
大数据开发之druid介绍
1:druid介绍1.1 druid是什么Druid的母公司MetaMarket在2011年以前也是Hadoop的拥趸者,但是在高并发环境下,Hadoop并不能对数据可用性以及查询性能给出产品级别的保证,使得MetaMarket必须去寻找新的解决方案,当尝试使用了各种关系型数据库以及NoSQL产品后,他们觉得这些已有的工具都不能解决他们的“痛点”,所以决定在2011年开始研发自己的“轮子”...
1:druid介绍
1.1 druid是什么
Druid的母公司MetaMarket在2011年以前也是Hadoop的拥趸者,但是在高并发环境下,Hadoop并不能对数据可用性以及查询性能给出产品级别的保证,使得MetaMarket必须去寻找新的解决方案,当尝试使用了各种关系型数据库以及NoSQL产品后,他们觉得这些已有的工具都不能解决他们的“痛点”,所以决定在2011年开始研发自己的“轮子”Druid,他们将Druid定义为“开源、分布式、面向列式存储的实时分析数据存储系统”,
druid是针对时间序列数据提供低延迟的数据写入以及快速交互式查询的分布式OLAP数据库。
1.2:为什么使用druid
1.2.1 为什么出现druid(OLAP&OLTP)
1:OLAP与OLTP的介绍和区别
数据处理大致可以分成两大类:联机事务处理OLTP(on-line transaction processing)、联机分析处理OLAP(On-Line Analytical Processing)。OLTP是传统的关系型数据库的主要应用,主要是基本的、日常的事务处理,例如银行交易。OLAP是数据仓库系统的主要应用,支持复杂的分析操作,侧重决策支持,并且提供直观易懂的查询结果。
OLTP:web系统中的关系型数据库的应用;数据的增删改查,CRUD
OLAP:大数据或者数据分析领域中常见的形式,注重对数据分析查询,不涉及或者很少涉及修改操作;
1.2.2:OLAP中常用的技术:
大数据OLAP技术;大数据OLAP能使用SQL进行查询和支持Hadoop。 其实还有很多的框架和技术都被在大数据领域的OLAP中使用,hive,spark,druid,kylin等都是比较常见的技术;druid与常见OLAP技术的对比:
1:由于hive/sparksql主要是注重离线分析,数据的时效性比较差,而且由于hive/sparksql的离线分析指标统计的延时性比较高,很难满足毫秒甚至秒级的要求;
2:Es作为全文索引技术,时效性以及查询延时都能满足要求,但是数据规模在中等规模的时候是比较优秀的,但是在万亿甚至更大规模的场景下,es的查询和写入都会遇到很大的性能问题;
3:kylin和druid是比较相似的技术,两者性能也比较类似,但是druid可以支持数据的实时导入,结合需求我们就采用了druid作为OLAP的技术框架;
1.2.3 druid的特点
优点:
a:对于大部分的查询场景都可以做到亚秒级的响应,
