
大模型算法工程师经典面试题—:为什么在softmax之前要对attention进行scaled(为什么除以 d_k的平方根)?”
因此, 的平方根被用于缩放(而非其他数值),因为,Q和K的矩阵乘积的均值本应该为0,方差本应该为1,这样会获得一个更平缓的softmax。从论文中可以看出,随着 的值变大,点积的大小会增大,从而推动softmax函数往仅有很小的梯度的方向靠拢(分布集中在绝对值大的区域),导致softmax 函数容易导致梯度消失问题。方差越大也就说明,点积的数量级越大(以越大的概率取大值)。网上虽然也有很多的学习资
面试题
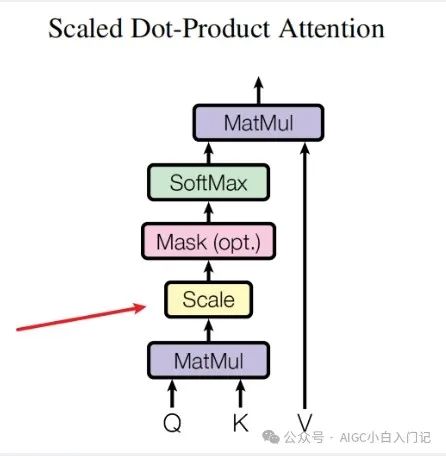
我们知道attention其实有很多种形式,而transformer论文中的attention是Scaled Dot-Porduct Attention 来计算keys和queries之间的关系。
如下图所示:
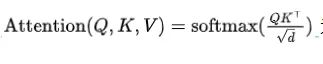
公式一
在公式一中,作者对 Q 和 K 进行点积以获得注意力权重,然后这些权重用于加权平均 V 。但在实际实现中,这个点积会被缩放,即除以keys的维度的平方根,常常表示为 。这里 是key向量的维度。
细心的同学都会发现,Attention 计算公式 中会 除以 根号d,那问题来了!!!
Attention为什么要除以根号d 呢?
注:这个题目属于 NLP 面试中一个高频题,基本上问到 Attention 或者 Transformers 的时候都会问。(小编在找实习的时候,就被问了不止十次,现在抽空整理一下答案。)
标准答案
这个问题在《Attention is All Your Need》论文中,作者就对该问题进行解答。
While for small values of the two mechanisms perform similarly, additive attention outperforms dot product attention without scaling for larger values of [3]. We suspect that for large values of, the dot products grow large in magnitude, pushing the softmax function into regions where it has extremely small gradients . To counteract this effect, we scale the dot products by
如果你没看懂上面英文答案,那下面我就对其进行解释:
从论文中可以看出,随着 的值变大,点积的大小会增大,从而推动softmax函数往仅有很小的梯度的方向靠拢(分布集中在绝对值大的区域),导致softmax 函数容易导致梯度消失问题。
例如,假设Q和K的均值为0,方差为1。它们的矩阵乘积将有均值为0,方差为 ( 是Q或者K的维度大小)。因此, 的平方根被用于缩放(而非其他数值),因为,Q和K的矩阵乘积的均值本应该为0,方差本应该为1,这样会获得一个更平缓的softmax。
如果你在面试过程中也遇到该问题,可以回答:
随着 的值变大,点积的大小会增大,如果没有及时对点积的大小进行缩放,那么万一点积的数量级很大,softmax的梯度就会趋向于0,也就会出现梯度消失问题。
问题引申新问题
当你按上述答案回答后,基本能够回答上点,但是面试官为了考察你对该问题的深度,会进行问以下两个问题:
-
为什么 变大会使得 softmax 梯度变小,从而导致梯度消失呢?
-
除了 , 是否可以用其他值代替?
-
self-attention一定要这样表达吗?
-
有其他方法不用除根号dk吗?
问题一:为什么 变大会使得 softmax 梯度变小,从而导致梯度消失呢?
