
深度学习&PyTorch 之 DNN-回归
PyTorch DNN回归实战
·
前面文章讲了PyTorch的基本原理,本篇正式用PyTorch来进行深度学习的实现。
一、基本流程
PyTorch建模的基本流程如下:
- 数据导入,就是指将本地或者线上数据导入
- 数据拆分,跟机器学习一样,将数据拆分为训练集和验证集
- Tensor转换,PyTorch只能使用张量数据进行训练
- 数据重构是指将数据按照Batch进行切分后训练
- 模型定义是指定义深度学习的网络架构
- 模型训练是根据重构的数据进行迭代训练
- 结果展示是指将训练的Loss值进行展示查看,分类会加入准确率数据
二、代码实现
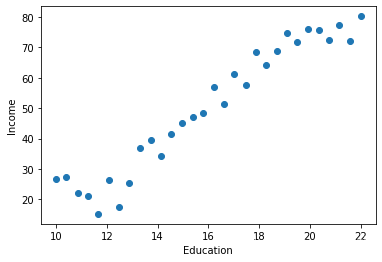
这里我们使用HR数据集进行展示,HR数据集有两列数据,一列是教育年限,一列是收入,旨在研究受教育年限与收入的关系。
我们按照上面的流程进行一一解读
2.1 数据导入
import pandas as pd
import torch
import torch.nn as nn
import numpy as np
import matplotlib.pyplot as plt
import os
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"
#本地训练建议加上这段代码,防止内存溢出
data = pd.read_csv('./Income1.csv')
data.columns
#Index(['Unnamed: 0', 'Education', 'Income'], dtype='object')
#一共两列数据
plt.scatter(data.Education, data.Income)
plt.xlabel('Education')
plt.ylabel('Income')
提前定义好超参数
batch = 16
epochs = 5000
lr = 0.00001
2.2 数据拆分
使用sklearn里面的train_test_split包
from sklearn.model_selection import train_test_split
train,test = train_test_split(data, train_size=0.7)
train_x = train[['Education']].values
test_x = test[['Education']].values
train_y = train.Income.values.reshape(-1, 1)
test_y = test.Income.values.reshape(-1, 1)
#全部转换成一维数据
2.3 To Tensor
将数据转换成Tensor格式
train_x = torch.from_numpy(train_x).type(torch.FloatTensor)
test_x = torch.from_numpy(test_x).type(torch.FloatTensor)
train_y = torch.from_numpy(train_y).type(torch.FloatTensor)
test_y = torch.from_numpy(test_y).type(torch.FloatTensor)
需要将训练集和测试集的特征列、标签列都要转换
2.4 数据重构
利用PyTorch里面TensorDataset、DataLoader进行重构
from torch.utils.data import TensorDataset
from torch.utils.data import DataLoader
train_ds = TensorDataset(train_x, train_y)
train_dl = DataLoader(train_ds, batch_size=batch, shuffle=True)
test_ds = TensorDataset(test_x, test_y)
test_dl = DataLoader(test_ds, batch_size=batch * 2)
#测试集不需要数据打乱
2.5 模型定义
利用nn.Module进行构建类
class LinearModel(nn.Module):
def __init__(self):
super(LinearModel, self).__init__()
self.linear = nn.Linear(1, 1)
#为了简单,构建一个全连接,没有隐藏层
#输入是一维,输出也是一维
def forward(self, inputs):
logits = self.linear(inputs)
return logits
定义优化器和损失函数
model = LinearModel()
loss_fn = nn.MSELoss()
opt = torch.optim.SGD(model.parameters(), lr=lr) # 定义优化器
2.6 模型训练
train_loss = []
train_acc = []
test_loss = []
test_acc = []
for epoch in range(epochs+1):
model.train()
for xb, yb in train_dl:
pred = model(xb)
loss = loss_fn(pred, yb)
loss.backward()
opt.step()
opt.zero_grad()
if epoch%10==0:
model.eval()
with torch.no_grad():
train_epoch_loss = sum(loss_fn(model(xb), yb) for xb, yb in train_dl)
test_epoch_loss = sum(loss_fn(model(xb), yb) for xb, yb in test_dl)
train_loss.append(train_epoch_loss.data.item() / len(train_dl))
test_loss.append(test_epoch_loss.data.item() / len(test_dl))
template = ("epoch:{:2d}, 训练损失:{:.5f}, 验证损失:{:.5f}")
print(template.format(epoch, train_epoch_loss.data.item() / len(train_dl), test_epoch_loss.data.item() / len(test_dl)))
print('训练完成')
基本上是标准的PyTorch代码
- 首先定义四个list来保存训练的损失值和准确率,回归的话只需要训练集损失和验证集损失
- 训练过程:预测–>记录损失–>向后传播–>迭代–>梯度清零
- 记录损失值并打印
epoch: 0, 训练损失:2376.64551, 验证损失:2268.30396
epoch:10, 训练损失:1810.91174, 验证损失:1848.62158
epoch:20, 训练损失:1773.27197, 验证损失:1485.73083
epoch:30, 训练损失:1213.77075, 验证损失:1199.84143
epoch:40, 训练损失:1202.41248, 验证损失:980.73230
epoch:50, 训练损失:851.91174, 验证损失:800.40961
epoch:60, 训练损失:737.22870, 验证损失:651.98907
epoch:70, 训练损失:526.98669, 验证损失:538.69696
epoch:80, 训练损失:483.67896, 验证损失:449.05524
epoch:90, 训练损失:424.45450, 验证损失:373.50266
epoch:100, 训练损失:456.17896, 验证损失:310.03577
epoch:110, 训练损失:272.65860, 验证损失:260.00620
epoch:120, 训练损失:317.16226, 验证损失:222.54755
epoch:130, 训练损失:210.82935, 验证损失:192.01817
......
2.7 查看结果
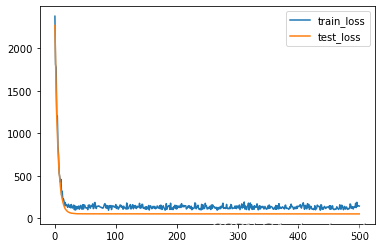
只打印结果看不出整体的Loss的走势,所以我们画图展示一下
import matplotlib.pyplot as plt
plt.plot(range(len(train_loss)), train_loss, label='train_loss')
plt.plot(range(len(test_loss)), test_loss, label='test_loss')
plt.legend()

技术共进,成长同行——讯飞AI开发者社区
更多推荐



 1
1 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)