
深度学习CNN基础网络架构
卷积神经网络(CNN)的基础网络架构包括多个经典模型,每个模型都有其独特的特点和应用场景。LeNet-5是最早的卷积网络,适用于轻量设备,但已不常用于目标检测。AlexNet是深度CNN的启蒙,虽然已淘汰,但引入了ReLU激活函数和Dropout正则化等技术。VGG网络结构简单,参数多,常用于目标检测,但不适合轻量设备。GoogLeNet/Inception通过多分支结构实现高效计算,适合目标检测
目录
学习记录一下CNN的基础网络架构,有时间可以回来看看。
1. 主流基础网络(Backbone)
| 网络名 | 发布年份 | 特点关键词 | 是否常用于目标检测 | 是否适合轻量设备 |
|---|---|---|---|---|
| LeNet-5 | 1998 | 最早卷积网络 | ❌ | ✅ |
| AlexNet | 2012 | 深度CNN启蒙 | ❌(已淘汰) | ❌ |
| VGG-16/VGG-19 | 2014 | 结构简单,参数多 | ✅(SSD用) | ❌ |
| GoogLeNet/Inception | 2014 | 多分支结构,计算高效 | ✅ | ✅ |
| ResNet(18/34/50/101/152) | 2015 | 残差结构、极深 | ✅(Faster R-CNN 等) | ⚠️视版本而定 |
| DenseNet | 2016 | 层间全连接、参数高效 | ✅ | ⚠️中等 |
1.1 基础卷积网络(CNN 系列)
| 网络 | 论文标题 | 链接 |
|---|---|---|
| LeNet-5 | Gradient-Based Learning Applied to Document Recognition | http://vision.stanford.edu/cs598_spring07/papers/Lecun98.pdf |
| AlexNet | ImageNet Classification with Deep Convolutional Neural Networks | https://proceedings.neurips.cc/paper_files/paper/2012/file/c399862d3b9d6b76c8436e924a68c45b-Paper.pdf |
