
【WT】YOLOv8模型训练结果网页可视化与分析展示TPL模板
我们重新编制了对图片的引用路径,如果你也正在使用YOLOv8模型,可以将以下代码直接拷贝下来,在你的结果目录(与模型结果图片同级目录)新建一个HTML文档,将代码粘贴进去,在浏览器打开该HTML文件,就能看到你的结果图片在网页中的调用,结合文字解释帮助你快速分析模型结果。
·
基于【WT】YOLO模型训练结果文件详细分析与理论认识-以YOLOv8为例-CSDN博客文章,我们重新编制了对图片的引用路径,如果你也正在使用YOLOv8模型,可以将以下代码直接拷贝下来,在你的结果目录(与模型结果图片同级目录)新建一个HTML文档,将代码粘贴进去,在浏览器打开该HTML文件,就能看到你的结果图片在网页中的调用,结合文字解释帮助你快速分析模型结果。
你也可以直接下载HTML文件丢到你的模型训练结果目录下,直接打开即可,免费下载地址:【免费】YOLOv8结果图片引用进行汇集的单页HTML模板资源-CSDN文库
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>YOLO模型训练结果文件详细分析与理论认识</title>
<style>
/* 全局样式 */
body {
font-family: 'Arial', sans-serif;
line-height: 1.6;
color: #333;
max-width: 1200px;
margin: 0 auto;
padding: 20px;
background-color: #f9f9f9;
}
h1, h2, h3 {
color: #2c3e50;
}
h1 {
text-align: center;
padding-bottom: 20px;
border-bottom: 2px solid #3498db;
}
h2 {
margin-top: 30px;
margin-bottom: 15px;
}
h3 {
margin-top: 20px;
margin-bottom: 10px;
}
p {
margin-bottom: 15px;
}
/* 图片样式 */
.image-container {
text-align: center;
margin: 20px 0;
}
.image-container img {
max-width: 100%;
height: auto;
border: 1px solid #ddd;
border-radius: 5px;
box-shadow: 0 2px 5px rgba(0,0,0,0.1);
}
/* 表格样式 */
table {
width: 100%;
border-collapse: collapse;
margin: 20px 0;
background-color: white;
box-shadow: 0 2px 5px rgba(0,0,0,0.1);
border-radius: 5px;
overflow: hidden;
}
th, td {
padding: 12px 15px;
text-align: left;
border-bottom: 1px solid #ddd;
}
th {
background-color: #3498db;
color: white;
}
tr:nth-child(even) {
background-color: #f2f2f2;
}
/* 公式样式 */
.formula {
background-color: #f8f9fa;
padding: 15px;
border-radius: 5px;
margin: 20px 0;
font-family: 'Courier New', monospace;
}
/* 导航栏样式 */
.navbar {
background-color: #3498db;
padding: 10px 0;
margin-bottom: 30px;
border-radius: 5px;
}
.navbar ul {
list-style-type: none;
padding: 0;
display: flex;
justify-content: center;
}
.navbar li {
margin: 0 15px;
}
.navbar a {
color: white;
text-decoration: none;
font-weight: bold;
transition: color 0.3s;
}
.navbar a:hover {
color: #f0f0f0;
}
footer {
text-align: center;
padding: 20px 0;
color: #7f8c8d;
font-size: 14px;
}
/* 响应式设计 */
@media (max-width: 768px) {
.navbar ul {
flex-direction: column;
align-items: center;
}
.navbar li {
margin: 5px 0;
}
}
</style>
</head>
<body>
<header>
<h1>YOLO模型训练结果文件详细分析与理论认识</h1>
<nav class="navbar">
<ul>
<li><a href="#confusion_matrix">混淆矩阵</a></li>
<li><a href="#normalized_confusion_matrix">归一化混淆矩阵</a></li>
<li><a href="#f1_curve">F1曲线</a></li>
<li><a href="#labels_distribution">标签分布图</a></li>
<li><a href="#labels_correlation">标签相关性分布图</a></li>
<li><a href="#precision_curve">精度曲线</a></li>
<li><a href="#pr_curve">PR曲线</a></li>
<li><a href="#recall_curve">召回率曲线</a></li>
<li><a href="#results_csv">results.csv</a></li>
<li><a href="#results_png">results.png</a></li>
<li><a href="#train_batches">训练批次标注图</a></li>
<li><a href="#val_batches">验证批次标注和预测图</a></li>
</ul>
</nav>
</header>
<main>
<section id="confusion_matrix">
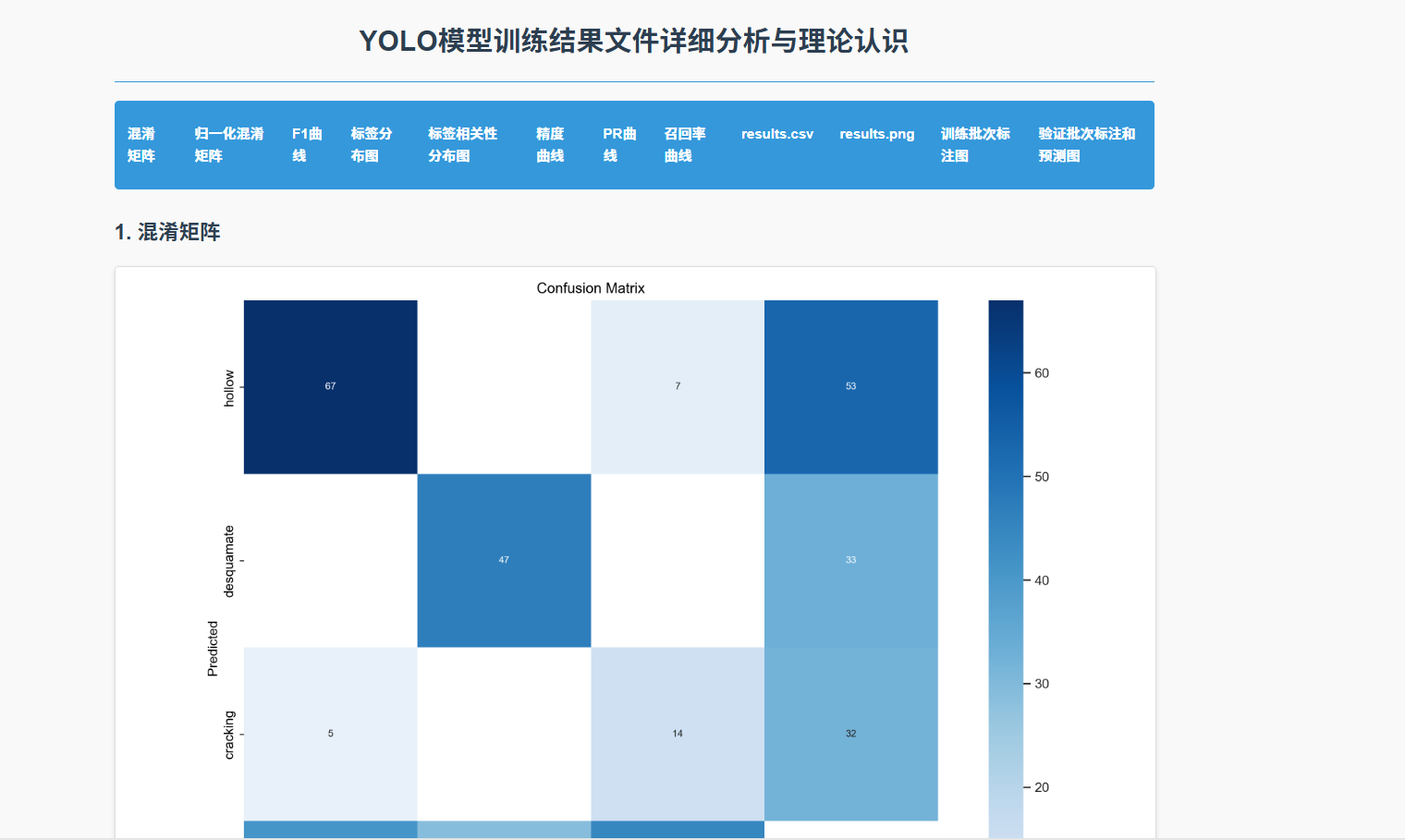
<h2>1. 混淆矩阵</h2>
<p>文件名称:confusion_matrix.png</p>
<div class="image-container">
<img src="confusion_matrix.png" alt="混淆矩阵">
</div>
<h3>1.1 定义与作用</h3>
