
【AI概念】数据增强(Data Augmentation)vs 合成数据(Synthetic Data)vs 数据生成(Data Generation)|数学表达与流程、典型技术与应用场景、常见误区
大家好,我是爱酱。本篇将会深入梳理数据增强(Data Augmentation)、合成数据(Synthetic Data)与数据生成(Data Generation)三大常见但易混淆的AI数据技术,结合定义、原理、典型算法、实际应用、优缺点和数学公式,帮助你厘清三者的本质区别与联系。注:本文章含大量数学算式、详细例子说明及大量代码演示,大量干货,建议先收藏再慢慢观看理解。新频道发展不易,你们的每个
大家好,我是爱酱。本篇将会深入梳理数据增强(Data Augmentation)、合成数据(Synthetic Data)与数据生成(Data Generation)三大常见但易混淆的AI数据技术,结合定义、原理、典型算法、实际应用、优缺点和数学公式,帮助你厘清三者的本质区别与联系。
注:本文章含大量数学算式、详细例子说明及大量代码演示,大量干货,建议先收藏再慢慢观看理解。新频道发展不易,你们的每个赞、收藏跟转发都是我继续分享的动力!
一、核心定义与本质区别
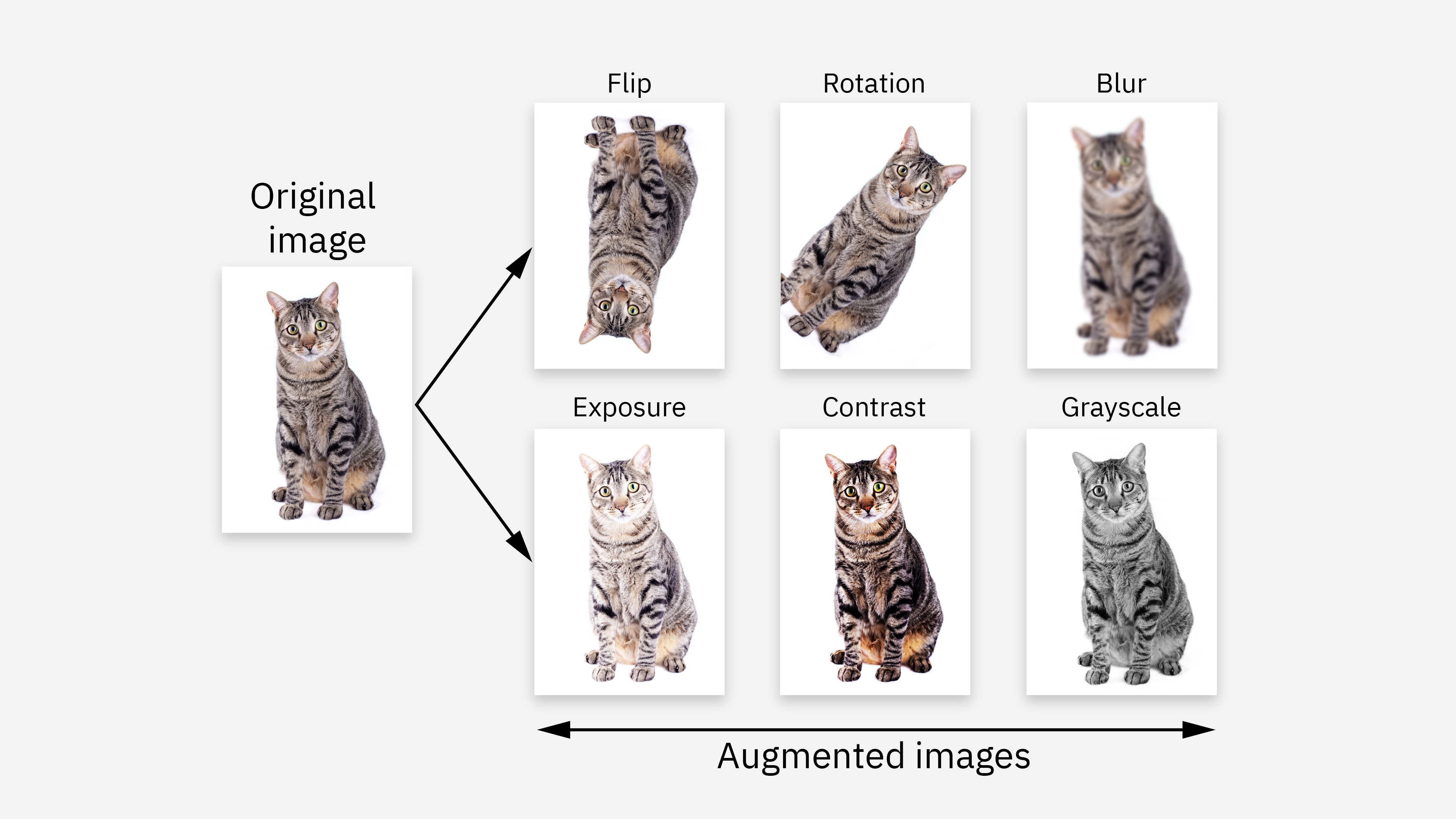
1. 数据增强(Data Augmentation)
-
定义:数据增强是指对现有真实数据进行各种转换、扰动或编辑,生成新的数据样本,从而扩大数据集规模、提升多样性与模型泛化能力。
-
英文专有名词:Data Augmentation
-
本质:所有新样本都基于已有真实数据,通过变换(如旋转、裁剪、加噪声、同义替换等)获得。
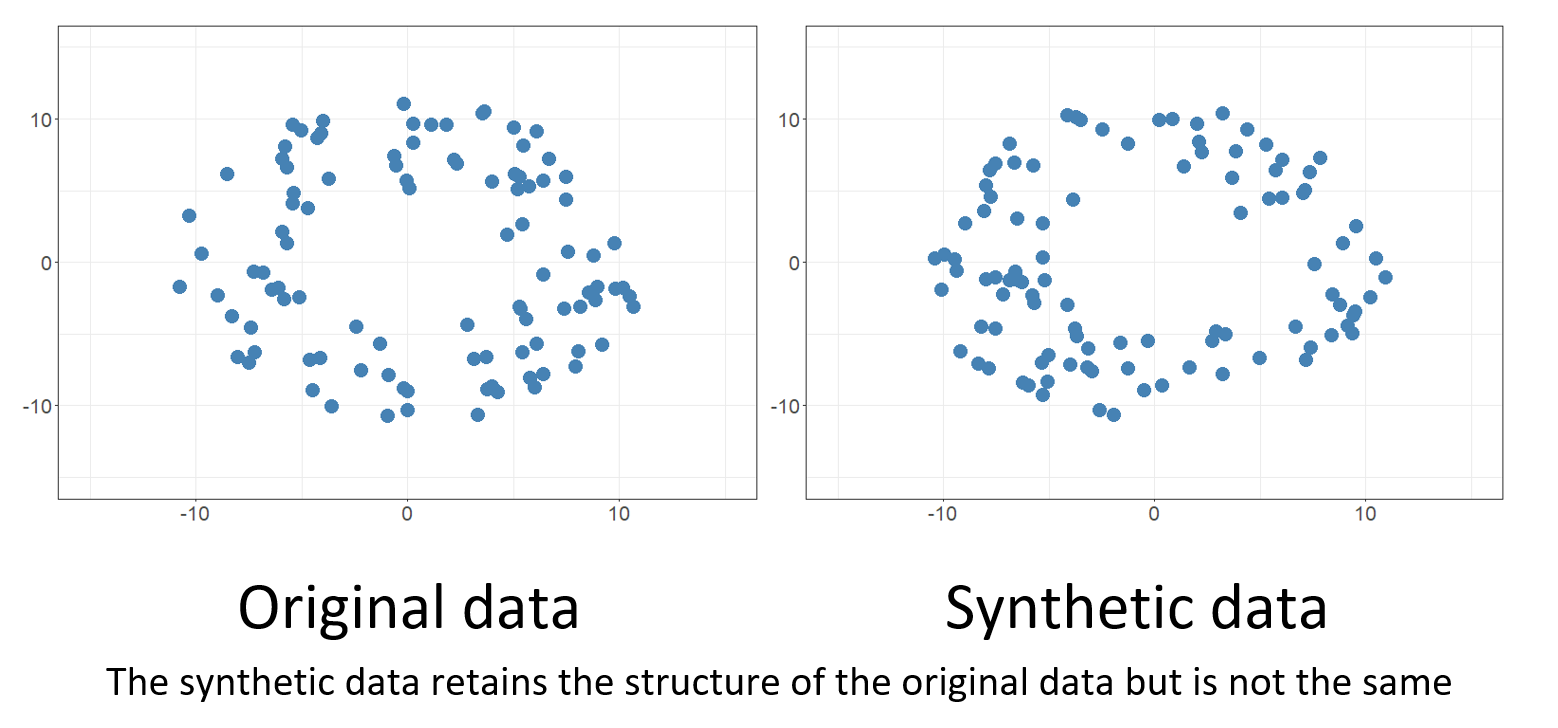
2. 合成数据(Synthetic Data)
-
定义:合成数据是指通过算法、仿真或生成模型(如GAN、VAE等)“从零”人工生成的数据,模拟真实世界数据的统计特性,但并非直接来源于真实观测。
-
英文专有名词:Synthetic Data
-
本质:数据完全由算法生成,可用于补充、替代真实数据,尤其适用于隐私保护、稀缺场景和边缘用例。