b:可以同时支持数据实时导入和批量导入两种方式
c:数据写入的时候进行预聚合,节省存储空间提高查询效率
d:集群扩展方便
缺点:
a:druid不支持join操作,
b:druid在大数据量下对明细查询有瓶颈
1.2.4 druid适合什么场景使用
1: 数据中包含明显的时间序列,时间序列是分析重要维度;
2: 快速的交互式查询,近实时的亚秒级快速响应
3:可以存储大数据量(TB,PB),且事件(数据)可以预先定义若干个维度
2 druid的重要概念
2.1 roll-up聚合
druid可以汇总原始数据。汇总是就是把选定的相同维度的数据进行聚合操作,可减少存储的大小。 druid要求数据具有如下要求,数据分为三部分:时间戳,维度列,指标列
-
Timestamp列: 所有的查询都以时间为中心。
-
Dimension列(维度): Dimensions对应事件的维度,通常用于筛选过滤数据。
-
Metric列(度量): Metrics是用于聚合和计算的列。通常是数字,并且支持count、sum等聚合操作。
比如:
{"timestamp":"2018-01-01T01:01:35Z","srcIP":"1.1.1.1", "dstIP":"2.2.2.2","packets":20,"bytes":9024} {"timestamp":"2018-01-01T01:01:51Z","srcIP":"1.1.1.1", "dstIP":"2.2.2.2","packets":255,"bytes":21133} {"timestamp":"2018-01-01T01:01:59Z","srcIP":"1.1.1.1", "dstIP":"2.2.2.2","packets":11,"bytes":5780} {"timestamp":"2018-01-01T01:02:14Z","srcIP":"1.1.1.1", "dstIP":"2.2.2.2","packets":38,"bytes":6289} {"timestamp":"2018-01-01T01:02:29Z","srcIP":"1.1.1.1", "dstIP":"2.2.2.2","packets":377,"bytes":359971} {"timestamp":"2018-01-01T01:03:29Z","srcIP":"1.1.1.1", "dstIP":"2.2.2.2","packets":49,"bytes":10204} {"timestamp":"2018-01-02T21:33:14Z","srcIP":"7.7.7.7", "dstIP":"8.8.8.8","packets":38,"bytes":6289} {"timestamp":"2018-01-02T21:33:45Z","srcIP":"7.7.7.7", "dstIP":"8.8.8.8","packets":123,"bytes":93999} {"timestamp":"2018-01-02T21:35:45Z","srcIP":"7.7.7.7", "dstIP":"8.8.8.8","packets":12,"bytes":2818}
