
倒排索引-自然语言处理
倒排索引简介
1 例子
倒排索引是搜索引擎的基础算法,假设用户有个搜索query,“苏州本轮疫情源头”,得到的响应如下:
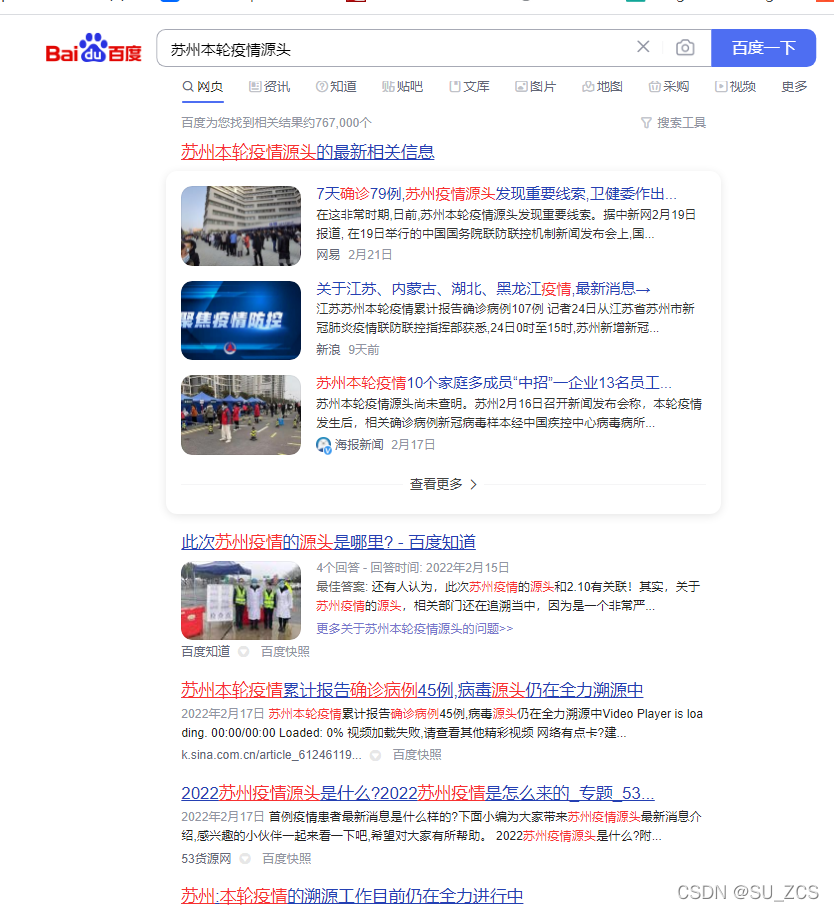
它是如何实现的呢?我们现在将query检索简化一下,假设这里有query“苏州本轮疫情源头”和存在于网页数据库中的四个网页:
4个网页
网页一:此次苏州疫情的源头,很多人认为...
网页二:本轮特大暴雨苏州的降水量达到...
网页三:2022苏州旅游攻略,苏州自由行攻略...
网页四:本土确诊+80!湖北武汉疫情源头查明...那么现在需要从4个网页中选取一个最合适的,需要进行如下操作。
1.1 关键词匹配
使用关键词匹配这种方法直接有效,即网页中包含查询的关键词越多,网页和查询query的相关度也就越大。在此之前需要进行文本预处理:
分词
将句子分成短语或关键词,python中有许多中文文本分词的库,可以使用jieba库进行分词。例如将query“苏州本轮疫情源头”分为{苏州,本轮,疫情,源头}。当然四个网页内容也需要分词:
网页一:此次,苏州,疫情,的,源头,很多,人,认为
网页二:本轮,特大,暴雨,苏州,的,降水量,达到
网页三:2022,苏州,旅游,攻略,苏州,自由行,攻略
网页四:本土,确诊,+,80,!,湖北,武汉,疫情,源头,查明去除停用词
在分词完之后,我们需要进行去除停用词操作,去除一些和查询无关紧要的东西,例如标点符号,语气词等。
| 网页序号 | 匹配关键词 | 匹配个数 |
| 一 |
此次,苏州,疫情,源头,很多,人,认为 |
3 |
| 二 | 本轮,特大,暴雨,苏州,降水量,达到 | 2 |
| 三 | 2022,苏州,旅游,攻略,苏州,自由行 | 1 |
| 四 | 本土,确诊,湖北,武汉,疫情,源头,查明 | 2 |
从上述表格“匹配个数”中我们可以得知,网页一是和查询query“苏州本轮疫情源头”最匹配的网页。
2 倒排索引
看到这里大家会有疑问,这和倒排索引有什么关系?大家需要从实际考虑,这个例子只有4个网页,检索起来比较容易,而实际情况网页的数量是数以万计的,那这样一个个去获取关键字匹配程度的效率是非常低的。引入倒排索引就很好的优化了这个问题。
在前面的介绍中,索引是网页(即key:网页一、二...),值是待匹配关键字(即value:此次、苏州、疫情...)。
倒排索引就是反过来:网页待匹配关键字作为索引(即key:此次、苏州、疫情...),所在网页索引为值(即value:网页一、二...)。前面的表格就可以改写成,
| query关键字 | 包含关键字的网页 |
| 苏州 | 网页一、网页二、网页三 |
| 本轮 | 网页二 |
| 疫情 | 网页一、网页四 |
| 源头 | 网页一、网页四 |
从上面表格可知,网页一是包含最多query关键词的网页,采用倒排索引的方法,使用倒排索引这种搜索的效率明显高了很多。
大家这时会问了,倒排索引的时候不也需要遍历所有的网页吗?不然怎么统计哪个网页包含的关键字最多?其实倒排索引的工作实现采用离线的工作完成了,即关键词苏州(网页一、网页二、网页三)已经提前创建好了,在查询的时候就直接从索引中查询。如图:
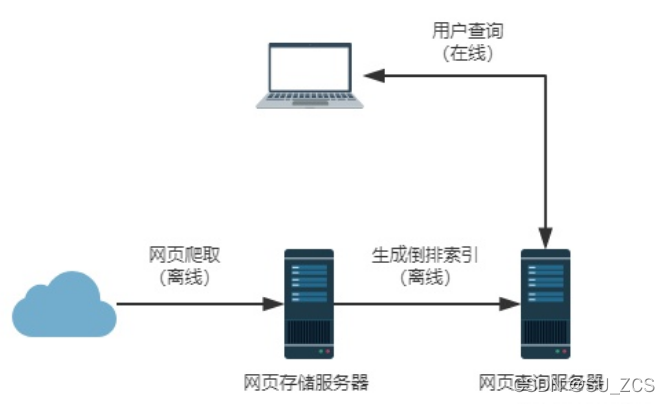
建立倒排索引不用考虑实时性的,庞大的数据量可以离线进行,但用户的在线查询则需要保证实时性,在查询时直接从建立好倒排索引服务器中查询。

技术共进,成长同行——讯飞AI开发者社区
更多推荐

 1
1 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)