
【多模态】swift3使用——多模态模型的类lora的不同peft方式
swift框架支持的不同peft方式
【多模态】swift3使用——多模态模型的类lora的不同peft方式
安装方法
conda create -n swift python=3.10
pip install ms-swift qwen_vl_utils vllm
1.lora
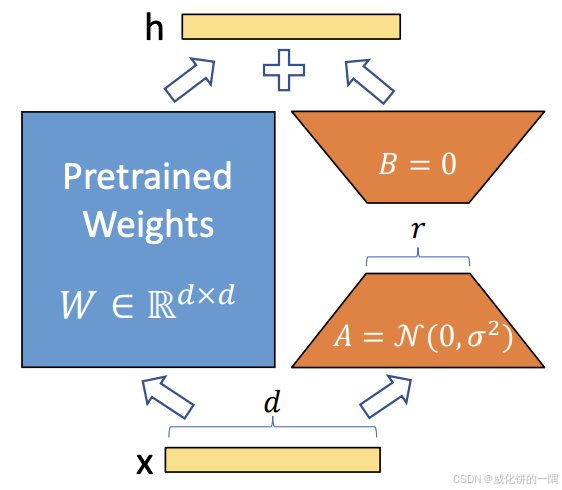
通常情况下直接使用lora即可,lora的rank=8,alpha=32,不那么容易过拟合,通常lora的rank变大并没有太多好处除了更消耗训练资源。swift3中直接使用下面的脚本,注明train_type为lora即可。
lora可以调整的粗粒度的三个冻结参数为freeze_vit、freeze_aligner、freeze_llm,分别表示是否要在ViT、merger和LLM模块中增加lora旁路微调,通常这三个都设置为false不冻结都增加旁路效果是最好的。
如果需要细粒度的控制微调哪些模块,可以用target_modules和target_regex来控制。
CUDA_VISIBLE_DEVICES=0 MAX_PIXELS=1003520 swift sft \
--model_type qwen2_vl \
--model /home/模型地址/ \
--dataset /home/train_dataset.jsonl \
--train_type lora \
--attn_impl flash_attn \
--freeze_vit false \
--freeze_aligner false \
--freeze_llm false \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 2 \