| VGG | Very Deep Convolutional Networks for Large-Scale Image Recognition | arXiv:1409.1556 |
| GoogLeNet (Inception v1) | Going Deeper with Convolutions | arXiv:1409.4842 |
| ResNet | Deep Residual Learning for Image Recognition | arXiv:1512.03385 |
| DenseNet | Densely Connected Convolutional Networks | arXiv:1608.06993 |
2.网络架构
2.1 LeNet-5
LeNet-5 是深度学习历史上非常重要的一张“开山鼻祖级”网络结构,它由 Yann LeCun 教授等人在 1998 年提出,用于手写数字识别任务(MNIST),也是**卷积神经网络(CNN)**的鼻祖之一。
网络结构图:
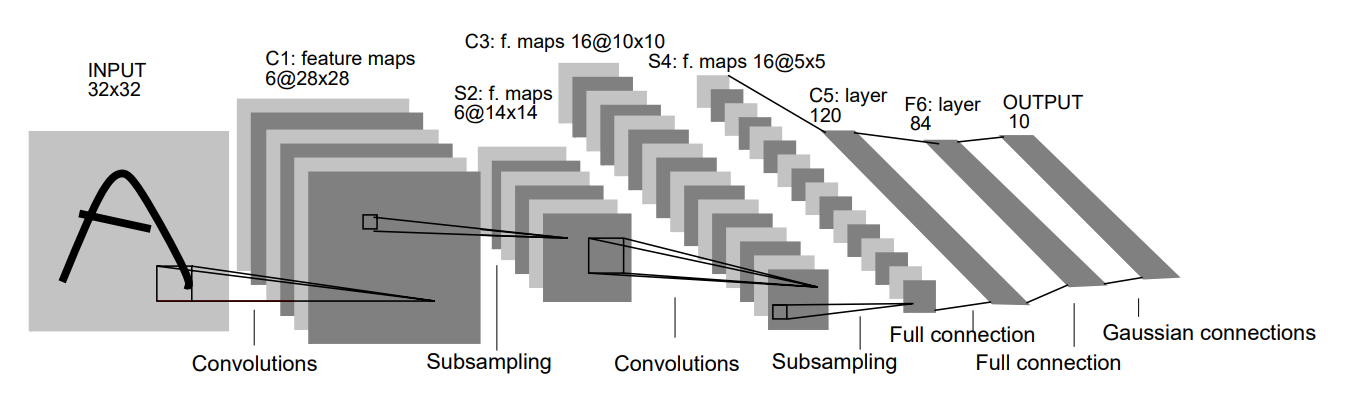
| 层名 | 类型 | 输出尺寸 | 描述 |
|---|---|---|---|
| C1 | 卷积层 | 28×28×6 | 6 个 5×5 卷积核 |
| S2 | 池化层 | 14×14×6 | 2×2 平均池化 |
| C3 | 卷积层 | 10×10×16 | 5x5 s=1 p=0 |
| S4 | 池化层 | 5×5×16 | 2×2 平均池化 |
| C5 | 卷积层 | 1×1×120 | 5×5 卷积 |
| F6 | 全连接层 | 84 | |
| Output | 全连接层 | 10 | 对应分类(如数字 0~9) |
网络结构特点:
✅ 开创性使用了:
-
卷积层 + 子采样(池化)
-
Sigmoid 或 tanh 激活(ReLU 当时未提出)
-
权值共享,减少参数
-
层间局部连接(非全连接)
❌ 局限性:
-
网络浅,泛化能力有限
-
没有使用 batch normalization、ReLU 等现代技术
-
仅适用于简单任务(如 MNIST)
2.2 AlexNet
下图是在2个GPU上运行示意图
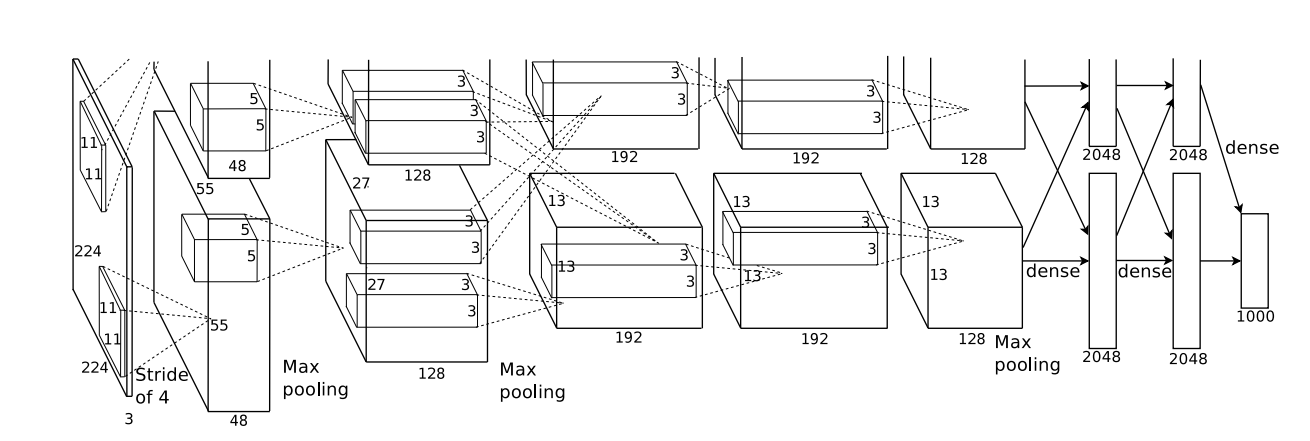
| 层名 | 类型 | 参数说明 | 输出尺寸(示意) |
|---|---|---|---|