<p>混淆矩阵是机器学习中用于评估分类模型性能的一种重要工具。它是一个表格,用于描述分类模型在测试数据上的预测结果与实际标签之间的关系。混淆矩阵的主要作用是直观地展示模型的分类效果,帮助研究者了解模型在不同类别上的预测准确性、误分类情况等,从而为进一步优化模型提供依据。</p>
<h3>1.2 混淆矩阵的构成元素</h3>
<p>混淆矩阵通常是一个二维矩阵,其行表示实际类别,列表示预测类别。对于一个二分类问题,混淆矩阵的构成元素如下:</p>
<ul>
<li><strong>真正例(TP, True Positive)</strong>:模型正确预测为正类的样本数量。</li>
<li><strong>假正例(FP, False Positive)</strong>:模型错误地将负类预测为正类的样本数量。</li>
<li><strong>真负例(TN, True Negative)</strong>:模型正确预测为负类的样本数量。</li>
<li><strong>假负例(FN, False Negative)</strong>:模型错误地将正类预测为负类的样本数量。</li>
</ul>
<h3>1.3 如何解读混淆矩阵</h3>
<p>通过混淆矩阵,可以直观地了解模型在各个类别上的表现:</p>
<ul>
<li><strong>对角线元素</strong>:表示模型正确分类的样本数量,对角线上的值越大,说明模型在对应类别上的分类效果越好。</li>
<li><strong>非对角线元素</strong>:表示模型错误分类的样本数量,非对角线上的值越小,说明模型的误分类情况越少。</li>
<li><strong>每一行的和</strong>:表示实际属于该类别的样本总数。</li>
<li><strong>每一列的和</strong>:表示模型预测为该类别的样本总数。</li>
</ul>
<p>通过分析混淆矩阵,可以计算出一些重要的评估指标,如准确率(Accuracy)、精确率(Precision)、召回率(Recall)和 F1 分数等,这些指标能够更全面地反映模型的性能。</p>
</section>
<section id="normalized_confusion_matrix">
<h2>2. 归一化混淆矩阵</h2>
<p>文件名称:confusion_matrix_normalized.png</p>
<div class="image-container">
<img src="confusion_matrix_normalized.png" alt="归一化混淆矩阵">
</div>
<h3>2.1 归一化的目的</h3>
<p>归一化混淆矩阵的目的是为了更好地比较不同类别之间的分类性能,尤其是在类别不平衡的情况下。在实际应用中,数据集中的各类别样本数量可能差异较大,例如某些类别可能只有少数样本,而其他类别则有大量样本。这种情况下,直接使用普通混淆矩阵可能会导致对模型性能的误判。通过归一化,可以将混淆矩阵中的每个元素转换为相对比例,从而更公平地评估模型在各个类别上的表现。</p>
<h3>2.2 归一化方法与计算公式</h3>
<p>归一化混淆矩阵通常有两种常见的归一化方法:</p>
<h4>2.2.1 按行归一化</h4>
<p>按行归一化是将混淆矩阵的每一行元素分别除以该行的总和。这种方法的计算公式如下:</p>
<div class="formula">
normalized_confusion_matrix<sub>ij</sub> = confusion_matrix<sub>ij</sub> / Σ<sub>k=1</sub><sup>n</sup> confusion_matrix<sub>ik</sub>
</div>
<p>其中,i 表示实际类别,j 表示预测类别,n 是类别的总数。按行归一化后的混淆矩阵每一行的和为1,这使得每一行的元素表示在给定实际类别的情况下,模型预测为各个类别的概率。</p>
<h4>2.2.2 按列归一化</h4>
<p>按列归一化是将混淆矩阵的每一列元素分别除以该列的总和。计算公式如下:</p>
<div class="formula">
normalized_confusion_matrix<sub>ij</sub> = confusion_matrix<sub>ij</sub> / Σ<sub>k=1</sub><sup>n</sup> confusion_matrix<sub>kj</sub>
</div>
<p>按列归一化后的混淆矩阵每一列的和为1,这使得每一列的元素表示在给定预测类别的情况下,实际类别为各个类别的概率。</p>
<h3>2.3 与普通混淆矩阵的对比</h3>
<p>归一化混淆矩阵与普通混淆矩阵的主要区别在于数据的表示方式和应用场景:</p>
<h4>2.3.1 数据表示方式</h4>
<ul>
<li><strong>普通混淆矩阵</strong>:直接显示模型在各个类别上的预测与实际标签的匹配数量,以绝对数值表示。</li>
<li><strong>归一化混淆矩阵</strong>:将这些数值转换为相对比例,通常以百分比或小数形式表示,便于直观比较不同类别之间的分类效果。</li>
</ul>
<h4>2.3.2 应用场景</h4>
<ul>
<li><strong>普通混淆矩阵</strong>:适用于样本数量较多且类别相对平衡的情况,能够直观地展示模型的分类效果和误分类情况。</li>
<li><strong>归一化混淆矩阵</strong>:在类别不平衡的情况下更具优势,能够更公平地评估模型在各个类别上的性能,避免因样本数量差异导致的误判。例如,在某些类别样本数量较少时,归一化混淆矩阵可以更清晰地展示模型在这些类别上的分类准确性。</li>
</ul>
</section>
<!-- 继续添加其他部分的HTML代码,按照文档内容进行编写 -->
<!-- 以下是其他部分的示例,实际代码需要根据文档内容完整编写 -->
<section id="f1_curve">
<h2>3. F1曲线</h2>
<p>文件名称:F1_curve.png</p>
<div class="image-container">
<img src="F1_curve.png" alt="F1曲线">
</div>
<h3>3.1 F1分数的定义</h3>
<p>F1分数是机器学习中用于评估分类模型性能的一个重要指标,它是精确率(Precision)和召回率(Recall)的调和平均数。F1分数的取值范围在0到1之间,值越接近1,表示模型的性能越好。具体来说,F1分数综合考虑了模型在预测正样本时的准确性和完整性,能够平衡精确率和召回率之间的关系,避免因过度关注某一指标而导致模型性能评估的片面性。</p>
<h3>3.2 F1分数的计算方法</h3>
<p>F1分数的计算公式如下:</p>
<div class="formula">
F1 = 2 × (Precision × Recall) / (Precision + Recall)
</div>
<p>其中,精确率(Precision)表示模型预测为正类的样本中实际为正类的比例,计算公式为:</p>
<div class="formula">
Precision = TP / (TP + FP)
</div>
