
AI智能协作系统教程(LangGraph实战)从零基础入门到精通,看这一篇就够了!
多智能体AI系统代表了人工智能应用架构的重要演进方向。通过将复杂任务分解为专门化智能体的协作模式,我们能够构建出性能更优、可维护性更强的AI系统。本文通过构建AI研究助手的完整案例,展示了从系统架构设计到具体实现的全过程。相比传统的单模型方案,多智能体架构在处理复杂任务时能够实现40-60%的性能提升,同时具备更好的可扩展性和可调试性。LangGraph框架为多智能体系统的开发提供了强大的工具支持
前言
在本篇文章中,我们将深入探讨如何运用langgraph与langchain来构建多人工智能智能体(multi - AI Agents)。文中所涉及的代码均已通过验证,具有较高的可靠性与实用性。当您认真读完这篇文章后,便具备了独立构建属于自己的多智能体系统的能力。
想象一下:只需四小时,一位初级开发者就能构建出同时处理事实核查、摘要生成、情感分析和多数据源交叉引用的AI研究助手。这在六个月前需要高级工程师团队数周的开发时间,如今借助LangGraph多智能体框架已经成为现实。
传统AI应用依赖单一大型模型处理所有任务,就像让一个人同时担任研究员、作家、事实核查员和编辑。而多智能体系统将复杂任务分配给专门化的AI智能体,每个智能体在特定领域发挥最佳性能,通过精确协调实现整体目标。
本文将通过构建AI研究助手的完整案例,展示如何使用LangGraph框架实现这种架构转变,从理论基础到具体实现,帮助你掌握下一代AI系统的构建方法。