如果该数据被druid加载并且我们打开了聚合功能,聚合的要求是packets和bytes对应的数据进行累加,并且对条数进行计数,聚合后的数据如下:
┌──────────────────────────┬────────┬───────┬─────────┬─────────┬─────────┐ │ __time │ bytes │ count │ dstIP │ packets │ srcIP │ ├──────────────────────────┼────────┼───────┼─────────┼─────────┼─────────┤ │ 2018-01-01T01:01:00.000Z │ 35937 │ 3 │ 2.2.2.2 │ 286 │ 1.1.1.1 │ │ 2018-01-01T01:02:00.000Z │ 366260 │ 2 │ 2.2.2.2 │ 415 │ 1.1.1.1 │ │ 2018-01-01T01:03:00.000Z │ 10204 │ 1 │ 2.2.2.2 │ 49 │ 1.1.1.1 │ │ 2018-01-02T21:33:00.000Z │ 100288 │ 2 │ 8.8.8.8 │ 161 │ 7.7.7.7 │ │ 2018-01-02T21:35:00.000Z │ 2818 │ 1 │ 8.8.8.8 │ 12 │ 7.7.7.7 │ └──────────────────────────┴────────┴───────┴─────────┴─────────┴─────────┘
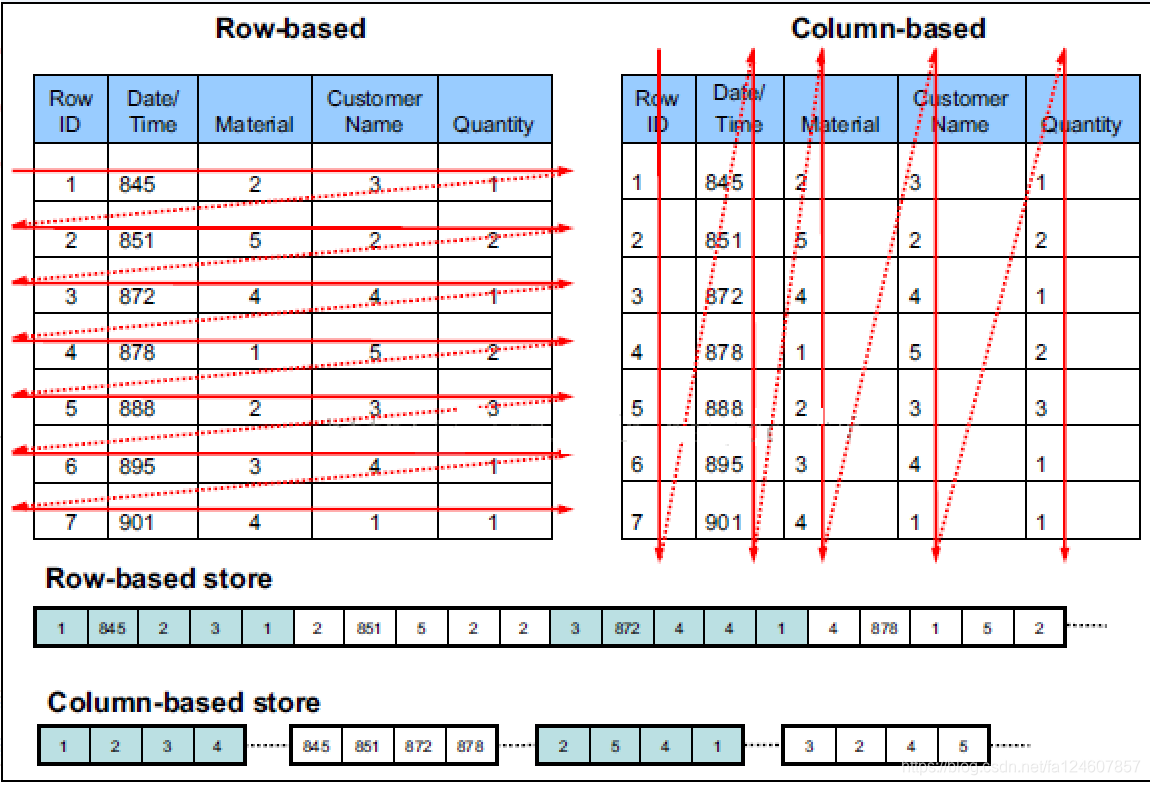
2.2 列式存储与行式存储
列式存储(Columnar or column-based)是相对于传统关系型数据库的行式存储(Row-basedstorage)来说的。简单来说两者的区别就是如何组织表:
行式存储对于 OLTP 场景是很自然的:大多数操作都以实体(Entity)为单位,即大多为增删改查一整行记录,显然把一行数据存在物理上相邻的位置是个很好的选择。
对于 OLAP 场景,一个典型的查询需要遍历整个表,进行分组、排序、聚合等操作,这样一来按行存储的优势就不复存在了。更糟糕的是,分析型 SQL 常常不会用到所有的列,而仅仅对其中某些感兴趣的列做运算,那一行中无关的列也不得不参与扫描,因此列式存储更适合这种场景。
2.3 Datasource和segments