<p>召回率(Recall)表示实际为正类的样本中被模型正确预测为正类的比例,计算公式为:</p>
<div class="formula">
Recall = TP / (TP + FN)
</div>
<p>在这里,TP表示真正例(True Positive),即模型正确预测为正类的样本数量;FP表示假正例(False Positive),即模型错误地将负类预测为正类的样本数量;FN表示假负例(False Negative),即模型错误地将正类预测为负类的样本数量。</p>
<h3>3.3 F1曲线的意义与应用</h3>
<p>F1曲线是一种用于展示F1分数随置信度阈值变化的图表。在目标检测或分类任务中,模型会为每个预测结果分配一个置信度值,表示模型对该预测结果的自信程度。通过调整置信度阈值,可以改变模型的预测结果,从而影响精确率和召回率。F1曲线的意义在于:</p>
<ul>
<li><strong>平衡精确率和召回率</strong>:F1曲线能够直观地展示在不同置信度阈值下,模型的F1分数变化情况。通过观察F1曲线,可以找到一个合适的置信度阈值,使得模型在精确率和召回率之间达到较好的平衡。</li>
<li><strong>评估模型性能</strong>:F1曲线的形状和位置可以反映模型的整体性能。一般来说,F1曲线越靠近右上角,表示模型在不同置信度阈值下都能保持较高的F1分数,即模型的性能越好。如果F1曲线在较低置信度阈值下就达到了较高的F1分数,并且在较高置信度阈值下仍能保持相对稳定的F1分数,这说明模型在预测时能够较好地平衡精确率和召回率,具有较高的准确性和鲁棒性。</li>
<li><strong>比较不同模型</strong>:F1曲线还可以用于比较不同模型之间的性能。当多个模型的F1曲线在同一图表中展示时,可以通过比较曲线的位置和形状来判断哪个模型在不同置信度阈值下表现更好。如果一个模型的F1曲线始终高于另一个模型的F1曲线,那么可以认为该模型在整体性能上优于另一个模型。</li>
</ul>
</section>
<!-- 继续添加其他部分的HTML代码 -->
<!-- 以下是标签分布图部分的示例 -->
<section id="labels_distribution">
<h2>4. 标签分布图</h2>
<p>文件名称:labels.jpg</p>
<div class="image-container">
<img src="labels.jpg" alt="标签分布图">
</div>
<h3>4.1 标签分布图的绘制方法</h3>
<p>标签分布图是通过对训练数据集中各类别标签的数量进行统计并以可视化方式呈现的图表。其绘制方法通常包括以下步骤:</p>
<ol>
<li><strong>数据收集</strong>:从训练数据集中提取所有样本的标签信息。</li>
<li><strong>数据统计</strong>:统计每个类别标签出现的次数,得到各类别的样本数量。</li>
<li><strong>可视化绘制</strong>:使用柱状图、饼图或其他合适的图表形式将各类别的样本数量进行可视化展示。例如,柱状图可以直观地显示每个类别对应的样本数量,饼图则可以展示各类别在总样本中所占的比例。</li>
</ol>
<h3>4.2 标签分布图反映的信息</h3>
<p>标签分布图能够直观地展示训练数据集中各类别标签的数量分布情况,反映以下重要信息:</p>
<ul>
<li><strong>类别平衡性</strong>:通过观察各类别标签的数量是否相近,可以判断数据集是否存在类别不平衡问题。如果某些类别的样本数量远多于其他类别,说明数据集存在类别不平衡,这可能会影响模型的训练效果,导致模型对多数类别的预测性能较好,而对少数类别的预测性能较差。</li>
<li><strong>数据集的代表性</strong>:标签分布图可以反映训练数据集在类别分布上是否具有代表性。如果数据集中的类别分布与实际应用场景中的类别分布相近,那么模型在实际应用中可能具有更好的泛化能力;反之,如果数据集的类别分布与实际应用差异较大,模型的泛化能力可能会受到限制。</li>
<li><strong>潜在的偏差</strong>:如果标签分布图显示某些类别明显占主导地位,可能暗示数据集中存在潜在的偏差,这种偏差可能来源于数据采集过程中的选择偏差或其他因素。这种偏差可能会影响模型的公平性和准确性,需要在数据预处理阶段加以关注和处理。</li>
</ul>
<h3>4.3 对模型训练的意义</h3>
<p>标签分布图对模型训练具有重要的指导意义,主要体现在以下几个方面:</p>
<ul>
<li><strong>指导数据预处理</strong>:如果发现数据集存在类别不平衡问题,可以根据标签分布图采取相应的数据预处理措施,如过采样(对少数类别进行样本增加)或欠采样(对多数类别进行样本减少),以平衡数据集中的类别分布,提高模型对少数类别的预测性能。</li>
<li><strong>选择合适的评估指标</strong>:了解标签分布情况后,可以更合理地选择模型评估指标。在类别不平衡的情况下,仅使用准确率(Accuracy)作为评估指标可能会产生误导,因为模型可能对多数类别预测准确,但对少数类别预测效果很差。此时,可以结合精确率(Precision)、召回率(Recall)、F1分数等指标,更全面地评估模型的性能。</li>
<li><strong>调整模型训练策略</strong>:标签分布图可以帮助研究人员调整模型训练策略。例如,对于类别不平衡的数据集,可以采用加权损失函数,为少数类别分配更高的权重,使模型在训练过程中更加关注少数类别的样本,从而提高模型的整体性能。</li>
<li><strong>预测模型性能</strong>:通过分析标签分布图,可以在一定程度上预测模型在实际应用中的性能表现。如果训练数据集的类别分布与实际应用场景相近,且模型在训练集上表现良好,那么模型在实际应用中可能具有较好的性能;反之,如果数据集的类别分布与实际应用差异较大,即使模型在训练集上表现良好,也可能在实际应用中出现性能下降的情况。</li>
</ul>
</section>
<!-- 继续添加其他部分的HTML代码 -->
<!-- 以下是标签相关性分布图部分的示例 -->
<section id="labels_correlation">
<h2>5. 标签相关性分布图</h2>
<p>文件名称:labels_correlogram.jpg</p>
<div class="image-container">
<img src="labels_correlogram.jpg" alt="标签相关性分布图">
</div>
<h3>5.1 标签相关性的定义与计算方法</h3>
<p>标签相关性是指数据集中不同标签之间存在的关联程度。在多标签分类任务中,一个样本可能同时属于多个类别,这些类别之间可能存在一定的相关性。例如,在图像识别中,一张包含“猫”的图片很可能同时包含“动物”这一标签,而“猫”和“动物”之间就存在正相关性。</p>
<p>计算标签相关性通常有以下几种方法:</p>
<h4>5.1.1 皮尔逊相关系数</h4>
<p>用于衡量两个变量之间的线性相关性,取值范围为[-1, 1]。对于标签 i 和 j,其计算公式为:</p>