| Input | 图像输入 | 224×224×3 | 224×224×3 |
| Conv1 | 卷积层 | 96 filters, 11×11, stride=4 | 55×55×96 |
| MaxPool1 | 最大池化 | 3×3, stride=2 | 27×27×96 |
| Conv2 | 卷积层 | 256 filters, 5×5 | 27×27×256 |
| MaxPool2 | 最大池化 | 3×3 | 13×13×256 |
| Conv3 | 卷积层 | 384 filters, 3×3 | 13×13×384 |
| Conv4 | 卷积层 | 384 filters, 3×3 | 13×13×384 |
| Conv5 | 卷积层 | 256 filters, 3×3 | 13×13×256 |
| MaxPool3 | 最大池化 | 3×3 | 6×6×256 |
| FC6 | 全连接 | 4096 神经元 | 4096 |
| FC7 | 全连接 | 4096 神经元 | 4096 |
| FC8 | 全连接 | 1000 类(Softmax) | 1000 |
网络结构特点:
| 技术 | 说明 |
|---|---|
| ✅ ReLU 激活函数 | 第一个广泛使用 ReLU 替代 Sigmoid/Tanh,提高收敛速度 |
| ✅ Dropout 正则化 | 用于减少过拟合(特别是在 FC 层) |
| ✅ 数据增强 | 随机裁剪、镜像、颜色扰动等 |
| ✅ GPU 并行训练 | 当时使用了两个 GPU 训练,网络被人为拆成两部分 |
2.3 VGG
VGG网络的结构一致,从头到尾全部使用的是3x3的卷积和2x2的max pooling。
VGG16包含了16个隐藏层(13个卷积层和3个全连接层)
VGG19包含了19个隐藏层(16个卷积层和3个全连接层)
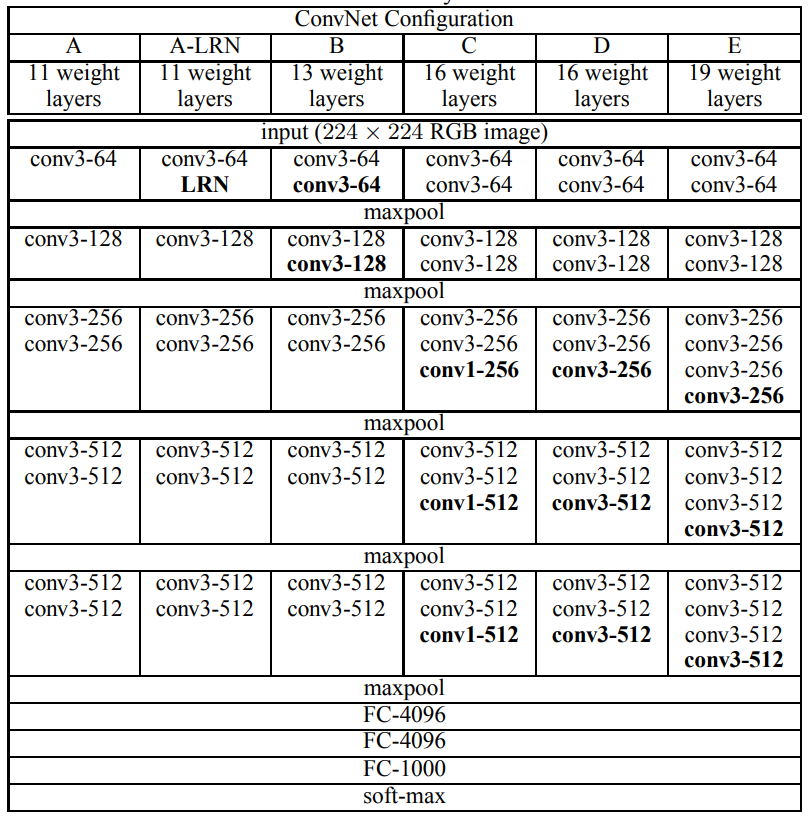
下图以VGG16为例的网络架构(主要由卷积层 + 池化层 + 全连接层组成)
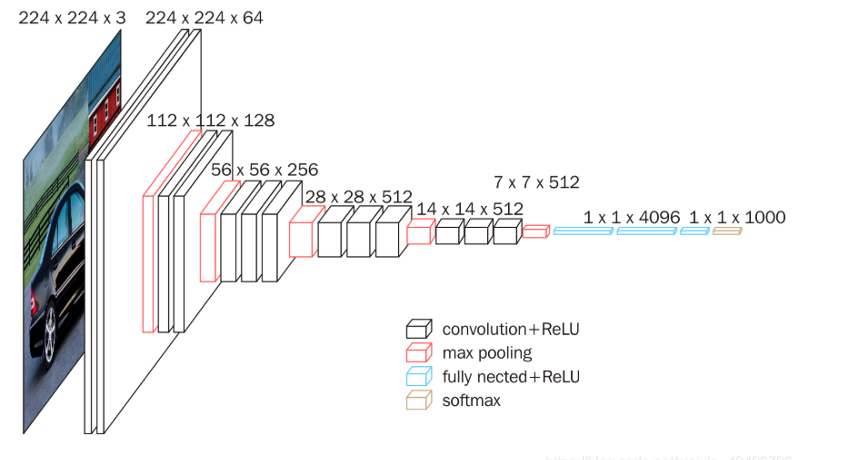
| Layer Name | Layer Type | Output Size | Filter Size / Stride / Padding |
