
Qwen3开源震撼来袭,引领大模型新时代
在人工智能领域,大模型的发展日新月异,不断重塑着技术格局。就在4月29日凌晨,阿里云重磅开源了Qwen3系列模型,这一动作无疑为行业投下了一颗“重磅炸弹”。Qwen3凭借卓越的性能和创新特性,引发了开发者和技术爱好者的广泛关注,有望成为推动AI技术迈向新高度的关键力量。接下来,就让我们深入了解Qwen3带来的全新变革。
目录

引言
在当今科技飞速发展的时代,AI 大模型已成为推动各行业变革的核心力量。从最初的 GPT 系列引发全球关注,到如今众多国产大模型如雨后春笋般涌现,大模型领域呈现出百花齐放的繁荣景象。2025 年 4 月 29 日凌晨,阿里巴巴宣布开源新一代通义千问模型 Qwen3,再次为这个充满活力的领域注入了新的强大动力,引发了 AI 社区和广大开发者的热烈讨论 。
Qwen3 开源发布
4 月 29 日凌晨,阿里云正式开源新一代通义千问模型 Qwen3 系列,这一消息犹如一颗重磅炸弹,在 AI 领域掀起了轩然大波 。此次开源的 Qwen3 系列模型阵容强大,包含了 2 个 MoE(混合专家)模型以及 6 个稠密模型 ,涵盖了从 0.6B 到 235B 等 8 种不同的参数规模。无论是追求极致性能的大型企业,还是资源有限但充满创新活力的小型团队,亦或是热衷于探索新技术的个人开发者,都能在 Qwen3 系列中找到适合自己需求的模型。
Qwen3 系列模型在多个知名开源平台上全面开源,包括 Hugging Face、ModelScope 和 Kaggle 等,并且均遵循宽松的 Apache 2.0 许可证。这意味着全球的开发者、研究机构和企业不仅可以免费下载这些模型,还能够将其应用于商业项目中,无需担心高昂的授权费用和复杂的使用限制,为 AI 技术的广泛应用和创新发展消除了一大障碍 。
性能卓越超越同行
(一)基准评测实力碾压
Qwen3 系列模型在性能表现上堪称惊艳,尤其是旗舰 MoE 模型 Qwen3 - 235B - A22B,在多个关键领域的基准评测中展现出了碾压同行的实力 。在代码生成能力的评估中,使用 LiveCodeBench 基准测试,Qwen3 - 235B - A22B 能够快速生成高质量、符合规范且逻辑清晰的代码片段。无论是复杂的算法实现,还是涉及多种编程语言特性的综合项目,它都能精准理解需求,生成的代码不仅语法正确,还具备良好的可读性和可维护性,在测试中的得分远高于 DeepSeek - R1 等模型 。
在数学推理方面,AIME25 基准测试是检验模型数学能力的重要指标。面对复杂的数学问题,Qwen3 - 235B - A22B 能够深入分析问题,运用强大的推理能力逐步推导,给出准确的解答。例如在解决一些涉及高等数学的复杂证明题或多步骤计算题时,它展现出的逻辑思维和计算准确性,超越了 OpenAI o1、谷歌 Gemini - 2.5 - Pro 等知名模型,彰显了其在数学领域的深厚造诣 。
