
FunASR语音转文字本地部署、API接口教程
首次运行会下载模型文件,模型文件会被下载到当前电脑用户的**.cache/modelscope/hub/iic**文件夹中。当然,也可以手动下载模型并放到这个目录下,如果手动下载模型的话,就不需要执行这一步了。FunASR的部署可以使用Docker,有关Docker的部署教程就很多了,一搜就是一大堆,我就不写了。阿里新开源的FunASR仓库(语音转文字),识别速度快,精度高。修改代码中的要识别的w
本地部署
部署前请先学习conda的基础使用。
平台:windows 11
阿里新开源的FunASR仓库(语音转文字),识别速度快,精度高。
FunASR的部署可以使用Docker,有关Docker的部署教程就很多了,一搜就是一大堆,我就不写了。
我就写一下Python本地部署的过程。
1.下载FunASR仓库
github仓库链接:https://github.com/modelscope/FunASR
直接下载仓库Zip文件。
下载完成后,解压缩。
2.创建虚拟环境
要求:
- python≥3.8 实测3.8失败,3.10成功
- torch≥1.13 实测torch-1.13.1+cu117成功
- torchaudio
3.安装库
在FunASR的路径下:
然后分别执行下面的命令:
pip install -e ./
pip install modelscope # 实测不需要,pip install -e ./时已经将modelscope作为依赖安装了
pip install torchaudio
上面的三个pip命令是安装必要的库。安装可能会很久,等待即可。
4.测试识别
在仓库根目录下新建一个test.py文件,并输入代码:
from funasr import AutoModel
import datetime
# paraformer-zh is a multi-functional asr model
# use vad, punc, spk or not as you need
model = AutoModel(model="paraformer-zh", vad_model="fsmn-vad", punc_model="ct-punc")
res = model.generate(input="D:\\imformation\\test.wav",
batch_size_s=300,
hotword='魔搭')
print(res)
修改代码中的要识别的wav文件路径,然后运行这个test.py,
首次运行会下载模型文件,模型文件会被下载到当前电脑用户的**.cache/modelscope/hub/iic**文件夹中。当然,也可以手动下载模型并放到这个目录下,如果手动下载模型的话,就不需要执行这一步了。
正常的话将看到这样的输出:

我们需要的是最后的白色文本,这才是对音频文件的识别结果。
到此,本地部署就完成了。
注意:部署部分修改于:FunASR Windows本地部署(语音转文字) - 哔哩哔哩
API接口
API分为服务端和客户端。
服务端
先安装API所需依赖库
pip install fastapi python-multipart uvicorn
再在仓库根目录下新建一个asr_server.py文件
from fastapi import FastAPI, File, UploadFile, HTTPException
from fastapi.responses import JSONResponse
from funasr import AutoModel
import os
from datetime import datetime
from typing import Optional
app = FastAPI()
# 初始化模型
model = None
def load_model():
global model
if model is None:
print(f"{datetime.now()} - 正在加载ASR模型...")
model = AutoModel(model="paraformer-zh", vad_model="fsmn-vad", punc_model="ct-punc")
print(f"{datetime.now()} - ASR模型加载完成")
@app.on_event("startup")
async def startup_event():
load_model()
@app.get("/")
async def health_check():
return {"status": "healthy", "message": "ASR服务运行中"}
@app.post("/asr")
async def transcribe_audio(
file: UploadFile = File(...),
batch_size_s: int = 300,
hotword: Optional[str] = None
):
try:
# 检查文件类型
if not file.filename.lower().endswith(('.wav', '.mp3', '.ogg', '.flac')):
raise HTTPException(status_code=400, detail="仅支持音频文件 (wav, mp3, ogg, flac)")
# 保存临时文件
temp_file = f"temp_{datetime.now().strftime('%Y%m%d%H%M%S')}_{file.filename}"
with open(temp_file, "wb") as buffer:
buffer.write(await file.read())
# 调用ASR模型
print(f"{datetime.now()} - 开始处理文件: {file.filename}")
result = model.generate(
input=temp_file,
batch_size_s=batch_size_s,
hotword=hotword
)
# 删除临时文件
os.remove(temp_file)
return JSONResponse(content={
"status": "success",
"filename": file.filename,
"transcription": result
})
except Exception as e:
# 如果出现错误,确保删除临时文件
if 'temp_file' in locals() and os.path.exists(temp_file):
os.remove(temp_file)
raise HTTPException(status_code=500, detail=str(e))
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8000)
运行该python文件
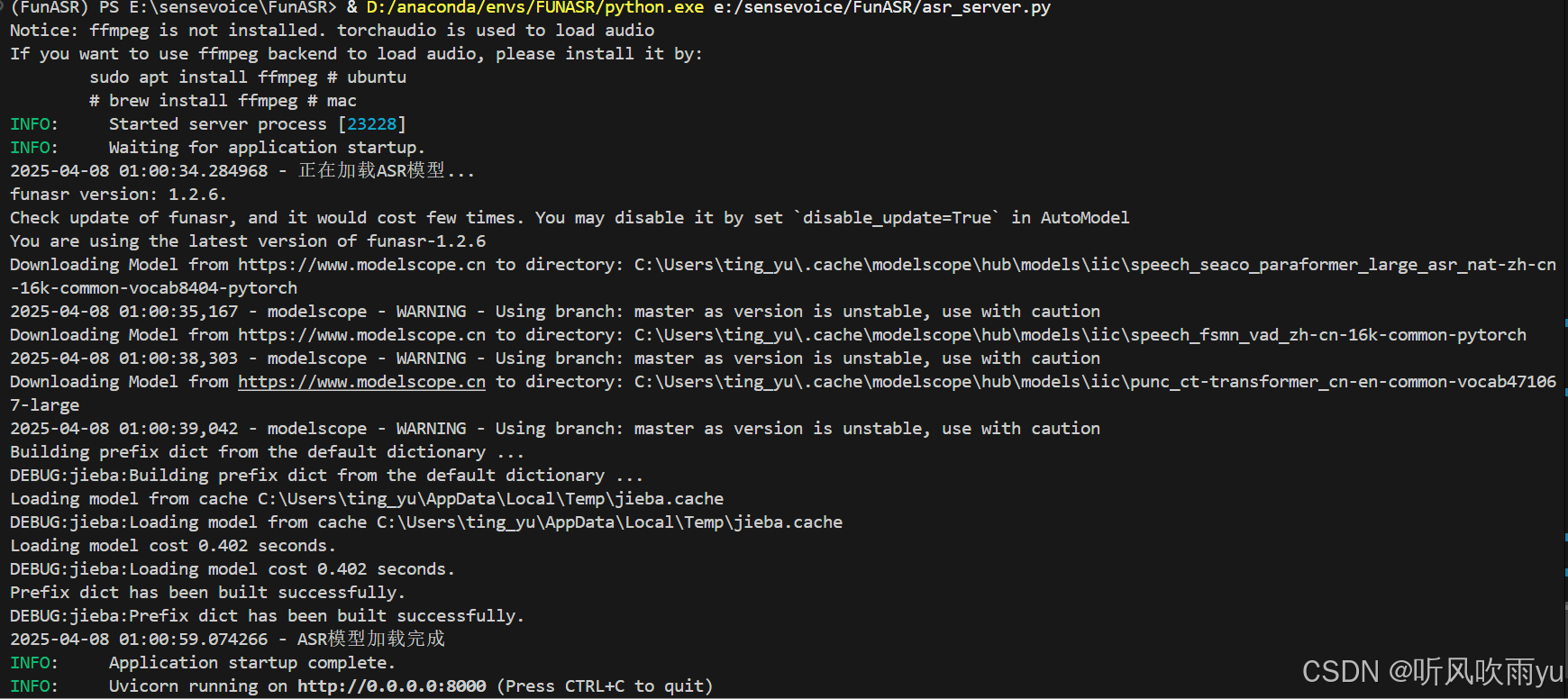
此时,不要关闭此Python脚本
客户端
客户端的Python环境可以不用和FunASR处于同一环境,只需要具有fastAPI库即可。
pip install fastapi
在任意位置任意Python环境下运行客户端代码ast_cilent.py
import requests
import time
from datetime import datetime
def test_asr_service(audio_file_path, hotword=None):
# API端点
url = "http://localhost:8000/asr"
# 准备文件
with open(audio_file_path, "rb") as audio_file:
files = {"file": (audio_file_path.split("/")[-1], audio_file)}
data = {"hotword": hotword} if hotword else {}
# 发送请求
start_time = time.time()
print(f"{datetime.now()} - 开始发送请求...")
response = requests.post(url, files=files, data=data)
# 处理响应
if response.status_code == 200:
result = response.json()
print(f"{datetime.now()} - 识别成功!")
print(f"文件名: {result['filename']}")
print(f"识别结果: {result['transcription']}")
print(f"处理时间: {time.time() - start_time:.2f}秒")
return result
else:
print(f"{datetime.now()} - 识别失败!")
print(f"状态码: {response.status_code}")
print(f"错误信息: {response.text}")
return None
if __name__ == "__main__":
# 测试调用
audio_file = "D:\\imformation\\test.wav" # 替换为你的音频文件路径
hotword = "魔搭" # 可选热词
result = test_asr_service(audio_file, hotword)
运行后结果如下:

同时可以在服务端看到如下的输出:

至此,FunASR模型的部署以及API调用完成

技术共进,成长同行——讯飞AI开发者社区
更多推荐
 34
34 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)