| ---------- | ------------------------ | --------------- | ------------------------------ |
| Input | 图像输入 | 224 × 224 × 3 | - |
| Conv1\_1 | Convolution (3x3) | 224 × 224 × 64 | 3×3 / 1 / 1 |
| Conv1\_2 | Convolution (3x3) | 224 × 224 × 64 | 3×3 / 1 / 1 |
| MaxPool1 | MaxPooling (2x2) | 112 × 112 × 64 | 2×2 / 2 / 0 |
| Conv2\_1 | Convolution (3x3) | 112 × 112 × 128 | 3×3 / 1 / 1 |
| Conv2\_2 | Convolution (3x3) | 112 × 112 × 128 | 3×3 / 1 / 1 |
| MaxPool2 | MaxPooling (2x2) | 56 × 56 × 128 | 2×2 / 2 / 0 |
| Conv3\_1 | Convolution (3x3) | 56 × 56 × 256 | 3×3 / 1 / 1 |
| Conv3\_2 | Convolution (3x3) | 56 × 56 × 256 | 3×3 / 1 / 1 |
| Conv3\_3 | Convolution (3x3) | 56 × 56 × 256 | 3×3 / 1 / 1 |
| MaxPool3 | MaxPooling (2x2) | 28 × 28 × 256 | 2×2 / 2 / 0 |
| Conv4\_1 | Convolution (3x3) | 28 × 28 × 512 | 3×3 / 1 / 1 |
| Conv4\_2 | Convolution (3x3) | 28 × 28 × 512 | 3×3 / 1 / 1 |
| Conv4\_3 | Convolution (3x3) | 28 × 28 × 512 | 3×3 / 1 / 1 |
| MaxPool4 | MaxPooling (2x2) | 14 × 14 × 512 | 2×2 / 2 / 0 |
| Conv5\_1 | Convolution (3x3) | 14 × 14 × 512 | 3×3 / 1 / 1 |
