
LLM大模型小白入门指南:关键术语通俗解析,看完这篇就够了!
大语言模型(LLM)是当前人工智能领域的“明星”,虽然听起来复杂,但本质上你可以理解成就是生成人类语言的智能系统。下面用通俗的方式,从几个方面详细介绍:
大语言模型(LLM)是当前人工智能领域的“明星”,虽然听起来复杂,但本质上你可以理解成就是生成人类语言的智能系统。下面用通俗的方式,从几个方面详细介绍:
一、基本概念与核心术语
先把关键术语“翻译”成大白话,后面会反复用到:
- 大语言模型(LLM,Large Language Model):字面意思,就是“规模很大的语言模型”。它能像人一样理解文字、生成文字,甚至做简单推理(比如“因为下雨,所以出门要带伞”)。
- 深度学习(Deep Learning):LLM的“底层技术”,模仿人脑神经元的工作方式,用多层“神经网络”处理信息。就像多层滤网,一层一层提炼数据里的规律。
- Transformer:LLM的“核心骨架”(2017年谷歌提出)。它的关键是“自注意力机制”——能像人一样,在一句话里“关注”重要的词。比如“小明给小红买了花,她很开心”,模型能知道“她”指小红。
- GPT(Generative Pre-trained Transformer):“生成式预训练Transformer”,是LLM的一种。特点是擅长“生成内容”(写文章、编故事等),代表产品是ChatGPT。
- BERT(Bidirectional Encoder Representations from Transformers):另一种LLM,擅长“理解文本”(比如分析句子情感、找关键词),但生成能力弱。
- 预训练(Pre-training):LLM的“基础教育阶段”。模型先在海量文本(比如全网书籍、网页、论文)里学习,掌握语言规律(比如“太阳从东边升起”是常识)。这个阶段就像人在上学,什么都学。
- 微调(Fine-tuning):LLM的“职业培训阶段”。预训练后的模型再用特定领域数据(比如医疗病历、法律条文)训练,让它更擅长某类任务(比如写病历)。
- Token:文本的“最小单位”。模型处理文字时,会把句子拆成Token(可能是单词、字、甚至字母片段)。比如“我爱中国”可能拆成3个Token(“我”“爱”“中国”);英文“apple”可能是1个Token,“unhappiness”可能拆成“un”“happiness”2个。
二、基本模型原理
LLM的工作原理可以简化为“三步曲”:
- 拆分成Token:把输入的文字(比如“帮我写一封请假条”)拆成Token,转换成模型能理解的数字(向量)。
- 用Transformer处理:通过“自注意力机制”分析Token之间的关系(比如“请假条”需要包含“请假时间”“原因”),结合预训练学到的知识,计算出“该说什么”。
- 生成回答:把计算结果转回文字,输出回答(比如“好的,这是一封请假条模板:尊敬的领导……”)。
简单说,就像一个“超级大脑”:先通过海量学习记住语言规律,再根据输入的内容“联想”出合理的回应。
三、核心能力
LLM的核心能力可以概括为“理解”和“生成”两大块,具体包括:
- 文本理解:能看懂文章、句子、关键词,比如总结一篇新闻的大意,分析用户评论是好评还是差评。
- 内容生成:能写文章、编故事、生成代码、创作诗歌,甚至模仿特定风格(比如模仿鲁迅的语气)。
- 问答互动:像“智能顾问”一样回答问题,从常识(“地球自转一圈多久”)到专业知识(“糖尿病患者饮食注意什么”)。
- 逻辑推理:能做简单的推理,比如“小明比小红大3岁,小红10岁,小明几岁?”(答案13岁)。
- 多语言处理:能翻译、跨语言对话(比如用中文问,模型用英文回答)。
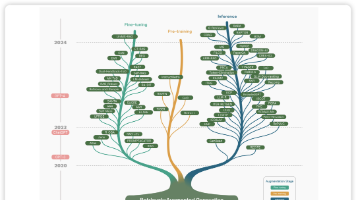
四、发展历程
LLM的发展是“从简单到复杂”的过程,关键节点:
- 2013年:词向量模型(如Word2Vec)出现,第一次让计算机“理解”单词的含义(比如“国王-男人+女人=女王”),但只能处理单个词。
- 2017年:Transformer架构诞生,解决了“长文本处理”问题,为LLM奠定基础。
- 2018年:谷歌发布BERT(擅长理解),OpenAI发布GPT-1(擅长生成),LLM开始走向实用。
- 2020年:GPT-3发布,参数量达到1750亿(相当于模型的“脑细胞”数量),生成能力大幅提升,能写邮件、编剧本。
- 2022年:ChatGPT(基于GPT-3.5)爆火,支持自然对话,让普通人第一次感受到LLM的强大。
- 2023年至今:GPT-4、Gemini等模型加入“多模态”能力(能处理图片、语音),LLM从“只懂文字”变成“能看能听”。
五、应用场景
LLM已经渗透到各行各业,举几个常见例子:
- 日常助手:写邮件、改简历、查天气、订机票(比如问Siri“帮我写一封感谢客户的邮件”)。
- 内容创作:自媒体写文案、短视频脚本、广告标语(比如用LLM生成“奶茶店促销文案”)。
- 教育培训:作业辅导(比如问“这道数学题怎么解”)、外语翻译(比如“把中文翻译成法语”)。
- 客服服务:替代人工客服回答常见问题(比如“我的快递什么时候到”)。
- 专业领域:医生用它分析病历、律师用它审查合同、程序员用它写代码(比如“帮我写一段Python爬虫代码”)。
六、业界TOP10产品及特点(按影响力排序)
目前没有绝对权威的排名,以下是公认的主流产品,各有侧重:
- GPT-4(OpenAI)
- 特点:能力最全面,支持文本+图片输入(多模态),推理、生成、逻辑能力强,适合复杂任务(比如写论文、做数据分析)。
- 缺点:部分功能收费,对中文语境的理解略逊于本土模型。
- Claude(Anthropic)
- 特点:擅长处理“超长文本”(比如一次分析10万字文档),安全性高(不容易生成违规内容),适合法律、学术等专业场景。
- 文心一言(百度)
- 特点:本土化强,对中文梗、成语、国内热点理解更准(比如“躺平”“内卷”的含义),支持生成短视频脚本、PPT等。
- 讯飞星火(科大讯飞)
- 特点:语音交互能力突出(毕竟是做语音起家),适合教育(作业批改)、医疗(语音转病历)场景。
- 通义千问(阿里)
- 特点:电商场景适配好(比如生成商品描述、分析用户评价),和阿里生态(淘宝、钉钉)结合紧密。
- Llama 3(Meta)
- 特点:开源免费(企业可自己修改),适合开发者二次定制(比如训练一个公司内部的客服模型),能力接近GPT-4。
- Gemini(谷歌)
- 特点:多模态能力强(文本+图片+视频),和谷歌搜索、地图等工具结合紧密,适合日常信息查询。
- CodeLlama(Meta)
- 特点:专门为“写代码”优化,支持Python、Java等几十种语言,程序员最爱之一。
- Qwen(通义千问的升级版,阿里)
- 特点:小模型版本(比如Qwen-7B)运行速度快,能在手机、电脑本地使用(不用联网),适合隐私敏感场景。
- Mistral(Mistral AI)
- 特点:欧洲代表模型,开源且效率高(用更少的计算资源达到接近GPT的效果),适合中小企业使用。
七、具体应用示例
- 场景1:写周报
输入:“帮我写一份电商运营周报,上周销售额10万,比前一周增长20%,主要来自直播带货,下周计划增加短视频推广。”
LLM(比如文心一言)会生成结构化的周报,包含“本周成果”“增长原因”“下周计划”等板块。
- 场景2:分析合同
上传一份租房合同给Claude,输入:“帮我找出合同里对租客不利的条款。” 模型会标出“提前退租不退押金”“物业费由租客承担”等潜在问题。
- 场景3:辅导作业
学生问讯飞星火:“‘忽如一夜春风来,千树万树梨花开’用了什么修辞手法?” 模型会解释是“比喻”,把雪花比作梨花。
八、发展趋势
- 多模态融合:未来的LLM不仅能处理文字,还能像人一样“看图片、听声音、甚至理解视频”(比如看到一张车祸现场图,能分析可能的原因)。
- 更“小而精”:现在的LLM需要超级计算机运行,未来会出现“轻量级模型”,在手机、手表上就能用(比如离线翻译)。
- 更懂“逻辑”:目前LLM偶尔会“一本正经地胡说八道”(比如算错简单数学题),未来会更擅长推理、减少错误。
- 行业定制化:每个行业会有自己的专属LLM(比如医院的“病历分析模型”、学校的“个性化辅导模型”)。
总结
大语言模型本质上是“用海量数据训练出来的语言专家”,它的核心是通过Transformer理解文字关系,经过预训练和微调后,能在各种场景帮人干活。虽然听起来复杂,但对普通人来说,不用懂原理,会用它提高效率(写东西、查信息)就够了~ 随着技术发展,它会变得越来越“聪明”,像手机一样成为日常工具。
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。
随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:
人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
只要你真心想学习AI大模型技术,这份精心整理的学习资料我愿意无偿分享给你,但是想学技术去乱搞的人别来找我!
在当前这个人工智能高速发展的时代,AI大模型正在深刻改变各行各业。我国对高水平AI人才的需求也日益增长,真正懂技术、能落地的人才依旧紧缺。我也希望通过这份资料,能够帮助更多有志于AI领域的朋友入门并深入学习。
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
大模型全套学习资料展示
自我们与MoPaaS魔泊云合作以来,我们不断打磨课程体系与技术内容,在细节上精益求精,同时在技术层面也新增了许多前沿且实用的内容,力求为大家带来更系统、更实战、更落地的大模型学习体验。