在通用能力的基准评估中,Qwen3 - 235B - A22B 同样表现出色。无论是对常识性知识的理解与应用,还是对复杂语义的解读和生成,它都能快速给出合理且准确的回应。在面对各类常识问答、文本摘要、语义理解等任务时,其表现稳定且优异,全面超越了同类型的其他模型 。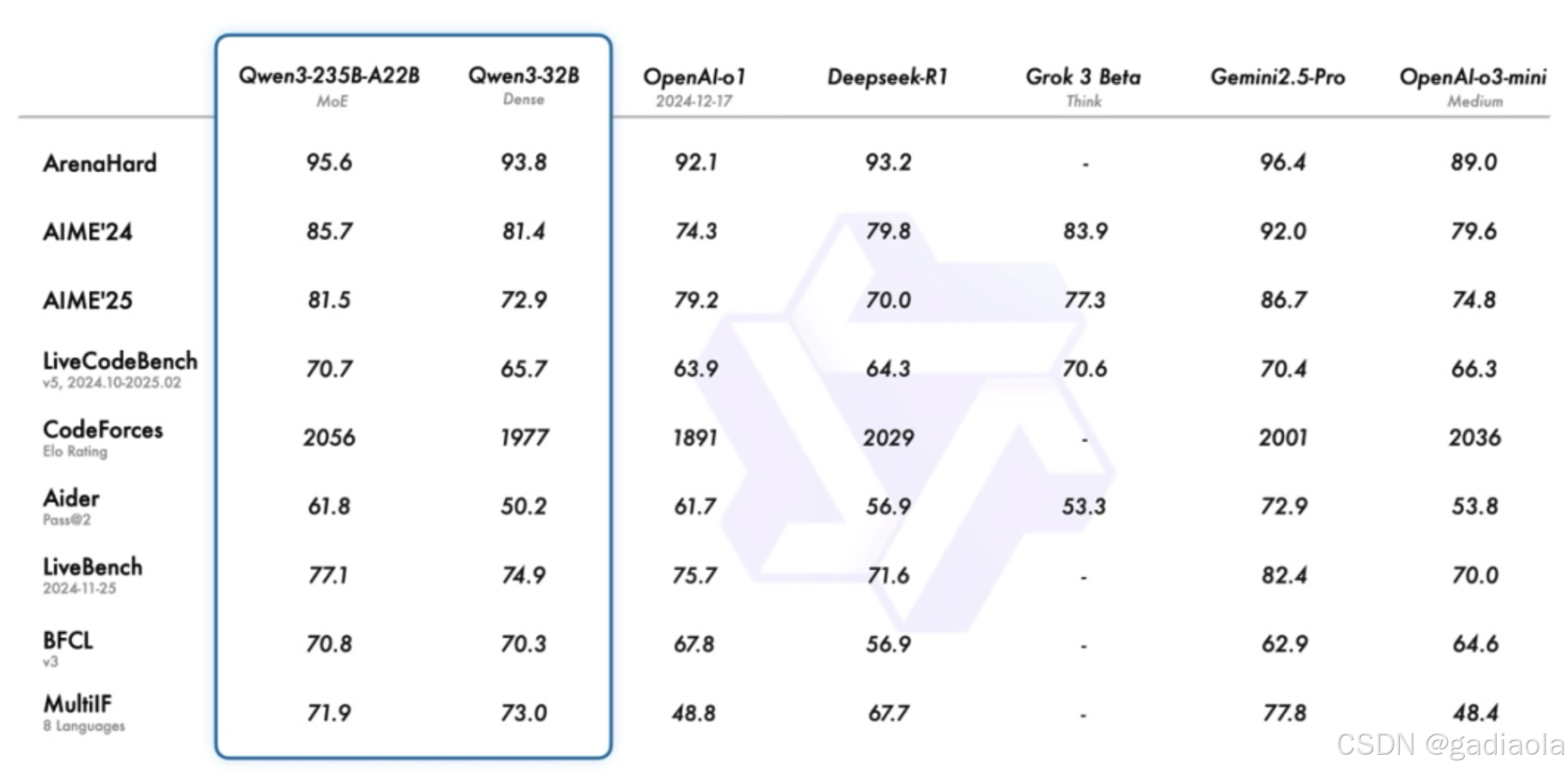
(二)以小博大参数优势
除了大型模型的卓越表现,Qwen3 系列中的小型模型也展现出了令人惊喜的 “以小博大” 的能力 。小型 MoE 模型 Qwen3 - 30B - A3B,总参数约为 300 亿,激活参数仅 30 亿 ,却在性能上实现了对 Qwen2.5 - 32B 的超越 。在 ArenaHard、LiveCodeBench 等多项测试中,Qwen3 - 30B - A3B 展现出了强大的实力。在代码理解和生成任务中,它能够迅速理解代码逻辑,并根据需求进行准确的修改和扩展,表现甚至优于一些参数量更大的模型 。
而 Qwen3 - 4B 这样参数规模更小的模型,同样有着出色的表现,性能匹敌前代 72B 模型 Qwen2.5 - 72B - Instruct 。在部分基准测试中,Qwen3 - 4B 面对复杂的文本分类、情感分析等任务时,能够快速准确地给出结果,展现出了超越其参数规模的能力 。这一系列小型模型的出色表现,充分证明了 Qwen3 系列在模型设计和训练优化上的巨大成功,通过创新的技术手段,实现了小参数模型的高性能表现,为资源有限的场景提供了强大的解决方案 。
五大特性创新升级
(一)丰富模型参数体系
Qwen3 系列模型在参数体系上进行了全面的拓展,提供了 8 种不同参数大小的模型,包括 0.6B、1.7B、4B、8B、14B、32B 这 6 个稠密模型,以及 Qwen3 - 235B - A22B(2350 亿总参数和 220 亿激活参数)、Qwen3 - 30B - A3B(300 亿总参数和 30 亿激活参数)这 2 个 MoE 模型 。不同参数规模的模型适用于各种不同的应用场景,小型模型如 0.6B、1.7B 适用于资源有限的边缘设备或对响应速度要求极高的移动端应用,能够在低算力环境下快速运行,满足简单任务的处理需求 。而大型模型如 Qwen3 - 235B - A22B 则凭借其强大的参数规模和复杂的模型结构,适用于对智能水平要求极高的企业级应用,如复杂的数据分析、决策支持系统等 。
