
【动手学习深度学习】数据预处理知识补充——Pandas库
Pandas 库是最常见的工具,提供了能够便捷地完成选取、重塑、切片、聚合等复杂精细的操作,对于深度学习来说,得到数据后要先进行数据预处理(数据清洗或做一些数据分析等),认识数据。文中总结了一些我见过、用过的函数。
Pandas 库是最常见的工具,提供了能够便捷地完成选取、重塑、切片、聚合等复杂精细的操作,可以对数据进行读取、选择、整理、描述、分组、分割、合并、变形,处理缺失值、异常值和重复值,处理时序数据,转换数据类型等。
文中总结了一些我见过、用过的函数,详细内容以及一些例程可以看官网的用户手册:User Guide — pandas 1.4.4 documentation
目录
1.1. 数据读入
注:表中pd为pandas的缩写、df为读入数据的存储变量、data_file为数据储存位置、data表示数据内容、index_data和columns_data为索引值
| 操作 | 函数 | ||
|---|---|---|---|
| 导入包 | import pandas as pd | ||
| 指定内容 | data为一维数据 | 默认索引 | df=pd.Series(data) |
| 指定索引 |
df=pd.Series(data,index=index_data) |
||
| data为二维数据 | 默认索引 | df=pd.DataFrame(data) | |
| 指定索引 | df=pd.DataFrame(data,index=index_data,columns=columns_data) | ||
| csv文件格式储存数据读入 |
df=pd.read_csv(data_file) 注:一般这样就ok,涉及到一些特殊的,比如下面这个例子,指定了编码格式,因为没有列的头,还指定了。 df=pd.read_csv(data_file,encoding='GB18030',header=None,names=header_names) 其中header_names为加入的列的名字 |
||
1.2. 查看与统计数据
注:df为读入数据的存储变量
| 操作 | 函数 |
|---|---|
| 查看维度 | df.shape |
| 查看数据Column Non-Null Count Dtype等信息 | df.info() |
| 统计运算 | df.describe() |
| 查看index | df.index |
| 查看columns | df.columns |
| 判断某个值是不是缺失值(空值) |
df.isna() df.isnull() |
| 取出第 10 到 25 行和第 3 到 5 列的数据 | df.iloc[9:25, 2:5] |
| 统计指定列同一类数据的总数 | df[列名].value_counts() |
| 查询指定条件的字符串 | df.query(查询条件) |
条件筛选,为提供的列表中的每一行返回一个True值 |
df[df[列名].isin()] |
| 某一列累加 | df[列名].cumsum() |
| 某一列累减 | df[列名].cumprod() |
| 某一列的累计最大 | df[列名].cummax() |
##查询的一些代码例程,只摆代码,不摆结果了,在深度学习课程/6/pandas里
#1
df[df['open']>27]
#2
#涨的天数与跌的天数
df[df['p_change']>0]['date'].count()
df[df['p_change']<0]['date'].count()
#3
df.query('open<24 & open>23')1.3. 操作数据
注:df为读入数据的存储变量、subset_list为columns中指定的一个或多个、index_name为编写的索引名、columns_name值列名
| 操作 | 函数 | |
|---|---|---|
| 索引操作 | 设置索引 | df.index=index_name |
| 指定某一列为索引 | df.set_index(列名) | |
| 重置索引 | df.reset_index(drop=True) | |
| 删除指定列 | df.drop(columns_name,axis=1) | |
|
删除有缺失值的行 注:缺失值指在dataframe中为nan或者naT(缺失时间) |
有一个缺失值就删除行 | df.dropna() |
| 所有值全为缺失值才删除行 | df.dropna(how='all') | |
| 至少出现过两个缺失值才删除 | df.dropna(thresh=2) | |
| 删除subset中的含有缺失值的行 | df.dropna(subset=subset_list) | |
| 补充有缺失值的行 | 用0补充缺失值 | df.fillna(0) |
| 横向用缺失值前面的值替换缺失值 | df.fillna(axis=1,method='ffill') | |
| 纵向用缺失值上面的值替换缺失值 | df.fillna(axis=0,method='ffill') | |
| 对指定列相同的行去重 | df.drop_duplicates(subset=subset_list,inplace=True) | |
| 按索引排序 | 索引进行排序,默认是升序 | df.sort_index() |
| 对索引进行降序排序 | df.sort_index(ascending=False) | |
|
按值排序 注:对值进行排序的时候,无论是升序还是降序,缺失值(NaN)都会排在最后面。 |
按值进行排序,默认是按值的升序进行排序的 | df.sort_values() |
| 按值进行降序排序 | df.sort_values(ascending=False) | |
| 按xx(和yy)分组,yy有也行,没有也行 | df[列名].groupby(xx,yy) | |
1.4. 数据合并
| 操作 | 函数 |
|---|---|
| 按照行索引进行合并 | pd.concat([data,dummies],axis=1) |
| 按照列索引进行合并 | pd.concat([data,dummies],axis=0) |
| 左连接、右连接(数据库里的概念) | pd.merge() |
1.5. 一个简单的例子
##创建一个名为house_tiny的csv文件,文件存在当前路径data文件夹下,并写入数据
import os
os.makedirs(os.path.join('data'), exist_ok=True)
data_file = os.path.join('data/house_tiny.csv')
with open(data_file, 'w') as f:
f.write('NumRooms,Alley,Price\n') # 列名
f.write('NA,Pave,127500\n') # 每行表示一个数据样本
f.write('2,NA,106000\n')
f.write('4,NA,178100\n')
f.write('NA,NA,140000\n')
##将数据读入
import pandas as pd
data=pd.read_csv(data_file)
data 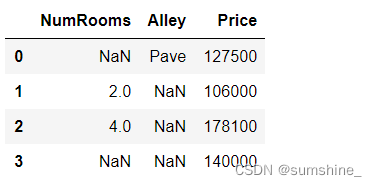
##数据为4行3列,用iloc函数划分输入和输出
inputs,outputs=data.iloc[:,0:2],data.iloc[:,2]
inputs,outputs


##inputs数据存在缺失值,用fillna()函数补充缺失值
inputs=inputs.fillna(inputs.mean())#用输入的平均值补充数字信息
inputs 
##运用get_dummies()函数用1和0分别表示数据是否存在
inputs=pd.get_dummies(inputs,dummy_na=True)
inputs 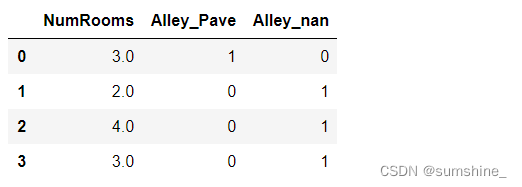
get_dummies()函数的用法可以用help(pd.get_dummies)语句查看
##将结果转化为张量
import torch
X,y=torch.tensor(inputs.values),torch.tensor(outputs.values)
X,y

技术共进,成长同行——讯飞AI开发者社区
更多推荐

 0
0 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)