
【源力觉醒 创作者计划】百度文心大模型ERNIE 4.5系列:重塑大模型效能边界的技术革命
在大模型竞争日益激烈的今天,百度文心ERNIE 4.5系列的开源发布引发了广泛关注。这个涵盖从0.3B到424B参数的模型家族,不仅挑战了「更大即更好」的传统认知,更通过创新的架构设计和参数优化,在性能与效率之间找到了令人惊叹的平衡点。本文将从技术创新、架构设计和实战测评三个维度,全面解析ERNIE 4.5系列模型的独特价值,并通过与市场上主流模型的对比,揭示其在不同应用场景中的优势与潜力。
文章目录
| 若 | 全栈若城 大家好,我是若城,本篇文章将带领大家手把手探索百度文心大模型的技术突破与应用价值 |
一起来轻松玩转文心大模型吧!文心大模型免费下载地址: https://ai.gitcode.com/paddlepaddle/ERNIE-4.5-VL-424B-A47B-Paddle
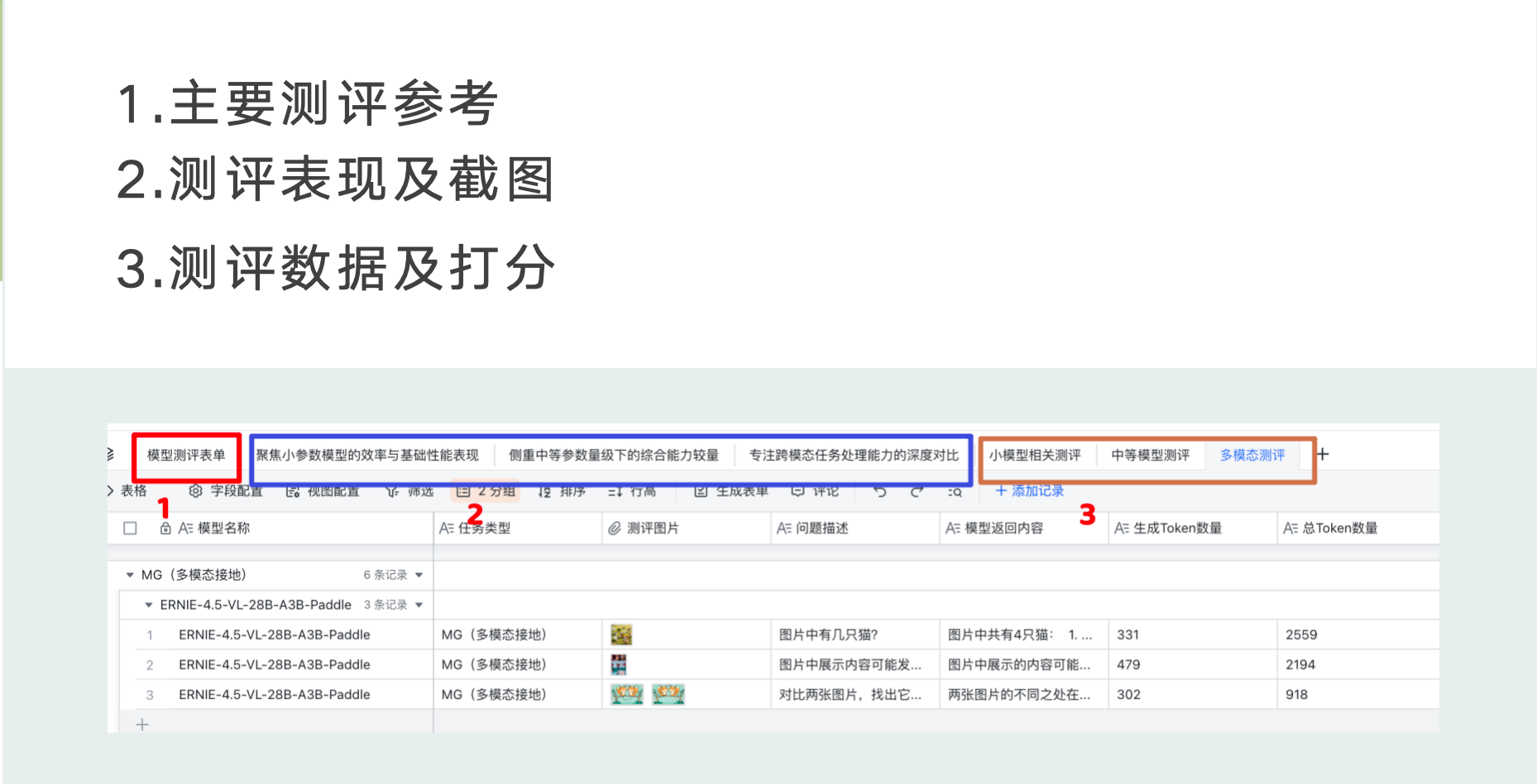
测评数据参考
本篇文章所涉及的测评数据以及不同任务类型下模型的回答内容
点击链接查看详细数据:https://i2i82gjh1i.feishu.cn/sheets/V1s0sICCwhcFZwtacvtced25nSf?from=from_copylink
引言:突破传统认知的模型家族
在大模型竞争日益激烈的今天,百度文心ERNIE 4.5系列的开源发布引发了广泛关注。这个涵盖从0.3B到424B参数的模型家族,不仅挑战了「更大即更好」的传统认知,更通过创新的架构设计和参数优化,在性能与效率之间找到了令人惊叹的平衡点。
本文将从技术创新、架构设计和实战测评三个维度,全面解析ERNIE 4.5系列模型的独特价值,并通过与市场上主流模型的对比,揭示其在不同应用场景中的优势与潜力。
一、技术创新:重新定义大模型架构
1.1 异构MoE架构:效率与性能的完美结合
ERNIE 4.5系列最引人注目的技术创新在于其异构混合专家(Heterogeneous Mixture of Experts, MoE)架构。与传统的密集模型不同,MoE架构允许模型在推理过程中只激活部分参数,大幅提升计算效率。
核心技术亮点:
- 参数激活机制:旗舰模型总参数量高达424B,但实际激活参数仅为47B,计算效率提升近10倍
- 模态分离处理:视觉专家与文本专家分离,确保多模态处理不影响文本任务性能
- 跨模态参数共享:在保持模态独立性的同时实现关键参数共享,平衡效率与性能
- FLOPs优化:视觉专家维度为文本专家的1/3,使FLOPs减少66%,显著提升推理速度
1.2 模块化设计:灵活适配多样化需求
ERNIE 4.5采用高度模块化的设计理念,使模型组件可以灵活组合,适应不同的应用场景。
设计优势:
- 组件可分离性:视觉编码器、视觉专家和适配器可独立移除,实现从多模态到纯文本模型的无缝转换