<div class="formula">
ρ<sub>ij</sub> = Σ(x<sub>ik</sub> - x̄<sub>i</sub>)(x<sub>jk</sub> - x̄<sub>j</sub>) / √[Σ(x<sub>ik</sub> - x̄<sub>i</sub>)² Σ(x<sub>jk</sub> - x̄<sub>j</sub>)²]
</div>
<p>其中,x<sub>ik</sub> 表示样本 k 是否属于标签 i(1 表示属于,0 表示不属于),x̄<sub>i</sub> 是标签 i 的均值。</p>
<h4>5.1.2 互信息</h4>
<p>用于衡量两个变量之间的相互依赖性,取值范围为 [0, +∞]。互信息越大,表示两个标签之间的相关性越强。对于标签 i 和 j,其计算公式为:</p>
<div class="formula">
I(i, j) = ΣΣ p(x<sub>i</sub>, x<sub>j</sub>) log [p(x<sub>i</sub>, x<sub>j</sub>)/(p(x<sub>i</sub>)p(x<sub>j</sub>))]
</div>
<p>其中,p(x<sub>i</sub>) 和 p(x<sub>j</sub>) 分别是标签 i 和 j 的边缘概率,p(x<sub>i</sub>, x<sub>j</sub>) 是标签 i 和 j 的联合概率。</p>
<h3>5.2 标签相关性分布图的解读</h3>
<p>标签相关性分布图通过可视化的方式展示了不同标签之间的相关性。通常以矩阵的形式呈现,矩阵的行和列分别表示不同的标签,矩阵中的每个元素表示两个标签之间的相关性强度。对于皮尔逊相关系数,正值表示正相关,负值表示负相关;对于互信息,值越大表示相关性越强。</p>
<ul>
<li><strong>正相关</strong>:如果两个标签之间存在正相关性,说明当一个标签出现时,另一个标签也更有可能出现。例如,在目标检测中,“汽车”和“道路”之间通常存在正相关性,因为汽车通常出现在道路上。</li>
<li><strong>负相关</strong>:如果两个标签之间存在负相关性,说明当一个标签出现时,另一个标签出现的可能性会降低。例如,“白天”和“夜晚”这两个标签之间存在负相关性。</li>
<li><strong>无相关性</strong>:如果两个标签之间的相关性接近于零,说明它们之间没有明显的关联。</li>
</ul>
<h3>5.3 对模型性能的影响</h3>
<p>标签相关性对模型性能有着重要的影响:</p>
<ul>
<li><strong>提高模型泛化能力</strong>:如果模型能够捕捉到标签之间的相关性,它在处理新的、未见过的数据时,能够更好地利用这些相关性进行预测,从而提高模型的泛化能力。</li>
<li><strong>优化模型结构</strong>:了解标签之间的相关性可以帮助设计更合理的模型结构。例如,在多标签分类任务中,如果某些标签之间存在强相关性,可以将这些标签合并为一个复合标签,或者在模型中引入共享层来捕捉这些相关性。</li>
<li><strong>减少过拟合</strong>:当数据集中存在类别不平衡时,模型可能会对多数类别过度拟合,而忽略少数类别。通过分析标签相关性,可以发现少数类别与其他类别的潜在关系,从而采取相应的措施,如数据增强或加权损失函数,减少过拟合现象。</li>
<li><strong>提升预测准确性</strong>:如果模型能够准确地利用标签之间的相关性,它可以更准确地预测样本的标签组合,从而提高预测的准确性。例如,在图像识别中,如果模型知道“猫”和“动物”之间存在正相关性,当它检测到“猫”时,可以更有信心地预测“动物”这一标签。</li>
</ul>
</section>
<!-- 继续添加其他部分的HTML代码 -->
<!-- 以下是精度曲线部分的示例 -->
<section id="precision_curve">
<h2>6. 精度曲线</h2>
<p>文件名称:P_curve.png</p>
<div class="image-container">
<img src="P_curve.png" alt="精度曲线">
</div>
<h3>6.1 精度的定义与计算公式</h3>
<p>精度(Precision)是评估分类模型性能的重要指标之一,它反映了模型预测为正类的样本中实际为正类的比例。对于目标检测任务,精度的计算公式为:</p>
<div class="formula">
Precision = TP / (TP + FP)
</div>
<p>其中,TP(True Positive)表示模型正确预测为正类的样本数量,FP(False Positive)表示模型错误地将负类预测为正类的样本数量。</p>
<p>在目标检测中,精度的计算通常基于置信度阈值。模型会对每个预测框分配一个置信度值,表示模型对该预测框的自信程度。通过调整置信度阈值,可以改变模型的预测结果,从而影响精度的计算。</p>
<h3>6.2 精度曲线的走势分析</h3>
<p>精度曲线展示了精度随置信度阈值变化的趋势。通常,精度曲线具有以下特点:</p>
<ul>
<li><strong>高置信度阈值</strong>:当置信度阈值较高时,模型只保留置信度较高的预测框,此时FP数量较少,精度通常较高。但随着置信度阈值的进一步提高,TP数量也会减少,导致精度曲线趋于平稳或略有下降。</li>
<li><strong>低置信度阈值</strong>:当置信度阈值较低时,模型会保留更多的预测框,包括大量可能错误的预测框(FP),此时精度通常较低。</li>
<li><strong>最优置信度阈值</strong>:通过观察精度曲线,可以找到一个合适的置信度阈值,使得模型在精度和召回率之间达到较好的平衡。例如,在某些应用中,可能需要较高的精度来确保预测结果的可靠性,此时可以选择较高的置信度阈值;而在其他应用中,可能更关注召回率,此时可以选择较低的置信度阈值。</li>
</ul>
<h3>6.3 精度曲线在模型评估中的作用</h3>
<p>精度曲线在模型评估中具有重要作用,主要体现在以下几个方面:</p>
<ul>
<li><strong>评估模型性能</strong>:精度曲线能够直观地展示模型在不同置信度阈值下的性能变化。通过观察曲线的走势,可以判断模型在高置信度和低置信度情况下的表现。一般来说,精度曲线越靠近右上角,表示模型在高置信度下能够保持较高的精度,说明模型的性能较好。</li>
<li><strong>选择合适的置信度阈值</strong>:精度曲线可以帮助研究人员和开发者选择合适的置信度阈值。在实际应用中,不同的应用场景对精度和召回率的要求不同。通过分析精度曲线,可以找到一个合适的置信度阈值,使得模型在满足特定需求的情况下达到最佳性能。</li>
<li><strong>比较不同模型</strong>:精度曲线还可以用于比较不同模型之间的性能。当多个模型的精度曲线在同一图表中展示时,可以通过比较曲线的位置和形状来判断哪个模型在不同置信度阈值下表现更好。如果一个模型的精度曲线始终高于另一个模型的精度曲线,那么可以认为该模型在精度方面优于另一个模型。</li>