Druid的数据被保存在datasource里面, DataSource类似于关系型数据库中的table。所有的DataSource是按照时间来分片的,每个时间区间范围被称为一个chunk(比如当你的DataSource是按天来分片的,一天就是一个chunk)。在chunk内部,数据被进一步分片成一个或多个segment。所有的segment是一个单独的文件,通常一个segment会包含数百万行数据。segment和chunk的关系示意图如下:
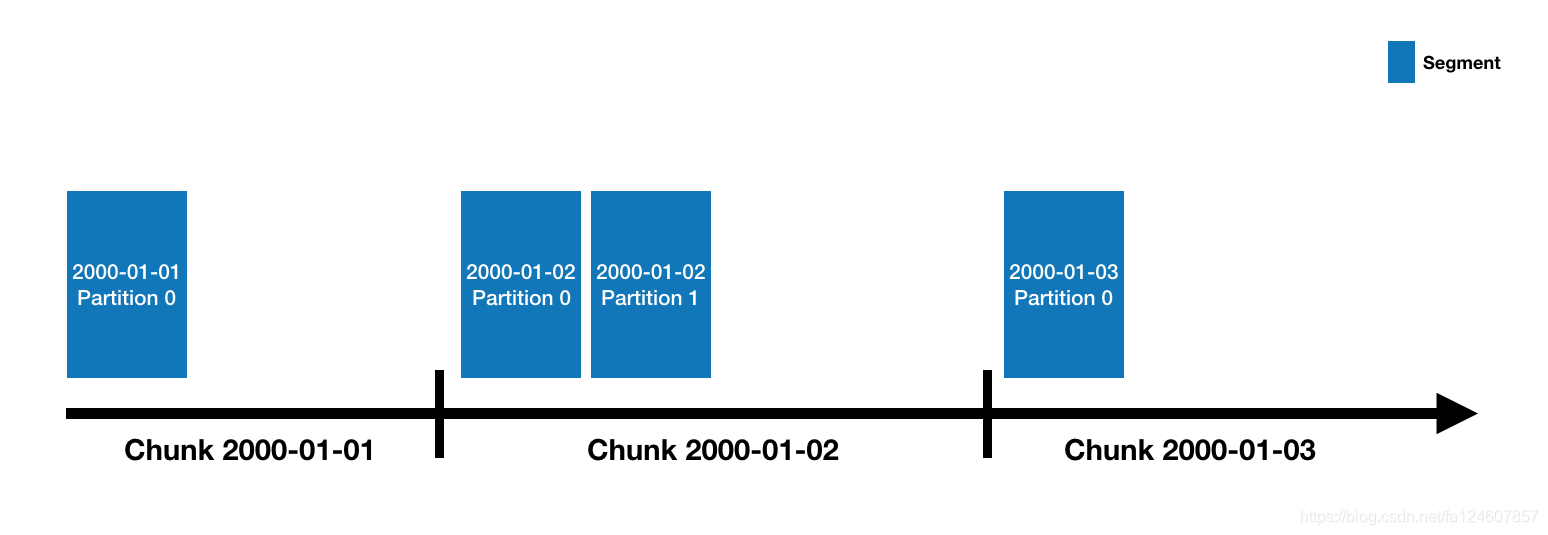
Segment是Druid中最基本的数据存储单元,采用列式(columnar)存储某一个时间间隔(interval)内某一个数据源(dataSource)的部分数据所对应的所有维度值、度量值、时间维度以及索引。
Segment存储结构
Segment逻辑名称形如“datasource_intervalStart_intervalEnd_version_partitionNum”,
dataSource:数据源;
intervalStart、intervalEnd:时间间隔的起止,使用ISO-8601格式;
version:版本号,使用导入的系统时间;
partitionNumber:分区编号,在每个时间间隔内,根据数据量的大小一个Segment内部可能会有多个分区,
数据以segments(段)的形式存储就是druid的分片,Segments是自包含容器,包括基于列的压缩,以及这些列的索引,对应下面要介绍的存储的descriptor.json和index.zip。Druid只需要清楚如何扫描这些segments就可以查询。
3 druid架构及原理
3.1druid的架构
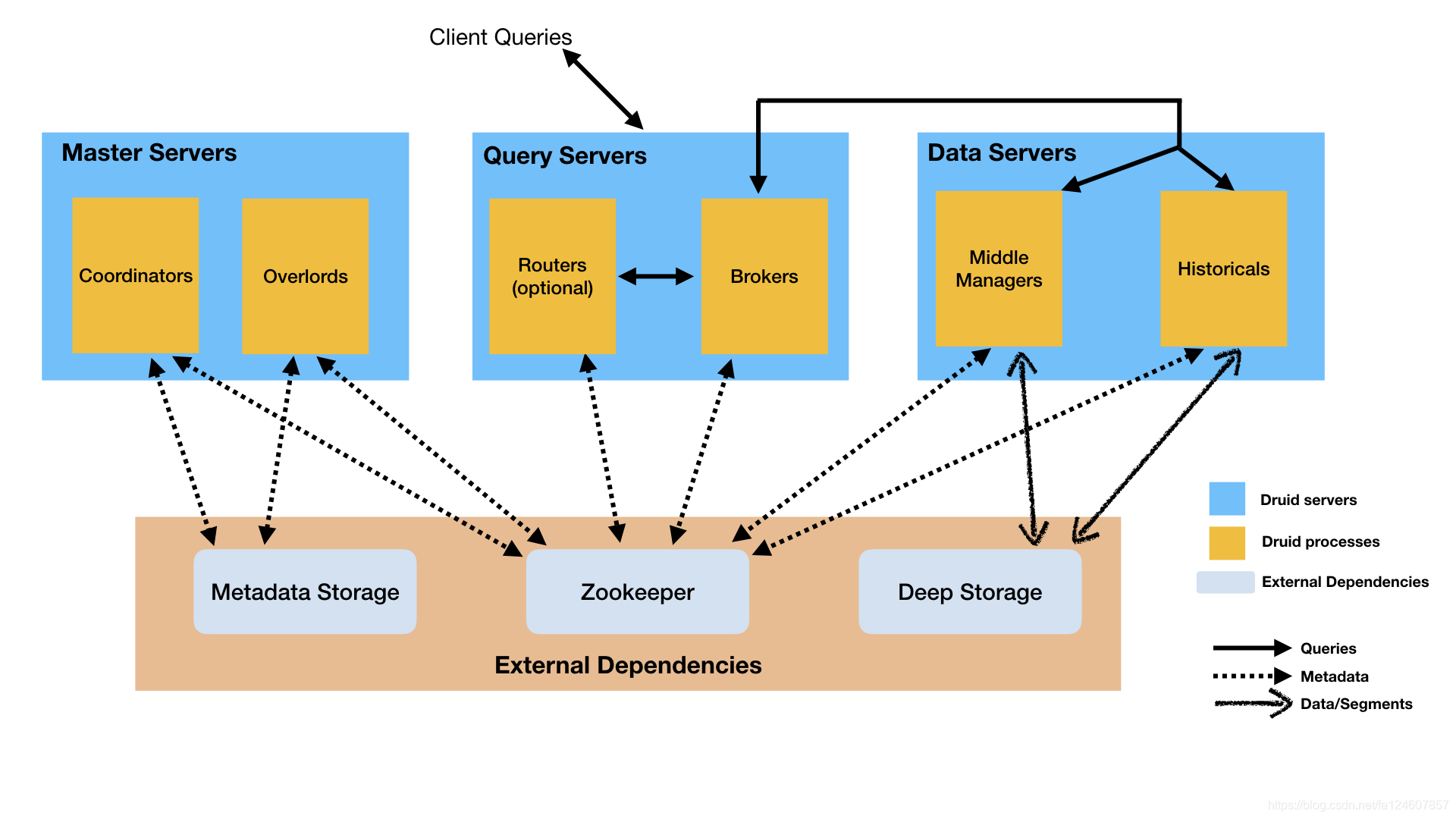
主要的节点包括(PS: Druid 的所有功能都在同一个软件包中,通过不同的命令启动):
-
Coordinator 节点:负责集群 Segment 的管理和发布,并确保 Segment 在 Historical 集群中的负载均衡
-
Broker 节点:负责从客户端接收查询请求,并将查询请求转发给 Historical 节点和 MiddleManager 节点。Broker 节点需要感知 Segment 信息在集群上的分布
-
Historical 节点:负责按照规则加载Segment并提供历史数据的查询
-
Router(可选) 节点:可选节点,在 Broker 集群之上的API网关,有了 Router 节点 Broker 不在是单点服务了,提高了并发查询的能力
-
Indexing Service
Indexing Service顾名思义就是指索引服务,在索引服务生成segment的过程中,由Overlord Node接收加载任务,然后生成索引任务(Index Service)并将任务分发给多个MiddleManager节点,MiddleManager节点根据索引协议生成多个Peon,Peon将完成数据的索引任务并生成segment,并将segment提交到分布式存储里面(一般是HDFS),然后Coordinator节点感知到segment生成,给Historical节点分发下载任务,Historical节点从分布式存储里面下载segment到本地。