- 硬件适配性:从高端GPU集群到边缘设备,均有对应的模型变体,满足不同硬件环境需求
- 部署灵活性:支持4-bit/2-bit无损量化、动态角色转换等先进部署技术,降低资源门槛
1.3 视觉处理创新:提升多模态理解能力
在视觉处理方面,ERNIE 4.5-VL系列引入了多项创新技术:
- NaViT架构整合:借鉴先进的视觉Transformer设计,增强图像特征提取能力
- 2D-RoPE技术应用:通过二维旋转位置编码,提升模型对空间关系的理解
- 自适应分辨率处理:优化不同分辨率图像的处理效率,提高视觉理解的准确性
- 时间戳渲染优化:改进视频序列处理,增强时序信息的捕捉能力
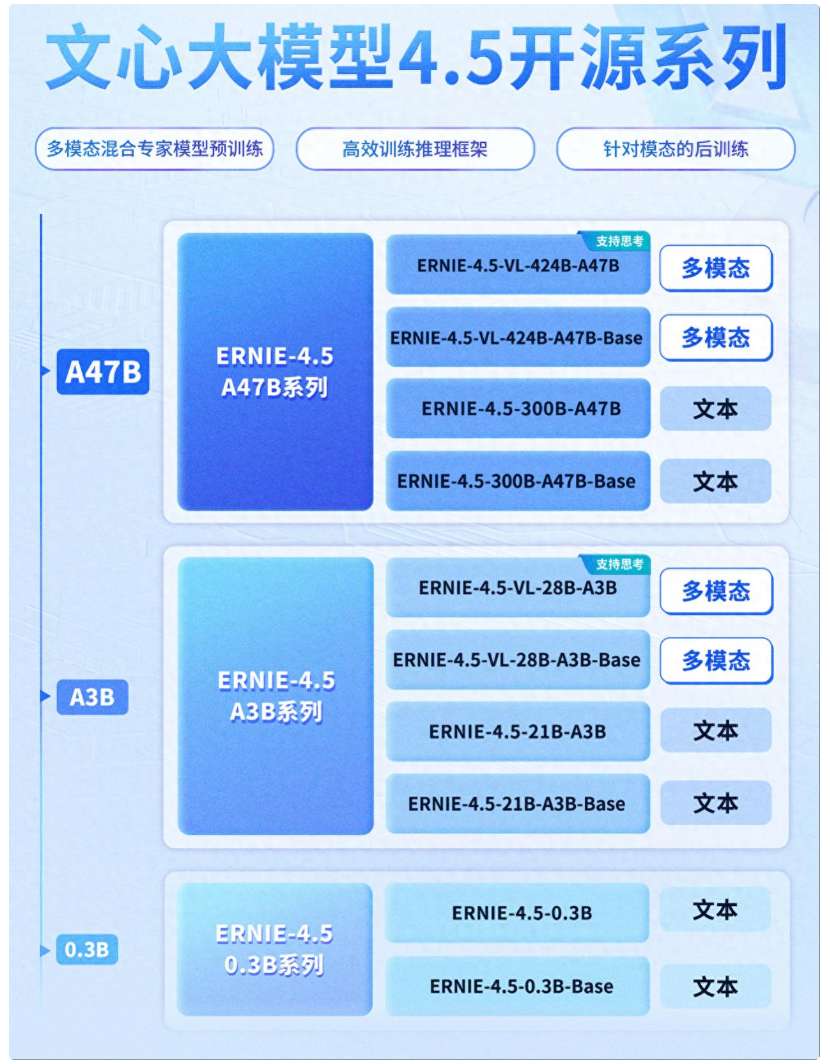
二、模型家族:三大分支的差异化定位
ERNIE 4.5系列覆盖A47B、A3B和0.3B三大分支,形成从超大规模多模态到极致轻量化文本模型的完整谱系。每个分支又细分为Base版和进阶版,满足不同用户的需求层次。
2.1 A47B分支:超大规模多模态旗舰
技术规格:
- 激活参数:47B(总参数424B)
- 架构特点:异构混合专家(MoE)架构
- 性能优化:视觉专家维度为文本专家1/3,FLOPs减少66%
版本差异:
| 对比维度 | Base版 | 进阶版 |
|---|---|---|
| 训练方式 | 基础微调(SFT、LoRA等) | 增加QAT量化感知训练 |
| 核心能力 | 通用多模态基础能力 | 复杂场景推理稳定性增强 |
| 适用场景 | 常规图文问答、基础视频分析 | 医疗影像分析、工业图纸解析 |
2.2 A3B分支:轻量多模态与高效文本
技术规格:
- 激活参数:3B(总参数21B/28B)
- 架构特点:精简专家数量的MoE架构
- 性能优化:自适应分辨率ViT、时间戳渲染优化
版本差异:
| 对比维度 | Base版 | 进阶版 |
|---|---|---|
| 训练方式 | 通用SFT和基础LoRA微调 | 优化推理适配性 |
| 核心能力 | 基础多模态交互 | 效率-性能平衡增强 |
| 适用场景 | 移动端图文识别、简单指令响应 | 智能客服终端、车载交互系统 |
2.3 0.3B分支:极致轻量化文本模型
技术规格:
- 参数规模:0.3B稠密参数
- 架构特点:精简Transformer架构(无MoE)
- 性能优化:FP8混合精度推理
版本差异:
| 对比维度 | Base版 | 进阶版 |
|---|---|---|
| 架构特点 | 基础稠密模型 | 优化推理引擎适配性 |
| 核心能力 | 基础文本处理 | 低功耗场景稳定性增强 |
| 适用场景 | 嵌入式设备基础对话 | 物联网终端、智能家居助手 |
三、实战测评:打破参数规模与性能的线性关系