<li><strong>指导模型优化</strong>:通过分析精度曲线,可以发现模型在某些置信度阈值下的性能瓶颈。例如,如果精度曲线在低置信度阈值下下降较快,可能说明模型在处理低置信度预测时存在较多的误分类。此时,可以通过调整模型的训练策略、优化损失函数或改进数据预处理方法来提高模型在低置信度阈值下的性能。</li>
</ul>
</section>
<!-- 继续添加其他部分的HTML代码 -->
<!-- 以下是PR曲线部分的示例 -->
<section id="pr_curve">
<h2>7. 精度 - 召回率曲线</h2>
<p>文件名称:PR_curve.png</p>
<div class="image-container">
<img src="PR_curve.png" alt="PR曲线">
</div>
<h3>7.1 召回率的定义与计算公式</h3>
<p>召回率(Recall)是评估分类模型性能的重要指标之一,它反映了模型能够正确识别出的正样本占所有实际正样本的比例。对于目标检测任务,召回率的计算公式为:</p>
<div class="formula">
Recall = TP / (TP + FN)
</div>
<p>其中,TP(True Positive)表示模型正确预测为正类的样本数量,FN(False Negative)表示模型错误地将正类预测为负类的样本数量。</p>
<p>在目标检测中,召回率的计算通常基于置信度阈值。模型会对每个预测框分配一个置信度值,表示模型对该预测框的自信程度。通过调整置信度阈值,可以改变模型的预测结果,从而影响召回率的计算。</p>
<h3>7.2 精度与召回率的关系</h3>
<p>精度(Precision)和召回率(Recall)是评估分类模型性能的两个重要指标,它们之间存在一定的关系:</p>
<ul>
<li><strong>平衡关系</strong>:精度和召回率通常是一对矛盾的指标。提高精度可能会降低召回率,反之亦然。例如,当置信度阈值较高时,模型只保留置信度较高的预测框,此时FP数量较少,精度较高,但FN数量可能增加,导致召回率较低;而当置信度阈值较低时,模型会保留更多的预测框,包括大量可能错误的预测框(FP),此时召回率较高,但精度可能较低。</li>
<li><strong>综合评估</strong>:在实际应用中,需要根据具体需求平衡精度和召回率。例如,在某些应用中,可能需要较高的精度来确保预测结果的可靠性,此时可以选择较高的置信度阈值;而在其他应用中,可能更关注召回率,此时可以选择较低的置信度阈值。</li>
</ul>
<h3>7.3 PR曲线的应用与解读</h3>
<p>PR曲线(Precision-Recall Curve)是一种用于展示模型在不同置信度阈值下精度和召回率变化的图表。它能够直观地反映模型在不同置信度阈值下的性能表现,帮助研究人员和开发者更好地理解模型的行为,选择合适的置信度阈值,从而优化模型的性能。</p>
<h4>7.3.1 PR曲线的形状与意义</h4>
<ul>
<li><strong>曲线形状</strong>:PR曲线通常从左上角向右下角延伸。曲线越靠近右上角,表示模型在不同置信度阈值下都能保持较高的精度和召回率,即模型的性能越好。如果PR曲线在较高召回率下仍能保持较高的精度,说明模型在预测时能够较好地平衡精确率和召回率,具有较高的准确性和鲁棒性。</li>
<li><strong>面积意义</strong>:PR曲线下的面积(AUC-PR)可以用来量化模型的整体性能。AUC-PR值越大,表示模型在不同置信度阈值下综合考虑精度和召回率的性能越好。一般来说,AUC-PR值接近1的模型性能较好。</li>
</ul>
<h4>7.3.2 PR曲线的应用</h4>
<ul>
<li><strong>模型评估</strong>:PR曲线能够直观地展示模型在不同置信度阈值下的性能变化。通过观察曲线的走势,可以判断模型在高置信度和低置信度情况下的表现。一般来说,PR曲线越靠近右上角,表示模型在不同置信度阈值下都能保持较高的精度和召回率,说明模型的性能较好。</li>
<li><strong>选择合适的置信度阈值</strong>:PR曲线可以帮助研究人员和开发者选择合适的置信度阈值。在实际应用中,不同的应用场景对精度和召回率的要求不同。通过分析PR曲线,可以找到一个合适的置信度阈值,使得模型在满足特定需求的情况下达到最佳性能。</li>
<li><strong>比较不同模型</strong>:PR曲线还可以用于比较不同模型之间的性能。当多个模型的PR曲线在同一图表中展示时,可以通过比较曲线的位置和形状来判断哪个模型在不同置信度阈值下表现更好。如果一个模型的PR曲线始终高于另一个模型的PR曲线,那么可以认为该模型在综合考虑精度和召回率的性能上优于另一个模型。</li>
<li><strong>指导模型优化</strong>:通过分析PR曲线,可以发现模型在某些置信度阈值下的性能瓶颈。例如,如果PR曲线在低置信度阈值下精度下降较快,可能说明模型在处理低置信度预测时存在较多的误分类。此时,可以通过调整模型的训练策略、优化损失函数或改进数据预处理方法来提高模型在低置信度阈值下的性能。</li>
</ul>
</section>
<!-- 继续添加其他部分的HTML代码 -->
<!-- 以下是召回率曲线部分的示例 -->
<section id="recall_curve">
<h2>8. 召回率曲线</h2>
<p>文件名称:R_curve.png</p>
<div class="image-container">
<img src="R_curve.png" alt="召回率曲线">
</div>
<h3>8.1 召回率曲线的走势分析</h3>
<p>召回率曲线展示了召回率随置信度阈值变化的趋势。通常,召回率曲线具有以下特点:</p>
<ul>
<li><strong>高置信度阈值</strong>:当置信度阈值较高时,模型只保留置信度较高的预测框,此时FN数量较多,召回率通常较低。例如,在目标检测中,如果模型只保留置信度高于0.9的预测框,可能会漏掉很多实际为正类但置信度稍低的样本,导致召回率下降。</li>
<li><strong>低置信度阈值</strong>:当置信度阈值较低时,模型会保留更多的预测框,包括大量可能错误的预测框(FP),此时FN数量减少,召回率通常较高。例如,当置信度阈值为0.1时,模型可能会将更多的样本预测为正类,从而提高召回率,但可能会引入更多的误分类。</li>
<li><strong>最优置信度阈值</strong>:通过观察召回率曲线,可以找到一个合适的置信度阈值,使得模型在召回率和精度之间达到较好的平衡。例如,在某些应用中,可能需要较高的召回率来确保不漏掉重要样本,此时可以选择较低的置信度阈值;而在其他应用中,可能更关注精度,此时可以选择较高的置信度阈值。</li>
</ul>
<h3>8.2 召回率曲线在模型评估中的作用</h3>
<p>召回率曲线在模型评估中具有重要作用,主要体现在以下几个方面:</p>
<ul>
<li><strong>评估模型性能</strong>:召回率曲线能够直观地展示模型在不同置信度阈值下的性能变化。通过观察曲线的走势,可以判断模型在高置信度和低置信度情况下的表现。一般来说,召回率曲线越靠近右上角,表示模型在低置信度下能够保持较高的召回率,说明模型的性能较好。</li>
