
目标检测与分类识别之提高map的方法---新生成类进行针对性训练
什么是map呢,已经有不少对map的解释说得很明白了,在这里就不再赘述。在分类识别中,我们往往会遇到个别ap比较低的,在这种情况下,ap低的类显然会拉低map,我们在计算map的过程中,可能会得出以下结果可以明显看出花盆、书籍纸张、金属器皿、污损用纸、垃圾桶这几个类别的ap特别低,我们可以单独对这些类别进行分析,如何将这些类别从数据集提取出来呢?可以参考这里:目标检测与分类识别之数据集分类通过分析
·
什么是map呢,已经有不少对map的解释说得很明白了,在这里就不再赘述。
在分类识别中,我们往往会遇到个别ap比较低的,在这种情况下,ap低的类显然会拉低map,我们在计算map的过程中,可能会得出以下结果
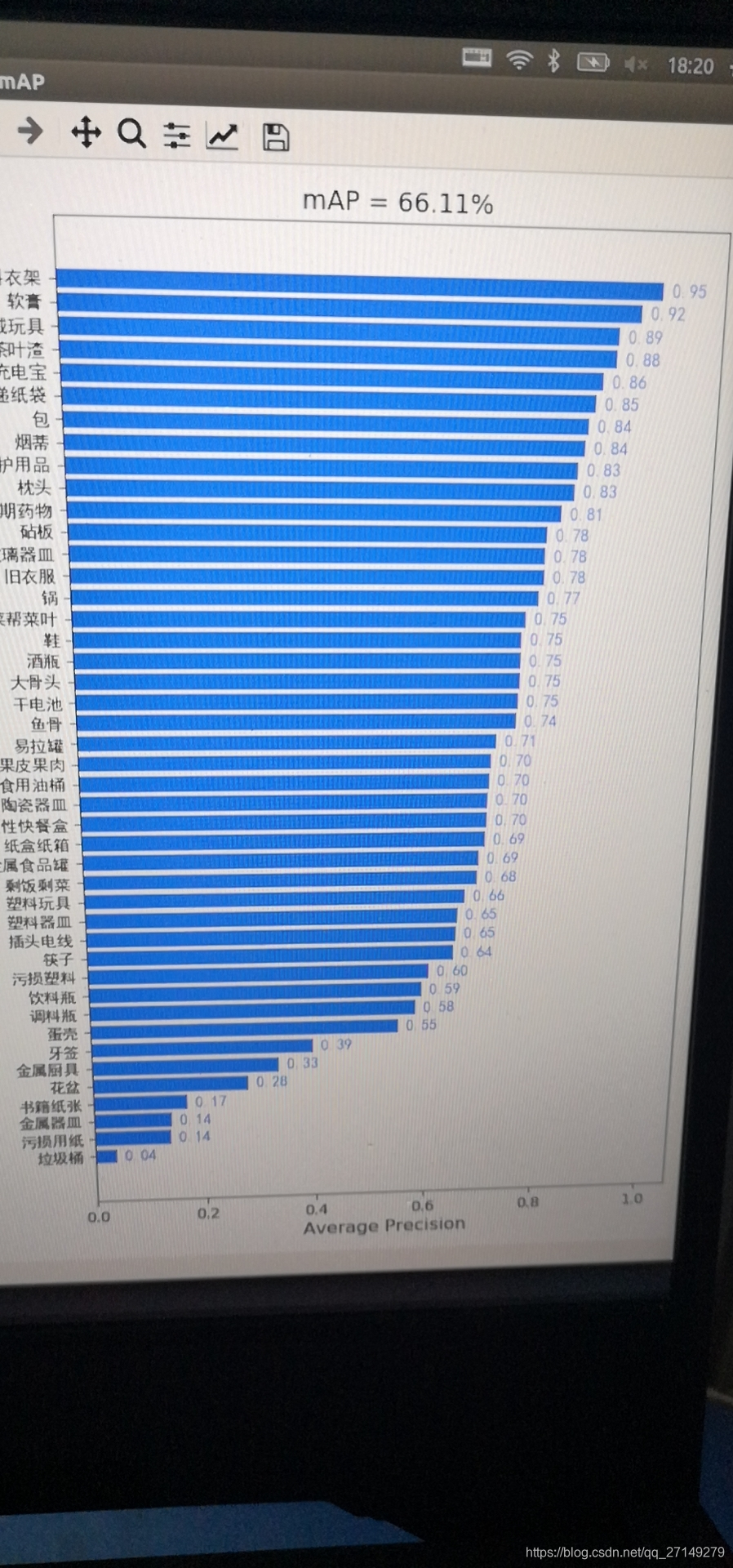
可以明显看出花盆、书籍纸张、金属器皿、污损用纸、垃圾桶这几个类别的ap特别低,我们可以单独对这些类别进行分析,如何将这些类别从数据集提取出来呢?可以参考这里:目标检测与分类识别之数据集分类
通过分析我们得出是数据集相对单一,图片太少,遮挡多导致的,那此时我们将这些类提取出来,生成新的数据集,方便我们对数据集进行扩充。
提取低ap的类,生成新数据集的代码如下:
import os
import xml.dom.minidom
import glob
import xml.etree.ElementTree as ET
import os,shutil
def get_categories(xml_files):
"""Generate category name to id mapping from a list of xml files.