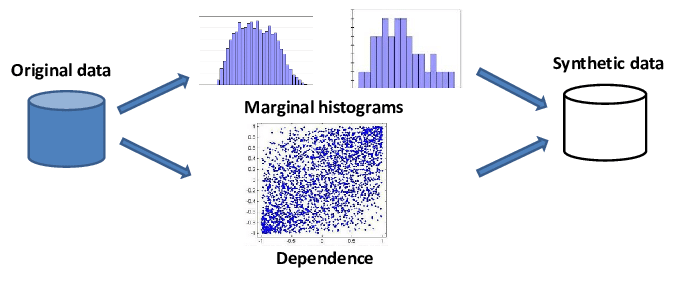
3. 数据生成(Data Generation)
-
定义:数据生成泛指通过算法、规则、仿真或生成模型自动产生数据的过程,既可以指合成数据的生成,也可包含数据增强、数据模拟等更广义的自动化数据产生方式。
-
英文专有名词:Data Generation
-
本质:是一个上位概念,包含数据增强、合成数据等所有人工或自动生成数据的方法。
二、三者的数学表达与流程
1. 数据增强的数学表达
假设原始数据集为 ,增强操作
作用于
,得到增强样本
增强后的数据集为
其中 是所有可用的数据增强变换集合。
2. 合成数据的数学表达
通过生成模型 从噪声或先验 zz 生成新样本:
合成数据集:
其中标签 可由规则、仿真或模型指定。
3. 数据生成的通用表达
数据生成可统一为:
-
:生成函数(可为变换、仿真、生成模型等)
-
:输入噪声或先验
-
:生成参数或规则
三、典型技术与应用场景
| 技术/概念 | 主要方法 | 典型应用场景 | 优势 | 局限/挑战 |
|---|---|---|---|---|
| 数据增强 | 旋转、裁剪、加噪声、同义替换、Mixup等 | 图像识别、语音识别、NLP、医学影像、小样本学习 | 简单高效,提升泛化,防过拟合 | 依赖原始数据,变化有限 |
| 合成数据 | GAN、VAE、仿真、规则生成 | 自动驾驶仿真、医疗隐私保护、边缘用例补充、测试 | 可无限生成,隐私友好,补稀缺 | 真实性、分布偏差、生成难 |
| 数据生成 | 规则/算法/仿真/生成模型 | 测试数据、AI训练、数据填充、模拟实验 | 灵活通用,自动化程度高 | 需保证代表性与多样性 |
四、三者的联系与区别
-
联系:
-
都可用于扩充训练数据,提升模型泛化能力。
-
可结合使用:如先用合成数据生成新样本,再对其做数据增强。
-
-
区别:
-
数据增强是对真实数据的“变体”生成,合成数据是“从零”生成,数据生成是更泛化的上位概念。
-
数据增强强调“多样性”,合成数据强调“可控性”和“补充性”,数据生成强调“自动化与灵活性”。
-
五、实际案例与工程实践
1. 数据增强案例
-