<li><strong>选择合适的置信度阈值</strong>:召回率曲线可以帮助研究人员和开发者选择合适的置信度阈值。在实际应用中,不同的应用场景对召回率和精度的要求不同。通过分析召回率曲线,可以找到一个合适的置信度阈值,使得模型在满足特定需求的情况下达到最佳性能。</li>
<li><strong>比较不同模型</strong>:召回率曲线还可以用于比较不同模型之间的性能。当多个模型的召回率曲线在同一图表中展示时,可以通过比较曲线的位置和形状来判断哪个模型在不同置信度阈值下表现更好。如果一个模型的召回率曲线始终高于另一个模型的召回率曲线,那么可以认为该模型在召回率方面优于另一个模型。</li>
<li><strong>指导模型优化</strong>:通过分析召回率曲线,可以发现模型在某些置信度阈值下的性能瓶颈。例如,如果召回率曲线在高置信度阈值下上升缓慢,可能说明模型在处理高置信度预测时存在较多的漏检。此时,可以通过调整模型的训练策略、优化损失函数或改进数据预处理方法来提高模型在高置信度阈值下的性能。</li>
</ul>
<h3>8.3 精度与召回率的权衡</h3>
<p>精度(Precision)和召回率(Recall)是评估分类模型性能的两个重要指标,它们之间存在一定的权衡关系:</p>
<ul>
<li><strong>平衡关系</strong>:提高精度可能会降低召回率,反之亦然。例如,当置信度阈值较高时,模型只保留置信度较高的预测框,此时FP数量较少,精度较高,但FN数量可能增加,导致召回率较低;而当置信度阈值较低时,模型会保留更多的预测框,包括大量可能错误的预测框(FP),此时召回率较高,但精度可能较低。</li>
<li><strong>综合评估</strong>:在实际应用中,需要根据具体需求平衡精度和召回率。例如,在某些应用中,可能需要较高的精度来确保预测结果的可靠性,此时可以选择较高的置信度阈值;而在其他应用中,可能更关注召回率,此时可以选择较低的置信度阈值。</li>
<li><strong>F1分数的平衡作用</strong>:F1分数是精度和召回率的调和平均数,能够综合考虑精度和召回率的平衡。通过观察F1分数曲线,可以找到一个合适的置信度阈值,使得模型在精度和召回率之间达到较好的平衡。F1分数的计算公式为:</li>
</ul>
<div class="formula">
F1 = 2 × (Precision × Recall) / (Precision + Recall)
</div>
<p>通过调整置信度阈值,可以优化F1分数,从而在精度和召回率之间找到最佳平衡点。</p>
</section>
<!-- 继续添加其他部分的HTML代码 -->
<!-- 以下是results.csv部分的示例 -->
<section id="results_csv">
<h2>9. results.csv 各训练轮次指标汇总表</h2>
<h3>9.1 results.csv文件的结构与内容</h3>
<p>`results.csv` 文件是 YOLO 模型训练过程中生成的重要数据记录文件,它以表格形式汇总了每个训练轮次(epoch)的各项关键指标。文件的结构通常包括以下列:</p>
<ul>
<li><strong>Epoch</strong>:表示当前训练的轮次编号,从 0 开始递增,反映了训练进度。</li>
<li><strong>Precision</strong>:精确率,用于衡量模型预测为正类的样本中实际为正类的比例,计算公式为 Precision = TP / (TP + FP),值越高表示模型预测正样本的准确性越高。</li>
<li><strong>Recall</strong>:召回率,用于衡量模型能够正确识别出的正样本占所有实际正样本的比例,计算公式为 Recall = TP / (TP + FN),值越高表示模型对正样本的检测能力越强。</li>
<li><strong>mAP</strong>:平均精度均值(mean Average Precision),综合考虑了不同类别在不同置信度阈值下的平均精度,是目标检测任务中衡量模型性能的关键指标,值越接近 1 表示模型性能越好。</li>
<li><strong>F1</strong>:F1 分数,是精确率和召回率的调和平均数,计算公式为 F1 = 2 × (Precision × Recall) / (Precision + Recall),它平衡了精确率和召回率,值越高表示模型在两者之间达到了较好的平衡。</li>
<li><strong>Loss</strong>:损失值,反映了模型在当前轮次的训练误差,通常包括分类损失、定位损失等,值越低表示模型的训练效果越好,与训练目标的契合度越高。</li>
<li><strong>Learning Rate</strong>:学习率,控制模型参数更新的步长,是训练过程中的重要超参数。不同的学习率策略(如固定学习率、学习率衰减等)会影响模型的收敛速度和最终性能。</li>
<li><strong>Time</strong>:每个轮次的训练时间,反映了训练过程的效率,对于大规模数据集和复杂模型的训练时间管理具有重要意义。</li>
</ul>
<h3>9.2 主要指标的含义与重要性</h3>
<ul>
<li><strong>精确率(Precision)</strong>:在目标检测中,精确率反映了模型预测为正类的样本中实际为正类的比例,是衡量模型预测准确性的重要指标。高精确率意味着模型在预测正样本时的可靠性较高,能够有效减少误报。</li>
<li><strong>召回率(Recall)</strong>:召回率衡量了模型能够正确识别出的正样本占所有实际正样本的比例,反映了模型对正样本的检测能力。高召回率意味着模型能够较好地检测到大部分正样本,减少漏检。</li>
<li><strong>mAP(平均精度均值)</strong>:mAP 是目标检测任务中衡量模型性能的综合指标,它考虑了不同类别在不同置信度阈值下的平均精度。mAP 越高,表示模型在不同类别和不同置信度阈值下都能保持较高的检测精度,是评价模型整体性能的关键指标。</li>
<li><strong>F1 分数</strong>:F1 分数是精确率和召回率的调和平均数,能够平衡两者之间的关系。在实际应用中,通常需要在精确率和召回率之间找到一个合适的平衡点,F1 分数提供了一个综合评估模型性能的指标,值越接近 1 表示模型在精确率和召回率之间达到了较好的平衡。</li>
<li><strong>损失值(Loss)</strong>:损失值反映了模型在当前轮次的训练误差,是训练过程中优化模型参数的目标。较低的损失值通常意味着模型的预测结果更接近真实标签,训练效果更好。通过观察损失值的变化趋势,可以判断模型是否收敛,以及是否存在过拟合或欠拟合等问题。</li>
<li><strong>学习率(Learning Rate)</strong>:学习率是训练过程中的重要超参数,控制模型参数更新的步长。合适的学习率可以加速模型的收敛速度,提高训练效率。过高的学习率可能导致模型震荡,难以收敛;过低的学习率则会使训练过程缓慢,甚至陷入局部最优。通过调整学习率策略,如学习率衰减,可以更好地平衡模型的收敛速度和最终性能。</li>
