
教你使用文字识别软件ABBYY FineReader PDF 15获取书本上的文字信息
很多人都有读书的习惯,随着摄像技术的提高,我们可以通过拍照的方法将书本上有价值的信息拍摄下来,方便后续查看。但随着拍摄的照片变多,查找起来也是很繁琐的。借助ABBYY FineReader PDF 15 文字识别软件的帮助,我们可以将照片中的文字信息识别出来,并保存为可编辑的文件,供后续使用。接下来,一起来感受下ABBYY FineReader PDF 15的神奇之处。图1:ABBYY FineR
很多人都有读书的习惯,随着摄像技术的提高,我们可以通过拍照的方法将书本上有价值的信息拍摄下来,方便后续查看。但随着拍摄的照片变多,查找起来也是很繁琐的。
借助ABBYY FineReader PDF 15 文字识别软件的帮助,我们可以将照片中的文字信息识别出来,并保存为可编辑的文件,供后续使用。接下来,一起来感受下ABBYY FineReader PDF 15的神奇之处。
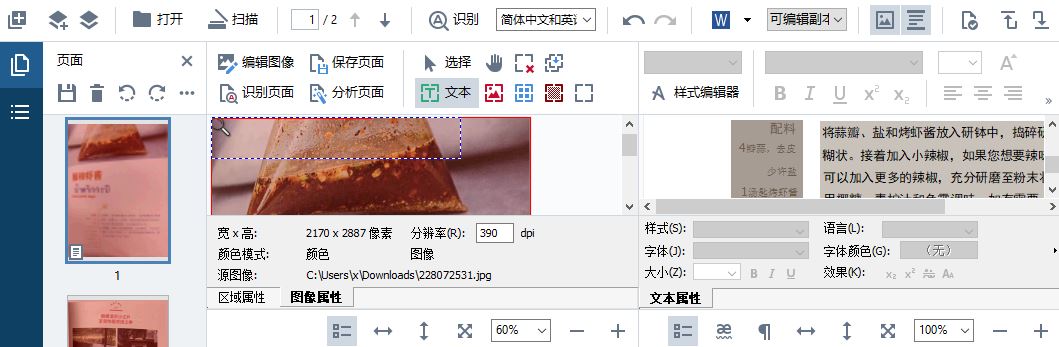
图1:ABBYY FineReader PDF 15界面
一、拍摄图片
由于书本有一定弧度,较难将一页内容都拍摄平整。因此,建议拍摄的时候,将手机或相机垂直于目标文字信息的部分。