希望这份系统、实用的大模型学习路径,能够帮助你从零入门,进阶到实战,真正掌握AI时代的核心技能!
01 教学内容

-
从零到精通完整闭环:【基础理论 →RAG开发 → Agent设计 → 模型微调与私有化部署调→热门技术】5大模块,内容比传统教材更贴近企业实战!
-
大量真实项目案例: 带你亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!
02适学人群
应届毕业生: 无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型: 非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能突破瓶颈: 传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。

vx扫描下方二维码即可
本教程比较珍贵,仅限大家自行学习,不要传播!更严禁商用!
03 入门到进阶学习路线图
大模型学习路线图,整体分为5个大的阶段:
04 视频和书籍PDF合集

从0到掌握主流大模型技术视频教程(涵盖模型训练、微调、RAG、LangChain、Agent开发等实战方向)

新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路(不吹牛,真有用)
05 行业报告+白皮书合集
收集70+报告与白皮书,了解行业最新动态!
06 90+份面试题/经验
AI大模型岗位面试经验总结(谁学技术不是为了赚$呢,找个好的岗位很重要)

07 deepseek部署包+技巧大全

由于篇幅有限
只展示部分资料
并且还在持续更新中…
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

技术共进,成长同行——讯飞AI开发者社区
更多推荐
 10
10 0
0- 0



 已为社区贡献64条内容
已为社区贡献64条内容

所有评论(0)