<li><strong>训练时间(Time)</strong>:每个轮次的训练时间反映了训练过程的效率,对于大规模数据集和复杂模型的训练时间管理具有重要意义。较短的训练时间可以提高训练效率,加快模型开发和迭代的速度。通过优化训练算法、硬件加速等手段,可以有效缩短训练时间,提高模型的实用性。</li>
</ul>
<h3>9.3 如何利用 results.csv 分析训练过程</h3>
<ul>
<li><strong>观察指标变化趋势</strong>:通过绘制指标随训练轮次变化的曲线图,可以直观地观察到精确率、召回率、mAP、F1 分数、损失值等指标的变化趋势。例如,如果损失值逐渐降低且趋于平稳,同时精确率、召回率、mAP 和 F1 分数逐渐升高并趋于稳定,说明模型在训练过程中逐渐收敛,性能逐渐提升。</li>
<li><strong>判断模型收敛情况</strong>:分析损失值的变化趋势是判断模型收敛的重要依据。如果损失值在训练过程中持续下降,但在某个轮次后变化趋于平缓,说明模型已经基本收敛。此时,可以考虑停止训练,避免过度训练导致过拟合。</li>
<li><strong>评估模型性能提升</strong>:通过比较不同轮次的精确率、召回率、mAP 和 F1 分数,可以评估模型在训练过程中的性能提升情况。如果这些指标在训练过程中持续提升,说明模型在不断优化,性能逐渐提高。例如,如果 mAP 从 0.6 提升到 0.8,说明模型的检测精度有了显著提高。</li>
<li><strong>分析过拟合或欠拟合</strong>:如果在训练过程中,训练集上的损失值持续下降,但验证集上的损失值却开始上升,同时验证集上的精确率、召回率、mAP 和 F1 分数开始下降,这可能是过拟合的迹象。此时,可以采取一些措施,如增加数据增强、调整模型结构、使用正则化等,来缓解过拟合问题。相反,如果训练集和验证集上的损失值都很高,且精确率、召回率、mAP 和 F1 分数都很低,可能是欠拟合的迹象,说明模型对数据的拟合能力不足,需要进一步调整模型结构或增加训练数据。</li>
<li><strong>调整超参数</strong>:根据 `results.csv` 中的指标变化情况,可以对训练过程中的超参数进行调整。例如,如果发现模型在训练初期收敛较慢,可以尝试调整学习率,采用学习率预热或学习率衰减策略,加快模型的收敛速度。如果模型在训练过程中出现过拟合,可以调整正则化参数、增加数据增强等,提高模型的泛化能力。</li>
<li><strong>选择最佳模型</strong>:通过分析 `results.csv` 中的指标数据,可以选择性能最佳的模型。通常可以选择 mAP、F1 分数最高的轮次对应的模型作为最终模型,或者根据实际应用需求,综合考虑精确率、召回率等指标,选择一个在各项指标之间达到较好平衡的模型。</li>
</ul>
</section>
<!-- 继续添加其他部分的HTML代码 -->
<!-- 以下是results.png部分的示例 -->
<section id="results_png">
<h2>10. results.png 各指标结果曲线图(根据 results.csv 绘制)</h2>
<div class="image-container">
<img src="results.png" alt="results.png">
</div>
<h3>10.1 results.png 文件的构成</h3>
<p>`results.png` 文件是根据 `results.csv` 文件中的数据绘制的可视化图表,用于直观展示 YOLO 模型训练过程中各项指标的变化趋势。该文件通常包含以下几条曲线:</p>
<ul>
<li><strong>损失值(Loss)曲线</strong>:反映了模型在每个训练轮次的损失值变化情况。损失值越低,表示模型的预测结果越接近真实标签,训练效果越好。</li>
<li><strong>精确率(Precision)曲线</strong>:展示了模型预测为正类的样本中实际为正类的比例随训练轮次的变化。高精确率意味着模型在预测正样本时的准确性较高。</li>
<li><strong>召回率(Recall)曲线</strong>:反映了模型能够正确识别出的正样本占所有实际正样本的比例随训练轮次的变化。高召回率意味着模型对正样本的检测能力较强。</li>
<li><strong>mAP(平均精度均值)曲线</strong>:综合考虑了不同类别在不同置信度阈值下的平均精度,是目标检测任务中衡量模型性能的关键指标。mAP 越高,表示模型的性能越好。</li>
<li><strong>F1 分数曲线</strong>:是精确率和召回率的调和平均数,能够平衡两者之间的关系,反映了模型在精确率和召回率之间达到的平衡情况。</li>
</ul>
<h3>10.2 各指标曲线图的解读方法</h3>
<h4>损失值曲线</h4>
<ul>
<li><strong>下降趋势</strong>:如果损失值曲线呈下降趋势,说明模型在训练过程中逐渐学习到数据的特征,预测结果与真实标签的差距逐渐减小,训练效果较好。</li>
<li><strong>趋于平稳</strong>:当损失值曲线趋于平稳时,表示模型已经基本收敛,训练过程可以考虑停止,以避免过度训练导致过拟合。</li>
<li><strong>震荡</strong>:如果损失值曲线出现震荡,可能是学习率过高导致模型参数更新过快,无法稳定收敛。此时可以尝试降低学习率或采用学习率衰减策略。</li>
</ul>
<h4>精确率曲线</h4>
<ul>
<li><strong>上升趋势</strong>:精确率曲线呈上升趋势,说明模型在预测正样本时的准确性逐渐提高,能够更好地识别出真正的正样本。</li>
<li><strong>平稳或下降</strong>:如果精确率曲线在训练过程中趋于平稳或出现下降,可能是模型对正样本的区分能力已经达到瓶颈,或者存在过拟合现象。此时可以检查数据集是否存在类别不平衡问题,或者调整模型结构和训练策略。</li>
</ul>
<h4>召回率曲线</h4>
<ul>
<li><strong>上升趋势</strong>:召回率曲线呈上升趋势,表示模型对正样本的检测能力逐渐增强,能够检测到更多的正样本。</li>
<li><strong>平稳或下降</strong>:如果召回率曲线趋于平稳或下降,可能是模型在检测正样本时出现了漏检现象,或者对负样本的误判增加。此时可以尝试调整置信度阈值,或者增加数据增强来提高模型的泛化能力。</li>
</ul>
<h4>mAP 曲线</h4>
<ul>
<li><strong>上升趋势</strong>:mAP 曲线呈上升趋势,说明模型在不同类别和不同置信度阈值下的检测精度逐渐提高,整体性能较好。</li>
<li><strong>趋于平稳</strong>:当 mAP 曲线趋于平稳时,表示模型的性能已经基本稳定,进一步提升的难度较大。此时可以考虑对模型进行微调,或者尝试使用更先进的模型架构。</li>
</ul>
<h4>F1 分数曲线</h4>
<ul>
<li><strong>上升趋势</strong>:F1 分数曲线呈上升趋势,表示模型在精确率和召回率之间达到了更好的平衡,综合性能逐渐提高。</li>