比如,如图1所示,中间的文字部分是本次获取的重点内容,因此,拍摄的时候尽量将手机或相机垂直于这部分内容。

图2:拍摄书本图片
二、使用OCR文字识别功能
完成照片的拍摄后,打开ABBYY FineReader PDF 15 文字识别软件,并使用其OCR编辑器打开照片。
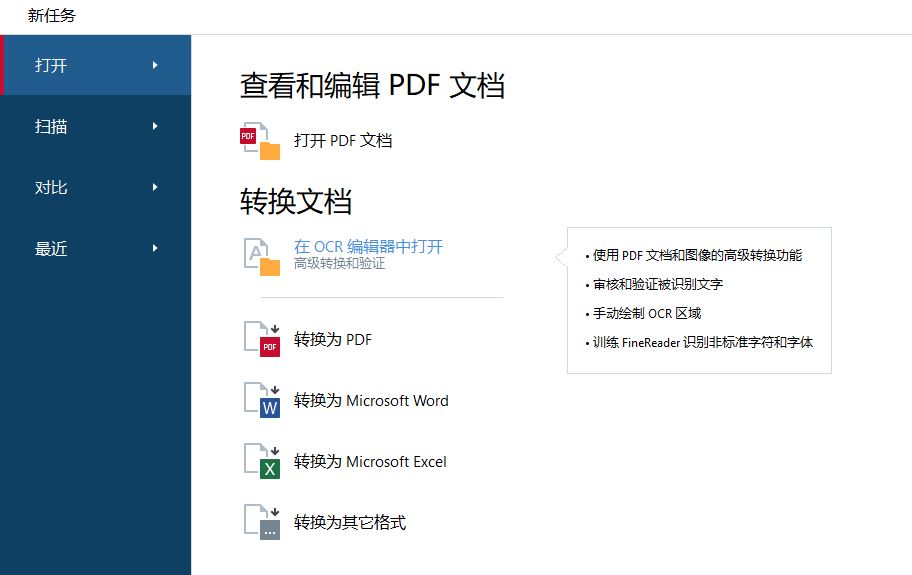
图3:在OCR编辑器中打开
在OCR编辑器中打开照片后,软件需要花费一些时间识别文字。
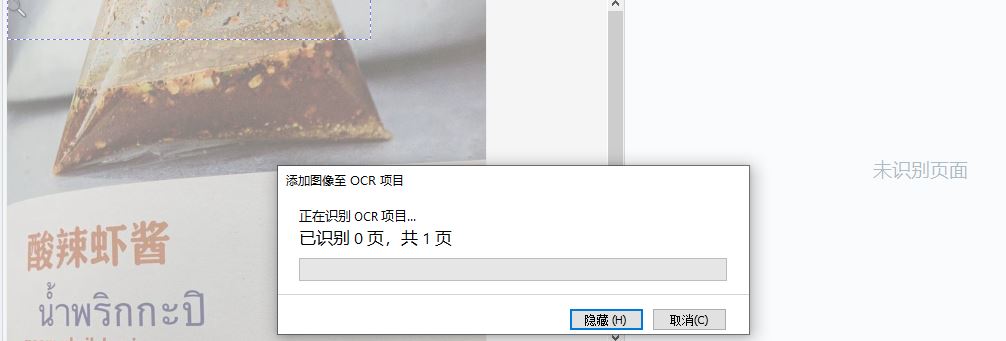
图4:识别OCR项目
三、检查识别区域属性的准确度
待ABBYY FineReader PDF 15完成文字识别后,查看器区域属性,重点是查看目标文字区域的属性。
如图5所示,可以看到,中间的目标文字部分已经被正确识别为文本(以绿色方框标注)。
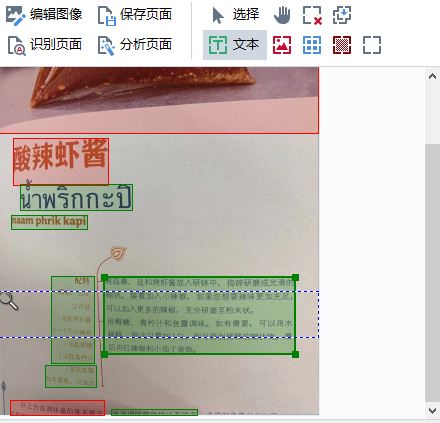
图5:区域属性
四、检查文本识别的准确度
接着,再使用OCR编辑器的文本编辑功能,查看文本识别的准确性。
如图6所示,可以看到,软件的识别准确度非常高,目标文字都识别正确。如果其中存在一些识别错误的话,也可以使用文本编辑器,手动修改文本。