在上下文长度设置上,Qwen3 系列也进行了精心的优化。其中,0.6B、1.7B、4B 参数规模的模型上下文长度为 32K,这使得它们在处理一些长度适中的文本任务时,能够充分理解上下文信息,给出准确的回复 。而 8B 及以上参数规模的模型,包括 8B、14B、32B 以及两个 MoE 模型,上下文长度均为 128K 。更长的上下文长度使得这些模型在处理长篇文档、多轮复杂对话等任务时具有明显优势,能够更好地把握文本的整体逻辑和语义,提供更加连贯和准确的回答 。
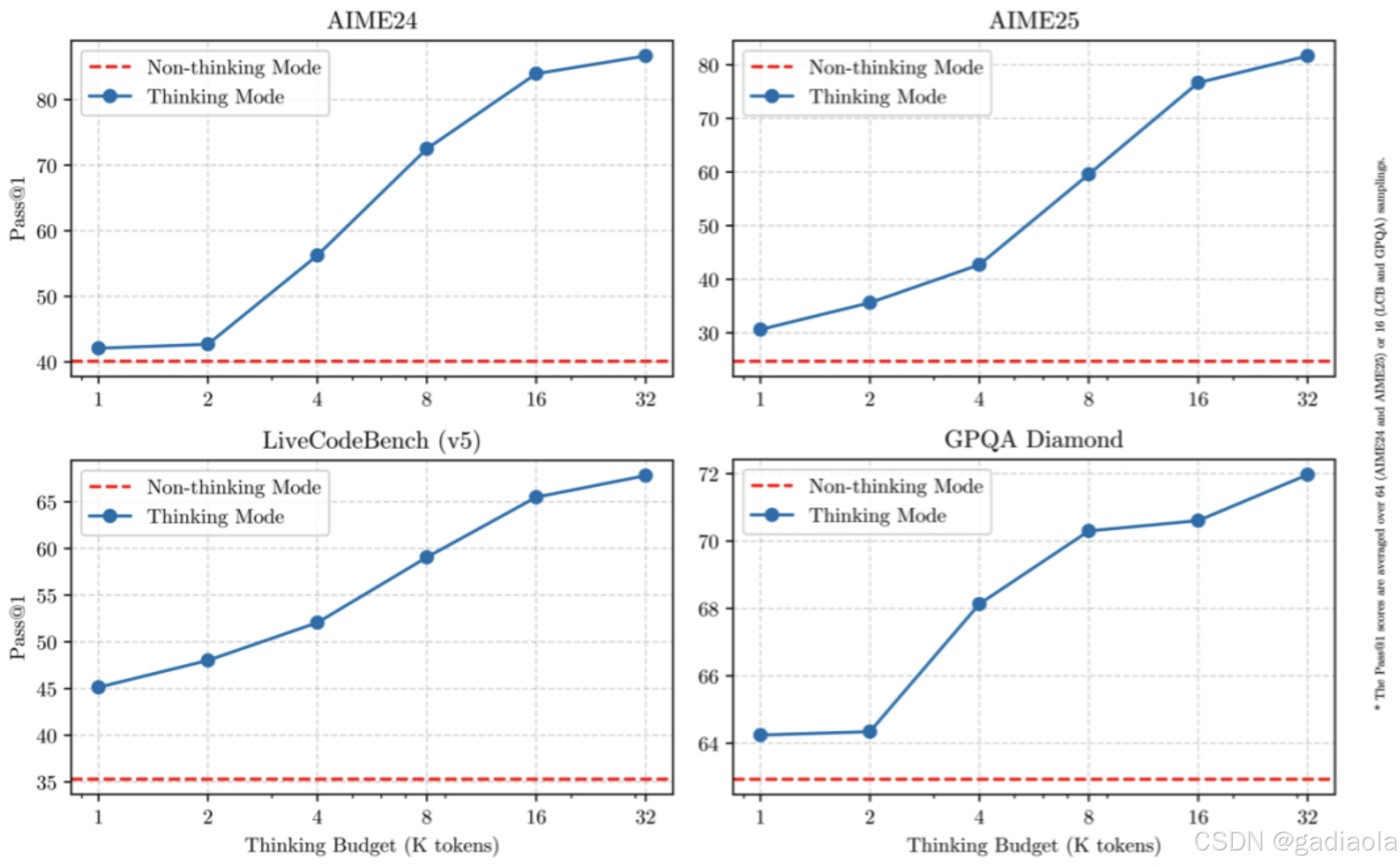
(二)混合思考灵活切换
Qwen3 系列模型引入了创新的 “思考模式” 与 “非思考模式”,为用户提供了更加灵活的交互体验 。在思考模式下,模型会启动深度推理机制,对问题进行逐步分析和推理,就像一位深思熟虑的学者,在面对复杂问题时,会调动大量的知识和逻辑思维,花费一定的时间来给出最终答案 。例如在解决数学证明题、复杂的逻辑推理问题或需要深入分析的专业领域问题时,思考模式能够让模型展现出强大的推理能力,通过多步骤的推导和论证,得出准确且详细的解答 。
而在非思考模式中,模型则像是一位反应敏捷的助手,能够提供快速、几乎瞬间的响应 。这种模式适用于那些对速度要求高于深度的简单问题,比如日常的闲聊、简单的信息查询等场景 。用户在与模型交互时,可以根据任务的实际需求,自由地切换这两种模式 。如果遇到紧急需要快速获取信息的情况,就可以选择非思考模式,迅速得到答案;而当面对需要深入探讨和分析的复杂问题时,切换到思考模式,让模型进行深度思考,提供更有价值的见解 。
(三)推理能力显著提升
在推理能力方面,Qwen3 较之前代模型以及部分同类模型有了质的飞跃 。与 QwQ 相比,在思考模式下,Qwen3 在数学推理、代码生成和常识逻辑推理等任务上表现得更加出色 。在解决复杂的数学问题时,Qwen3 能够更准确地理解问题的本质,运用多种数学方法和逻辑进行推导,给出更严谨的解答 。在代码生成任务中,它可以生成更高效、更符合规范的代码,并且能够更好地理解代码的上下文和业务逻辑,根据需求进行灵活的代码修改和扩展 。
对比 Qwen2.5 instruct models,Qwen3 在非思考模式下同样展现出了强大的推理能力 。在常识逻辑推理测试中,Qwen3 能够快速理解问题所涉及的常识知识,运用合理的逻辑进行判断和推理,给出准确的结论 。例如在判断一些日常生活中的因果关系、事件合理性等问题时,Qwen3 能够迅速分析并给出正确的答案,展现出了超越同类模型的快速推理能力 。
(四)MCP 集成 Agent 增强
Qwen3 系列模型对 MCP(模型上下文协议)的支持,为其 Agent 能力的提升带来了巨大的助力 。MCP 协议是一种创新的技术,它允许大语言模型与外部数据源和工具进行无缝集成 。通过 MCP 协议,Qwen3 可以连接到各种外部资源,如数据库、知识库、API 接口等,获取最新的信息和数据,从而为用户提供更准确、更实时的回答 。在回答关于市场动态、实时数据等问题时,Qwen3 可以通过 MCP 协议调用相关的数据源,获取最新的市场数据和信息,给出最新的回答 。
