
低代码SFT有监督微调Qwen3大模型的实践分享
使用LlaMaFactory零代码SFT微调Qwen3大模型的实践过程
近期工作上都在往大模型上做技术迁移和升级,所以做了一些大模型的调研、微调的工作。前面有篇文章分享了Qwen2.5-VL做图文理解生成,这里主要介绍使用Qwen3文本生成模型来做有监督微调的案例,做下经验总结和分享。这里借助LLaMA Factory 工具,它是一个简单易用且高效的大型语言模型(Large Language Model)训练与微调平台。通过 LLaMA Factory,可以在无需编写任何代码的前提下,在本地完成上百种预训练模型的微调。有个这个微调工具平台,我们只需要做一些偏工程、数据上的工作,即可完成大模型的微调和训练,过程变得相当简单易上手操作。
1、选择模型
Qwen3系列的文本生成模型有很多参数量级的可选择,可根据自己服务器的大小去选择。
Qwen3 是 Qwen 系列中的最新一代大型语言模型,提供了一整套密集型和专家混合(MoE)模型。基于广泛的训练,Qwen3 在推理、指令遵循、代理能力和多语言支持方面实现了突破性进展,具有以下关键特性:
- 独特支持在单一模型内无缝切换思维模式(适用于复杂的逻辑推理、数学和编码)和非思维模式(适用于高效、通用的对话),确保在各种场景下的最佳性能。
- 显著增强其推理能力,在数学、代码生成和常识逻辑推理方面超越了之前的 QwQ(在思维模式下)和 Qwen2.5 指令模型(在非思维模式下)。
- 优越的人类偏好对齐,在创意写作、角色扮演、多轮对话和指令遵循方面表现出色,提供更自然、吸引人和沉浸式的对话体验。
- 代理能力专长,能够在思维和非思维模式下与外部工具精确集成,并在复杂的基于代理的任务中达到开源模型中的领先性能。
- 支持 100 多种语言和方言,具备强大的多语言指令遵循和翻译能力。
1.1 Qwen3-4B模型概述
Qwen3-4B 具有以下特点:
- 类型:因果语言模型
- 训练阶段:预训练 & 后训练
- 参数数量:40 亿
- 非嵌入参数数量:36 亿
- 层数:36 层
- 注意力头数(GQA):Q 为 32 个,KV 为 8 个
- 上下文长度:原生 32,768 和 使用 YaRN 的 131,072 个令牌。