<li><strong>平稳或下降</strong>:如果 F1 分数曲线趋于平稳或下降,可能是模型在精确率和召回率之间出现了失衡。此时可以通过调整置信度阈值或优化模型结构来重新平衡两者之间的关系。</li>
</ul>
<h3>10.3 如何通过曲线图发现训练过程中的问题</h3>
<h4>过拟合</h4>
<ul>
<li><strong>现象</strong>:如果训练集上的损失值持续下降,但验证集上的损失值开始上升,同时验证集上的精确率、召回率、mAP 和 F1 分数开始下降,这可能是过拟合的迹象。</li>
<li><strong>解决方法</strong>:可以增加数据增强,如随机裁剪、翻转、旋转等,扩大训练数据集的多样性;使用正则化方法,如 L1 或 L2 正则化,限制模型参数的复杂度;提前停止训练,当验证集上的性能不再提升时及时停止训练;还可以尝试使用 Dropout 技术,在训练过程中随机丢弃一些神经元,防止模型对训练数据过度拟合。</li>
</ul>
<h4>欠拟合</h4>
<ul>
<li><strong>现象</strong>:如果训练集和验证集上的损失值都很高,且精确率、召回率、mAP 和 F1 分数都很低,可能是欠拟合的迹象,说明模型对数据的拟合能力不足。</li>
<li><strong>解决方法</strong>:可以增加模型的复杂度,如增加网络层数或神经元数量,提高模型的表达能力;增加训练数据量,使模型能够学习到更多样化的特征;调整模型的超参数,如学习率、批大小等,找到更适合的训练策略;还可以尝试更换模型架构,选择更适合当前任务的模型。</li>
</ul>
<h4>学习率问题</h4>
<ul>
<li><strong>学习率过高</strong>:如果损失值曲线出现震荡,或者在训练初期损失值下降缓慢,可能是学习率过高导致模型参数更新过快或过慢。此时可以尝试降低学习率,或者采用学习率预热策略,在训练初期使用较低的学习率,随着训练的进行逐渐提高学习率。</li>
</ul>
</section>
<!-- 继续添加其他部分的HTML代码 -->
<!-- 以下是训练批次标注图部分的示例 -->
<section id="train_batches">
<h2>11. 训练批次标注图(`train_batch*.jpg`)</h2>
<div class="image-container">
<img src="train_batch0.jpg" alt="训练批次标注图">
</div>
<h3>11.1 文件的构成</h3>
<ul>
<li>`train_batch0.jpg`:展示了训练数据中第 0 批次的标注结果。</li>
<li>`train_batch1.jpg`:展示了训练数据中第 1 批次的标注结果。</li>
<li>`train_batch2.jpg`:展示了训练数据中第 2 批次的标注结果。</li>
<li>`train_batch*.jpg`:随机展示训练数据中3个批次的标注结果。</li>
</ul>
<h3>11.2 作用</h3>
<ul>
<li><strong>检查数据标注质量</strong>:通过查看这些图像,可以直观地检查训练数据的标注是否准确,是否存在标注错误或遗漏。</li>
<li><strong>观察模型学习情况</strong>:在训练过程中,这些图像可以帮助开发者观察模型是否能够正确学习到数据的特征,例如目标的边界框是否准确,类别是否正确等。</li>
<li><strong>调试和优化</strong>:如果发现标注错误或模型学习效果不佳,可以及时调整数据标注或模型训练策略。</li>
</ul>
<h3>11.3 如何利用这些图像</h3>
<ul>
<li><strong>对比标注和预测结果</strong>:可以将这些图像与对应的预测结果(如 `val_batch*_pred.jpg`)进行对比,观察模型的预测是否与真实标注一致。</li>
<li><strong>数据增强效果</strong>:如果使用了数据增强技术(如随机裁剪、翻转、旋转等),可以通过这些图像观察数据增强的效果是否合理。</li>
</ul>
</section>
<!-- 继续添加其他部分的HTML代码 -->
<!-- 以下是验证批次标注和预测图部分的示例 -->
<section id="val_batches">
<h2>12. 验证批次标注和预测图(`val_batch*_labels.jpg` 和 `val_batch*_pred.jpg`)</h2>
<div class="image-container">
<img src="val_batch0_labels.jpg" alt="验证原始标注">
<img src="val_batch0_pred.jpg" alt="模型预测标注">
</div>
<h3>12.1 文件的构成</h3>
<ul>
<li>`val_batch0_labels.jpg`:展示了验证数据中第 0 批次的真实标注结果。</li>
<li>`val_batch0_pred.jpg`:展示了验证数据中第 0 批次的模型预测结果。</li>
<li>`val_batch1_labels.jpg`、`val_batch1_pred.jpg`:展示了验证数据中第 1 批次的真实标注和预测结果。</li>
<li>`val_batch2_labels.jpg`、`val_batch2_pred.jpg`:展示了验证数据中第 2 批次的真实标注和预测结果。</li>
</ul>
<h3>12.2 作用</h3>
<ul>
<li><strong>评估模型性能</strong>:通过对比真实标注和预测结果,可以直观地评估模型在验证数据上的性能,例如检测的准确性、边界框的精确度等。</li>
<li><strong>发现模型不足</strong>:如果预测结果与真实标注存在较大偏差,可以发现模型在某些类别或场景下的不足,为进一步优化模型提供依据。</li>
<li><strong>调试和优化</strong>:根据预测结果,可以调整模型的超参数、训练策略或数据预处理方法,以提高模型的性能。</li>
</ul>
<h3>12.3 如何利用这些图像</h3>
<ul>
<li><strong>定量分析</strong>:除了直观观察,还可以结合定量指标(如精确率、召回率、mAP 等)来全面评估模型性能。</li>
<li><strong>类别分析</strong>:观察不同类别在预测中的表现,找出模型对某些类别识别效果不佳的原因,例如类别不平衡、数据标注不准确等。</li>
<li><strong>边界框分析</strong>:检查边界框的预测精度,观察是否存在边界框偏移、尺寸不准确等问题,进一步优化模型的边界框回归部分。</li>
</ul>
</section>
</main>
<footer>
<p>© Wit数据研究所</p>
</footer>
</body>
</html>
技术共进,成长同行——讯飞AI开发者社区
更多推荐
 8
8 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)