--split_dataset_ratio 0.1 \
--output_dir /home/model_save_dir \
--num_train_epochs 6 \
--save_steps 20 \
--eval_steps 20 \
--acc_strategy seq \
--save_total_limit 2 \
--logging_steps 10 \
--seed 42 \
--learning_rate 1e-4 \
--init_weights true \
--lora_rank 8 \
--lora_alpha 32 \
--adam_beta1 0.9 \
--adam_beta2 0.95 \
--adam_epsilon 1e-08 \
--weight_decay 0.1 \
--gradient_accumulation_steps 16 \
--max_grad_norm 1 \
--lr_scheduler_type cosine \
--warmup_ratio 0.05 \
--warmup_steps 0 \
--gradient_checkpointing false
2.lora+
《LoRA+: Efficient Low Rank Adaptation of Large Models》论文中提出来的,提出的微调时让B矩阵的学习率比A矩阵大一些效果会好一些,大概好1%-2%。苏神的空间中有详细解释:
在swift3框架里面,实际操作时,需要设置train_type为lora的情况下设置lorap_lr_ratio参数,设置为例如10。
3.Rank-Stabilized LoRA
在《A Rank Stabilization Scaling Factor for Fine-Tuning with LoRA》中提出,核心表达的是只增加lora的rank效果可能不会明显提升lora效果,还要同时调整lora的学习,可以获得更低的loss。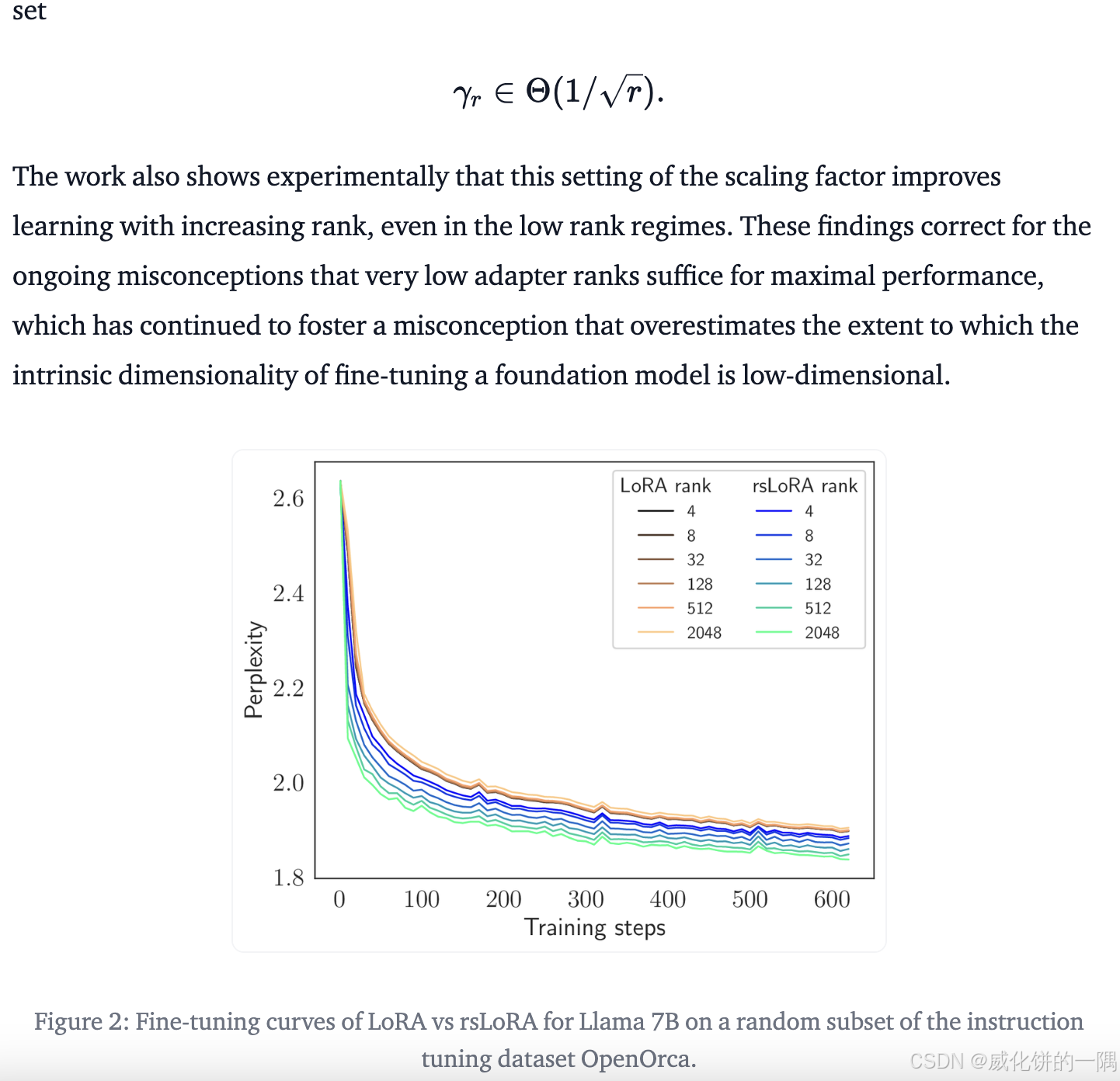
report里面看上去有提升但是不明显,实验测试了几次没做出提升的效果。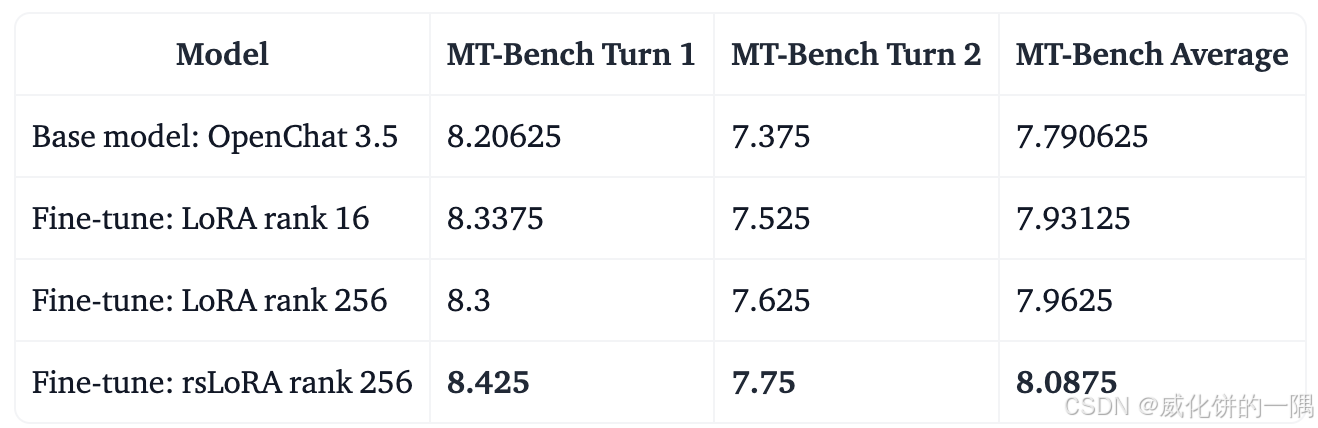
swift3框架里面使用Rank-Stabilized LoRA,需要设置train_type为lora的情况下设置use_rslora参数为true,默认是false。
4.dora
可以作者写的参考官方介绍,显示dora在各种任务上比lora大概1%-2%的提升。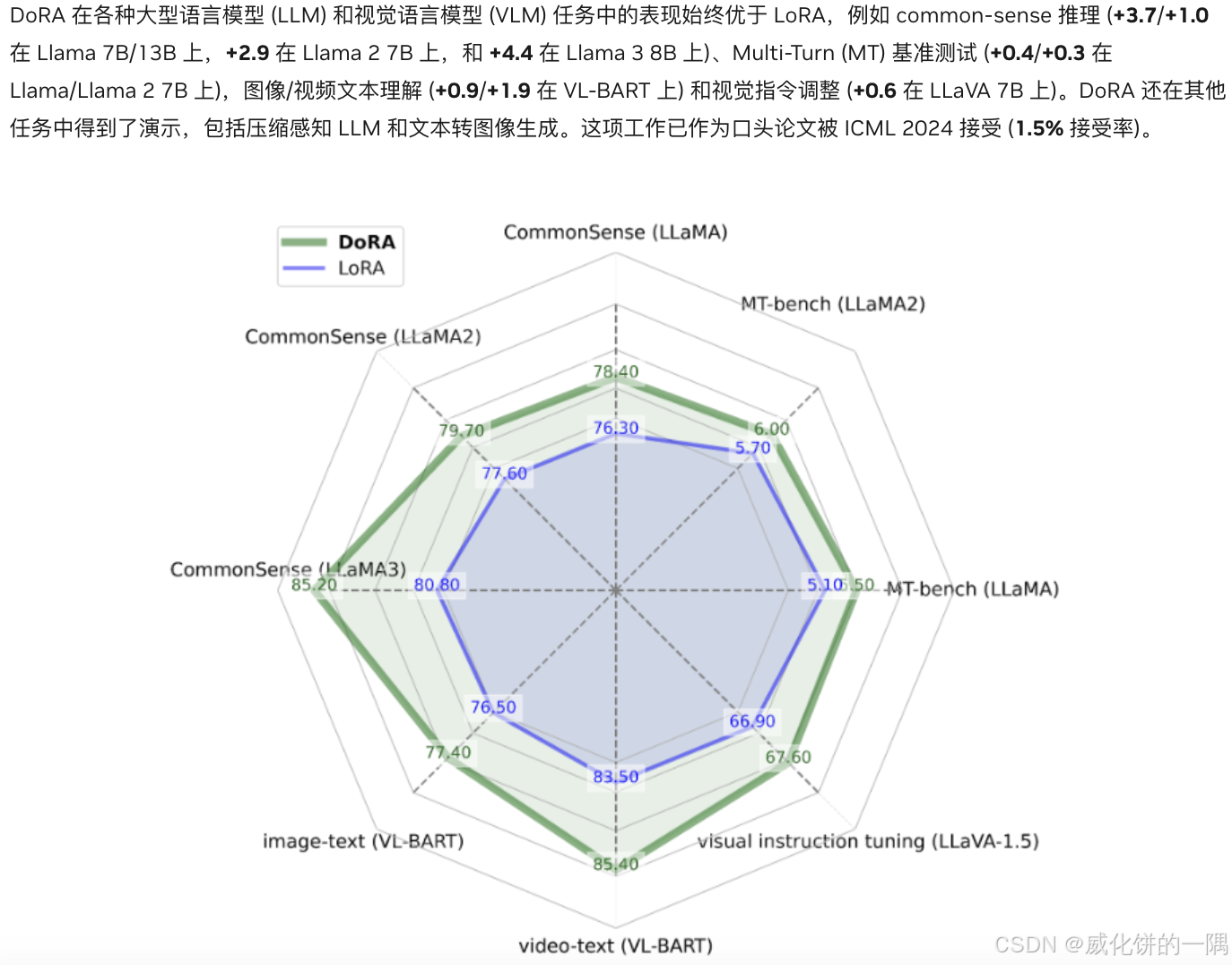
“DoRA 首先将预训练权重分解为其 大小 和 方向 分量,然后对两者进行微调。由于方向分量在参数方面的尺寸较大,DoRA 利用 LoRA 进行方向适应,以实现高效的微调,最后在推理前可以将 DoRA 与预训练权重合并,从而避免引入额外的延迟。”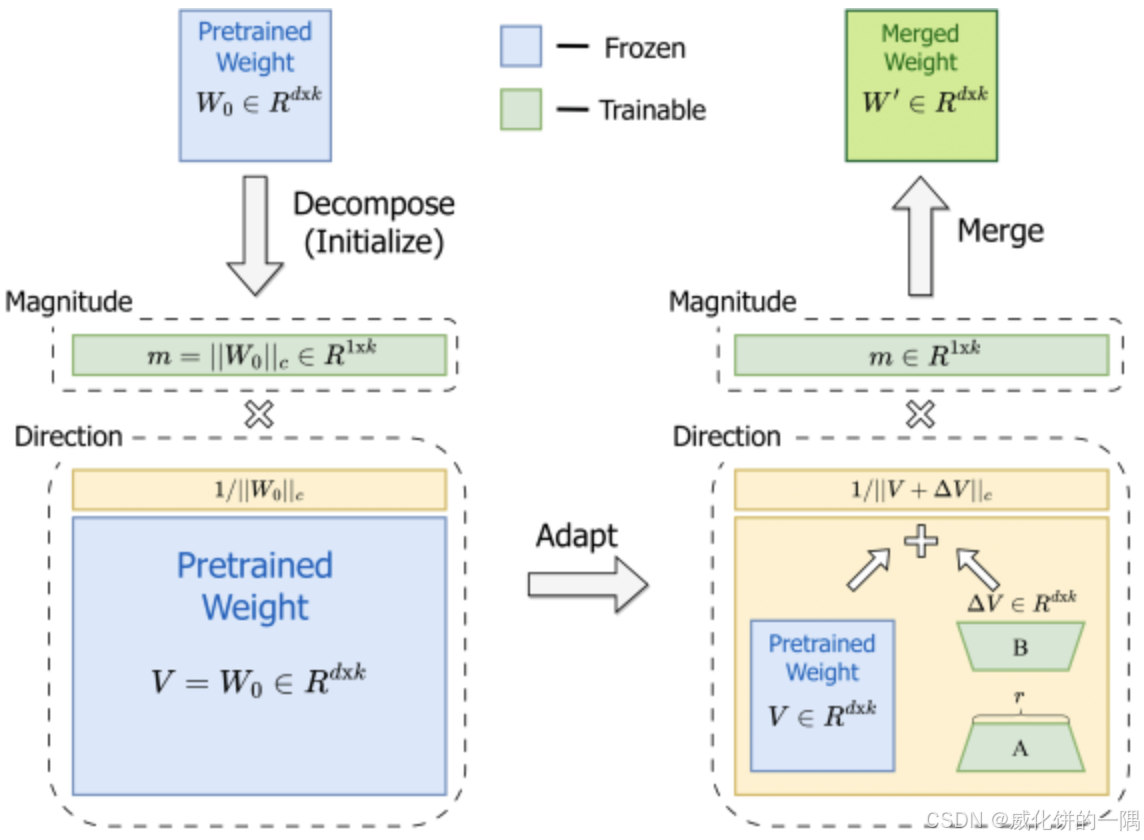
swift3框架里面使用dora,需要设置train_type为lora的情况下,设置参数为true,默认是false。
5. 冻结一部分比例微调
swift3还支持训练%的参数,例如训练30%的原始参数,冻结70%,作为全参数微调和peft的折中。需要设置train_type为full进行全参微调,然后设置freeze_parameters_ratio为0.7,指的是从模型头到模型尾,冻结前面70%的参数,不冻结后面30%的参数。internvl2.5系列这种训练方式效果比lora好,qwen2-vl这种方式训练不太稳定。
# swift3的freeze_parameters部分对应的源码
def freeze_parameters(model: nn.Module, freeze_parameters_ratio: float, freeze_parameters: List[str]) -> None:
if freeze_parameters_ratio > 0:
n_parameters = get_n_params_grads(model)[0]
n_parameters = np.array(n_parameters, dtype=np.int64)
n_freeze_parameters = int(np.sum(n_parameters) * freeze_parameters_ratio)
n_parameters_cs = np.cumsum(n_parameters)
idx = bisect_right(n_parameters_cs, n_freeze_parameters)
for _, p in zip(range(idx), model.parameters()):
p.requires_grad = False
if len(freeze_parameters) > 0:
for n, p in model.named_parameters():
for freeze_p in freeze_parameters:
if n.startswith(freeze_p):
p.requires_grad = False

技术共进,成长同行——讯飞AI开发者社区
更多推荐


 13
13 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)