标准答案:输入softmax的值过大,会导致偏导数趋近于0,从而导致梯度消失
下面我们将对该问题进行证明:
对于一个输入向量 , softmax函数将其映射归一化到一个分布 。
此时,softmax函数会先采用一个自然底数 e 将输入中的元素间差距先“拉大”,然后归一化为一个分布。假设某个输入 x 中最大的的元素下标是 k ,如果输入的数量级变大(每个元素都很大),那么 会非常接近1。
举个栗子,假定输入 ,对于不同量级的 a 产生的, 的值将发生什么变化:
a=1时,;
a=10时,;
a=100 时,(计算机精度限制)。
通过以下代码:
from math import exp
from matplotlib import pyplot as plt
import numpy as np
f = lambda x: exp(x * 2) / (exp(x) + exp(x) + exp(x * 2))
x = np.linspace(0, 100, 100)
y_3 = [f(x_i) for x_i in x]
plt.plot(x, y_3)
plt.show()
绘制图像如下:
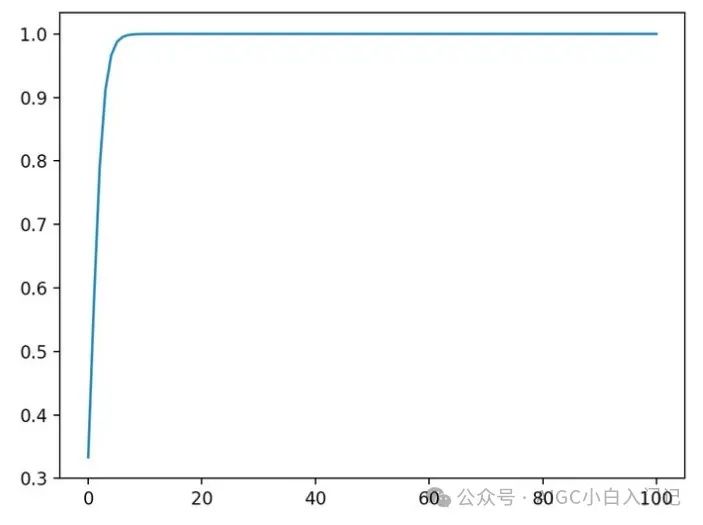
从图像中,我们发现数量级对于 softmax 函数的分布影响还是很大的。在数量级增大到某个值时,softmax 函数全部概率分布将趋于最大值对应阿标签。
接下来,我们一起来分析一个 softmax 函数的梯度,这里我们将 softmax 函数 设定为 ,softmax 函数对应的分布向量 的梯度为:
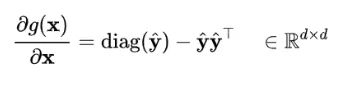
通过将该矩阵展开:
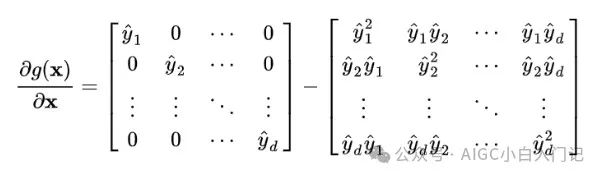
根据前面的讨论,当输入 x 的元素均较大时,softmax会把大部分概率分布分配给最大的元素假设我们的输入数量级很大,最大的元素是 1,那么就将产生一个接近one-hot的向量 ,,此时上面的矩阵变为如下形式:
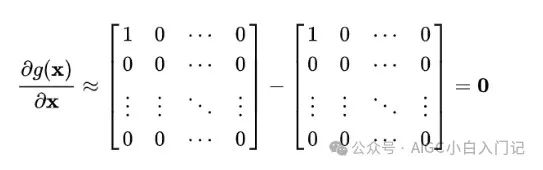
可以看出,在输入的数量级很大时,梯度消失为0,造成参数更新困难,
问题二:除了 , 是否可以用其他值代替?