优秀的人类团队通常采用专业分工的方式运作,而非让一个人同时承担研究员、作家、事实核查员和编辑的全部职责。团队成员各自在专业领域发挥优势,通过无缝协作实现整体目标。
这一原则同样适用于AI系统架构。相比强制单一模型在所有任务上表现平庸,多智能体系统允许创建在特定任务领域表现卓越的专门化AI智能体,这些智能体能够像精密机械一样协同运作。
研究数据表明,多智能体AI系统在处理复杂任务时的性能比单模型方法提升40-60%。更重要的是,这种架构不仅提升了效率,还具备更好的可维护性、可调试性和可扩展性。
传统的AI驱动内容创作系统通常采用单一大型模型处理研究、写作、事实核查和编辑等全部流程。这种方法的结果类似于瑞士军刀——各项功能都能完成,但缺乏专业深度。
多智能体架构将复杂任务分解为专门化角色:研究员智能体专精于信息检索和综合,作家智能体专注于内容创作,事实核查智能体负责声明验证和引用检查,编辑智能体负责最终输出的润色和完善。每个智能体在其专业领域内表现卓越,通过协作产生协同效应。
构建研究助手多智能体系统
本节将通过构建一个AI研究助手展示多智能体系统的实际应用。该系统通过专门化智能体间的分工协作处理复杂研究主题,实现主题研究、信息验证和综合报告生成的完整流程。
系统架构设计
首先建立多智能体系统的基础架构。以下代码定义了所有智能体共享的基本结构和状态管理机制:
from langgraph.graph import StateGraph, START, END from typing import TypedDict, Annotated, List from langgraph.graph.message import add_messages class ResearchState(TypedDict): topic: str research_queries: List[str] raw_information: List[str] validated_facts: List[str] final_report: str current_agent: str messages: Annotated[list, add_messages] # 初始化多智能体工作流 workflow = StateGraph(ResearchState)
此架构创建了所有智能体可以读写的共享状态空间,类似于团队成员共享的信息交换平台,每个智能体都能访问其他智能体的贡献并添加自己的分析结果。
研究员智能体实现
研究员智能体的核心功能是将复杂研究主题分解为具体的研究查询,并收集相关信息:
def researcher_agent(state: ResearchState):
"""
将研究主题分解为具体查询
并收集初始信息
"""
topic = state["topic"]
# 生成研究查询
query_prompt = f"""
将这个研究主题分解为3-5个具体的、
可搜索的查询:{topic}
让每个查询都集中且可操作。
"""
queries = llm.invoke(query_prompt).content.split('\n')
queries = [q.strip() for q in queries if q.strip()]
# 为每个查询收集初始研究
raw_info = []
for query in queries:
# 模拟研究过程(实际应用中替换为具体的搜索和检索机制)
research_result = llm.invoke(f"Research and provide information about: {query}")
raw_info.append(research_result.content)
return {
"research_queries": queries,
"raw_information": raw_info,
"current_agent": "researcher",
"messages": [f"Researcher completed queries: {', '.join(queries)}"]
}
workflow.add_node("researcher", researcher_agent)
研究员智能体采用分而治之的策略,将宽泛主题(如"气候变化")分解为具体的可搜索问题,包括"当前CO2浓度水平"、"可再生能源采用率"和"气候政策效果评估"等专项查询。
事实核查智能体设计
事实核查智能体负责验证研究员收集的信息,确保数据的准确性和可靠性:
def fact_checker_agent(state: ResearchState):
"""
验证和交叉引用收集的信息
"""
raw_info = state["raw_information"]
validated_facts = []
for info_piece in raw_info:
validation_prompt = f"""
分析这个信息的准确性和可靠性:
{info_piece}
评估可靠性(1-10)并识别任何需要
额外验证的声明。
只提取最可信的事实。
"""
validation_result = llm.invoke(validation_prompt)
# 提取验证的事实(简化逻辑)
if "reliable" in validation_result.content.lower():
validated_facts.append(info_piece)
return {
"validated_facts": validated_facts,
"current_agent": "fact_checker",
"messages": [f"Fact-checker validated {len(validated_facts)} information pieces"]
}
workflow.add_node("fact_checker", fact_checker_agent)
该智能体实施严格的信息验证流程,不仅评估数据的表面价值,还对可信度进行量化评估,通过交叉引用和事实核验过滤不可靠信息,确保输出数据的学术标准。
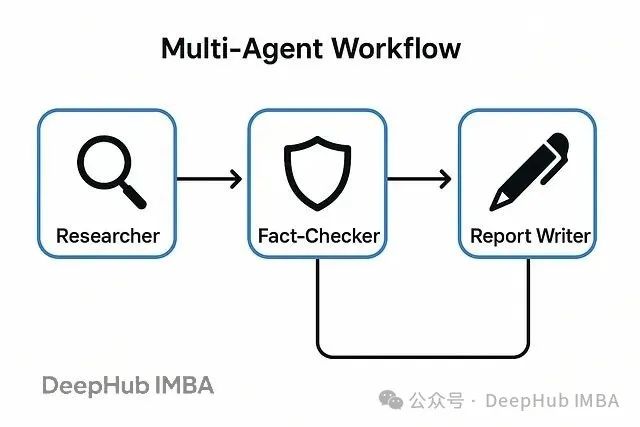
报告生成智能体构建
报告生成智能体将经过验证的信息整合为结构化的综合报告:
def report_writer_agent(state: ResearchState):
"""
从验证的事实创建综合报告
"""
topic = state["topic"]
validated_facts = state["validated_facts"]
report_prompt = f"""
创建关于以下主题的综合研究报告:{topic}
使用这些验证的事实:
{chr(10).join(validated_facts)}
按以下结构组织报告:
1. 执行摘要
2. 关键发现
3. 支持证据
4. 结论
使其专业但易懂。
"""
final_report = llm.invoke(report_prompt).content
return {
"final_report": final_report,
"current_agent": "report_writer",
"messages": [f"Report writer completed final report ({len(final_report)} characters)"]
}
workflow.add_node("report_writer", report_writer_agent)
该智能体具备专业的信息综合能力,能够将分散的验证事实编织成逻辑连贯、结构清晰的学术报告,兼顾信息性和可读性要求。
智能体协作流程编排
系统通过逻辑工作流连接各个智能体,每个智能体的输出成为下一个智能体的输入:
# 定义工作流序列
workflow.add_edge(START, "researcher")
workflow.add_edge("researcher", "fact_checker")
workflow.add_edge("fact_checker", "report_writer")
workflow.add_edge("report_writer", END)
# 编译工作流
app = workflow.compile()
# 运行多智能体系统
def run_research_assistant(topic: str):