MCP 协议还支持工具调用功能,这使得 Qwen3 能够利用各种外部工具来完成复杂的任务 。在处理一些需要专业工具支持的任务时,如数据分析、图像处理等,Qwen3 可以调用相应的工具,借助工具的强大功能完成任务 。它可以调用数据分析工具对大量的数据进行分析和可视化处理,或者调用图像处理工具对图片进行编辑和优化,大大拓展了模型的应用范围和能力边界 。
(五)多语言支持广泛
Qwen3 在多语言支持方面表现卓越,能够支持 119 种语言和方言,涵盖了全球主要的语系 。无论是印欧语系的英语、法语、德语,还是汉藏语系的汉语(包括简体中文、繁体中文及粤语等方言),亦或是阿拉伯语、日语、韩语等其他重要语言,Qwen3 都能熟练应对 。这使得 Qwen3 在全球化应用中具有得天独厚的优势,能够满足不同国家和地区用户的需求 。
在跨语言交流、多语言文档处理、国际业务支持等场景中,Qwen3 的多语言能力得到了充分的体现 。在跨国公司的客服系统中,Qwen3 可以与来自不同国家的客户进行流畅的交流,准确理解客户的问题并提供合适的解决方案 。在处理多语言文档时,它能够准确地识别文档的语言类型,并进行高效的翻译、摘要和内容分析等操作 。
训练优化数据升级
(一)预训练数据翻倍
在预训练数据方面,Qwen3 相较于 Qwen2.5 实现了重大飞跃,数据量达到了约 36 万亿个 token,几乎是 Qwen2.5 的两倍 。为了构建这个庞大而丰富的数据集,研发团队采用了多元化的数据收集与处理方式 。他们广泛地从网络上收集各种类型的数据,包括新闻资讯、学术论文、博客文章、社交媒体内容等,这些数据涵盖了丰富的知识领域和语言表达方式 。
团队还利用 Qwen2.5 - VL 从 PDF 文档中提取信息 。PDF 文档通常包含大量的专业知识和结构化信息,通过 Qwen2.5 - VL 的处理,能够将这些文档中的文本准确地提取出来,进一步丰富了训练数据的来源 。在数据提取后,再使用 Qwen2.5 对提取的内容进行质量改进,通过对文本的清洗、去重、纠错等操作,提高了数据的质量和可用性 。
为了增加数学和代码数据的数量,团队利用 Qwen2.5 - Math 和 Qwen2.5 - Coder 这两个数学和代码领域的专家模型合成数据 。这些合成数据包括教科书、问答对以及代码片段等多种形式,为模型在数学推理和代码生成等特定领域的能力提升提供了有力支持 。
(二)分阶段训练流程
Qwen3 的训练采用了精心设计的分阶段流程,包括预训练的三个阶段和后训练的四个阶段,每个阶段都对模型能力的提升起到了关键作用 。