标准答案:为什么选择 ,时因为可以使得 Q 和 K 点积 趋向于 期望为0,方差为1的标准正态分布,说白了就是归一化。
公式分析:
首先假设q和k都是服从期望为0,方差为1的独立的随机变量。
假设 ,则:
![]()
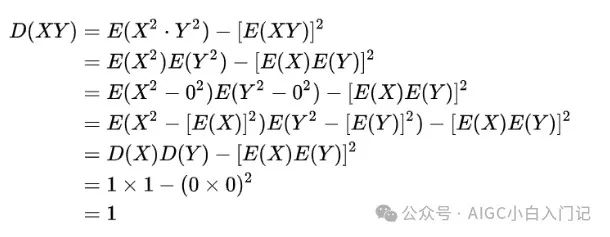
此时
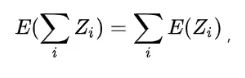
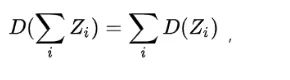
故有 Q 和 K 点积的均值 ,方差 。方差越大也就说明,点积的数量级越大(以越大的概率取大值)。那么一个自然的做法就是把方差稳定到1,做法是将 Q 和 K 点积除以,这样有:
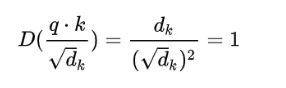
将方差控制为1,也就有效地控制了前面提到的梯度消失的问题。
问题三:self-attention一定要这样表达吗?
不需要,能刻画相关性,相似性等建模方式都可以。最好速度快,模型好学,表达能力够。
问题四:有其他方法不用除根号dk吗?
有,同上,只要能做到每层参数的梯度保持在训练敏感的范围内,不要太大,不要太小。那么这个网络就比较好训练。方式有,比较好的初始化方法,类似于google的T5模型,就在初始化把这个事情干了。
这份《AI产品经理学习资料包》已经上传CSDN,还有完整版的大模型 AI 学习资料,朋友们如果需要可以在文末CSDN官方认证二维码免费领取【保证100%免费】
资料包: CSDN大礼包:《对标阿里黑客&网络安全入门&进阶学习资源包》免费分享

AI产品经理,0基础小白入门指南
作为一个零基础小白,如何做到真正的入局AI产品?
什么才叫真正的入局?
是否懂 AI、是否懂产品经理,是否具备利用大模型去开发应用能力,是否能够对大模型进行调优,将会是决定自己职业前景的重要参数。
你是否遇到这些问题:
1、传统产品经理
不懂Al无法对AI产品做出判断,和技术沟通丧失话语权
不了解 AI产品经理的工作流程、重点
2、互联网业务负责人/运营
对AI焦虑,又不知道怎么落地到业务中想做定制化AI产品并落地创收缺乏实战指导
3、大学生/小白
就业难,不懂技术不知如何从事AI产品经理想要进入AI赛道,缺乏职业发展规划,感觉遥不可及
为了帮助开发者打破壁垒,快速了解AI产品经理核心技术原理,学习相关AI产品经理,及大模型技术。从原理出发真正入局AI产品经理。
