
【最新开源】美研究机构发布全球最大生物学AI模型Evo 2!阶跃星辰首次开源Step系列多模态大模型!
2月19日,美国 Arc Institute 与英伟达合作,联合斯坦福大学、加州大学伯克利分校和加州大学旧金山分校的研究人员,共同推出了——。该模型以超过 128,000 个基因组的数据为基础,训练了 9.3 万亿个核苷酸,使其规模与最强大的生成性 AI 语言模型相媲美。是一种先进的 DNA 语言模型,专注于长上下文的建模和设计。它能够在单核苷酸分辨率下对 DNA 序列进行建模,支持长达 100
01 NVIDIA和Arc研究所联合发布全球最大生物学 AI 模型 —— Evo 2
2月19日,美国 Arc Institute 与英伟达合作,联合斯坦福大学、加州大学伯克利分校和加州大学旧金山分校的研究人员,共同推出了全球最大的生物学人工智能模型 —— Evo 2。

该模型以超过 128,000 个基因组的数据为基础,训练了 9.3 万亿个核苷酸,使其规模与最强大的生成性 AI 语言模型相媲美。
Evo 2 是一种先进的 DNA 语言模型,专注于长上下文的建模和设计。它能够在单核苷酸分辨率下对 DNA 序列进行建模,支持长达 100 万碱基对的上下文长度。
Evo 2 使用 StripedHyena 2 架构进行预训练,并在 OpenGenome2 数据集上进行自回归训练,该数据集包含来自所有生命领域的 8.8 万亿个token。
开发者表示,Evo 1 和 Evo 2 模型的开发代表了新兴的生成式生物学领域的关键时刻,因为这些模型使机器能够“用核苷酸语言来读、写和思考”。
Evo 2 具备多种功能,包括识别影响蛋白质功能和生物体适应性的基因变化。例如,在乳腺癌相关基因 BRCA1 变体的测试中,Evo 2 预测基因突变良性或致病性的准确率超过 90%,这将有助于加速新药研发,节省实验时间和成本。此外,Evo 2 还能用于设计新的生物工具和疗法。
目前,Evo 2 的开发团队已发布该模型的详细信息,并推出名为 Evo Designer 的用户友好界面。Evo 2 的代码已在 Arc 的 GitHub 上公开,并已集成至 NVIDIA 的 BioNeMo 框架,以促进科学研究的进展。
02 阶跃星辰首次宣布开源Step系列多模态大模型
2月18日,阶跃星辰和吉利汽车集团联合开源了两款阶跃 Step 系列多模态大模型—— Step-Video-T2V 视频生成模型和 Step-Audio 语音模型。
-
目前全球范围内参数量最大、性能最好的开源视频生成模型——阶跃 Step-Video-T2V:参数量达到300亿,可以直接生成204帧、540P分辨率的高质量视频。
-
行业内首款产品级开源语音交互大模型——阶跃 Step-Audio:能够根据不同的场景需求生成情绪、方言、语种、歌声和个性化风格的表达,能和用户自然地高质量对话。
从官方公布的技术报告来看,这次开源的两款模型在Benchmark中表现优秀,性能超过国内外同类开源模型。

2.1 全球最大开源视频模型 Step-Video-T2V
Step-Video-T2V 是一个先进的文本到视频预训练模型,拥有30B参数,能够生成长达 204 帧的视频。这是目前已知全球范围内参数量最大的开源视频生成大模型,原生支持中英双语输入。