| Conv5\_2 | Convolution (3x3) | 14 × 14 × 512 | 3×3 / 1 / 1 |
| Conv5\_3 | Convolution (3x3) | 14 × 14 × 512 | 3×3 / 1 / 1 |
| MaxPool5 | MaxPooling (2x2) | 7 × 7 × 512 | 2×2 / 2 / 0 |
| FC1 | Fully Connected | 4096 | - |
| FC2 | Fully Connected | 4096 | - |
| FC3 | Fully Connected (Output) | 1000 (classes) | - |
| Softmax | 分类概率输出 | 1000 | - |
网络结构特点:
-
全部使用 3x3 的小卷积核(stride=1,padding=1),保证尺寸不变。
-
每个 block 后面有一个 2x2 的最大池化(stride=2)用于降维。
-
VGG16 有 13 个卷积层 + 3 个全连接层,总共 16 层可训练层(VGG19 有 19 层)。
-
所有激活函数使用 ReLU。
2.4 GoogLeNet/Inception
GoogLeNet 是 Google 在 2014 年提出的一种高效且深度较大的卷积神经网络架构。它的核心是 Inception 模块,通过在同一层同时使用不同尺寸的卷积核,实现了更高效的特征提取和计算性能。
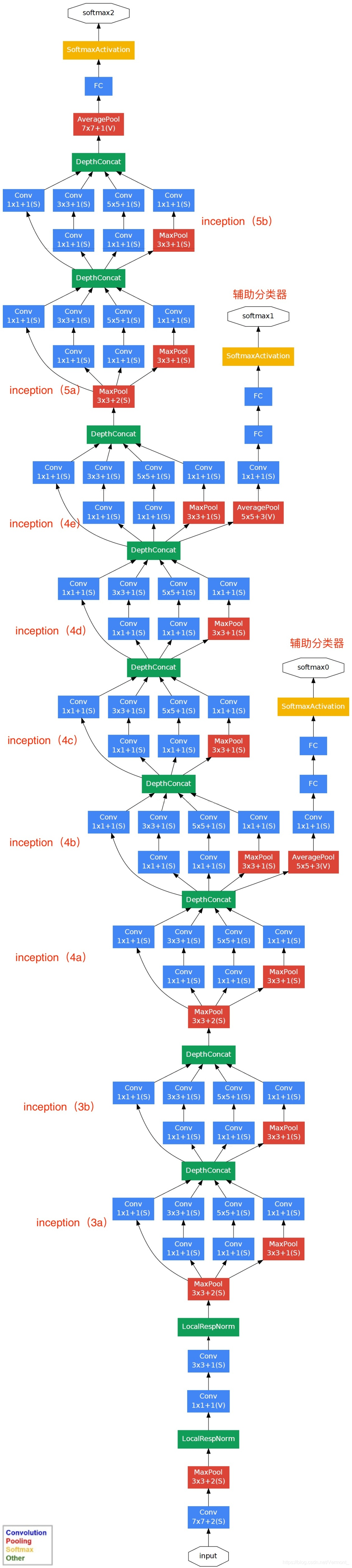

Inception 模块结构(核心)
每个 Inception 模块包括以下并行路径,然后将输出在 通道维度 concat:
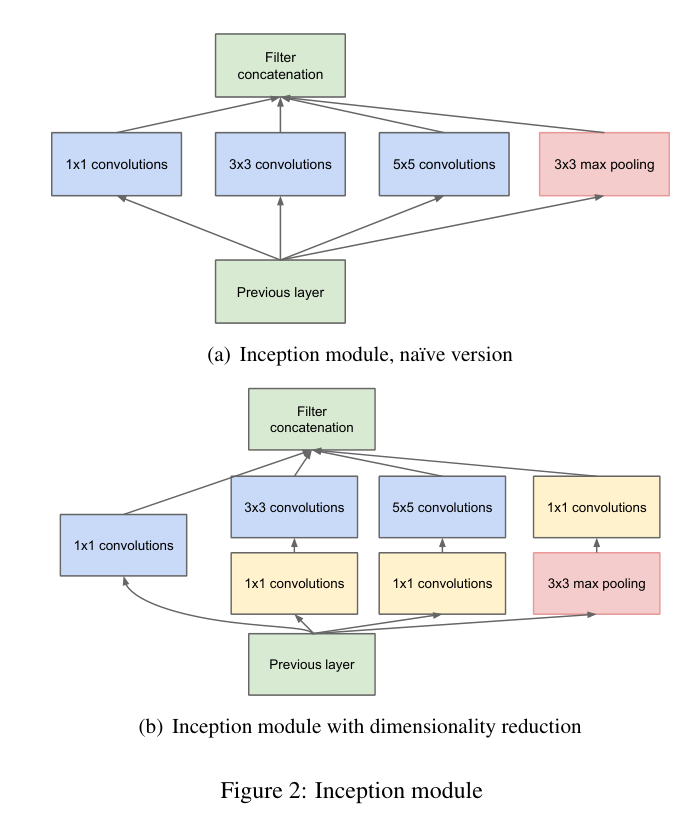
| Path | 操作 |
|---|---|
| 1 | 1×1 卷积 |
| 2 | 1×1 卷积 → 3×3 卷积 |
| 3 | 1×1 卷积 → 5×5 卷积 |
| 4 | 3×3 最大池化 → 1×1 卷积 |
这样做的好处是:同时提取不同尺度的特征,同时使用 1x1 卷积进行降维,减少参数量和计算量。
网络结构特点:
| 特点 | 说明 |
|---|---|
| Inception 模块 | 多尺度卷积结构提高了表达力 |