在预训练的第一阶段(S1),模型在超过 30 万亿个 token 上进行了预训练,上下文长度为 4K token 。这个阶段就像是为模型打下坚实的基础,让模型学习基本的语言技能和通用知识 。通过对大量文本的学习,模型逐渐掌握了语言的语法规则、词汇含义以及常见的语义表达,能够对各种自然语言文本进行初步的理解和处理 。
第二阶段(S2),团队通过增加知识密集型数据(如 STEM、编程和推理任务)的比例来改进数据集,随后模型又在额外的 5 万亿个 token 上进行了预训练 。这一阶段就像是给模型进行专业知识的强化训练,使得模型在科学、技术、工程、数学以及编程等领域的知识和推理能力得到了显著提升 。在这个阶段,模型学习到了更多专业领域的术语、概念和解决问题的方法,能够更好地应对这些领域的复杂任务 。
最后阶段,团队使用高质量的长上下文数据将上下文长度扩展到 32K token,确保模型能够有效地处理更长的输入 。这一阶段让模型具备了处理长篇文档、复杂对话等长文本任务的能力,能够更好地理解文本的整体逻辑和语义关系,避免了因上下文信息不足而导致的理解偏差和错误回答 。
在后训练阶段,为了开发能够同时具备思考推理和快速响应能力的混合模型,团队实施了一个四阶段的训练流程 。在长思维链冷启动阶段,使用多样的长思维链数据对模型进行了微调,涵盖了数学、代码、逻辑推理和 STEM 问题等多种任务和领域 。这一过程为模型配备了基本的推理能力,让模型学会如何分析问题、运用知识进行推理,并逐步形成解决问题的思路 。
长思维链强化学习阶段则重点利用基于规则的奖励来增强模型的探索和钻研能力 。通过设定一系列的奖励规则,鼓励模型在面对复杂问题时,积极探索不同的解决方案,不断优化自己的推理过程,提高解决问题的能力和效率 。
思维模式融合阶段,在一份包括长思维链数据和常用的指令微调数据的组合数据上对模型进行微调,将非思考模式整合到思考模型中 。这一阶段确保了模型能够在不同的任务需求下,灵活地切换思考模式和非思考模式,实现推理和快速响应能力的无缝结合 。
通用强化学习阶段,在包括指令遵循、格式遵循和 Agent 能力等在内的 20 多个通用领域的任务上应用了强化学习,以进一步增强模型的通用能力并纠正不良行为 。通过这一阶段的训练,模型在各种通用任务上的表现得到了进一步提升,能够更好地理解和遵循用户的指令,生成符合格式要求的回答,并在智能体任务中展现出更强的能力 。
应用前景与未来展望
(一)现有应用接入
Qwen3 的强大性能和广泛特性使其在应用领域展现出了巨大的潜力,目前已经在多个应用场景中得到了实际接入和应用 。个人用户可以立即通过通义 APP 直接体验 Qwen3,感受其强大的智能交互能力 。在通义 APP 与网页版的主对话页面中,用户可以在逻辑推理、编程、翻译等垂类场景下体验到 Qwen3 的顶级智能能力 。通义 APP 还以超级智能体作为交互中枢,在主对话页面实现能问、能聊、理解图片、生成图片、翻译、写作等智能体验 ,为用户打造了一个全方位的智能助手 。