Step-Video-T2V共有 4 大技术特点:
1. 可直接生成最长204帧、540P分辨率的视频,确保生成的视频内容具有极高的一致性和信息密度。
2. 针对视频生成任务设计并训练了高压缩比的Video-VAE,在保证视频重构质量的前提下,能够将视频在空间维度压缩16×16倍,时间维度压缩8倍。(当下市面上多数VAE模型压缩比为8x8x4,在相同视频帧数下,Video-VAE能额外压缩8倍,故而训练和生成效率都提升64倍。)
3. 针对DiT模型的超参设置、模型结构和训练效率,Step-Video-T2V 进行深入的系统优化,确保训练过程的高效性和稳定性。
4. 详细介绍了预训练和后训练在内的完整训练策略,包括各阶段的训练任务、学习目标以及数据构建和筛选方式。
例如,在训练最后阶段引入 Video-DPO(视频偏好优化)——这是一种针对视频生成的RL优化算法,能进一步提升视频生成质量,强化生成视频的合理性和稳定性。
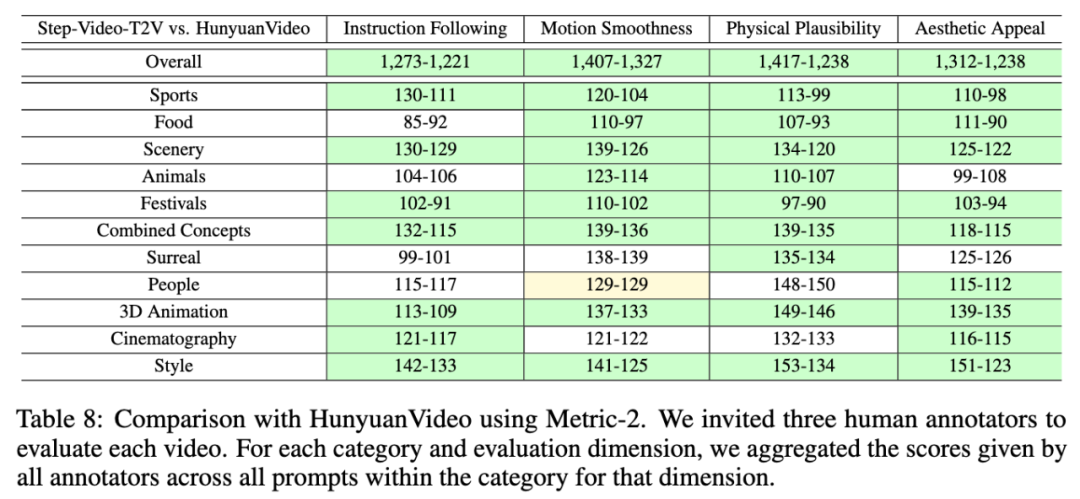
该项目在一个新的视频生成基准 Step-Video-T2V-Eval 上进行了评估,评测结果如下表所示。
可以看到,Step-Video-T2V 在指令遵循、运动平滑性、物理合理性、美感度等方面,表现均超越此前最佳的开源视频模型。
-
Step-Video-T2V的Github地址:https://github.com/stepfun-ai/Step-Video-T2V
-
Step-Video-T2V 技术报告:https://arxiv.org/abs/2502.10248
2.2 行业内首个产品级的开源语音交互模型 Step-Audio