| 全局平均池化(Global Avg Pool) | 替代全连接层,减少参数,避免过拟合 |
| 参数量少 | 比 AlexNet 和 VGG 少很多参数(GoogLeNet 约 500 万,VGG16 超过 1 亿) |
| 辅助分类器(Auxiliary Classifiers) | 在中间层加两个小的 softmax 头,辅助训练防止梯度消失 |
| 深度较大 | 22 层(不含辅助分类器) |
2.5.ResNet
ResNet(残差网络)是深度学习中具有里程碑意义的网络结构,由微软研究院的何恺明等人在 2015 年提出,并在 ILSVRC 2015 中取得冠军。它通过引入 残差连接(skip connection),成功训练了 非常深的神经网络(如 ResNet-50、ResNet-101、ResNet-152),大幅提升了模型性能。
残差结构:
这个设计解决了深层网络 梯度消失/退化问题,使得网络可以堆叠到 几十甚至上百层。
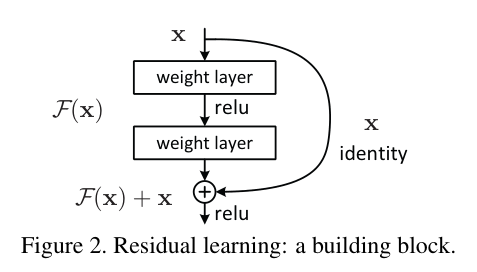
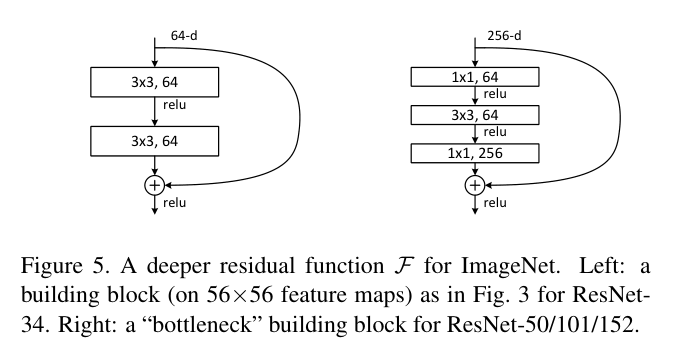
网络结构:
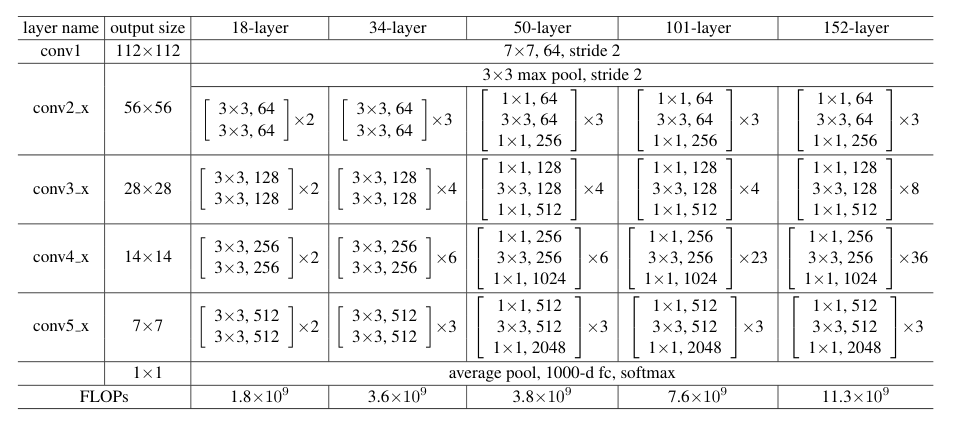

网络结构特点:
| 优点 | 说明 |
|---|---|
| 解决深层网络退化问题 | 网络更深时不会出现准确率下降 |
| 可训练非常深的网络 | 如 ResNet-152 等 |
| 参数利用更有效 | 更少的参数训练更深的网络 |
| 迁移性好 | 适用于分类、检测、分割等多任务 |
| 是众多后续模型的基础 | 如:ResNeXt、DenseNet、HRNet、Swin 等 |
2.6.DenseNet
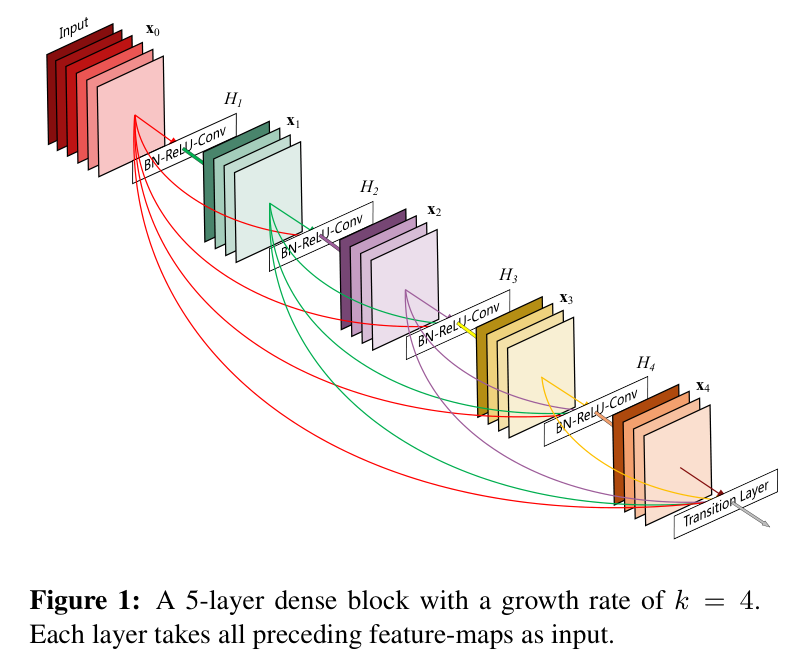
DenseNet(全称:Densely Connected Convolutional Networks)是 2017 年由黄高等人提出的一种改进型卷积神经网络结构,它通过**每一层与前面所有层相连接(dense connection)**的方式,进一步提高了特征复用率、梯度流通性,并有效减少了参数数量。
核心思想:
每一层的输入不是来自上一层,而是来自前面所有层的输出的连接,即:
![]()
其中 ![]() 表示所有先前层特征图的连接(concatenation),