图像分类:对猫狗图片做旋转、翻转、裁剪,提升模型在不同视角下的鲁棒性。
-
NLP文本分类:同义词替换、句子重排,增强模型对多样表达的适应力。
-
医学影像:对少量罕见病影像做增强,提升检测准确率。
2. 合成数据案例
-
自动驾驶:用仿真引擎生成各种极端交通场景,训练鲁棒的感知系统。
-
医疗隐私:用GAN生成虚拟患者数据,既能训练模型又保护隐私。
-
金融风控:合成罕见欺诈交易数据,提升模型识别能力。
3. 数据生成案例
-
软件测试:自动生成满足业务规则的大规模测试数据。
-
AI大模型:用生成式AI自动生成对话、代码、图像等多模态训练数据。
六、常见误区与工程建议
-
误区1:数据增强=合成数据。实际上,数据增强是对已有数据的“变体”,合成数据是“从零”生成。
-
误区2:合成数据一定优于真实数据。合成数据若分布偏差大,反而可能影响模型性能。
-
误区3:只用一种技术即可解决所有数据问题。实际工程常常需要多种技术协同。
建议:
-
数据稀缺时优先用数据增强,极端稀缺或隐私场景用合成数据,复杂自动化需求用数据生成。
-
合成数据需严格评估其分布与真实数据的差异,防止“domain gap”。
-
工程中可先用合成数据预训练,再用真实数据微调。
七、未来趋势与发展方向
-
生成式AI驱动的数据生成:Diffusion、GAN、LLM等模型推动高质量、多模态数据生成。
-
隐私保护与合规:合成数据将在医疗、金融、政务等敏感领域大规模落地。
-
自动化与智能化:AutoML与数据生成深度融合,实现端到端的数据管道自动化。
-
多技术融合:数据增强、合成数据、数据生成将协同提升AI系统的鲁棒性与泛化能力。
八、总结
数据增强(Data Augmentation)、合成数据(Synthetic Data)和数据生成(Data Generation)是现代AI与机器学习系统中提升模型性能、解决数据稀缺和隐私保护问题的三大关键数据技术。三者虽然在实际工程和文献中常被混用,但本质、实现方式和适用场景各具特色。
数据增强以真实数据为基础,通过各种变换(如旋转、裁剪、加噪声、同义替换等)生成“变体”样本,极大丰富了数据分布,提升了模型的泛化能力和鲁棒性。数据增强操作简单、易于集成,是应对小样本、过拟合风险和模型鲁棒性不足的首选手段,广泛应用于图像、语音、文本、医学影像等领域。