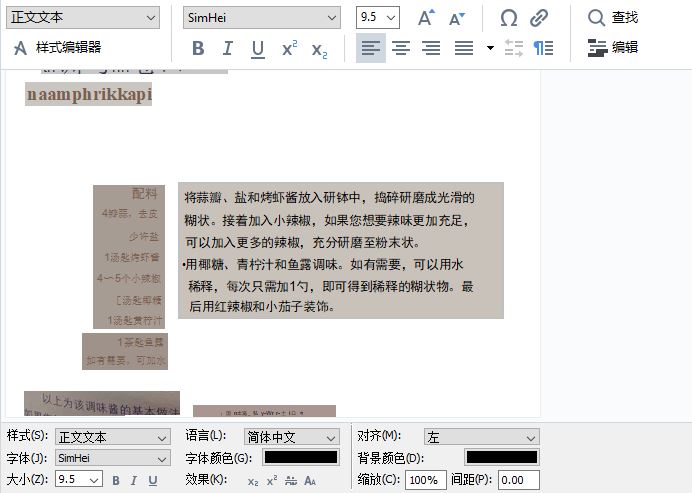
图6:文本属性
五、导出可编辑文本
确认目标文本识别无误后,就可以将其保存起来。ABBYY FineReader PDF 15提供了多种类型的保存选项,其中包含了PDF文档、Word文档等选项。
我们这里选择了以Word文档作为保存格式。
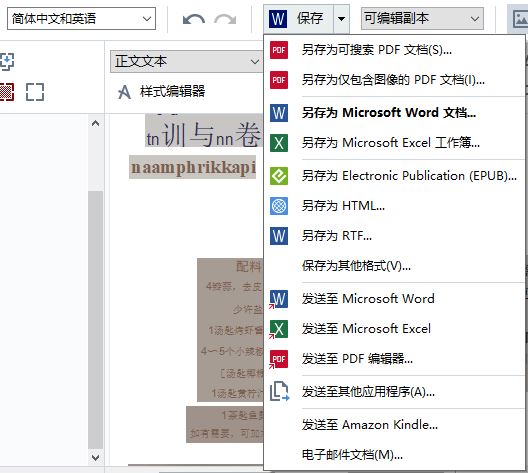
图7:另存为选项
导出完成后,打开Word文档。如图8所示,可以看到,不仅目标文本识别准确度高,其排版也是尽量与拍摄的照片保持一致,使用感相当好。
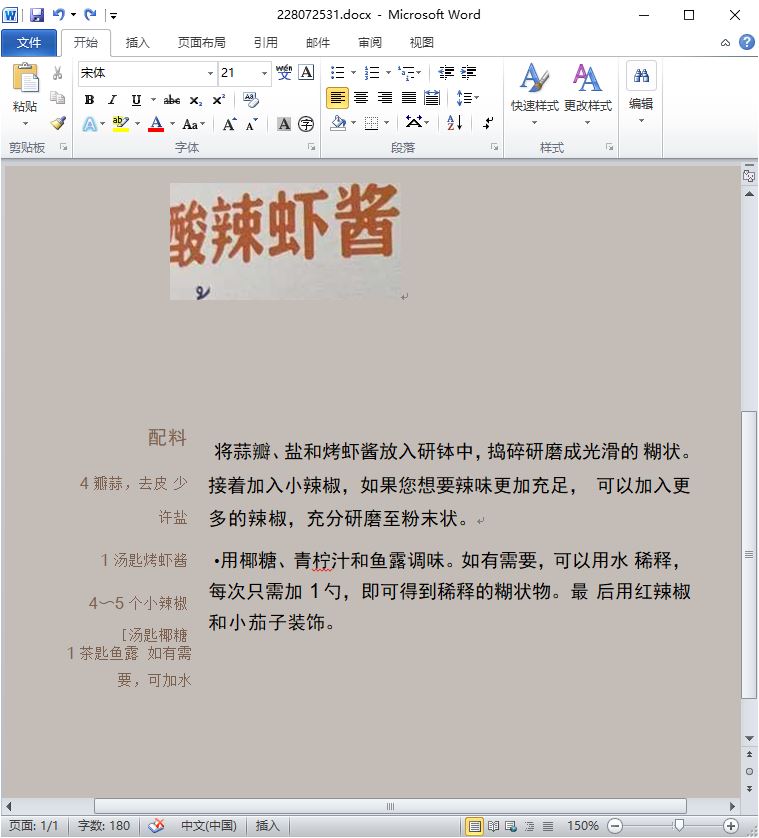
图8:导出到Word文档
六、小结
作为一款智能化的文字识别软件,ABBYY FineReader PDF 15能出色地完成文本识别的任务,无论是在PDF文档文本识别领域,还是在图像文本识别领域,都表现得相当优秀。
如果您还停留于手抄书的阶段,不如尝试使用一下ABBYY FineReader PDF 15的文本识别功能,会让您发现一个新世界!

技术共进,成长同行——讯飞AI开发者社区
更多推荐
 0
0 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)