Step-Audio,是行业内首个产品级的开源语音交互模型。
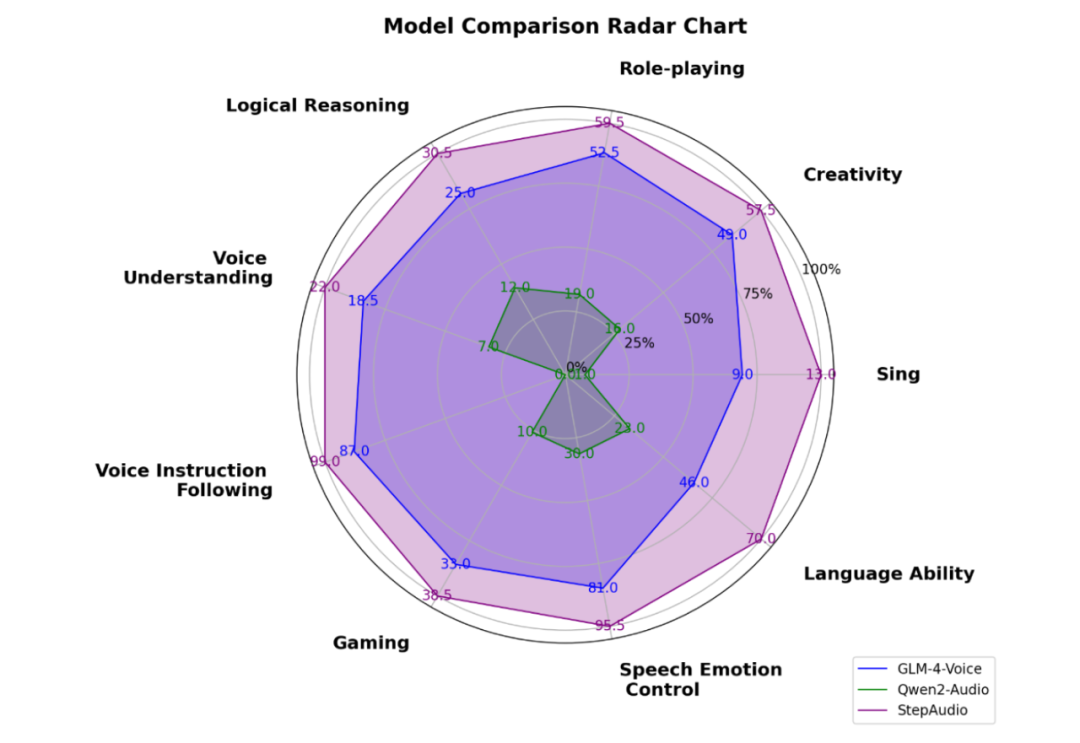
在阶跃自建并开源的多维度评估体系 StepEval-Audio-360 基准测试上,Step-Audio 在逻辑推理、创作能力、指令控制、语言能力、角色扮演、文字游戏、情感价值等维度,均取得最佳成绩。
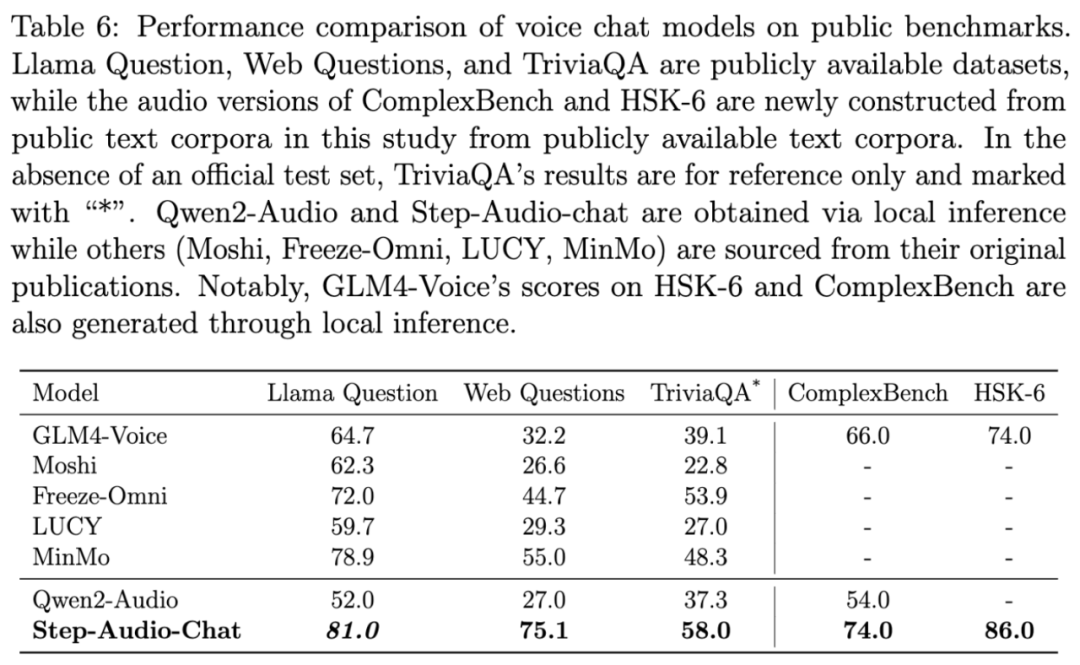
在 LlamA Question、Web Questions 等 5 大主流公开测试集中,Step-Audio 性能均超过了行业内同类型开源模型,位列第一。可以看到,它在 HSK-6(汉语水平考试六级)评测中的表现尤为突出。
-
Step-Audio 的Github地址:https://github.com/stepfun-ai/Step-Audio
-
Step-Audio 技术报告:https://github.com/stepfun-ai/Step-Audio/blob/main/assets/Step-Audio.pdf
参考:
https://arcinstitute.org/news/blog/evo2
https://zhuanlan.zhihu.com/p/24480513575
欢迎各位关注我的微信公众号:HsuDan,我将分享更多自己的学习心得、避坑总结、面试经验、AI最新技术资讯。


技术共进,成长同行——讯飞AI开发者社区
更多推荐



 20
20 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)