合成数据则是利用生成模型(如GAN、VAE)、仿真系统或规则算法“从零”人工生成数据。这类数据不仅能补充真实数据的不足,还能用于隐私保护、模拟极端或稀有场景、降低采集成本。合成数据的优势在于可控性和无限扩展性,但也面临分布偏差、真实性和生成难度等挑战。其在自动驾驶仿真、医疗隐私保护、AI测试等领域展现出巨大潜力。
数据生成是更广义的上位概念,涵盖了所有自动化产生数据的方式,包括数据增强、合成数据、仿真生成、规则生成等。数据生成强调灵活性和自动化,适用于大规模测试、AI训练、数据填充、模拟实验等多种场景,是AI系统数据管道自动化和智能化的基础。
三者的联系在于都可用于扩充训练集、提升模型泛化能力,并可协同使用(如合成数据+数据增强)。区别在于数据增强强调“多样性”、合成数据强调“可控性和补充性”、数据生成强调“自动化和灵活性”。
工程实践建议:
-
数据稀缺时优先采用数据增强,极端稀缺或隐私场景用合成数据,复杂自动化需求用数据生成。
-
合成数据需严格评估与真实数据的分布差异,防止“domain gap”影响模型效果。
-
多技术协同是提升数据价值和模型效能的最佳途径,实际项目中可先用合成数据预训练,再用真实数据微调。
未来趋势方面,生成式AI(如Diffusion、GAN、LLM等)将推动高质量、多模态数据生成,合成数据将在医疗、金融等敏感领域大规模落地,AutoML与数据生成将实现端到端的数据管道自动化,多技术融合将成为AI系统鲁棒性与泛化能力提升的关键。
理解和灵活应用数据增强、合成数据与数据生成,是打造高效、智能、可靠AI系统的基础能力。面对现实世界的数据挑战,只有结合业务需求、数据现状和技术优势,科学选用与组合这些数据技术,才能最大化数据价值,实现AI系统的持续创新与落地。
谢谢你看到这里,你们的每个赞、收藏跟转发都是我继续分享的动力。
如需进一步案例、代码实现或与其他聚类算法对比,欢迎留言交流!我是爱酱,我们下次再见,谢谢收看!

技术共进,成长同行——讯飞AI开发者社区
更多推荐

 23
23 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)