为全面评估ERNIE 4.5系列的实际表现,我们设计了一套严格的测评方案,将其与市场上同类型的主流模型进行对比。测评涵盖20种任务类型,包括17种文本任务和3种视觉任务,从响应时间、生成速度到输出质量进行多维度评估。
3.1 测评方法与环境配置
测评对象:
| ERNIE 4.5系列 | 对比模型 | 模型类型 |
|---|---|---|
| ERNIE-4.5-0.3B-Paddle | DeepSeek-R1-Distill-Qwen-1.5B | 小型文本模型 |
| ERNIE-4.5-21B-A3B-Paddle | DeepSeek-R1-Distill-Qwen-32B | 中型文本模型 |
| ERNIE-4.5-VL-28B-A3B-Paddle | Qwen2.5-VL-32B-Instruct | 多模态模型 |
硬件环境:
A100-80G GPU服务器,配置16核CPU和64GB内存,使用FastDeploy框架部署。
评分标准:
采用0-10分的评分制度,由专业评估人员(本人_)根据输出质量、准确性和完整性进行评分。
3.2 小型模型对比:以小博大的惊人表现
ERNIE-4.5-0.3B vs DeepSeek-R1-Distill-Qwen-1.5B
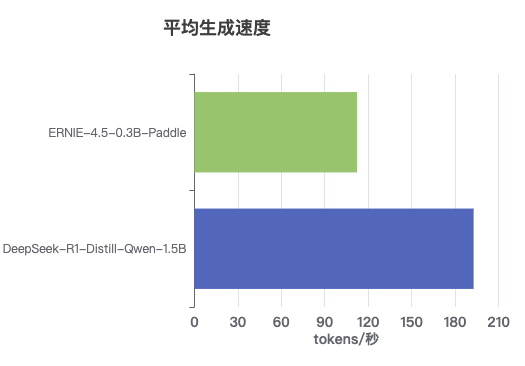
速度对比:
- DeepSeek-1.5B:约194 tokens/秒
- ERNIE-0.3B:约112 tokens/秒
虽然DeepSeek模型在生成速度上领先约1.7倍,但ERNIE模型在质量评分上展现出惊人优势。
质量评分对比:
- ERNIE-0.3B:平均评分7.2分,多数任务评分≥6分
- DeepSeek-1.5B:平均评分4.8分,多数任务评分≤4分
最大优势任务:
- 机器翻译:ERNIE 7.7分 vs DeepSeek 1.0分(+6.7分)
- 序列标记:ERNIE 8.3分 vs DeepSeek 1.7分(+6.6分)
核心发现:
ERNIE-4.5-0.3B以仅1/5的参数量,在质量评分上全面超越DeepSeek-1.5B,证明了优化的模型架构和训练策略可以打破参数规模与性能的线性关系。
3.3 中型模型对比:更小更快更强的全面胜利
ERNIE-4.5-21B-A3B vs DeepSeek-R1-Distill-Qwen-32B
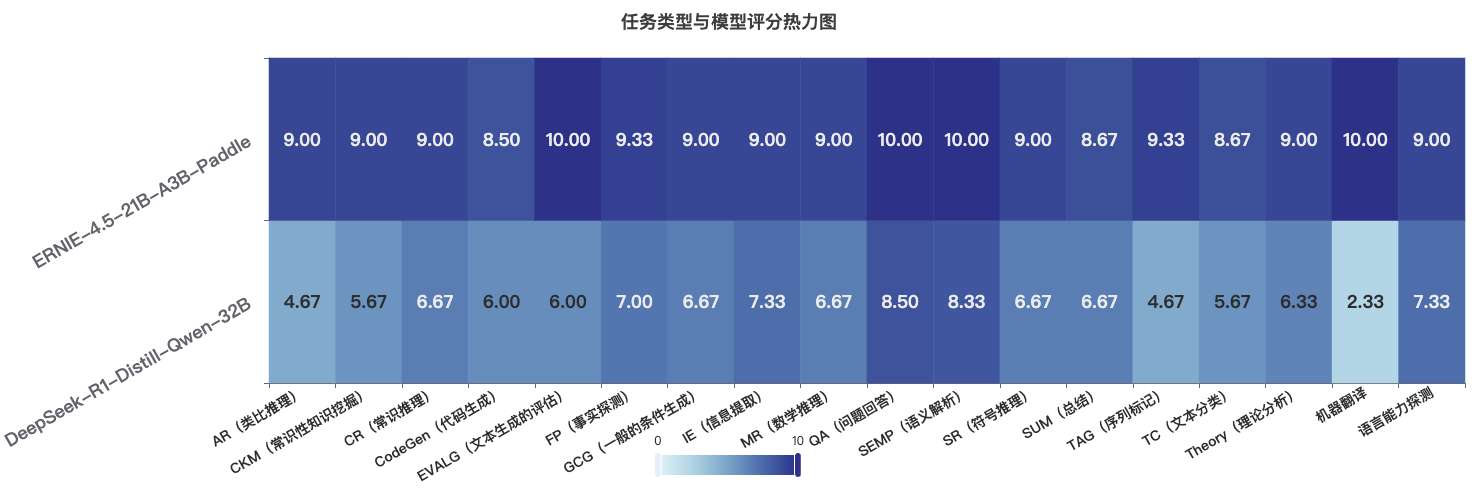
速度与参数对比:
- ERNIE-21B:约59.8 tokens/秒,激活参数3B
- DeepSeek-32B:约43.8 tokens/秒,参数32B
质量评分对比:
- ERNIE-21B:平均评分9.2分,多数任务接近满分
- DeepSeek-32B:平均评分6.3分,表现不均衡
最大优势任务:
- 机器翻译:ERNIE 10.0分 vs DeepSeek 2.3分(+7.7分)
- 序列标记:ERNIE 9.3分 vs DeepSeek 4.7分(+4.6分)
核心发现:
ERNIE-4.5-21B-A3B通过MoE架构,以更少的激活参数实现了更快的速度和更高的质量,在所有测试任务上全面超越DeepSeek-32B,展现了异构MoE架构的巨大优势。
3.4 多模态模型对比:视觉理解的显著领先
ERNIE-4.5-VL-28B-A3B vs Qwen2.5-VL-32B-Instruct
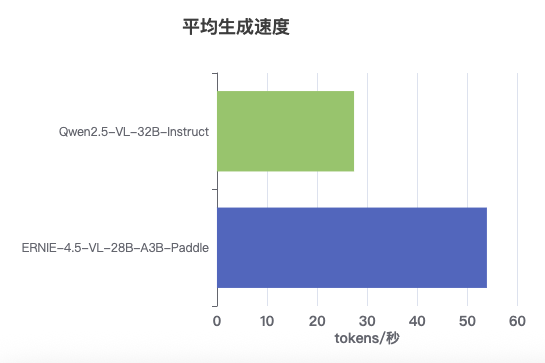
速度对比:
- Qwen2.5-VL:约53.9 tokens/秒
- ERNIE-4.5-VL:约26.9 tokens/秒
虽然Qwen模型在生成速度上领先约2倍,但ERNIE模型在视觉理解质量上展现出决定性优势。
质量评分对比:
- ERNIE-4.5-VL:平均评分9.0分,表现稳定一致
- Qwen2.5-VL:平均评分5.5分,表现波动较大
各任务表现对比:
| 任务类型 | ERNIE-4.5-VL | Qwen2.5-VL | 评分差距 |
|---|---|---|---|
| 多模态接地 | 8.3分 | 3.3分 | +5.0分 |
| 视觉事实探测 | 9.0分 | 7.5分 | +1.5分 |
| 视觉问题回答 | 9.7分 | 5.7分 | +4.0分 |
核心发现:
ERNIE-4.5-VL-28B-A3B在视觉理解质量上全面超越Qwen2.5-VL-32B-Instruct,特别是在多模态接地和视觉问答任务上优势显著,证明了其视觉处理架构的先进性。
四、应用价值:从技术到场景的落地转化
基于测评结果,我们可以清晰地看到ERNIE 4.5系列在不同应用场景中的独特价值。
4.1 参数效率革命:降低AI落地门槛
ERNIE 4.5系列通过MoE架构和参数优化,实现了参数效率的质的飞跃:
- 小型模型:0.3B参数实现接近1.5B模型的性能,参数效率提升约5倍
- 中型模型:激活3B参数超越32B模型,参数效率提升约10倍
- 多模态模型:28B参数模型在视觉理解上超越32B模型
这种参数效率的提升直接转化为更低的硬件要求、更低的部署成本和更广泛的应用场景,大幅降低AI技术落地门槛。
4.2 场景适配策略:Base版与进阶版的差异化价值
ERNIE 4.5系列的Base版与进阶版设计体现了对不同用户需求的精准把握:
Base版价值:
- 「开箱即用」的通用能力,无需复杂配置
- 更低的训练和部署成本
- 适合新手用户或快速验证场景
进阶版价值:
- 针对性能优化的「增强包」
- 支持低比特量化和特殊部署需求
- 适合专业用户和特定领域应用
4.3 最佳应用场景推荐
基于测评结果,我们推荐以下最佳应用场景:
| 模型 | 最佳应用场景 | 核心优势 |
|---|---|---|
| ERNIE-4.5-0.3B | 移动设备、边缘计算、IoT终端 | 超小参数量、较好的文本理解能力 |
| ERNIE-4.5-21B-A3B | 企业级应用、通用AI助手、专业领域服务 | 平衡的速度与性能、全面的能力覆盖 |
| ERNIE-4.5-VL-28B-A3B | 多模态应用、图像分析、视觉问答系统 | 出色的视觉理解能力、高效的跨模态处理 |
五、部署实践:从理论到实战的技术路径
5.1 FastDeploy部署框架
ERNIE 4.5系列模型可通过FastDeploy框架快速部署,支持多种硬件平台:
- NVIDIA GPU:支持A100/A30/H100等高端GPU和A10/4090/L40等中端GPU
- 国产芯片:支持昆仑芯XPU、天数智芯GPU和燧原GCU等
5.2 部署步骤与最佳实践
基本部署流程:
- 安装PaddlePaddle框架
python -m pip install paddlepaddle-gpu==3.1.0 -i https://www.paddlepaddle.org.cn/packages/stable/cu126/
- 安装FastDeploy
# 对于A100/A30/H100等GPU
python -m pip install fastdeploy-gpu -i https://www.paddlepaddle.org.cn/packages/stable/fastdeploy-gpu-80_90/ --extra-index-url https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple
- 启动模型服务
# 文本模型启动示例
python -m fastdeploy.entrypoints.openai.api_server \
--model baidu/ERNIE-4.5-21B-A3B-Paddle \
--port 8180 \
--metrics-port 8181 \
--engine-worker-queue-port 8182 \
--max-model-len 32768 \
--max-num-seqs 32
# 多模态模型启动示例
python -m fastdeploy.entrypoints.openai.api_server \
--model baidu/ERNIE-4.5-VL-28B-A3B-Paddle \
--port 8180 \
--metrics-port 8181 \
--engine-worker-queue-port 8182 \
--max-model-len 32768 \
--enable-mm \
--reasoning-parser ernie-45-vl \