Arguments:
xml_files {list} -- A list of xml file paths.
Returns:
dict -- category name to id mapping.
"""
classes_names = []
for xml_file in xml_files:
tree = ET.parse(xml_file)
root = tree.getroot()
for member in root.findall("object"):
classes_names.append(member[0].text)
classes_names = list(set(classes_names))
classes_names.sort()
return {name: i for i, name in enumerate(classes_names)}
def makdir(new_datasets_path):
if not os.path.exists(new_datasets_path):
os.makedirs(new_datasets_path)
print('makdir......',new_datasets_path)
def get_loss_count(countpath):
allClass = {}
lowApClass = {}
with open(countpath,'r',encoding='utf-8') as f:
lines = f.readlines()
for i in lines:
s=i.split(':')
allClass[s[0]] = int(s[1])
if int(s[1])<=400:#-------------------------------------------筛选小于400的类别
lowApClass[s[0]] = int(s[1])
return allClass,lowApClass
countpath = r'./VOCdevkit/count.txt'
AnnoPath = r'./VOCdevkit/VOC2007/Annotations/'
imagePath = r'./VOCdevkit/VOC2007/JPEGImages/'
newdatasets={'a':'Annotations','i':'ImageSets','j':'JPEGImages'}
newdatasetspath = r'./VOCdevkit/newdatasets_400/'
Annolist = os.listdir(AnnoPath)
makdir(newdatasetspath)
makdir(os.path.join(newdatasetspath,newdatasets['a']))
makdir(os.path.join(newdatasetspath,newdatasets['i']))
makdir(os.path.join(newdatasetspath,newdatasets['i'],'main'))
makdir(os.path.join(newdatasetspath,newdatasets['j']))
#jpglist = os.listdir(AnnoPath)
total1 = 0
total = 0
totalerror = 0
allClass = {}
lowApClass = {}
allClass,lowApClass = get_loss_count(countpath)
rate = allClass
for key ,value in rate.items():
rate[key]=0
f=open(r'./VOCdevkit/noexit.txt','w',encoding='utf-8')
for annotation in Annolist:
fullname = AnnoPath + annotation
print(fullname,annotation)
dom = xml.dom.minidom.parse(fullname) # 打开XML文件
# print(fullname,annotation)
# print('---------------', total1)
collection = dom.documentElement # 获取元素对象
objectlist = collection.getElementsByTagName('object') # 获取标签名为object的信息
filename = collection.getElementsByTagName('filename') # 获取标签名为object的信息
# name = filename[:-4]
for object in objectlist:
namelist = object.getElementsByTagName('name') # 获取子标签name的信息
objectname = namelist[0].childNodes[0].data # 取到name具体的值
# rate[objectname] += 1
if objectname in lowApClass.keys(): # 判断字典里有没有标签,如无添加相应字段
if os.path.exists(os.path.join(imagePath,filename[0].childNodes[0].data)):
shutil.copy(os.path.join(AnnoPath, annotation), os.path.join(newdatasetspath, newdatasets['a']))
shutil.copy(os.path.join(imagePath, filename[0].childNodes[0].data),
os.path.join(newdatasetspath, newdatasets['j']))
total1 += 1
else:
totalerror+=1
print( '-------------------路径不存在个数', totalerror,annotation)
f.write( os.path.join(AnnoPath, annotation)+'\n')
rate[objectname] += 1
total += 1
f.close()
print(rate)
print(total1,total,'-------------------路径不存在个数',totalerror)
将代码保存为脚本get_low_ap_class.py
运行可得到新的数据集
然后我们就可以针对这些数据集进行扩充或者做其他处理,来提升其ap
如果新生成的类遇到标签与图片不对应的情况,可以执行以下脚本
import os
import shutil
img_list = os.listdir('./VOCdevkit/VOC2007/JPEGImages')
anno_list = os.listdir('./VOCdevkit/VOC2007/Annotations')
#anno_name = []
#for anno in anno_list:
# anno_name.append(anno.split('.')[0])
#for i in range(len(img_list)):
# img_name = img_list[i].split('.')[0]
# if img_name not in anno_name:
# print(img_name)
# --------------------------->
# shutil.copy('./Annotations/' + img_name + '.xml', './VOCdevkit/VOC2007/Annotations/' + img_name + '.xml')
img_name = []
for img in img_list:
img_name.append(img.split('.')[0])
for i in range(len(anno_list)):
anno_name = anno_list[i].split('.')[0]
if anno_name not in img_name:
print(anno_name)
shutil.copy('K:/VOCdevkit/VOC2007/JPEGImages/' + anno_name + '.jpg', './VOCdevkit/VOC2007/JPEGImages/' + anno_name + '.jpg')

技术共进,成长同行——讯飞AI开发者社区
更多推荐

 0
0 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)