Overlord
Overlord Node负责segment生成的任务,并提供任务的状态信息,当然原理跟上面类似,也在Zookeeper中对应的目录下,由实际执行任务的最小单位在Zookeeper中同步更新任务信息,类似于回调函数的执行过程。跟Coordinator Node一样,它在集群里面一般只存在一个,如果存在多个Overlord Node,Zookeeper会根据选举算法(一致性算法避免脑裂)产生一个Leader,其余的当Follower,当Leader遇到问题宕机时,Zookeeper会在Follower中再次选取一个Leader,从而维持集群生成segment服务的正常运行。Overlord Node会将任务分发给MiddleManager Node,由MiddleManager Node负责具体的segment生成任务。
MiddleManager
Overlord Node会将任务分发给MiddleManager Node,所以MiddleManager Node会在Zookeeper中感知到新的索引任务。一但感知到新的索引任务,会创建Peon(segment具体执行者,也是索引过程的最小单位)来具体执行索引任务,一个MiddleManager Node会运行很多个Peon的实例。
Peon
Peon(segment生成任务的具体执行者,也是索引过程的最小单位),所有的Peon都会在Zookeeper对应的目录中实时更新自己的任务状态。
简化版:
coordinator-Master节点,管理集群的数据视图,segment的load与drop;
historical :历史节点,负责历史窗口内数据的查询;
broker:查询节点,查询拆分,结果汇聚;
indexing service-一套实时/批量数据导入任务的调度服务
overlord-调度服务的master节点,负责接收任务,管理任务状态;
middleManager-worker节点,接收任务启动任务;
peon-实际的任务进程
外部依赖
深度存储服务(Deep storage):深度存储服务是能够被每个Druid服务都能访问的共享文件系统,一般是分布式对象存储服务,用于存放Druid所有摄入的数据。比如S3、HDFS或网络文件系统。
元数据存储(Metadata store):元数据存储服务主要用于存储Druid中的一些元数据,比如segment的相关信息。一般是传统的RDMS,比如Mysql。
Zookeeper:用于内部服务发现、协调和leader选举的。

技术共进,成长同行——讯飞AI开发者社区
更多推荐


 0
0 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)