--max-num-seqs 32
5.3 常见问题与解决方案
在部署过程中可能遇到的常见问题及解决方案:
- libgomp.so.1缺失问题
# 更新包列表并安装libgomp1
apt-get update
apt-get install -y libgomp1
- 主机名解析问题
# 将主机名添加到/etc/hosts
hostname=$(hostname)
echo "127.0.0.1 $hostname" >> /etc/hosts
六、结论与展望
ERNIE 4.5系列模型通过创新的异构MoE架构和精细的参数优化,成功挑战了大模型领域「更大即更好」的传统认知。测评结果表明,这一系列模型在保持高性能的同时显著提升了推理效率,为不同应用场景提供了灵活的选择。
核心价值总结:
- 参数效率革命:以更少的参数实现更好的性能,降低AI落地门槛
- 全面的能力覆盖:从文本理解到视觉分析,无明显短板
- 灵活的部署选项:从云端服务器到边缘设备,满足多样化需求
未来展望:
随着异构MoE架构的进一步优化和更多领域专家模型的加入,ERNIE系列有望在更多垂直领域实现突破,同时进一步降低模型部署门槛,推动AI技术的普惠化应用。
详细测评数据可参考:https://i2i82gjh1i.feishu.cn/sheets/V1s0sICCwhcFZwtacvtced25nSf?from=from_copylink
参考资料
- NaViT相关论文 - 一种用于视觉Transformer的先进设计方法,ERNIE 4.5的视觉模块参考了该技术。
- 2D-RoPE技术 - 一种二维旋转位置编码技术,用于提升模型对二维空间信息的理解能力。
- SOTA (State-Of-The-Art) - 文本与多模态基准测试中达到最先进水平,意味着在这些测试场景下,ERNIE 4.5的性能超越了同期其他模型。
- 专家模型(MoE)和Dense模型 - 博主古月居GYH的文章《Dense 与 MoE 系列模型架构的全面对比与应用策略》
- 模型 FLOPs 利用率(Model FLOPs Utilization,MFU)- 衡量硬件计算资源被模型有效利用程度的关键指标。
- FastDeploy - 基于 PaddlePaddle 的大语言模型和视觉语言模型的推理与部署工具包。
- DeepSeek-R1-Distill系列模型 - DeepSeek 公司通过知识蒸馏技术开发的推理增强型模型。
- Qwen2.5-VL-32B-Instruct - 阿里云开源的视觉理解模型,凭借320亿参数实现了超越前代720亿参数模型的性能。

技术共进,成长同行——讯飞AI开发者社区
更多推荐


 47
47 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)