夸克也即将全线接入 Qwen3 ,这将进一步拓展 Qwen3 的应用范围,让更多用户在日常搜索和信息获取中受益于 Qwen3 的强大能力 。通过与夸克的结合,Qwen3 可以为用户提供更加智能、精准的搜索结果和信息服务,提升用户的搜索体验和效率 。
(二)未来发展方向
展望未来,阿里巴巴的研发团队有着明确而宏伟的目标,致力于从多个维度对 Qwen3 进行持续的优化和升级 。在模型架构方面,团队将深入研究和创新,探索更加高效、灵活的模型结构,以进一步提升模型的性能和表现 。通过优化模型架构,可以使模型在处理各种任务时更加智能和准确,能够更好地理解和处理复杂的自然语言信息 。
扩展数据规模也是未来发展的重要方向之一 。随着数据量的不断增加,模型可以学习到更多的知识和语言模式,从而提升其泛化能力和智能水平 。研发团队将不断收集和整理更多高质量的数据,丰富模型的训练数据来源,使模型能够接触到更广泛的知识领域和语言表达方式 。
增加模型大小可以提升模型的表示能力,使其能够处理更加复杂和抽象的任务 。团队将在硬件和算法等方面进行创新和优化,以支持更大规模模型的训练和部署 。延长上下文长度可以让模型更好地理解长文本的语义和逻辑关系,在处理长篇文档、多轮对话等任务时表现更加出色 。拓宽模态范围则可以使模型能够处理多种类型的数据,如文本、图像、音频等,实现多模态交互,为用户提供更加丰富和全面的服务 。
利用环境反馈推进强化学习以进行长周期推理也是未来的重要发展方向 。通过强化学习,模型可以根据环境的反馈不断调整自己的行为和策略,提高在复杂任务中的推理能力和决策能力 。在未来的发展中,Qwen3 有望在更多领域得到深入应用,推动人工智能技术在各个行业的落地和发展 。在医疗领域,它可以辅助医生进行疾病诊断、病历分析等工作,提高医疗效率和准确性;在教育领域,能够为学生提供个性化的学习辅导、智能答疑等服务,促进教育公平和质量提升 。
结语
Qwen3 的开源发布,无疑是 AI 领域的一次重大里程碑 。其卓越的性能、创新的特性以及广泛的应用潜力,为 AI 技术的发展开辟了新的道路 。无论是在学术界的研究探索,还是在工业界的实际应用,Qwen3 都有望发挥重要作用,推动 AI 技术的普及和创新 。对于广大开发者而言,Qwen3 提供了一个强大的工具和平台,鼓励大家积极探索和尝试,共同挖掘 AI 技术的无限可能 。相信在 Qwen3 的引领下,AI 领域将迎来更加繁荣和创新的发展阶段 。

技术共进,成长同行——讯飞AI开发者社区
更多推荐
 14
14 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)