表示所有先前层特征图的连接(concatenation),![]() 是当前层的非线性变换(通常是 BN → ReLU → Conv)。
是当前层的非线性变换(通常是 BN → ReLU → Conv)。
这种连接方式形成了“密集连接”,所以叫 DenseNet。

DenseNet 变种与参数量对比
| 网络名称 | Dense Block 层数 | 参数量约(M) |
|---|---|---|
| DenseNet-121 | 6-12-24-16 | ~8M |
| DenseNet-169 | 6-12-32-32 | ~14M |
| DenseNet-201 | 6-12-48-32 | ~20M |
| DenseNet-264 | 6-12-64-48 | ~33M |
网络局限性:
虽然 DenseNet 在性能、特征复用和训练效率上有诸多优点,但它也存在一些 明显的局限性和问题,尤其在实际工程应用中。
1. 特征图通道数增长过快(内存开销大)
-
由于每一层都拼接之前所有层的输出,导致特征图通道数随深度线性增长。
-
特征图越往后越“宽”,对 GPU 显存要求较高,限制了 DenseNet 的深度和实际应用。
例如:DenseNet-121 后期的层会有数百个通道拼接输入,这会显著增加内存占用。
2. 推理速度慢(尤其在嵌入式环境)
-
每一层都需要访问前面所有层的输出 → 内存访问频繁 → 推理效率低。
-
特征图拼接操作在硬件中不容易并行,影响部署性能。
3. 结构复杂,不易定制化扩展
-
网络之间层层依赖,无法简单地剪枝或修改 block 数量。
-
更改结构(如替换某一层)时需要格外小心,容易破坏拼接顺序。
4. 实际部署困难
-
对内存布局、缓存命中率不友好,不适合直接部署在移动设备或低功耗环境。
-
一些框架(如 TensorRT)在早期版本中对 DenseNet 支持不佳。
5. 过多特征拼接可能引入冗余
-
虽然特征复用是优点,但长期拼接会带来冗余特征,信息密度下降。
-
后期层面临“信号过载”,也有可能影响最终性能。
6. 不适合极大尺寸图像或高分辨率任务
-
特征图太多导致内存暴涨,特别是在高分辨率输入时(如医学图像、遥感图像),不如一些轻量网络实用。

技术共进,成长同行——讯飞AI开发者社区
更多推荐
 36
36 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)