例子中我们选择Qwen3-4B的模型进行SFT有监督微调。可以直接使用未经SFT微调的Qwen3-4B模型做baseline。
2、准备训练数据
如果要进行SFT微调,就需要准备训练数据。
这里我们计划使用 LLmaFactory进行微调,官方文档:LLaMA Factory 。
根据不同任务来选择合适的训练数据集格式。这里我们使用指令监督微调数据集。
指令监督微调数据集 格式要求 如下:
[
{
"instruction": "人类指令(必填)",
"input": "人类输入(选填)",
"output": "模型回答(必填)",
"system": "系统提示词(选填)",
"history": [
["第一轮指令(选填)", "第一轮回答(选填)"],
["第二轮指令(选填)", "第二轮回答(选填)"]
]
}
]如上所示,主要需要准备的是 instruction、input、output。如果加上Think逻辑,可以放在system作为系统提示词。
这里我准备了两份训练数据,一份是只有instruction、input、output的;另一份是使用Qwen3-4B模型 Think思维链路生成的系统提示词,即数据有instruction、input、output、system。
两份训练数据示例:
# 训练数据集1
[{"instruction": "判断类型:{对话内容}", "input": "临近五一假期,有关出行的车票机票已经开始抢购,部分景点已经开始人头攒动", "output": "旅游", "system": "你是新闻内容审核员,负责新闻的内容的分类和内容安全合规审查", "history": []},]
# 训练数据集2
[{"instruction": "判断类型:{对话内容}", "input": "临近五一假期,有关出行的车票机票已经开始抢购,部分景点已经开始人头攒动", "output": "旅游", "system": "该文本包含'五一假期'、'机票'、'景点'旅游强相关的关键词,故判断为旅游分类", "history": []},]数据准备完成后,在dataset_info.json文件中添加数据集及其内容的定义,以备后续训练使用。
3、模型SFT
我们打开LlamaFactory交互操作界面
llamafactory-cli webuiIP是你所用服务器的IP,端口可以自定义。操作界面如下:
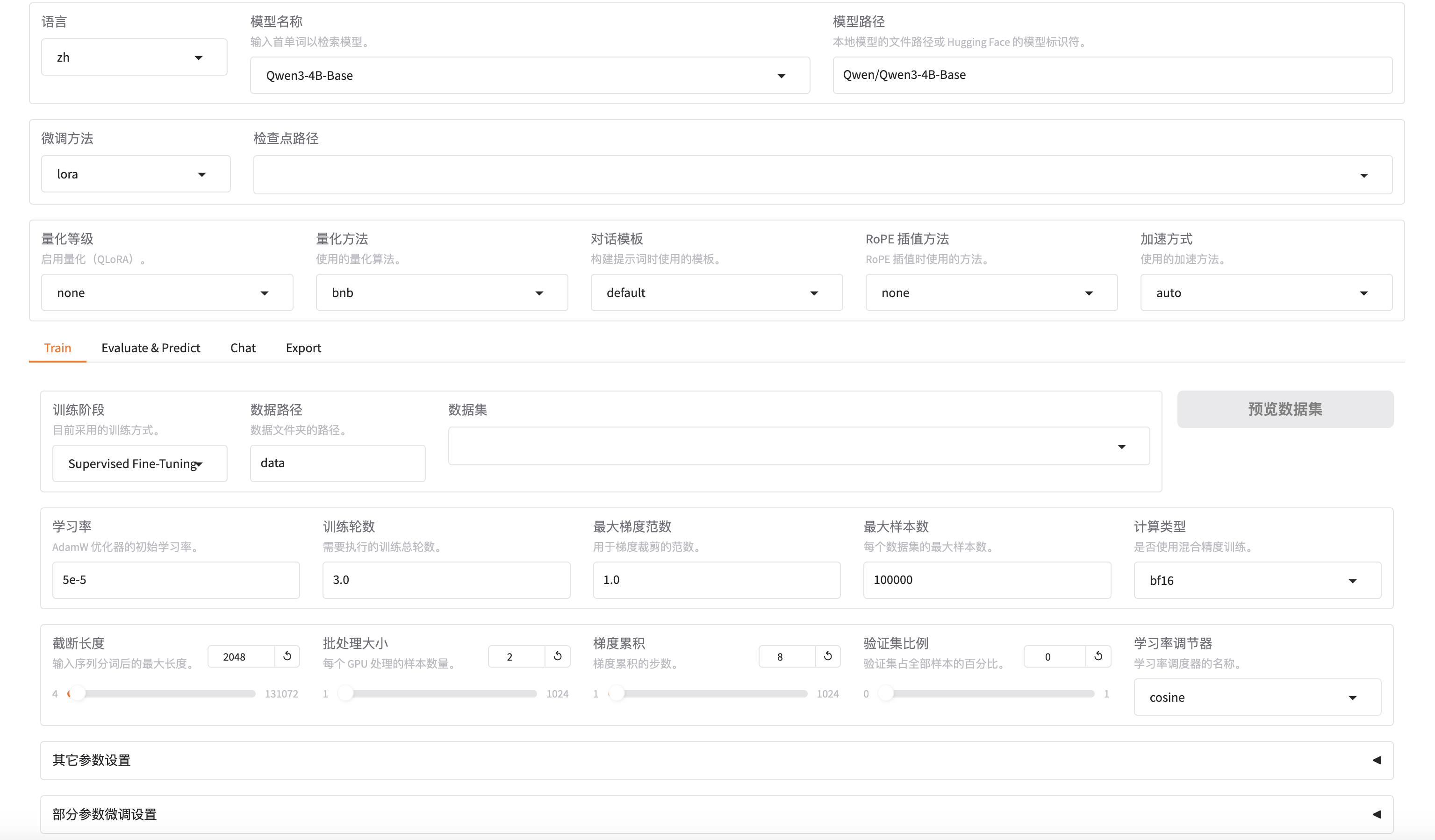
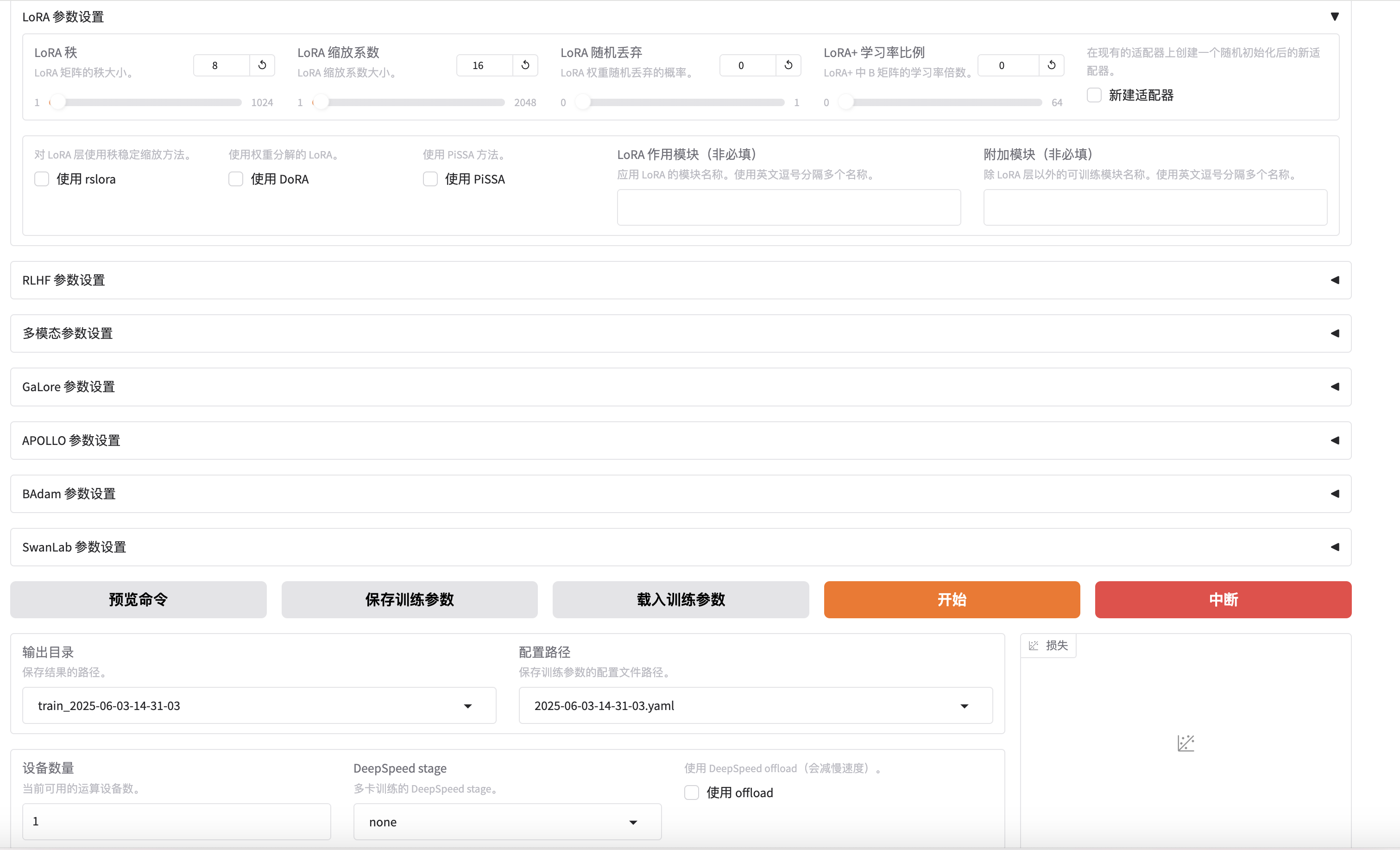
LlamaFactory的训练微调界面帮助实现了一个零代码SFT微调的功能。它还可以在右下角实时展现训练过程中loss的收敛曲线。训练时选择数据集为我们准备好的训练数据。
如果不想使用操作界面来训练,可以复制命令行,后台挂起去训练。
4、模型效果评价
模型训练完后,可以在操作界面上选择我们保存好的模型,使用chat模式去交互,直观测试几个case体验下交互效果。当然也可以使用选择好的标准去评价。比如我的需求是个多分类的任务,就选择了传统的多分类模型的评价指标,准确率、召回率、f1指标,这样可以将大模型的效果和线上模型的效果等做一个一致性的标准验收和比较。
除此之外,大模型还有一个很重要的检验指标,就是QPS。因为模型要上线提供服务,所以吞吐量、并发数、响应时间也是很重要的考核指标。
将上述微调好后的Qwen3大模型发布成API接口,使用AB压测来测试QPS。比如对我的任务接口,测试下来一条任务大约需要0.15-0.2s响应完成,AB压测响应:
ab -n 10000 -c 1000 -s 60 -k -H "Accept-Encoding: gzip" http://your.Ip:端口/pathPercentage of the requests served within a certain time (ms)
50% 86
66% 102
75% 115
80% 126
90% 193
95% 224
98% 252
99% 301
100% 350 (longest request)5、结论
结合上述实验过程和模型效果评价对比,就可以得出结论了,比如关键指标是否有提升,响应是否更快,大模型是否可以上线使用结论性的结果。我的调研实践结果是Qwen3大模型可以替代之前的小模型上线,只是需要在部署上多一些并发来支持算法服务。
以上就是使用LlaMaFactory零代码SFT微调大模型的实践过程。门槛低,简单易上手。
Done

技术共进,成长同行——讯飞AI开发者社区
更多推荐

 18
18 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)