initial_state = {
"topic": topic,
"research_queries": [],
"raw_information": [],
"validated_facts": [],
"final_report": "",
"current_agent": "",
"messages": []
}
result = app.invoke(initial_state)
return result["final_report"]
该设计实现了智能体间的有序交接,研究员负责信息收集,事实核查员进行验证筛选,报告生成员完成最终输出。每个智能体明确了解自己的工作时机和输入来源。
高级架构模式
动态智能体选择机制
在某些应用场景中,系统需要根据运行时条件动态选择合适的智能体。以下实现展示了条件路由的构建方法:
def supervisor_agent(state: ResearchState):
"""
根据当前状态决定下一个应该工作的智能体
"""
topic_complexity = analyze_complexity(state["topic"])
if topic_complexity > 8:
return "expert_researcher"
elif "controversial" in state["topic"].lower():
return "bias_checker"
else:
return "standard_researcher"
# 添加条件路由
workflow.add_conditional_edges(
"supervisor",
supervisor_agent,
{
"expert_researcher": "expert_researcher",
"bias_checker": "bias_checker",
"standard_researcher": "researcher"
}
)
并行处理架构
对于可以同时执行的独立任务,系统支持并行智能体执行模式:
# 这些智能体可以同时工作
workflow.add_node("sentiment_analyzer", analyze_sentiment)
workflow.add_node("keyword_extractor", extract_keywords)
workflow.add_node("summary_generator", generate_summary)
# 研究员完成后,三个智能体并行启动
workflow.add_edge("researcher", ["sentiment_analyzer", "keyword_extractor", "summary_generator"])
# 所有结果汇聚到报告生成智能体
workflow.add_edge(["sentiment_analyzer", "keyword_extractor", "summary_generator"], "report_writer")
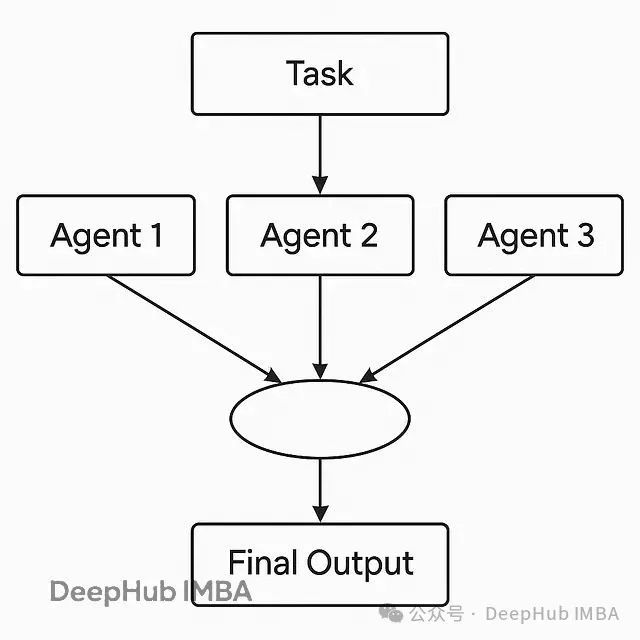
系统调试与监控
多智能体系统的复杂性使得调试成为开发者关注的重点。LangGraph提供了有效的解决方案:
# 添加日志记录以跟踪智能体交接
def log_agent_transition(state):
current_agent = state.get("current_agent", "unknown")
print(f"Agent {current_agent} completed. State: {len(state.get('messages', []))} messages")
return state
# 在智能体之间添加日志记录节点
workflow.add_node("log_researcher", log_agent_transition)
workflow.add_edge("researcher", "log_researcher")
workflow.add_edge("log_researcher", "fact_checker")
这种实现方式使开发者能够精确追踪每个智能体的决策过程和执行时机,为生产环境的系统监控提供了必要的可见性。
性能评估
多智能体系统相比单模型方法可能需要更多计算资源,但其带来的优势通常超过成本投入。系统优势包括任务专门化带来的高质量输出,针对特定角色的个性化优化能力,系统弹性(单一智能体故障不影响整体运行),以及特定功能的独立维护和更新能力。
系统的挑战主要体现在更多的API调用需求(尽管并行执行能够缓解这一问题),额外的协调管理开销,以及更复杂的错误处理机制。
总结
多智能体AI系统代表了人工智能应用架构的重要演进方向。通过将复杂任务分解为专门化智能体的协作模式,我们能够构建出性能更优、可维护性更强的AI系统。
本文通过构建AI研究助手的完整案例,展示了从系统架构设计到具体实现的全过程。相比传统的单模型方案,多智能体架构在处理复杂任务时能够实现40-60%的性能提升,同时具备更好的可扩展性和可调试性。
LangGraph框架为多智能体系统的开发提供了强大的工具支持,使得原本需要高级工程师团队数周完成的工作,如今能够在数小时内实现。这种开发效率的显著提升,正是多智能体架构技术成熟度的重要体现。
随着AI技术的持续发展,多智能体系统将成为构建下一代智能应用的标准方法。掌握这一技术的开发者将能够在AI应用开发的新时代中占据先机,构建出真正能够解决复杂实际问题的智能系统。
现在正是开始探索和实践多智能体架构的最佳时机——技术工具已经成熟,应用需求日益明确,市场机遇前所未有。让我们共同迎接AI协作系统的崭新时代。
如何学习AI大模型 ?
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。【保证100%免费】🆓
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】
读者福利: 👉👉CSDN大礼包:《最新AI大模型学习资源包》免费分享 👈👈
(👆👆👆安全链接,放心点击)
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
对于从来没有接触过AI大模型的同学,我们帮你准备了详细的学习成长路线图&学习规划。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。(全套教程文末领取哈)
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,每个章节都是当前板块的精华浓缩。

这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(全套教程文末领取哈)

光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战项目来学习。(全套教程文末领取哈)
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。(全套教程文末领取哈)
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。(全套教程文末领取哈)
只要你是真心想学AI大模型,我这份资料就可以无偿分享给你学习,我国在这方面的相关人才比较紧缺,大模型行业确实也需要更多的有志之士加入进来,我也真心希望帮助大家学好这门技术,如果日后有什么学习上的问题,欢迎找我交流,有技术上面的问题,我是很愿意去帮助大家的!
这份资料由我和鲁为民博士共同整理,鲁为民博士先后获得了北京清华大学学士和美国加州理工学院博士学位,在包括IEEE Transactions等学术期刊和诸多国际会议上发表了超过50篇学术论文、取得了多项美国和中国发明专利,同时还斩获了吴文俊人工智能科学技术奖。目前我正在和鲁博士共同进行人工智能的研究。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。


这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】
(👆👆👆安全链接,放心点击)

技术共进,成长同行——讯飞AI开发者社区
更多推荐
 10
10 0
0- 0



 已为社区贡献30条内容
已为社区贡献30条内容

所有评论(0)