这里整理了一些AI产品经理学习资料包给大家
📖AI产品经理经典面试八股文
📖大模型RAG经验面试题
📖大模型LLMS面试宝典
📖大模型典型示范应用案例集99个
📖AI产品经理入门书籍
📖生成式AI商业落地白皮书
🔥作为AI产品经理,不仅要懂行业发展方向,也要懂AI技术,可以帮助大家:
✅深入了解大语言模型商业应用,快速掌握AI产品技能
✅掌握AI算法原理与未来趋势,提升多模态AI领域工作能力
✅实战案例与技巧分享,避免产品开发弯路
这份《AI产品经理学习资料包》已经上传CSDN,还有完整版的大模型 AI 学习资料,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
资料包: CSDN大礼包:《对标阿里黑客&网络安全入门&进阶学习资源包》免费分享
AI大模型学习福利
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
大模型&AI产品经理如何学习
求大家的点赞和收藏,我花2万买的大模型学习资料免费共享给你们,来看看有哪些东西。
1.学习路线图
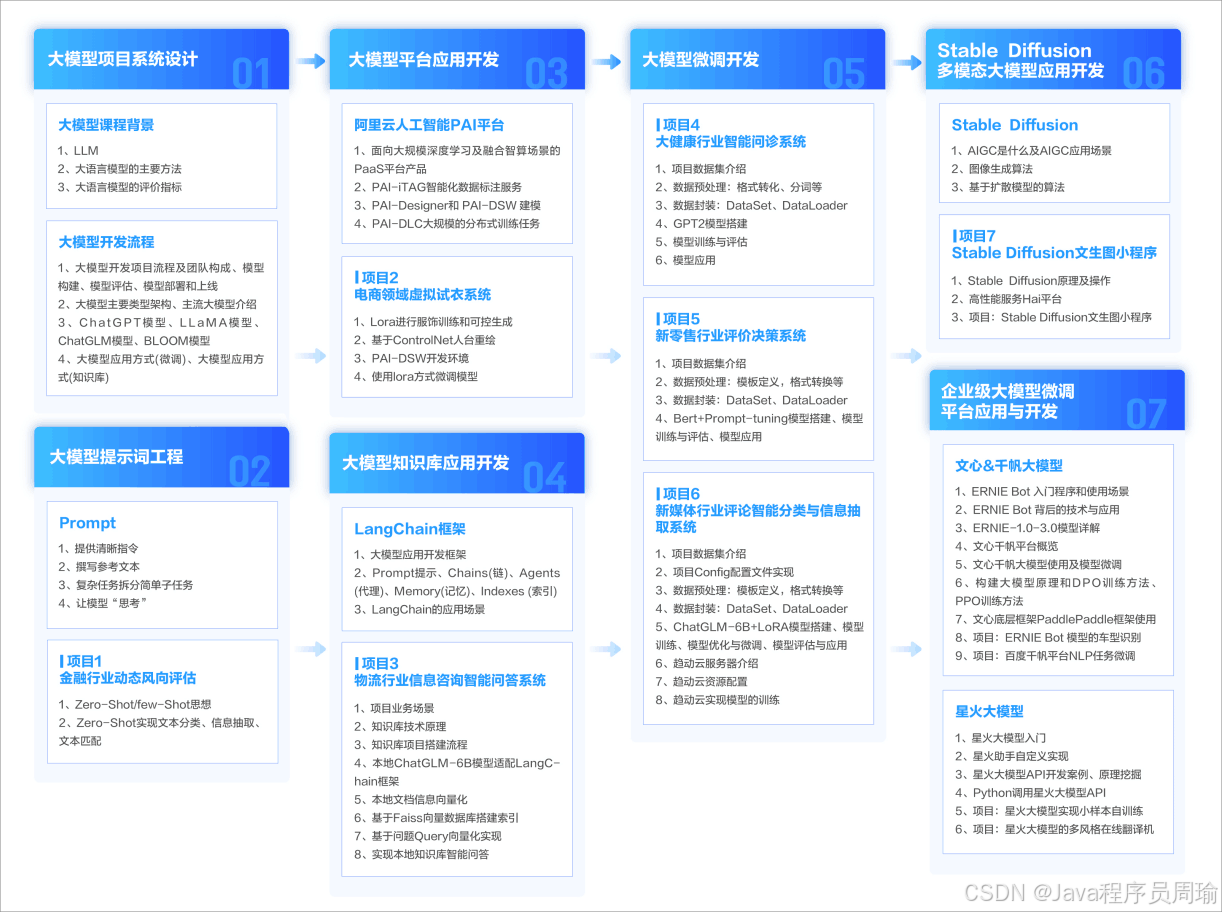
第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己整理的大模型视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。
(都打包成一块的了,不能一一展开,总共300多集)
因篇幅有限,仅展示部分资料,需要点击CSDN大礼包:《对标阿里黑客&网络安全入门&进阶学习资源包》免费分享前往获取
3.技术文档和电子书
这里主要整理了大模型相关PDF书籍、行业报告、文档,有几百本,都是目前行业最新的。

4.LLM面试题和面经合集
这里主要整理了行业目前最新的大模型面试题和各种大厂offer面经合集。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以CSDN大礼包:《对标阿里黑客&网络安全入门&进阶学习资源包》免费分享免费领取【保证100%免费】🆓

技术共进,成长同行——讯飞AI开发者社区
更多推荐


 20
20 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)