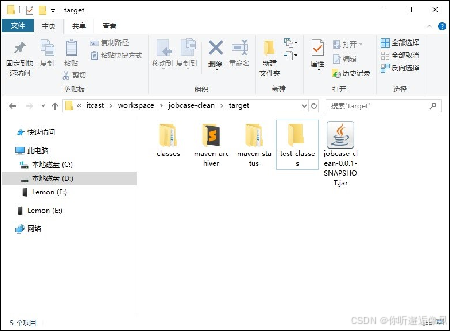
4.在本地项目目录的target目录下查看生成得jar包
(三)将jar包提交到集群运行
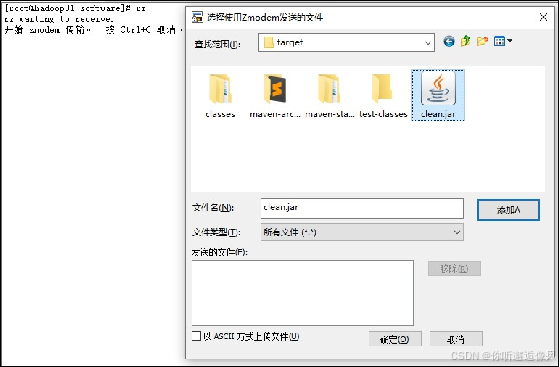
1.为了便于后续使用,可自行修改jar包名称,这里将jar名称修改为clean.jar。在hadoop01虚拟机通过“rz”指令将jar包上传至export/software目录
(四)检查运行结果
1.在集群中运行hadoop程序
在hadoop01中运行hadoop jar命令执行数据预处理程序的jar包,在命令中指定数据输入和结果输出的目录,指令如下
hadoop jar clean.jar com.position.clean.CleanMain /JobData/20190807/ /JobData/output
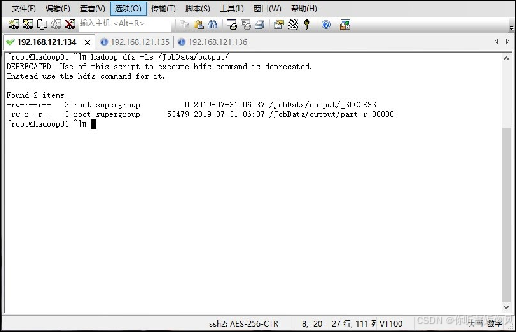
通过Hadoop命令查看HDFS上的指定目录是否生成文件.
2.查看运行结果
在Hadoop01中通过Hadoop命令查看HDFS上查看最终数据内容。
hadoop dfs -cat /JobData/output/part-r-00000
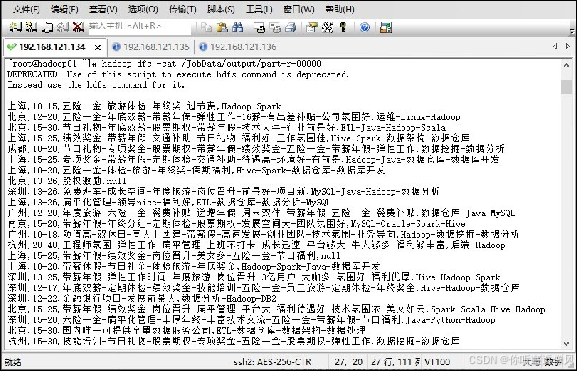
这样我们完成了数据预处理,之后进行hive数据分析!

技术共进,成长同行——讯飞AI开发者社区
更多推荐

 25
25 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)